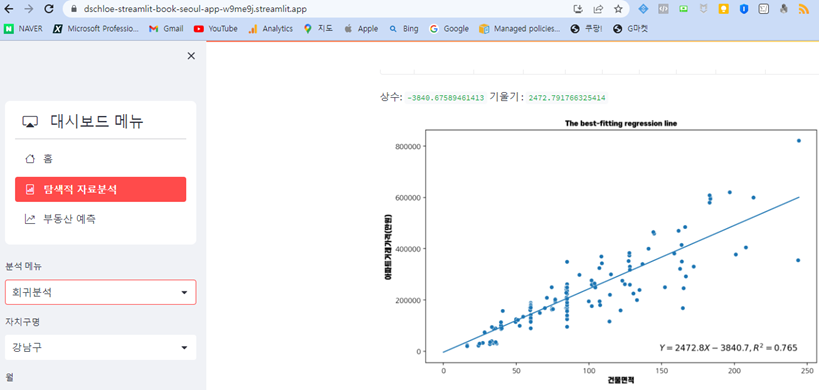
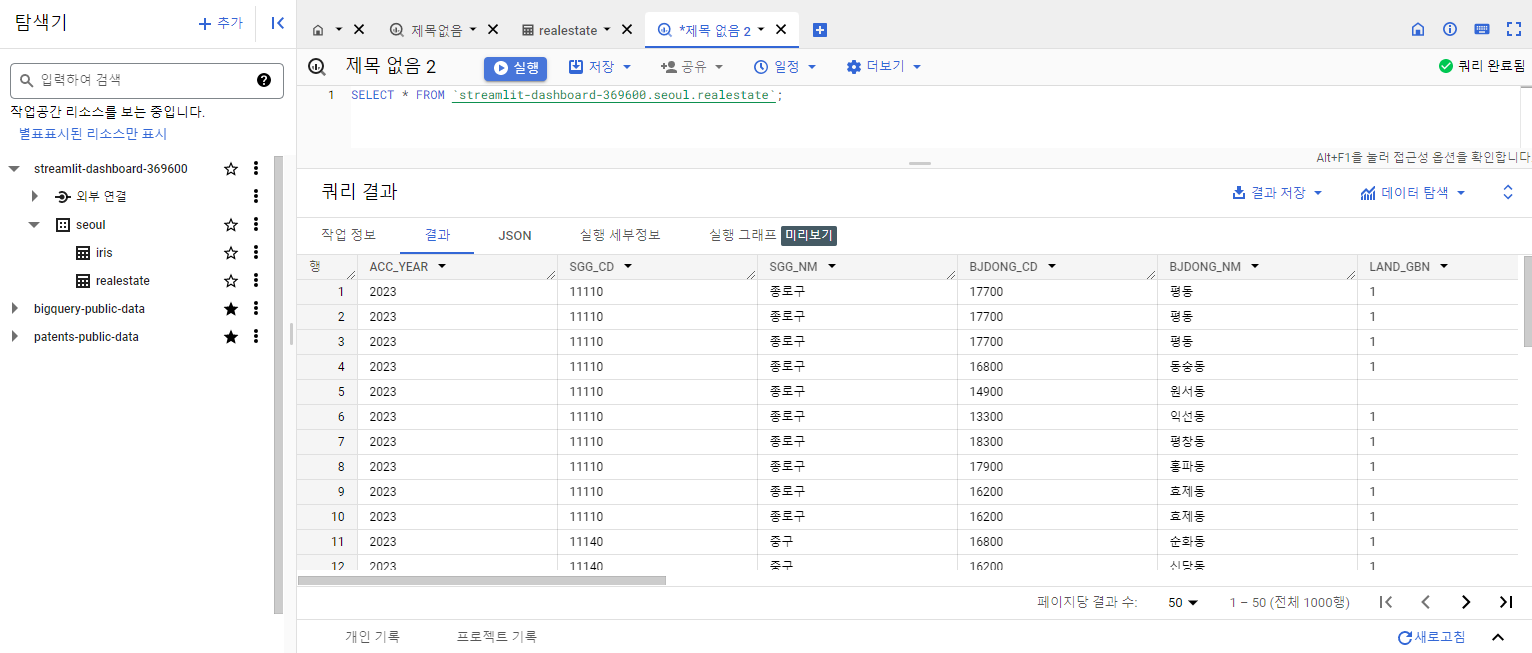
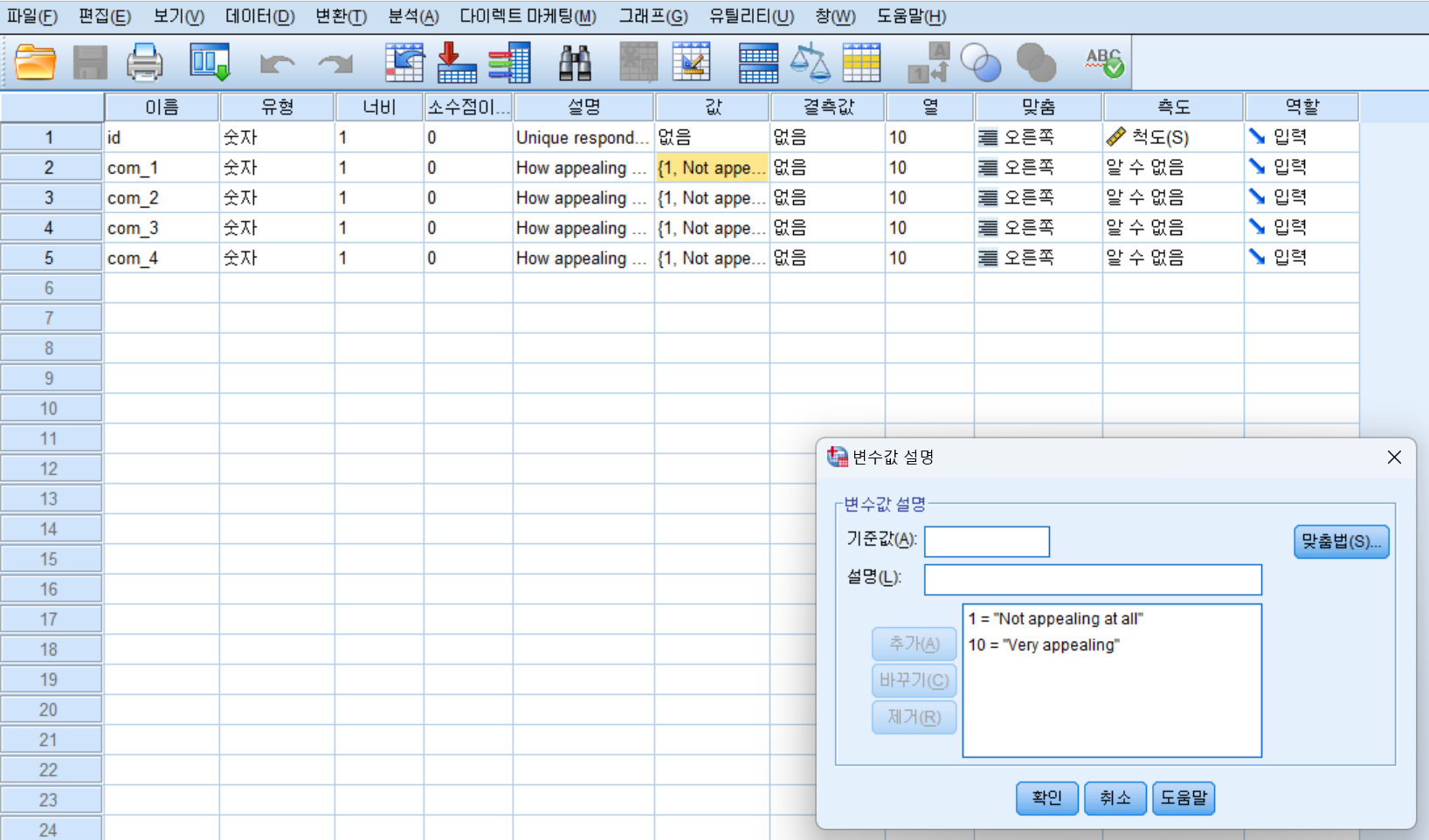
개요
- 연도, 월, 주만 있는 컬럼을 날짜 데이터 타입으로 변경하려면 어떻게 해야할까?
- 약간의 트릭이 필요하다
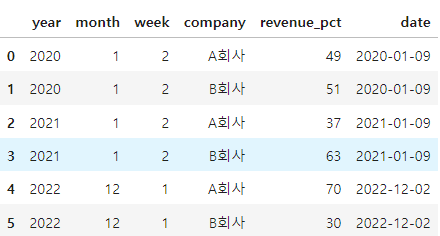
데이터 생성
import pandas as pd
data = [
{"year": 2020, "month": 1, "week": 2, "company" : "A회사", "revenue_pct" : 49},
{"year": 2020, "month": 1, "week": 2, "company" : "B회사", "revenue_pct" : 51},
{"year": 2021, "month": 1, "week": 2, "company" : "A회사", "revenue_pct" : 37},
{"year": 2021, "month": 1, "week": 2, "company" : "B회사", "revenue_pct" : 63},
{"year": 2022, "month": 12, "week": 1, "company" : "A회사", "revenue_pct" : 70},
{"year": 2022, "month": 12, "week": 1, "company" : "B회사", "revenue_pct" : 30},
]
df = pd.DataFrame(data)
df
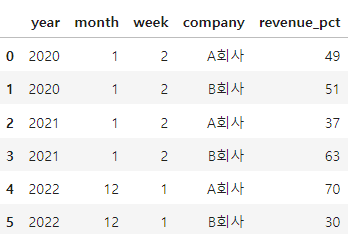
ChatGPT 방식
- chatGPT에서 알려준 방식으로 진행해본다.
df["date"] = pd.to_datetime(df["year"].astype(str) + df["week"].astype(str) + '1', format="%Y%W%w")
df
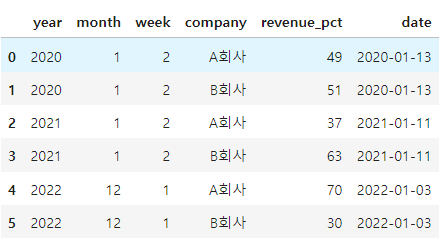
- 기대했던 것은 2022-12-1 일 방식인데, 2022-01-03이다.
- 만약, 전체데이터가 있다면, date 날짜가 중복될 수 있다.
수정된 방식
- 아래와 같이 수정하도록 한다.
- 두번째 라인 코드
7-6 은 일종의 특정 일자를 지정하는 것이다.
df["date"] = pd.to_datetime(df["year"].astype(str) + "-" + df["month"].astype(str))
df["date"] = df["date"] + pd.to_timedelta(df["week"] * 7 - 6, unit="D")
df