Step 01 - 빅카인즈 접속 후, 데이터 내려받기
- Step 03 - 분석 결과 및 시각화 탭을 클릭한다.
- 데이터 다운로드 탭 하단에 엑셀 다운로드 버튼을 클릭한다.
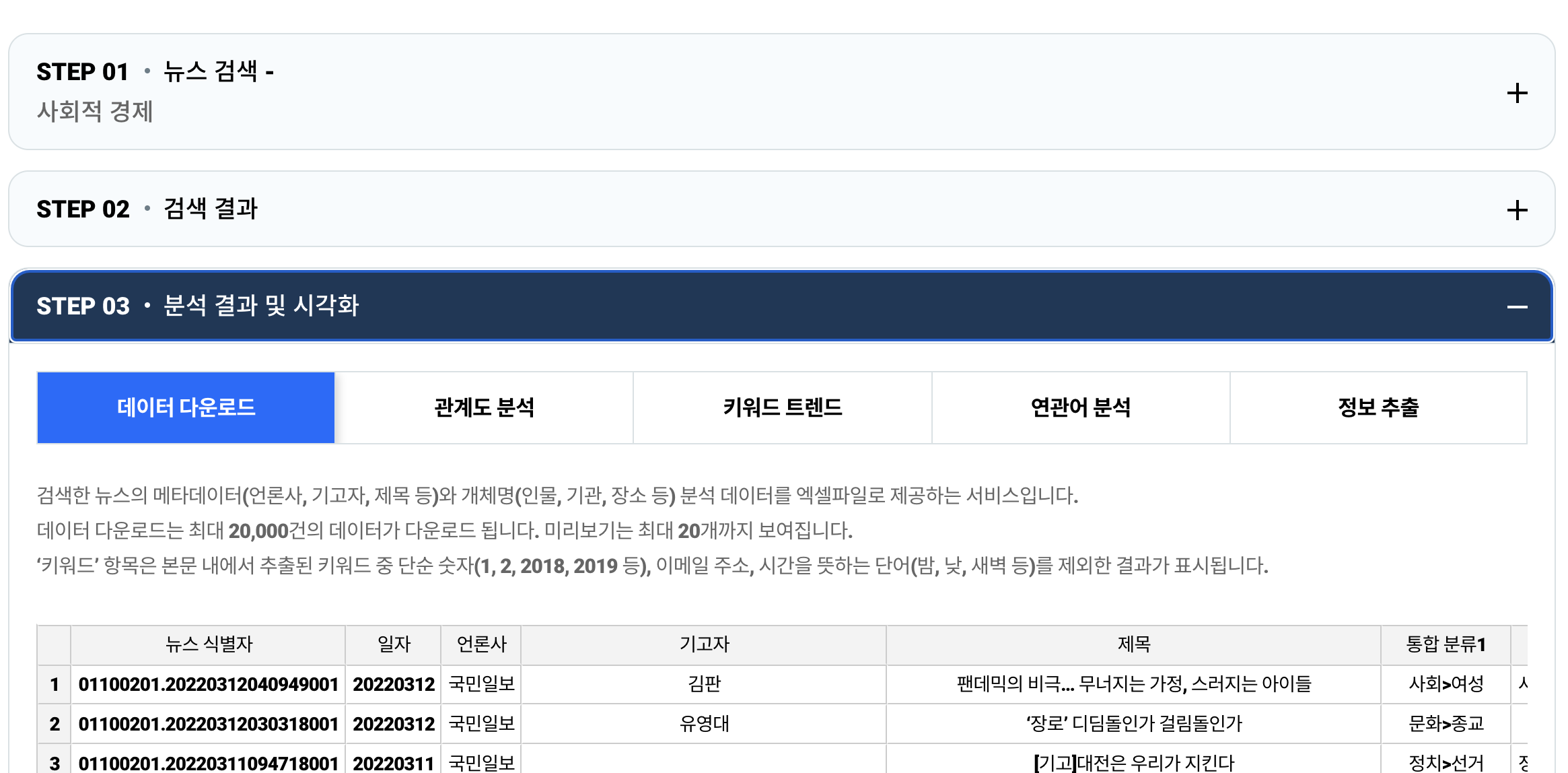
- 해당 파일에는 본문이 있지만, 보통 200자 내외로 짧게 요약이 되어 있다.
Step 02 - 웹 크롤링 소스 코드 작성을 위한 사전 준비
- 먼저 기 다운로드 된 파일을 불러온다.
- 전체 데이터에서 필요한 컬럼만 재추출한다.
> library(dplyr)
> library(readxl)
> raw_df = read_excel("data/NewsResult_20211213-20220313.xlsx", sheet = 1)
> raw_df2 = raw_df %>% select(일자, 언론사, 제목, URL)
> raw_df2 %>% group_by(언론사) %>% summarise(n = n())
# A tibble: 3 × 2
언론사 n
<chr> <int>
1 국민일보 180
2 조선일보 115
3 중앙일보 256
- 각 신문사별로 나눠서 객체를 저장한다. 여기에서는 국민일보만 추출하는 코드를 예시로 하였다.
> kmib_df = raw_df2 %>% filter(언론사 == "국민일보")
> head(kmib_df, 3)
# A tibble: 3 × 4 일자 언론사 제목 URL
<chr> <chr> <chr> <chr>
1 20220312 국민일보 팬데믹의 비극 무너지는 가정, 스러지는 아이들 http://news.kmib.co…
2 20220312 국민일보 ‘장로’ 디딤돌인가 걸림돌인가 http://news.kmib.co…
3 20220311 국민일보 [기고]대전은 우리가 지킨다 http://news.kmib.co…
- 이번에는 URL만 추출하여 특이점이 있는지 확인한다.
- 전체적으로 주소는 비슷하다.
- 몇몇 주소에서는
&cp=kd 같은 문자가 더 추가된 것을 확인할 수 있다. - 서로 다른 싸이트에서 본문의 위치 등이 동일한지 다른지 확인할 필요가 있다. (확인 결과, 차이는 없다!)
> kmib_df$URL[1:5]
[1] "http://news.kmib.co.kr/article/view.asp?arcid=0924235144&code=11131100"
[2] "http://news.kmib.co.kr/article/view.asp?arcid=0924235120&code=23111111"
[3] "http://news.kmib.co.kr/article/view.asp?arcid=0016856942&code=61221514&cp=kd"
[4] "http://news.kmib.co.kr/article/view.asp?arcid=0016853803&code=61111711&cp=kd"
[5] "http://news.kmib.co.kr/article/view.asp?arcid=0016847353&code=61131111&cp=kd"
Step 03 - 웹 크롤링 본문 내용 발췌
> url = kmib_df$URL[1]
> news = read_html(url, encoding = "EUC-KR")
> news
{html_document}<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ko">
[1] <head>\n<title>팬데믹의 비극… 무너지는 가정, 스러지는 아이들-국민일보</title>\n<meta http-equiv="Cont ...
[2] <body>\r\n<div id="wrap">\r\n\r\n<!-- header -->\r\n\r\n<script src="http://ww ...
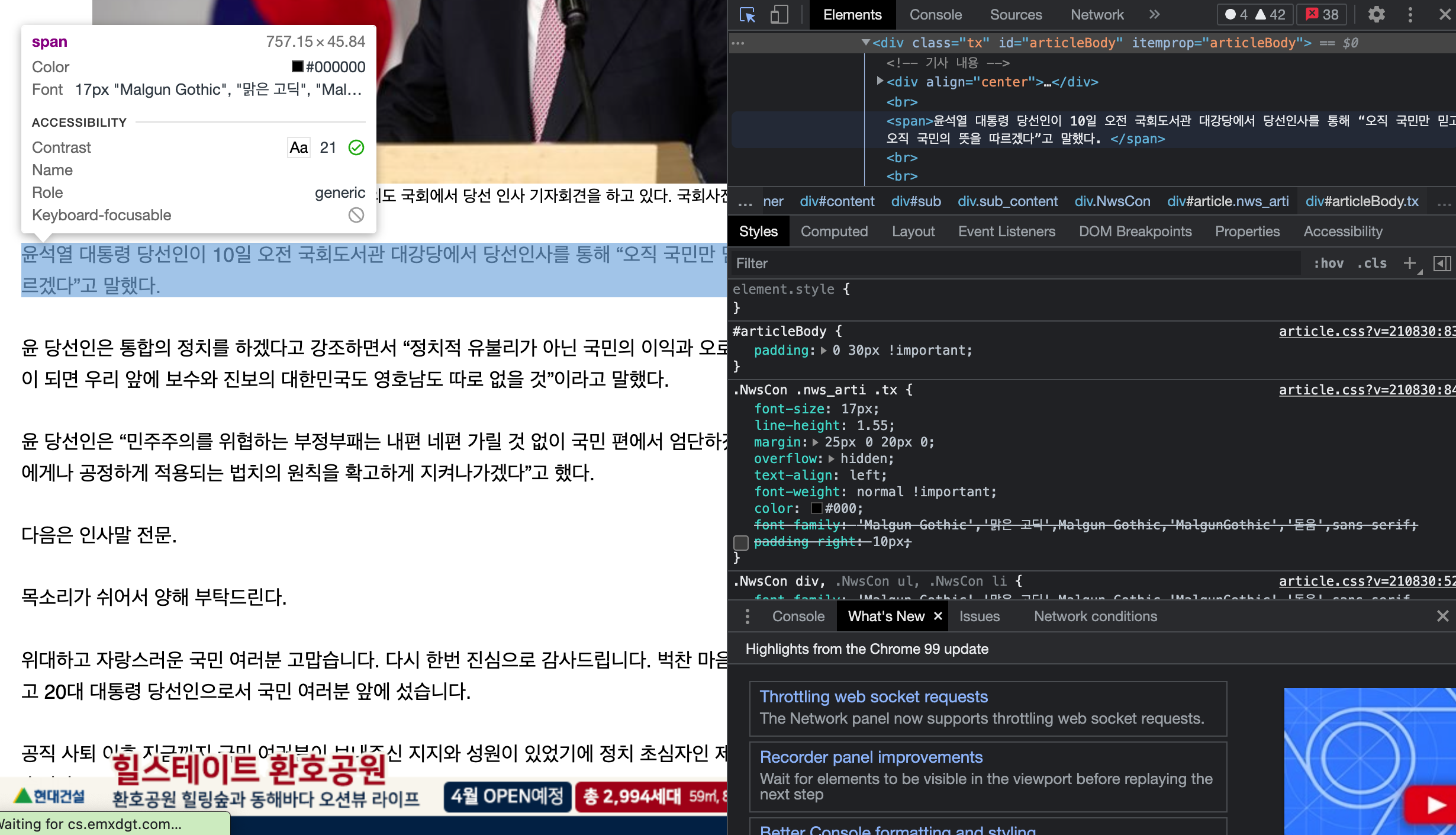
- 여기에서 div 태그 안에 있는 class tx 하단에 텍스트가 있는 것을 확인할 수 있다.