강의 홍보
사전 작업
- 우선 임시 데이터를 기록할 라이브러리인
faker 를 설치한다. - 흔히 쓰이는 필드들을 함수 하나로 쉽게 만들 수 있도록 지원한다.
(venv) $ pip3 install faker
데이터 생성하기 전체 코드
- 필자는
[writecsv.py](http://writecsv.py) 형태로 저장하였다. - 먼저 한줄 씩 설명하면 다음과 같다.
from faker import Faker
import csv
output=open('mydata.csv', mode = 'w')
fake=Faker()
header=['name','age','street','city','state','zip','lng','lat']
mywriter=csv.writer(output)
mywriter.writerow(header)
for r in range(1000):
mywriter.writerow([fake.name(),fake.random_int(min=18, max=80, step=1), fake.street_address(), fake.city(),fake.state(),fake.zipcode(),fake.longitude(),fake.latitude()])
output.close()
from faker import Faker 는 라이브러리를 불러오는 것이다.import csv 는 .csv 파일로 만들어주는 함수를 제공한다.- 이제 하나씩 살펴보도록 한다.
output=open('mydata.csv','w')
- 파일을 쓰기 모드로 연다는 뜻이며,
w 파일 쓰기 모드로 지정한다. - 읽기 전용 모드로 사용하려면
r , - 기존 내용에 덧붙여 쓴다면,
a, - 읽기와 쓰기가 모두 가능한 파일 모드는
r+ , - 마지막으로 텍스트가 아닌 파일을 다룰 때는
b 붙인다. 예를 들면, 데이터를 바이트 단위로 기록하려면 mode = "wb" 로 지정한다.
fake는 Faker() 클래스의 객체를 생성했다는 것을 의미한다.
header=['name','age','street','city','state','zip','lng','lat']
- header라는 리스트 객체를 만들고, 그 안에 각종 데이터가 들어갈 컬럼명을 추가했다.
mywriter=csv.writer(output)
mywriter.writerow(header)
for r in range(1000):
mywriter.writerow([fake.name(),fake.random_int(min=18, max=80, step=1), fake.street_address(), fake.city(),fake.state(),fake.zipcode(),fake.longitude(),fake.latitude()])
output.close()
- csv.writer 객체를 생성하여 mywriter로 지정한다.
- 그리고, header를 writerow()로 추가하면, 일종의 컬럼값이 우선 만들어진다.
- 그 후에, 데이터 행을 파일에 기록하는 코드를 fake 내 함수를 반복문으로 활용하여 만든 것이다.
- 모든 작업이 완료가 되었으면
output.close() 로 종료 한다.
(venv) $ python3 ch01_loadcsv.py
(venv) $ ls
ch01_loadcsv.py data.csv
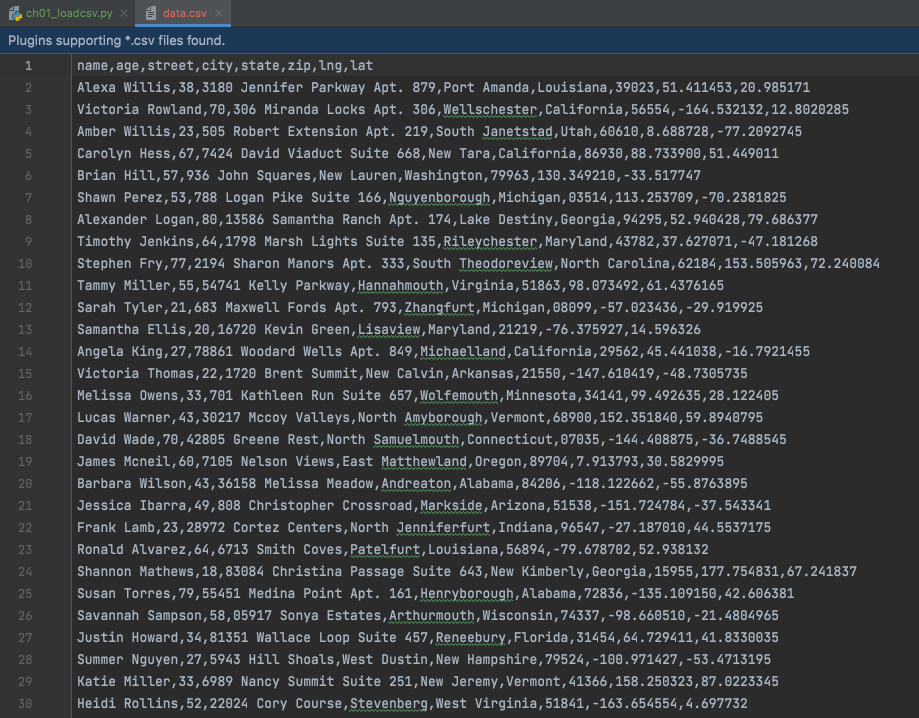
- 파일을 실행하면 위와 같이 데이터가 만들어진 것을 볼 수 있다.
- 실제 아래와 같이 나온 것을 확인할 수 있다.