개요
- 엘라스틱서치에서 밀집 벡터 위한 매핑 구성 방법 살펴보기
- 밀집 벡터가 저장될 embedding 이라는 필드 정의
- Python 코드로 엘라스틱서치 코드 구현
코드 전체 시나리오
Elasticsearch에 연결 및 인덱스 초기화dense_vector 타입으로 매핑 정의- 문서 배열 정의
BERT 모델을 이용해 각 문서를 벡터 임베딩- 벡터 포함 문서를 Elasticsearch에 색인
Elasticsearch 클라이언트 연결
- 로컬에서 실행 중인
Elasticsearch 서버에 접속 basic_auth: 로그인 자격 (ID: elastic, PW: 123456)verify_certs=False: 인증서 검증 생략 (로컬에서 SSL 없이 사용 시 편의용)
es_admin = Elasticsearch("http://localhost:9200",
basic_auth=("elastic", "123456"),
verify_certs=False)
Mapping 정의 및 인덱스 생성
dense_vector: 벡터 검색용 필드 (벡터 유사도 기반 검색 가능)dims: BERT의 출력 벡터는 기본적으로 768차원이므로 그에 맞춤
mapping = {
"properties": {
"embedding": {
"type": "dense_vector",
"dims": 768 # BERT의 출력 벡터 차원 수
}
}
}
기존 인덱스 삭제 후 새로 생성
- 기존에 있던
chapter-2 인덱스를 삭제 (중복 방지) - 새로운 인덱스를 위에서 정의한 벡터 매핑으로 생성
try:
es_admin.indices.delete(index="chapter-2")
print("기존 chapter-2 인덱스를 삭제했습니다.")
except:
print("chapter-2 인덱스가 존재하지 않습니다.")
es_admin.indices.create(index="chapter-2", body={'mappings': mapping})
print("새로운 chapter-2 인덱스를 생성했습니다.")
색인할 문서 데이터 구성
title과 text로 구성된 단순 문서 리스트text는 BERT 임베딩의 입력값이 된다
docs = [
{"title": "Document 1", "text": "This is the first document"},
{"title": "Document 2", "text": "This is the second document"},
{"title": "Document 3", "text": "This is the third document"}
]
BERT 모델과 토크나이저 초기화
bert-base-uncased: Hugging Face에서 사전 학습된 BERT 모델AutoTokenizer: 입력 텍스트를 BERT가 이해할 수 있는 토큰으로 변환AutoModel: 텍스트에 대한 BERT 임베딩 추출
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
BERT 임베딩 생성
tokenizer(...): 텍스트를 토큰화하고 PyTorch 텐서로 변환model(**inputs): BERT 실행 → 각 토큰에 대한 임베딩 벡터 반환last_hidden_state.mean(dim=1): 문장의 전체 임베딩을 mean pooling으로 하나의 벡터로 압축 (1×768 벡터)squeeze(0).numpy(): 불필요한 batch 차원 제거 후 NumPy로 변환tolist(): Elasticsearch에 저장 가능하게 리스트 형태로 변환
for doc in docs:
text = doc["text"]
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs).last_hidden_state.mean(dim=1).squeeze(0).numpy()
doc["embedding"] = outputs.tolist()
Elasticsearch에 색인
- 각 문서를
chapter-2 인덱스에 색인 - Elasticsearch는
embedding 필드를 dense_vector로 저장하며, 향후 벡터 검색에도 사용 가능
for doc in docs:
es_admin.index(index="chapter-2", body=doc)
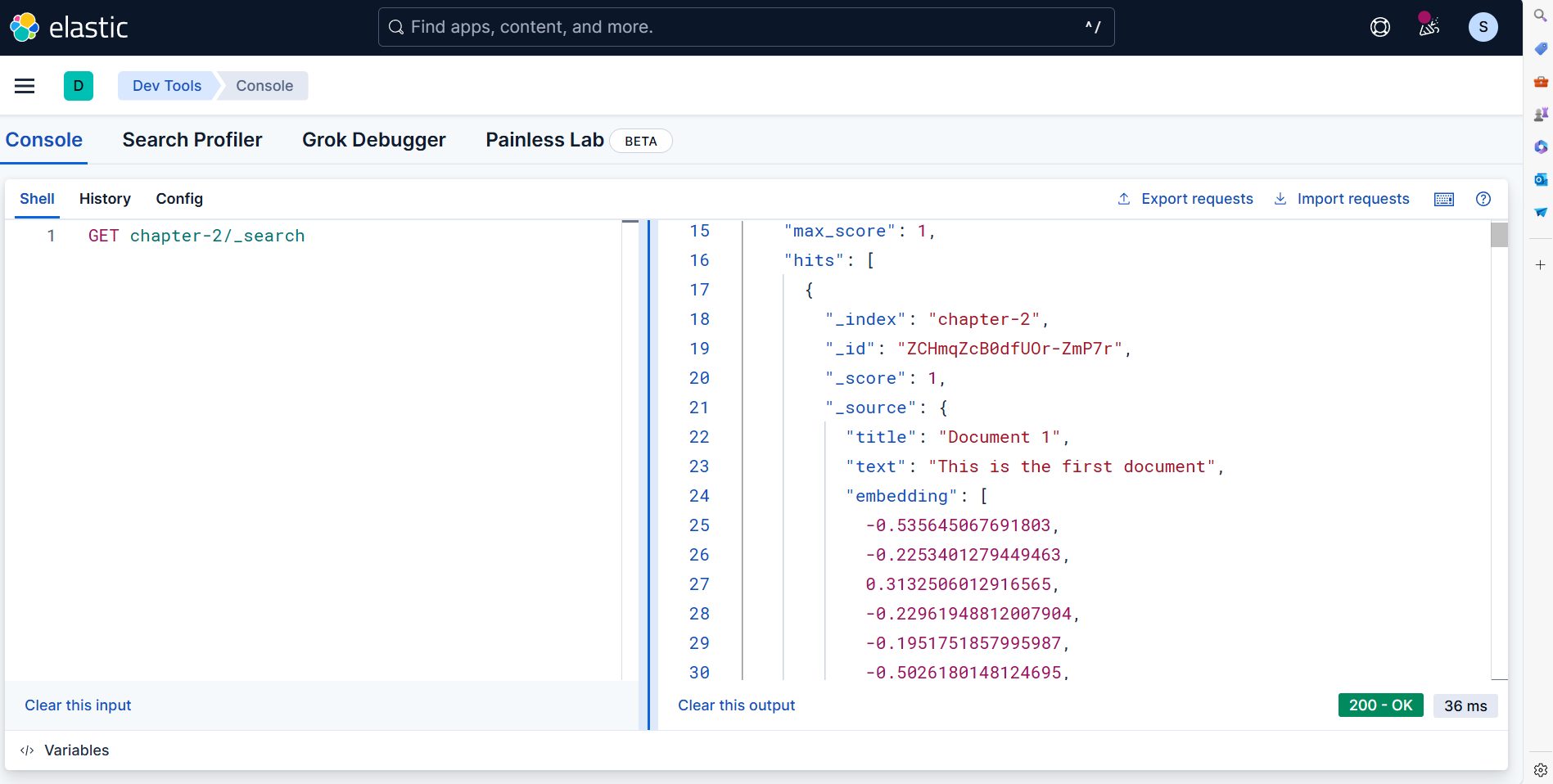
확인
- Kibana | Management | Dev Tools에서 색인된 문서 조회