현상
- plotly 라이브러리를 활용하여 Google Colab에서 시각화를 할 때 그래프가 보이지 않는 현상이 존재함
- 여러 방법론이 등장하지만, 공식문서에 따라서 어떻게 활용하는지 확인하도록 함
Google Colab
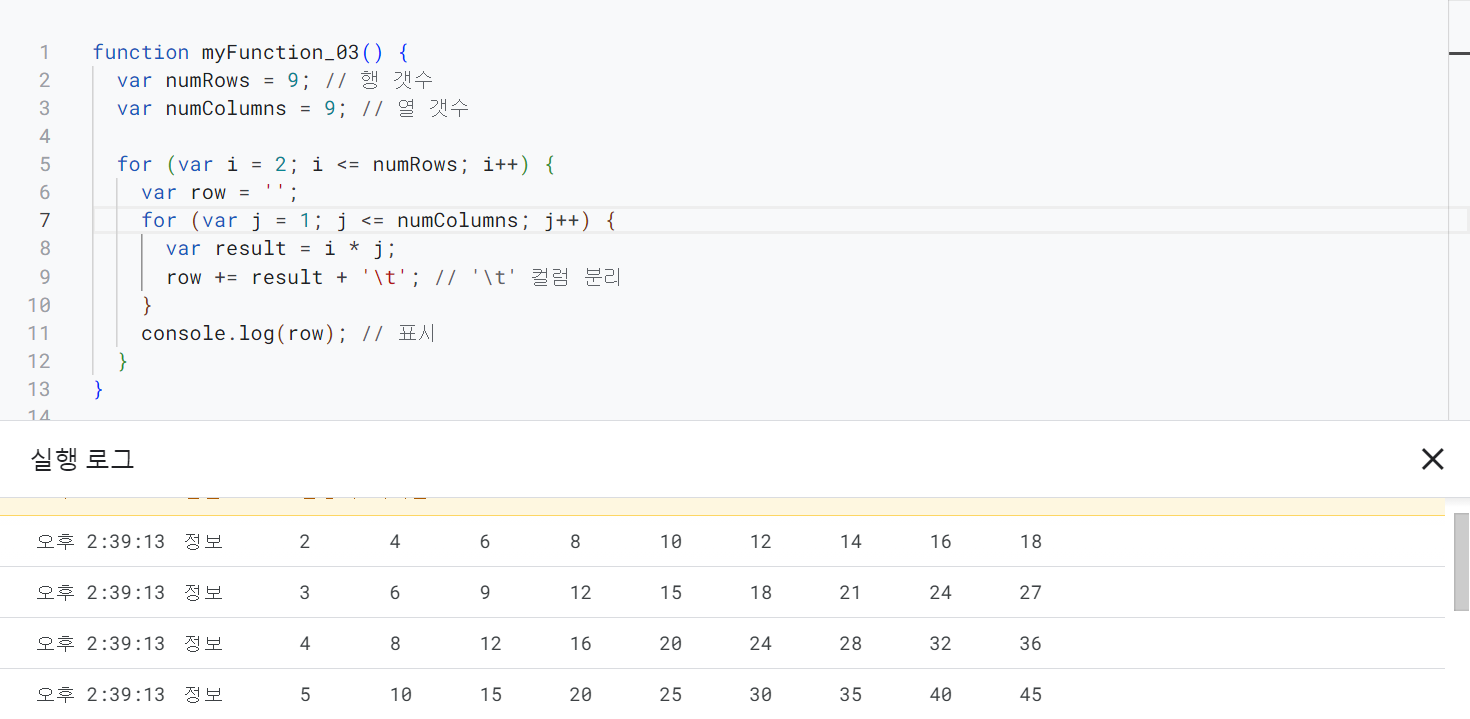
- 먼저 구글 코랩에서 간단한 시각화 코드를 작성하고 코드를 실행한다.
import plotly
plotly.__version__
# 5.13.1
import plotly.graph_objects as go
import pandas as pd
temp = pd.DataFrame({
"Fruit": ["Apples", "Oranges", "Bananas", "Apples", "Oranges", "Bananas"],
"Contestant": ["Alex", "Alex", "Alex", "Jordan", "Jordan", "Jordan"],
"Number Eaten": [2, 1, 3, 1, 3, 2],
})
fig = go.Figure()
fig.add_trace(go.Bar(name = "Alex", x = temp['Fruit'], y = temp[temp['Contestant'] == 'Alex']['Number Eaten'].values))
fig.add_trace(go.Bar(name = "Jordan", x = temp['Fruit'], y = temp[temp['Contestant'] == 'Jordan']['Number Eaten'].values))
fig.update_layout(barmode='group')
print(type(fig))
fig.show()
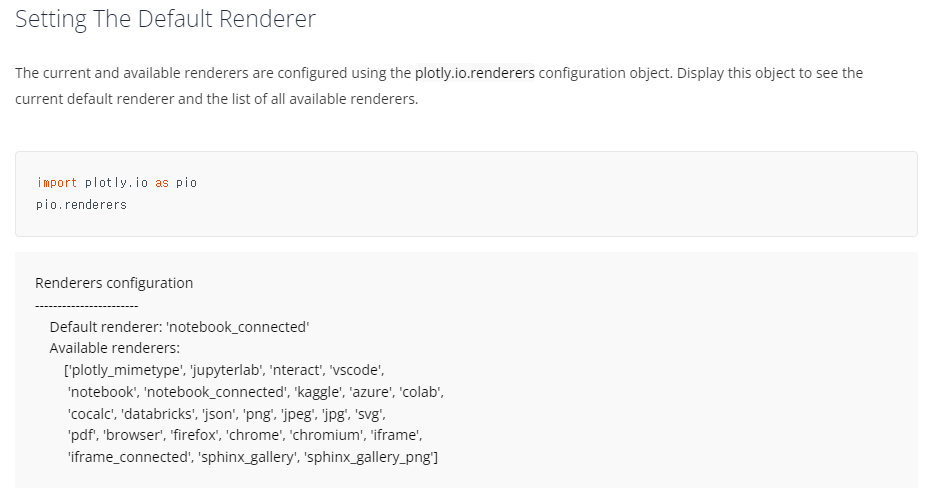
시각화가 나타나지 않을 경우
- 만약 시각화가 나타나지 않는다면 설정이 제대로 되어 있지 않았을 가능성이 있다.
- 공식문서를 참조하면 다음과 같다.
- 공식 문서에서의 설명을 보면 다음과 같다.