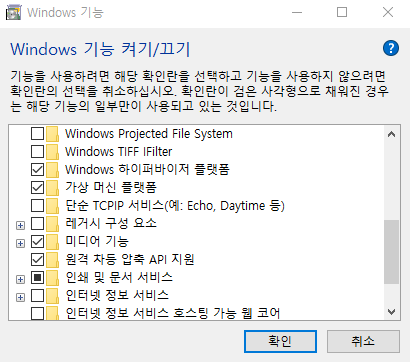
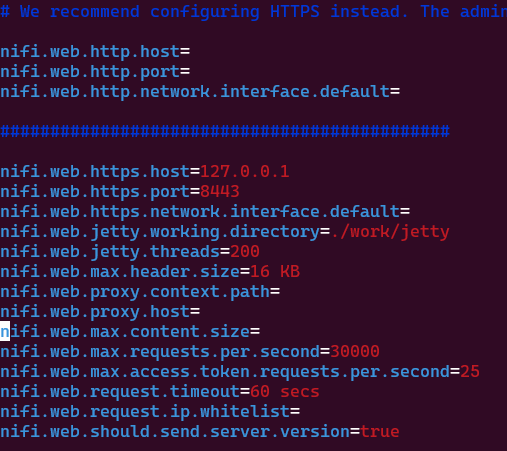
Step 1. 사전 필수 패키지 설치
- 우선 시스템 패키지를 업데이트 하고, HTTPS와 관련된 패키지를 설치한다.
$ sudo apt update
$ sudo apt install apt-transport-https
- 자바를 설치한다.
$ sudo apt install openjdk-11-jdk
$ java -version
openjdk version "11.0.14.1" 2022-02-08
OpenJDK Runtime Environment (build 11.0.14.1+1-Ubuntu-0ubuntu1.20.04)
OpenJDK 64-Bit Server VM (build 11.0.14.1+1-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)
- 자바 환경 변수를 설정하기 위해 아래와 같이 에디터를 입력한다.
$ sudo vi /etc/environment
JAVA_HOME="/usr/lib/jvm/java-11-openjdk-amd64"
$ source /etc/environment
$ echo $JAVA_HOME
/usr/lib/jvm/java-11-openjdk-amd64
Step 2. ElasticSearch 설치
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
OK
$ sudo sh -c 'echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" > /etc/apt/sources.list.d/elastic-7.x.list'
$ sudo apt-get update
Hit:1 https://artifacts.elastic.co/packages/7.x/apt stable InRelease
Hit:2 http://security.ubuntu.com/ubuntu focal-security InRelease
Hit:3 http://archive.ubuntu.com/ubuntu focal InRelease
Hit:4 http://archive.ubuntu.com/ubuntu focal-updates InRelease
Hit:5 http://archive.ubuntu.com/ubuntu focal-backports InRelease
Reading package lists... Done
$ sudo apt-get install elasticsearch
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
elasticsearch
0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
Need to get 312 MB of archives.
After this operation, 517 MB of additional disk space will be used.
Get:1 https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 elasticsearch amd64 7.17.2 [312 MB]
Fetched 312 MB in 8s (40.9 MB/s)
Selecting previously unselected package elasticsearch.
(Reading database ... 32942 files and directories currently installed.)
Preparing to unpack .../elasticsearch_7.17.2_amd64.deb ...
Creating elasticsearch group... OK
Creating elasticsearch user... OK
Unpacking elasticsearch (7.17.2) ...
Setting up elasticsearch (7.17.2) ...
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.service
warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME
Created elasticsearch keystore in /etc/elasticsearch/elasticsearch.keystore
Processing triggers for systemd (245.4-4ubuntu3.15) ...
Step 3. Elasticsearch 서비스 시작
- 이번에는 elasticsearch 서비스를 시작한다.
$ sudo systemctl start elasticsearch
- 만약 아래와 같은 에러 메시지가 뜬다면, 추가해야 한다.
System has not been booted with systemd as init system (PID 1).
Can't operate. Failed to connect to bus: Host is down
$ sudo -b unshare --pid --fork --mount-proc /lib/systemd/systemd --system-unit=basic.target
$ sudo -E nsenter --all -t $(pgrep -xo systemd) runuser -P -l $USER -c "exec $SHELL"
$ sudo systemctl enable elasticsearch
Synchronizing state of elasticsearch.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable elasticsearch
Created symlink /etc/systemd/system/multi-user.target.wants/elasticsearch.service → /lib/systemd/system/elasticsearch.service.
$ sudo systemctl start elasticsearch
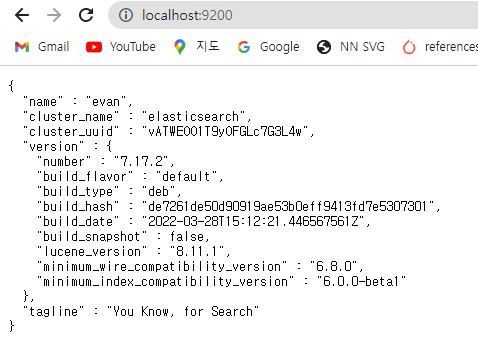
$ curl -X GET "localhost:9200/"
{
"name" : "evan",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "vATWEOO1T9yOFGLc7G3L4w",
"version" : {
"number" : "7.17.2",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "de7261de50d90919ae53b0eff9413fd7e5307301",
"build_date" : "2022-03-28T15:12:21.446567561Z",
"build_snapshot" : false,
"lucene_version" : "8.11.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
- 만약 위와 같은 메시지가 뜨면, 윈도우 화면에서 재 확인해본다.