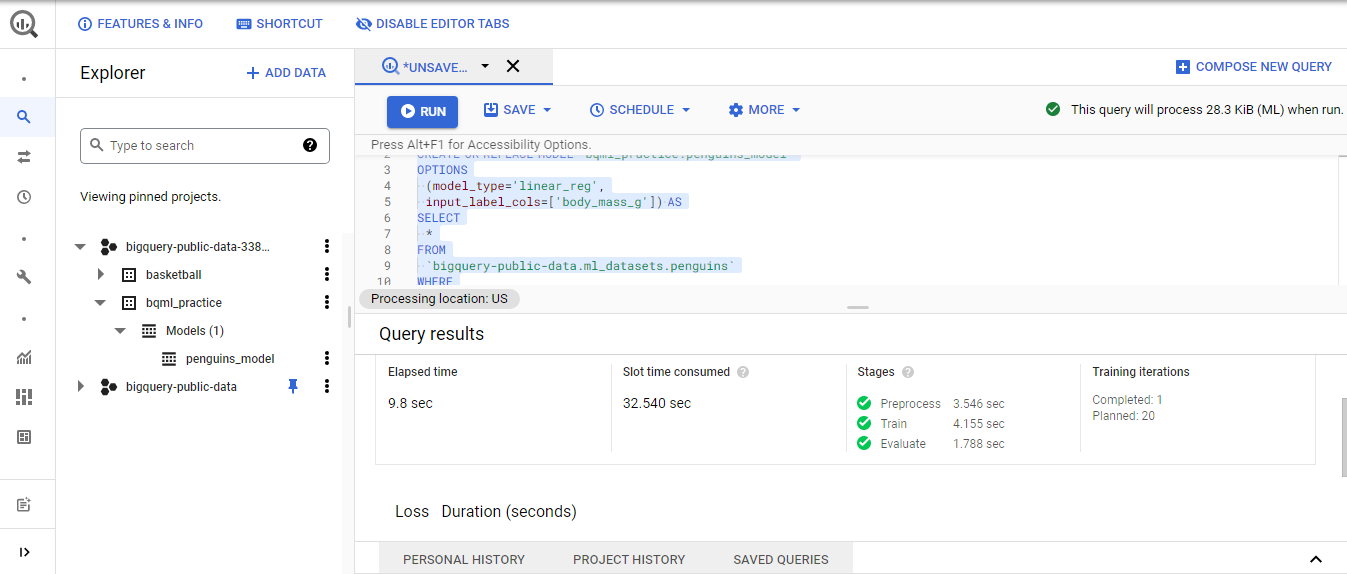
BigQuery 데이터 입출력 From Local TO BigQuery
개요
- 서비스 계정 추가 후, 데이터 업로드
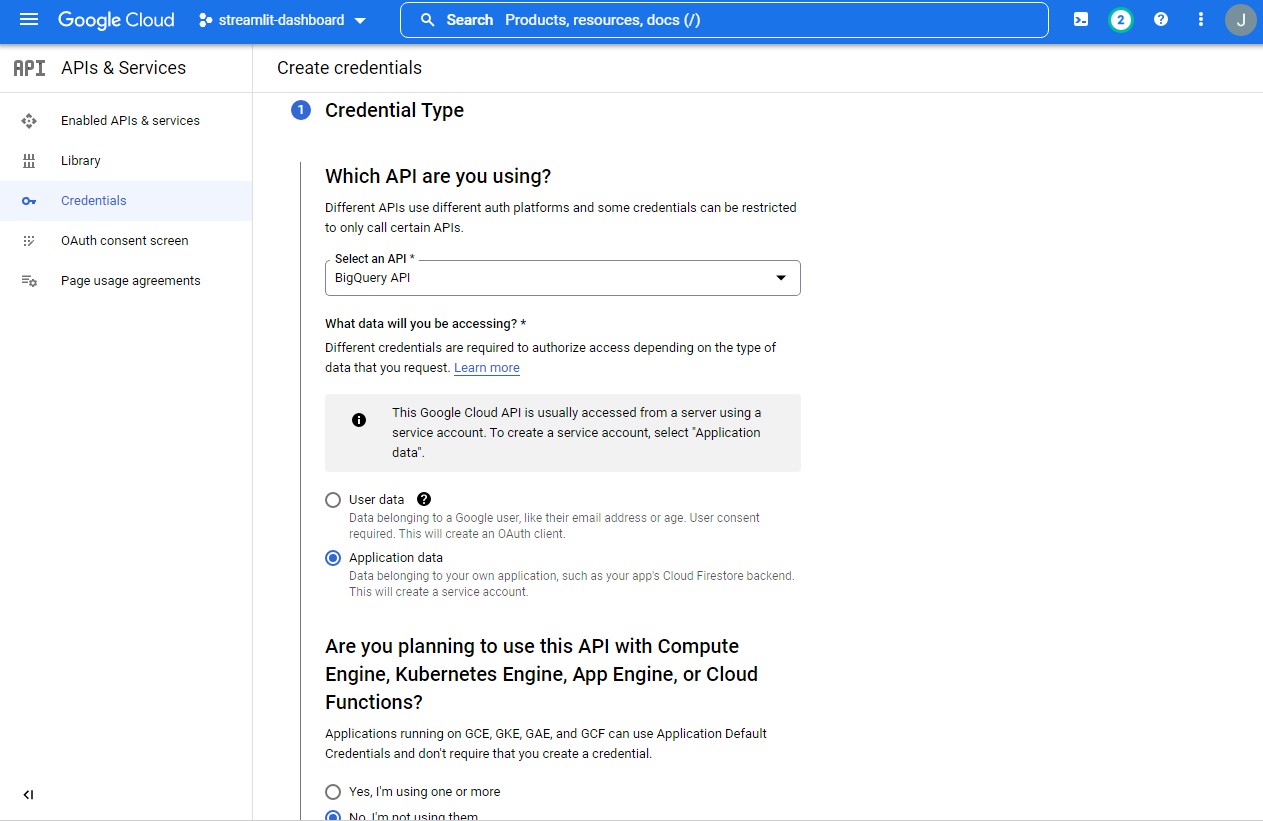
GCP 서비스 계정 추가
- IAM 및 관리자 > 서비스 계정 > 서비스 계정 만들기 선택
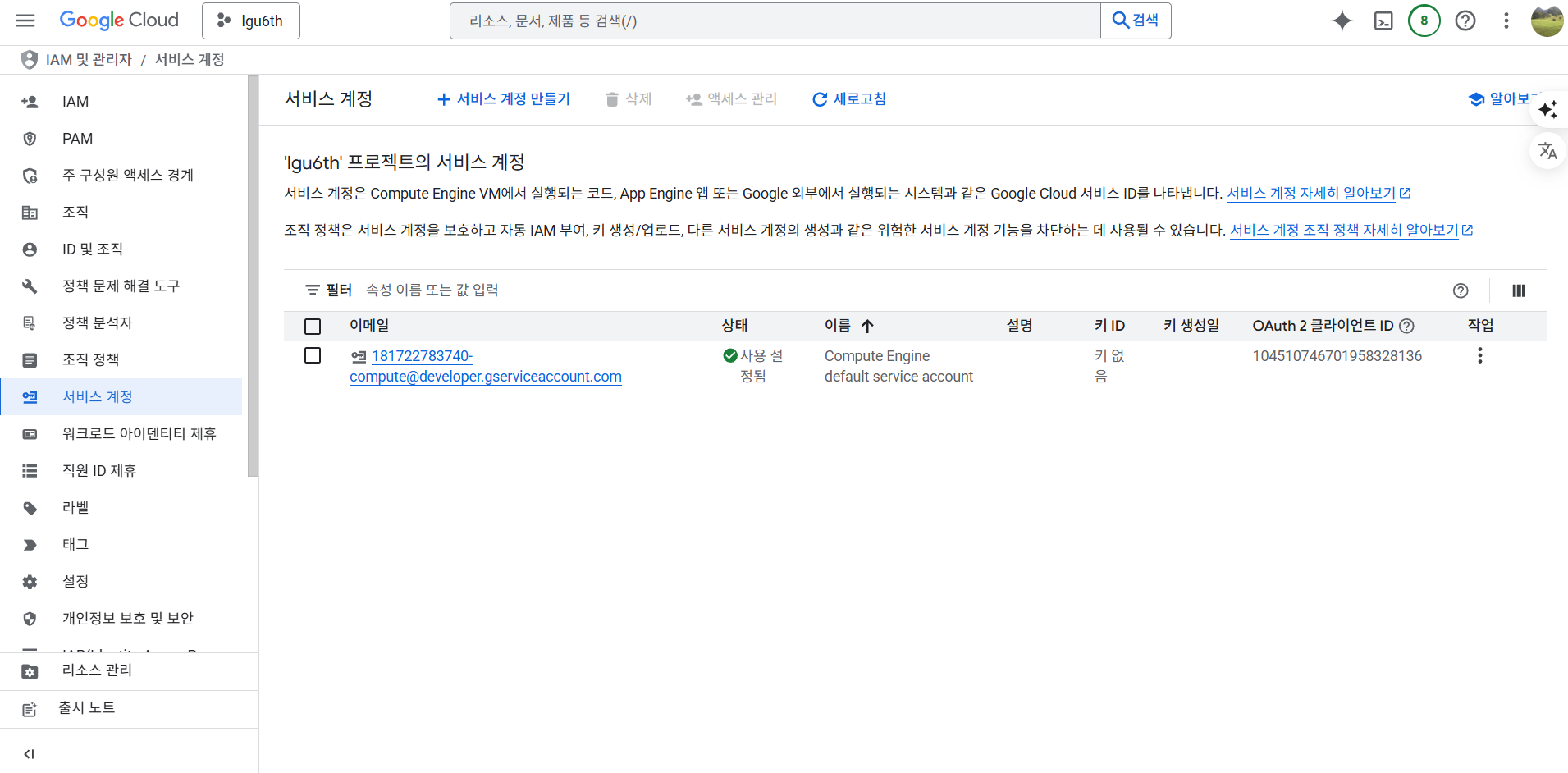
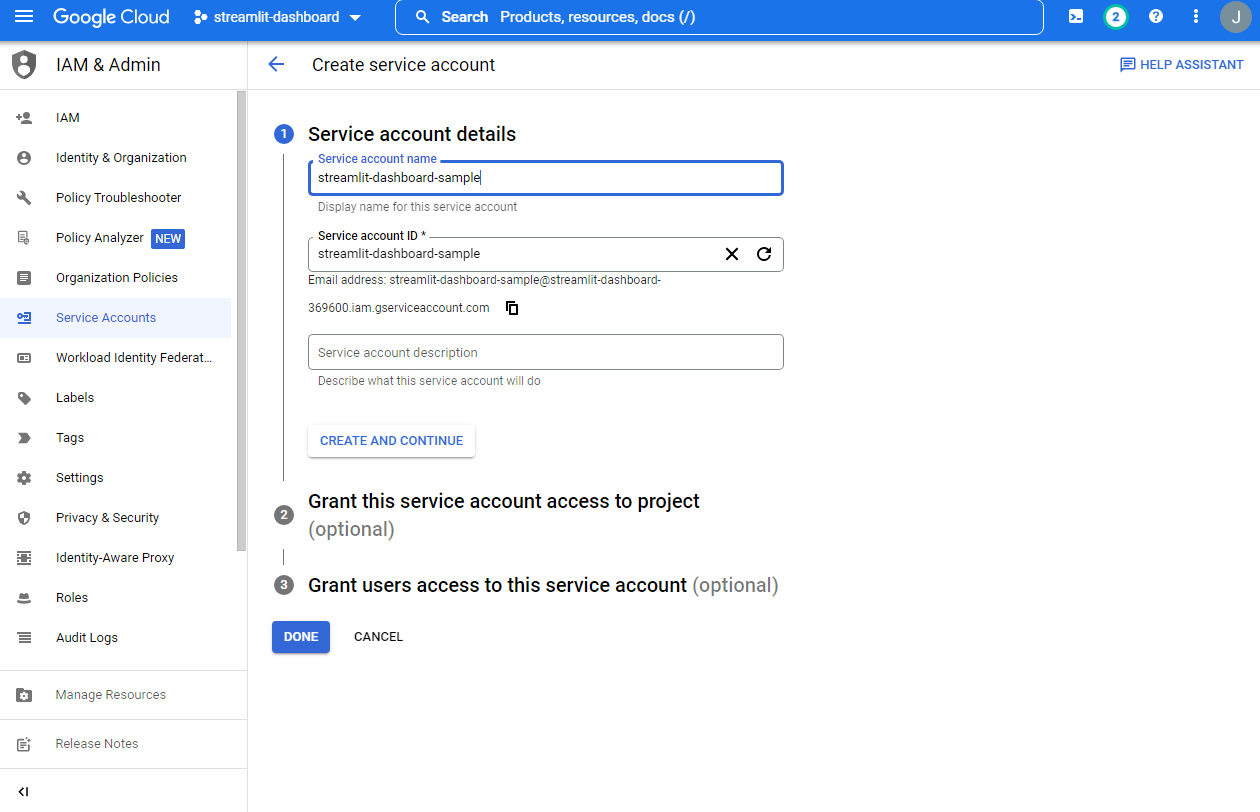
- 서비스 계정 이름은 각자 정한다. 필자는 lgu6th-bq-loader로 명명했다.
- 서비스계정 ID는 이메일 주소 ID를 사용한다.
- 만들고 계속하기 버튼을 클릭한다.
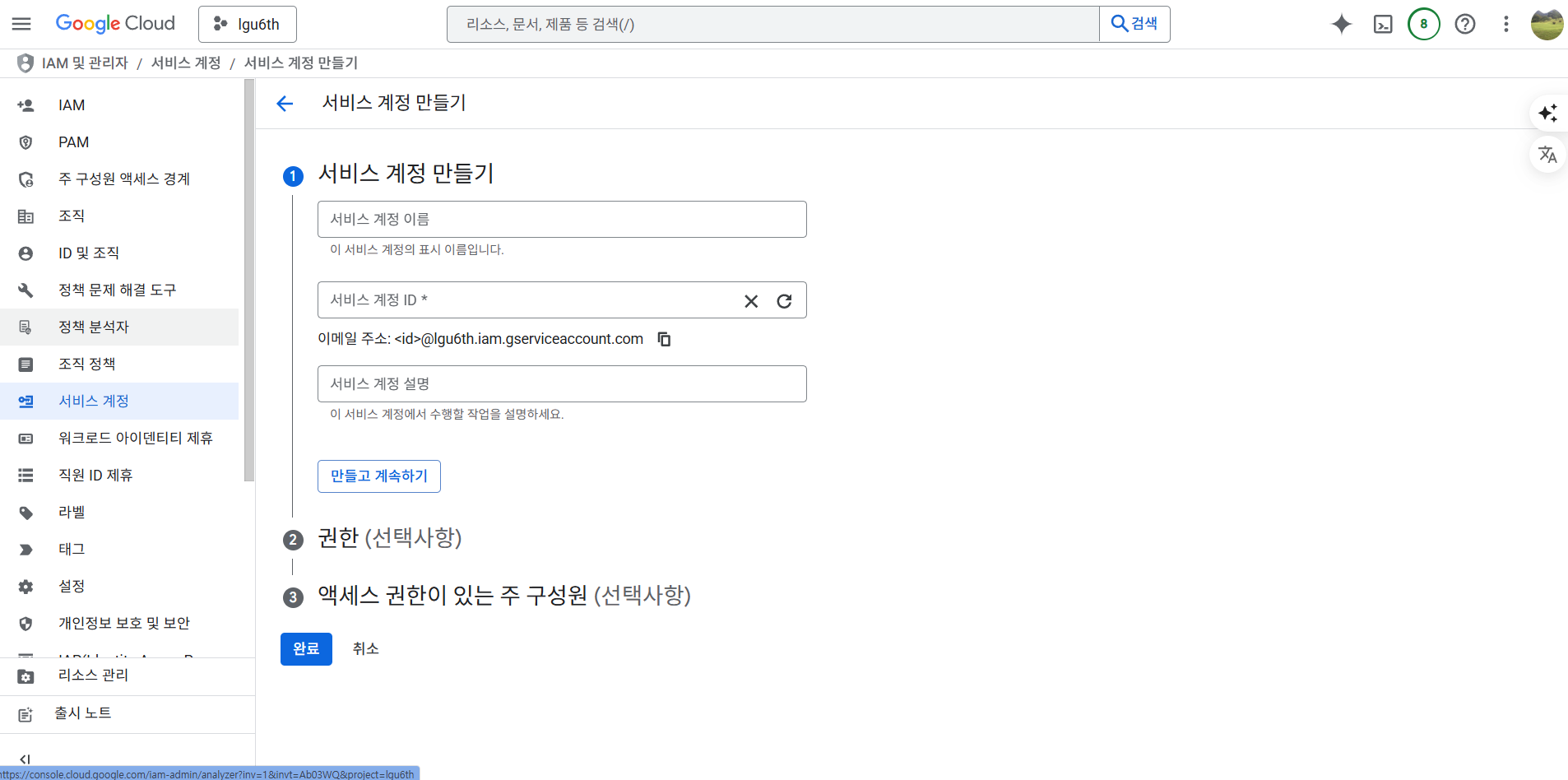
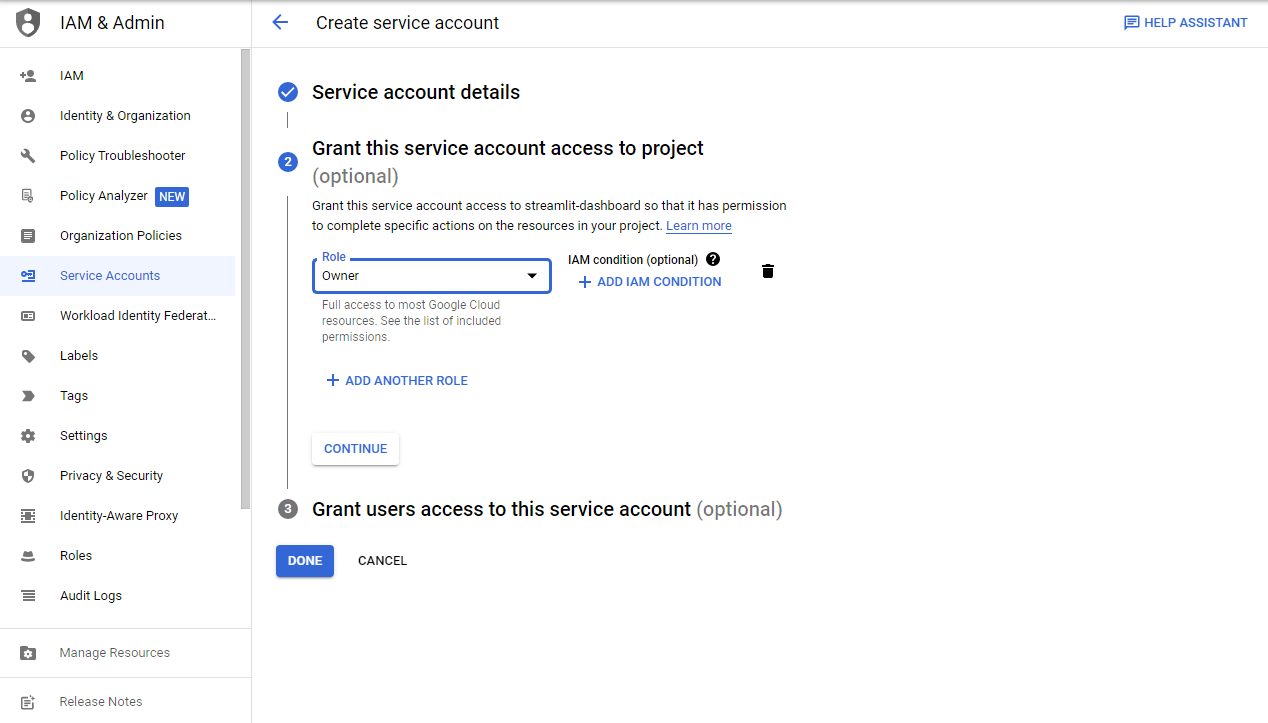
- 권한을 부여한다. BigQuery 관리자를 선택한다.
- 그 후 계속 버튼을 클릭한다.
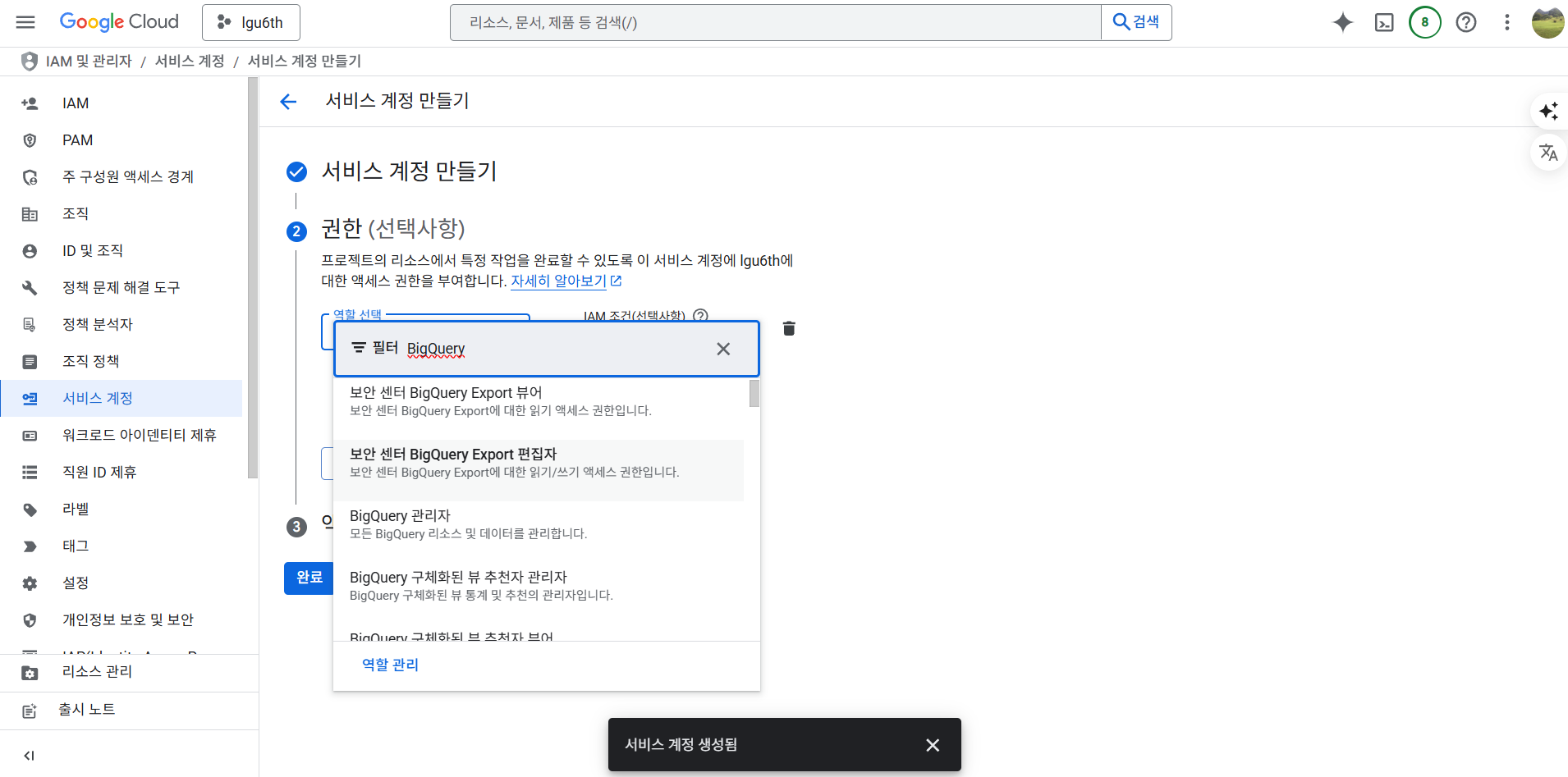
- 그 후 완료 버튼을 클릭한다.
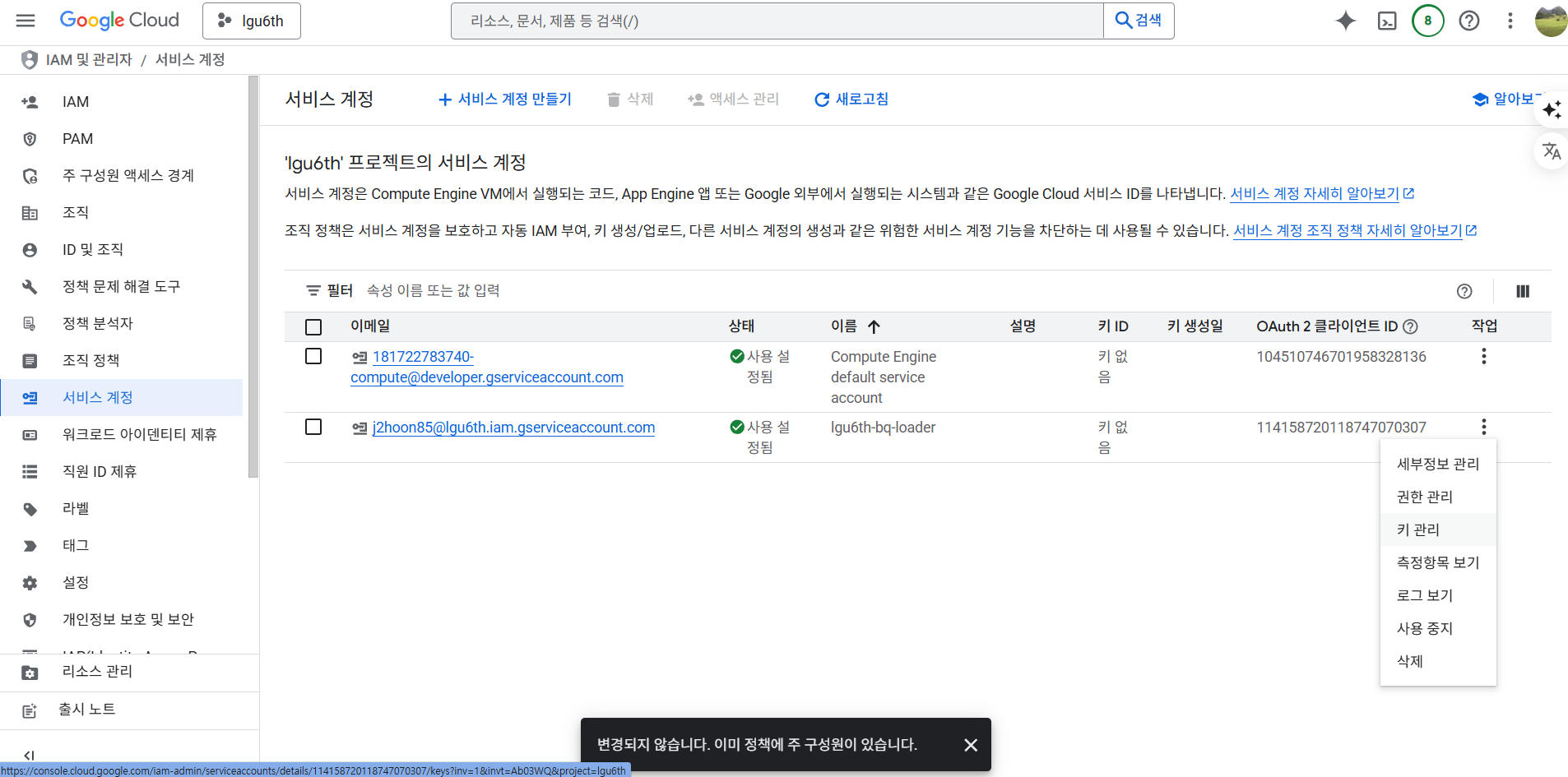
서비스 키 다운로드
- 다음과 같은 화면에서 키 관리 버튼을 클릭한다.