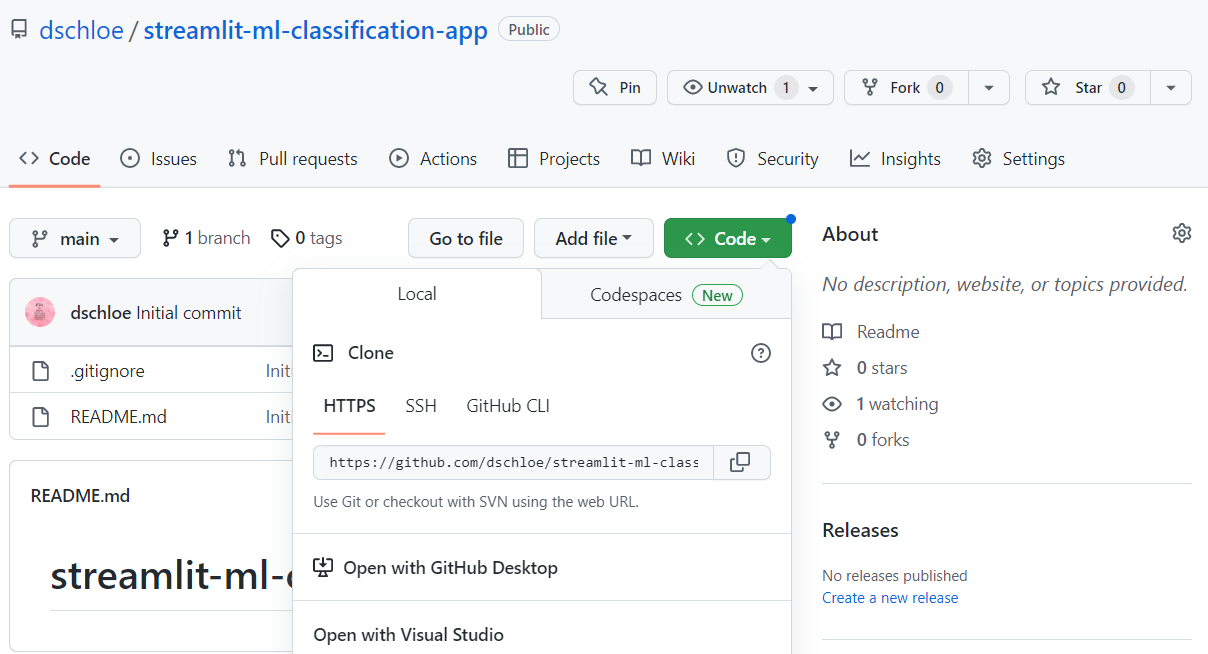
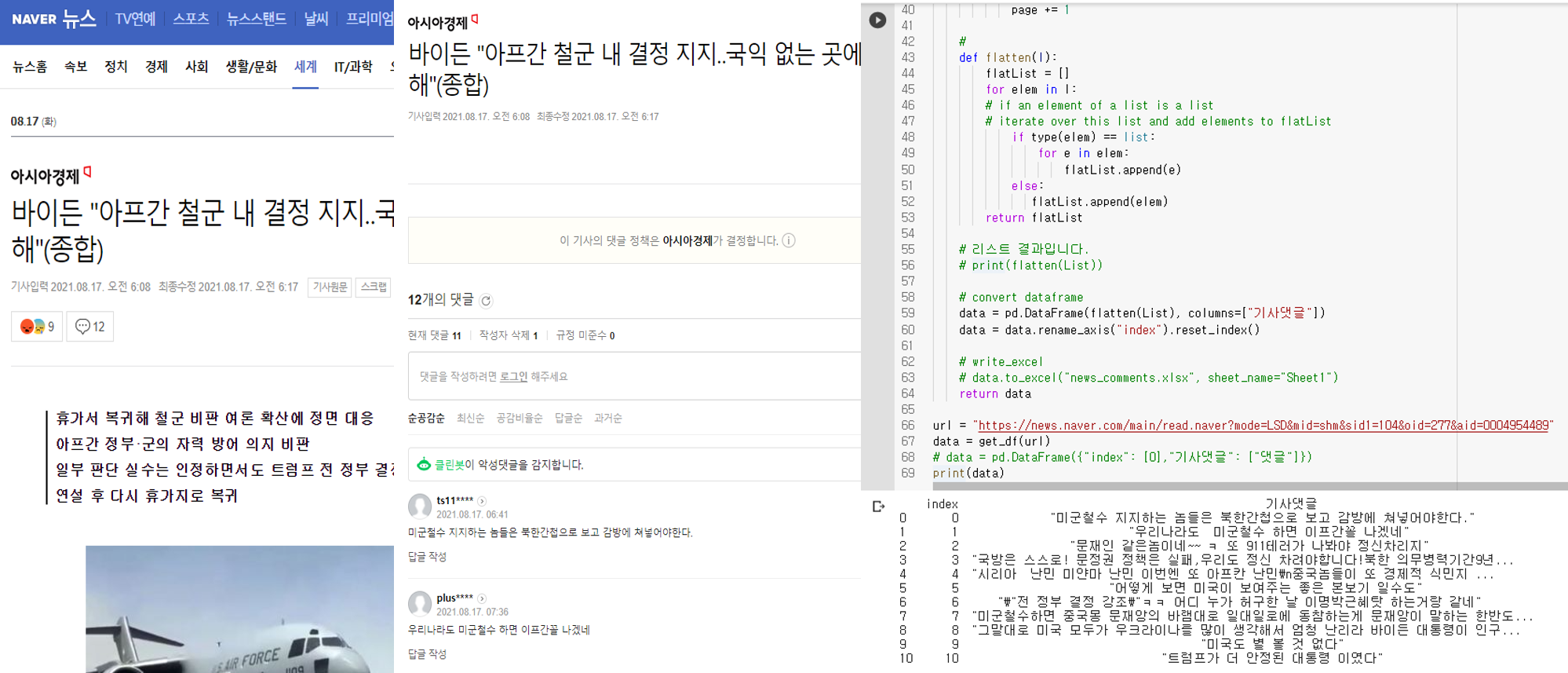
개요
Windows와 Virtualenv를 활용하여 빠르게 App 배포를 해본다.
1. 프로그램 다운로드
C:\Program Files\heroku\bin
- Heroku가 제대로 환경설정이 되어 있는지 확인하려면, 터미널에서 다음 명령어를 입력해 확인한다.
$ heroku -v
heroku/7.53.0 win32-x64 node-v12.21.0
(base)
2. Getting Started
$ heroku login
heroku: Press any key to open up the browser to login or q to exit:
Opening browser to https://cli-auth.heroku.com/auth/cli/browser/93982084-f22f-4a6b-b347-94f1aa4b6b47?requestor=SFMyNTY.g2gDbQAAAA4xMTIuMTQ0LjIyOC43Nm4GACiKMnR9AWIAAVGA.j9hng63oLOpCVOcHcWyOYDqT4s11jMHDtEesGw5xUD4
heroku: Waiting for login...
Logging in... done
Logged in as your_email@gmail.com
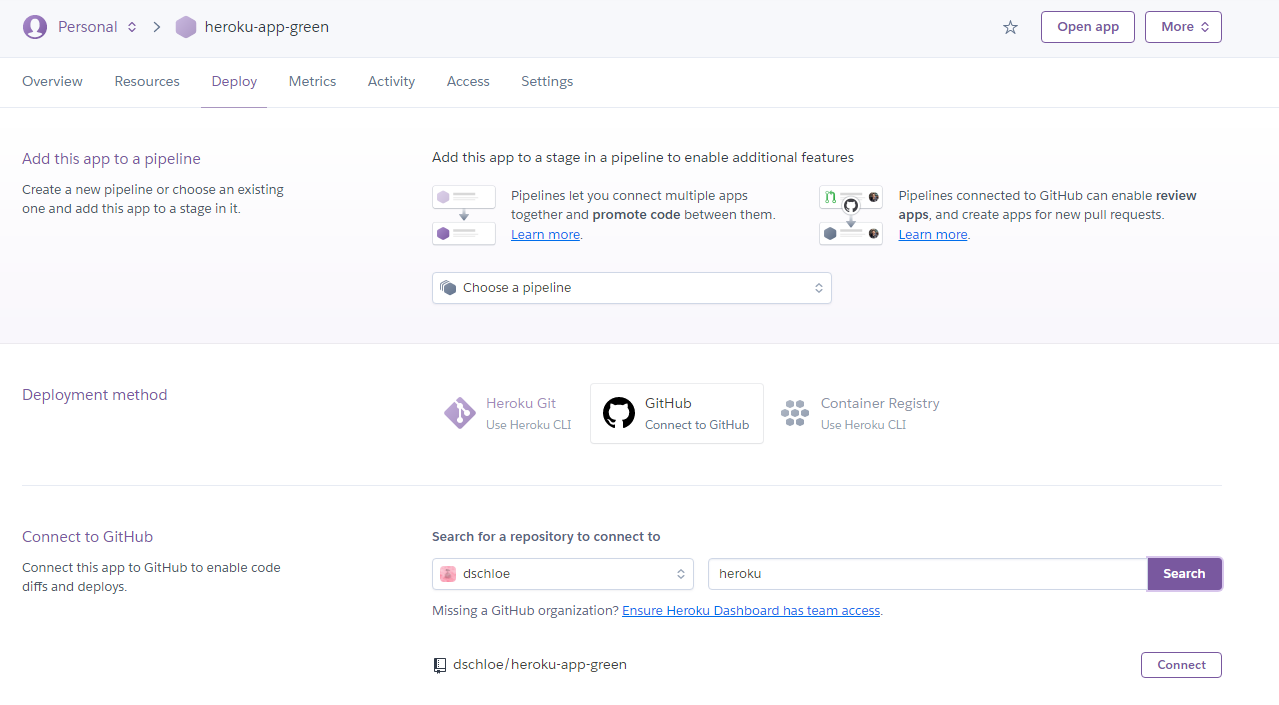
- Github Repo를 생성하고, git clone 으로 바탕화면(또는 적정한 곳)에 Repo를 내려 받는다.
$ git clone https://github.com/your_name/heroku-app-green.git
- heroku_app 경로에서 다음과 같이 실행한다.
- 이 때, 프로젝트 폴더명, github repo 이름, heroku 이름이 동일해야 한다.
- 또 한가지 주의해야 할 점은 name 방식이다. 무료 방식이기 때문에, 타 사용자가 해당 주소를 사용하고 있다면, 쓸수 없다. 또한, heroku_app 과 같은 형식도 되지 않는다.
- 아래는 heroku app 생성 실패 내역이다.
$ heroku create heroku-app
» Warning: heroku update available from 7.53.0 to 7.59.2.
Creating heroku-app... !
! Name heroku-app is already taken
- 정상적으로 설치가 완료되면 다음과 같이 뜬다.
$ heroku create heroku-app-green
» Warning: heroku update available from 7.53.0 to 7.59.2.
Creating heroku-app-green... done
https://heroku-app-green.herokuapp.com/ | https://git.heroku.com/heroku-app-green.git
(base)
$ heroku login
heroku: Press any key to open up the browser to login or q to exit:
Opening browser to https://cli-auth.heroku.com/auth/cli/browser/9320abcd-b8c6-406d-9198-ca14d1e59a26?requestor=SFMyNTY.g2gDbQAAAA4yMjEuMTU3LjM3LjIxNm4GAGgtTBB7AWIAAVGA.GlyVc8jbyiW6NG0MVzCS0bOjtzBWvYRfjB9-gnkQaoQ
Logging in... done
Logged in as your_email_address
- 이제 마지막으로 heroku app에 repository를 생성한다.
$ heroku git:remote -a your_app
» Warning: heroku update available from 7.53.0 to 7.59.2.
set git remote heroku to https://git.heroku.com/heroku-app-green.git
heroku-app-green 이 생긴 것을 확인할 수 있다.