Python 통계 - 비모수 통계
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

분포에 대한 가정을 만족 못할 시의 문제점
- 1종 오류의 값이 커지거나, 분석 결과 자체에 대한 신뢰성이 떨어짐
- 모수 통계 분석 적용 못할 시, 비모수 통계 분석 활용
(1) 언제 적용할까?
- 분포 가정 불만족 (예: 정규분포 아님)
- 분석기법의 전제조건 불만족 (예: 다중공선성)
- 표본 수 불만족 (예: 설문조사 20개)
- 데이터 척도 단순화 (예: 명목 또는 서열 척도로만 측정)
(2) 비모수 통계분석 유형
- 비모수 통계분석의 유형은 아래와 같다. (p. 357)
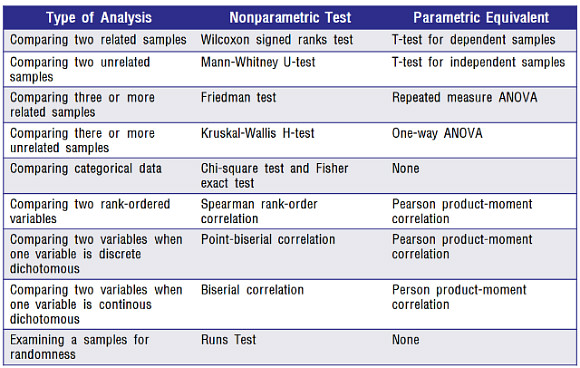
통계분석 실습 - 적합도 검정
(1) 적합도 검정: RUN 검정
- 가정된 확률이 정해져 있는 경우, 예) 제품의 A등급(6), B등급(3), C등급(1)
- 적합도 검정 예시
- 키워드: 측정도수 & 기대도수, RUN 검정
- 비모수 통계는 반대로, 표본의 배열이 무작위로 구성되어 있는지 검정
- (교재, p. 357)
- 마케팅 행사가 공정하게 이루어졌는지 RUN 검정 실시
- 가설검정
- 귀무가설: 멤버십 소지 고객과 비소지 고객의 방문은 무작위로 이루어짐
- 연구가설: 멤버십 소지 고객과 비소지 고객의 방문은 무작위로 이루어지지 않음
from statsmodels.sandbox.stats.runs import Runs
import numpy as np
x = [1,0,0,0,0,1,1,1,1,0,0,0,0,1,1,0,0,0,0,0]
x = np.array(x)
Runs(x).runs_test()
(-1.8277470669267506, 0.06758752074917526)
- z값의 공식은 (RUN의 개수 - RUN의 평균) + 0.5 / RUN의 표준편차 (p.358) 참조
- 평균 및 표준편차를 구하는 방식은 모수의 방식과 다르다 (주의)
- -1.8은 z값을 의미하고, p 값은 0.067로 도출됨으로 유의수준 0.1 수준에서 유의하다.
- 즉, 연구가설을 채택하는데, 이 말의 함의는 공정하게 이루어지지 않았음을 의미
(2) Kolmogorov-Smirnov 검정
표본의 분포가 가정한 분포와 적합한지 검정 $$D_{n} = max|F_{n}(x) - F_{0}(x)$$