개요
- 간단하게 Spark Tutorial을 활용하여 Web UI를 가동한다.
Spark Submit을 활용한다.
파이썬 가상환경
- 파이썬 가상환경을 작성한다. (필자의 경로는 pyskt_tutorial)
$ pwd
/mnt/c/hadoop/pyskt_tutorial
evan@evan:/mnt/c/hadoop/pyskt_tutorial$ virtualenv venv
evan@evan:/mnt/c/hadoop/pyskt_tutorial$ source venv/bin/activate
(venv) evan@evan:/mnt/c/hadoop/pyskt_tutorial$
PySpark 설치
(venv) evan@evan:/mnt/c/hadoop/pyskt_tutorial$ pip install pyspark
Requirement already satisfied: pyspark in ./venv/lib/python3.8/site-packages (3.2.1)
Requirement already satisfied: py4j==0.10.9.3 in ./venv/lib/python3.8/site-packages (from pyspark) (0.10.9.3)
데이터 생성
- 가상의 데이터를 생성한다.
- 소스파일과 구분 위해 data 폴더를 만든 후, 마크다운 파일을 하나 만들 것이다.
(venv) evan@evan:/mnt/c/hadoop/pyskt_tutorial$ mkdir data && cd data
(venv) evan@evan:/mnt/c/hadoop/pyskt_tutorial/data$ vi README.md
This program just counts the number of lines containing ‘a’ and the number containing ‘b’ in a text file. Note that you’ll need to replace YOUR_SPARK_HOME with the location where Spark is installed. As with the Scala and Java examples, we use a SparkSession to create Datasets. For applications that use custom classes or third-party libraries, we can also add code dependencies to spark-submit through its --py-files argument by packaging them into a .zip file (see spark-submit --help for details). SimpleApp is simple enough that we do not need to specify any code dependencies.
We can run this application using the bin/spark-submit script:
SimpleApp.py 작성
- 다음과 같은 파일을 작성한다.
- 구체적인 코드 설명은 생략한다.
- 중요한 코드 중 하나는 input( ) 이다. 사용자가 입력을 하지 않으면 spark 세션은 계속 열린상태로 남게 된다. (일종의 Trick)
from pyspark.sql import SparkSession
logFile = "data/README.md" # Should be some file on your system
spark = SparkSession.builder.appName("SimpleApp").getOrCreate()
logData = spark.read.text(logFile).cache()
numAs = logData.filter(logData.value.contains('a')).count()
numBs = logData.filter(logData.value.contains('b')).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
input("Typing....")
spark.stop()
Spark-Submit 제출
- 여기가 매우 중요한 파트이다.
- 보통
bin/spark-submitscript라 부르기도 한다.
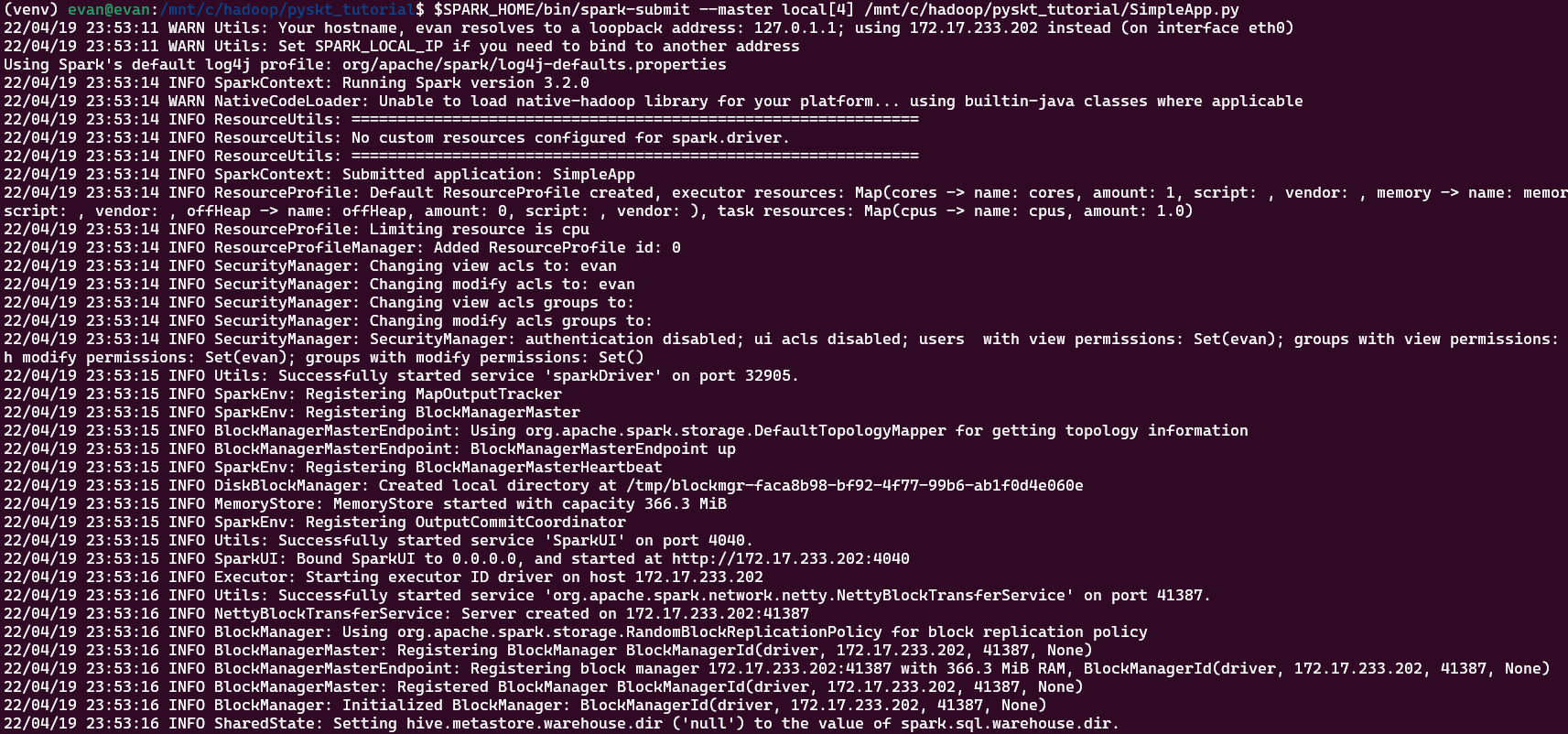
(venv) evan@evan:/mnt/c/hadoop/pyskt_tutorial$ $SPARK_HOME/bin/spark-submit --master local[4] /mnt/c/hadoop/pyskt_tutorial/SimpleApp.py
- 실행하면 아래와 같은 메시지가 뜰 것이다. 이 때, 주소를 복사한다.
- Using 172.17.233.202 주소를 복사한다. (이는 각 컴퓨터마다 다를 것이다!)