GROUP BY 1의 의미와 사용법 예제
개요
- GROUP BY 1의 구체적인 의미에 대해 파악을 한다.
데이터 개요
- 주어진 데이터는 아래와 같다.
- 이 데이터는 미국의 과거 및 현재 국회의원 데이터셋을 사용한다.
SELECT * FROM legislators_terms;
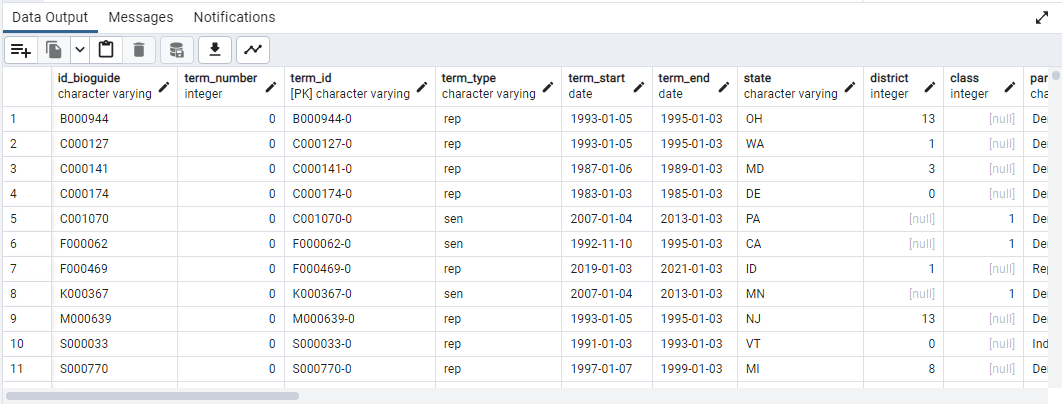
쿼리 예제
- 다음 쿼리는 리텐션을 구하는 쿼리를 작성하기 위해 작성했다.
- 먼저, 각 의원이 첫 임기를 시작한 날짜를 first_term으로 정의한다.
SELECT
id_bioguide
, MIN(term_start) AS first_term
FROM legislators_terms
GROUP BY 1;
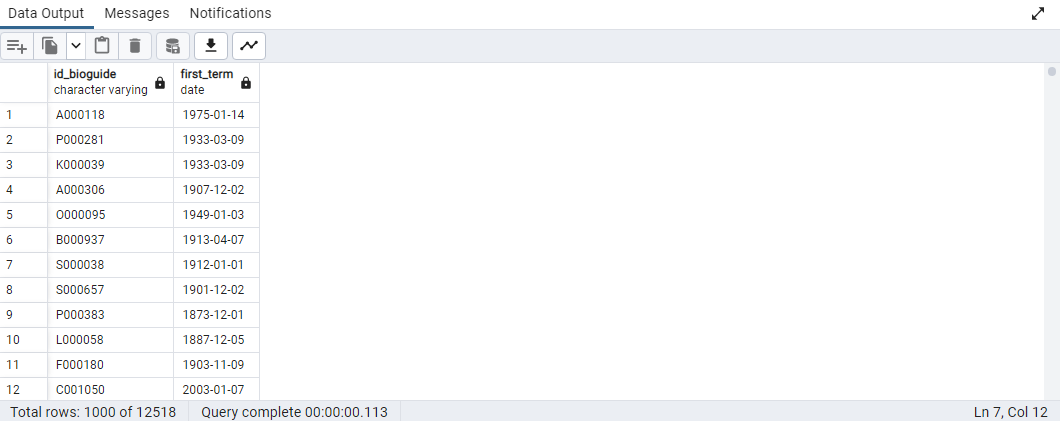
GROUP BY 1대신에GROUP BY id_bioguide로 변경하여 코드를 작성해본다.- 당연한 말이지만, 결과는 동일하다.
SELECT
id_bioguide
, MIN(term_start) AS first_term
FROM legislators_terms
GROUP BY id_bioguide;
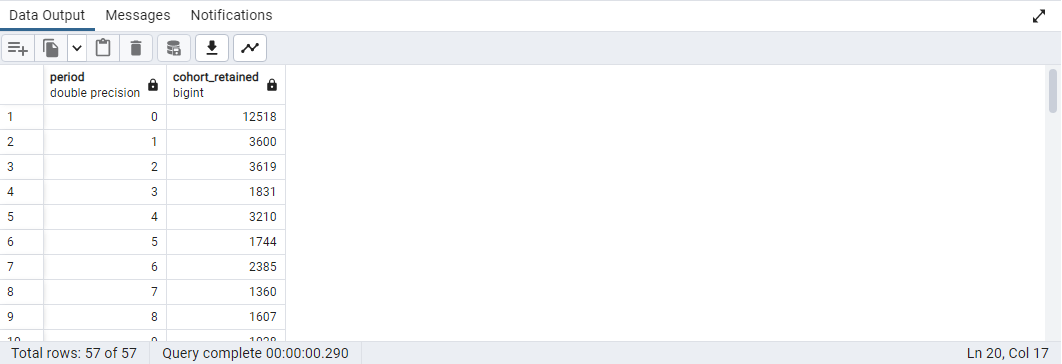
- 이번에는 연도를 period으로 변환하여 각 구간마다 재임 중인 의원 수를 구하도록 한다.
SELECT
date_part('year', AGE(b.term_start, a.first_term)) AS period
, COUNT(DISTINCT a.id_bioguide) AS cohort_retained
FROM (
SELECT
id_bioguide
, MIN(term_start) AS first_term
FROM legislators_terms
GROUP BY id_bioguide
) a
JOIN legislators_terms b ON a.id_bioguide = b.id_bioguide
GROUP BY period;
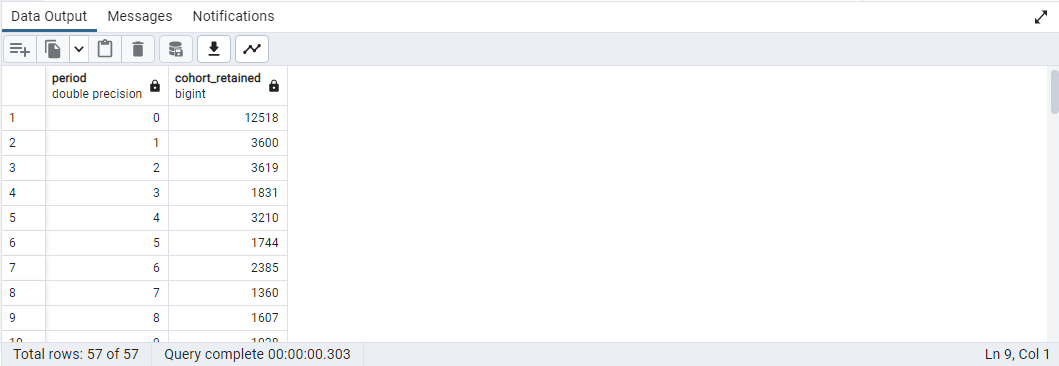
- 위 쿼리에서
GROUP BY코드의컬럼명대신, 1로 변경하여 실행한다.- 결과는 동일하다.
SELECT
date_part('year', AGE(b.term_start, a.first_term)) AS period
, COUNT(DISTINCT a.id_bioguide) AS cohort_retained
FROM (
SELECT
id_bioguide
, MIN(term_start) AS first_term
FROM legislators_terms
GROUP BY 1
) a
JOIN legislators_terms b ON a.id_bioguide = b.id_bioguide
GROUP BY 1;
GROUP BY 1이 의미하는 것은 무엇이며, 왜 사용할까?
- 기본적으로 GROUP BY 1이 의미하는 것은 SELECT 절 이하 첫번째 컬럼을 의미한다.
- 1을 사용하는 가장 큰 이유는 코드 에러를 방지하기 위한 목적이 있다. 서브쿼리 절의 GROUP BY와 메인 쿼리의 GROUP BY절이 사용하는 컬럼명은 다르다. 그런데, 코드가 길어지면
id_bioguide를 연속해서 사용할 가능성이 있다. 또한 SELECT 절 이하 코드가 매우 길어지게 될 경우, GROUP BY를 동시에 사용해야 하는데, 그럴 경우 불필요하게 코드가 길어져 가독성을 해치게 될 수도 있기 때문에 종종 사용한다.
FROM chatGPT
- chatGPT 에서 답을 찾아 올린다. (신기해서 올림)
- 질의는 아래와 같다.
why use group by 1 in SQL statement
In an SQL
GROUP BYclause, theGROUP BYexpression specifies the columns or expressions that the SELECT statement should group the result set by. If you use the expressionGROUP BY 1, this means that the result set will be grouped by the first column in theSELECTstatement’s list of columns.Here is an example of using
GROUP BY 1in aSELECTstatement:
SELECT col1, SUM(col2)
FROM table
GROUP BY 1
This
SELECTstatement will group the result set by the values in thecol1column and compute the sum of the values in thecol2column for each group. TheGROUP BY 1expression is used to specify that the result set should be grouped by the values in the first column in theSELECTlist, which iscol1.Using
GROUP BY 1can be useful when you want to group the result set by the first column in theSELECTlist, but you don’t want to have to specify the name of the column. This can make theSELECTstatement easier to read and understand, especially if the column names are long or complex.It’s important to note that the use of
GROUP BY 1is not standard SQL and may not be supported by all database systems. In general, it’s a good idea to use column names rather than column positions when specifying theGROUP BYclause, as this can make theSELECTstatement more readable and easier to maintain.
