SPSS 반복측정 분산분석
Page content
반복측정 분산분석
- comercial_ratings.csv 데이터 불러오기
데이터탐색
- 분석 - 기술통계량 - 데이터탐색
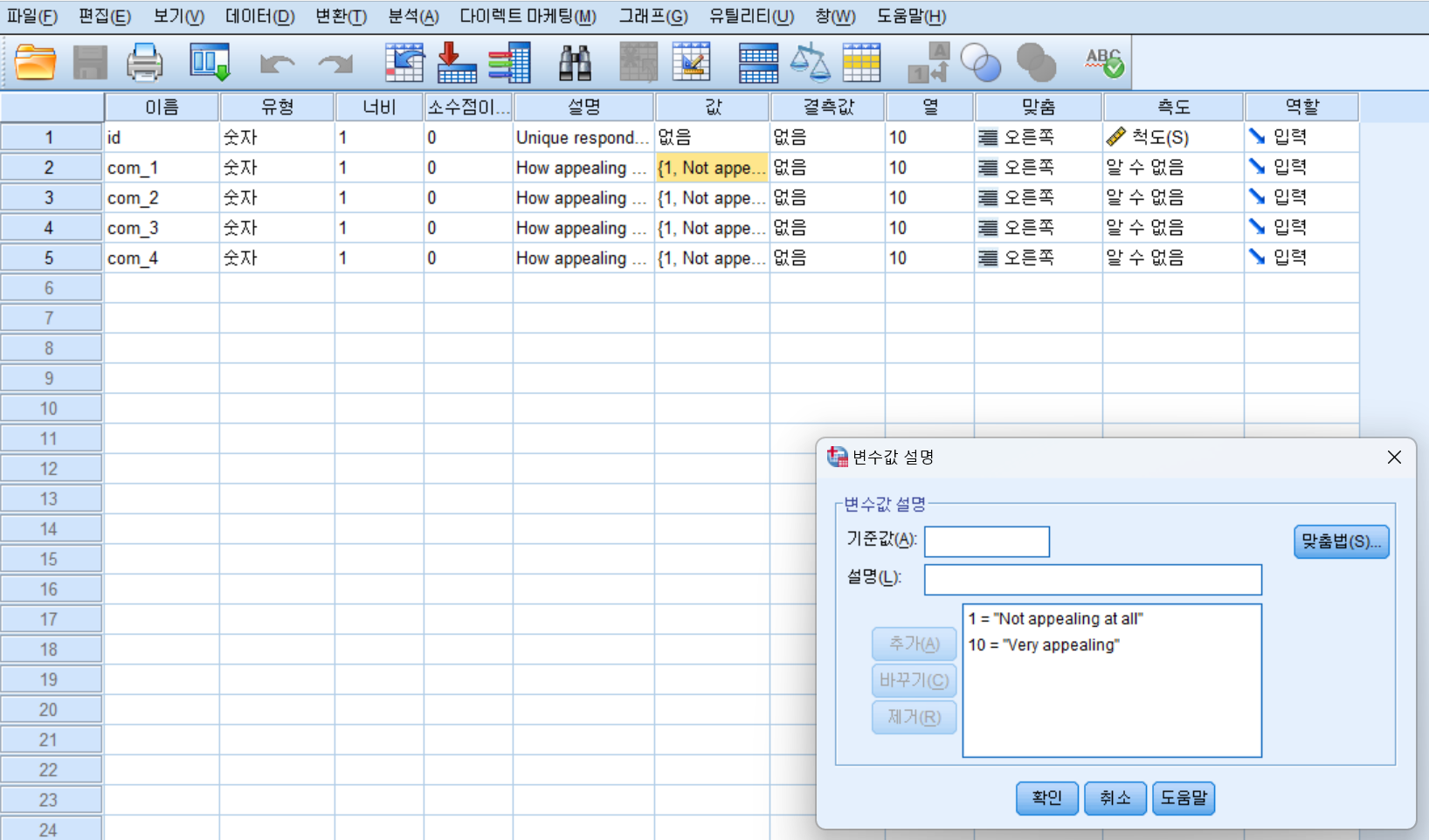
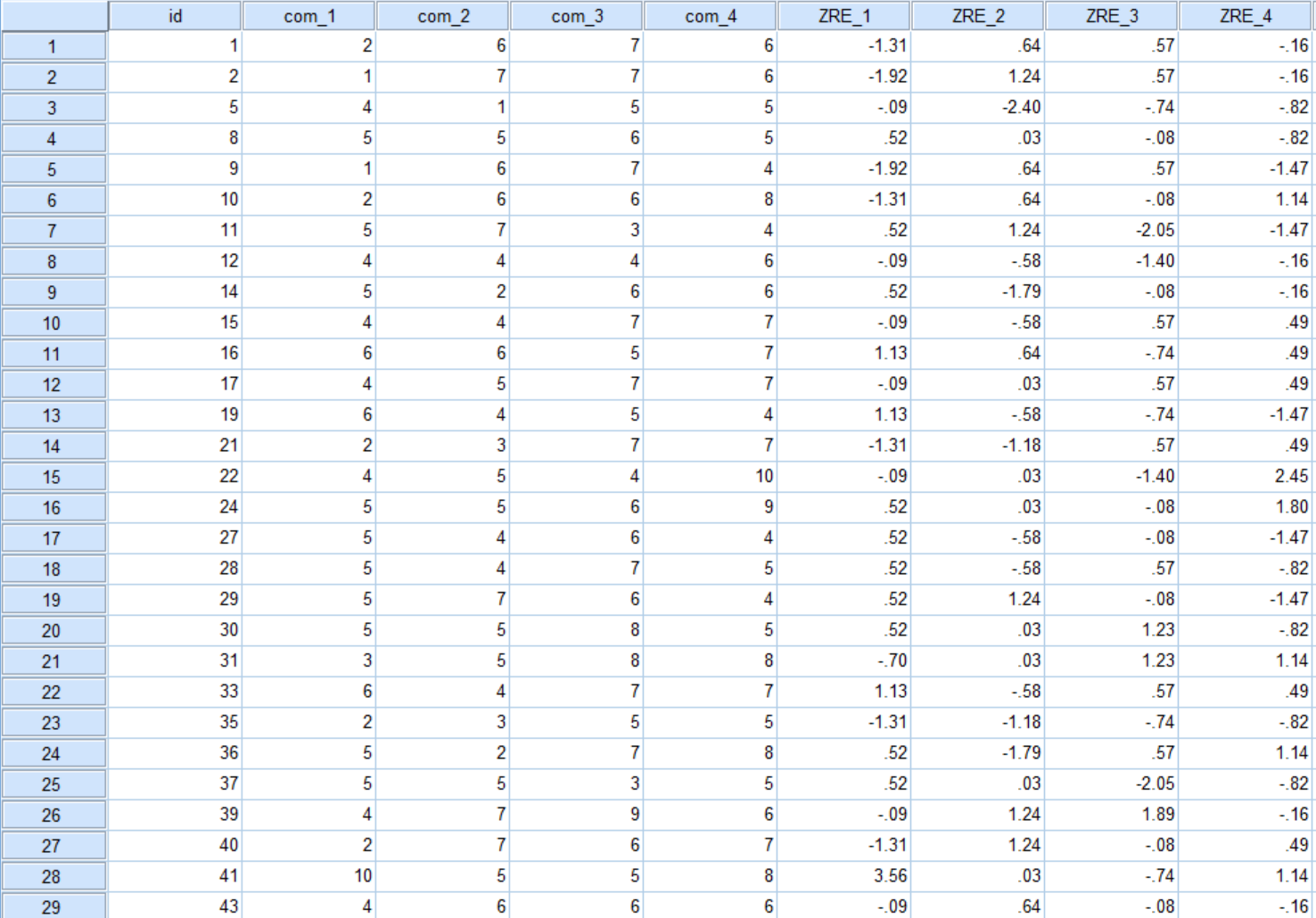
- 아래와 같이 4개의 설문조사 데이터는 종속변수로 넣는다.
- 확인 버튼을 누른다.
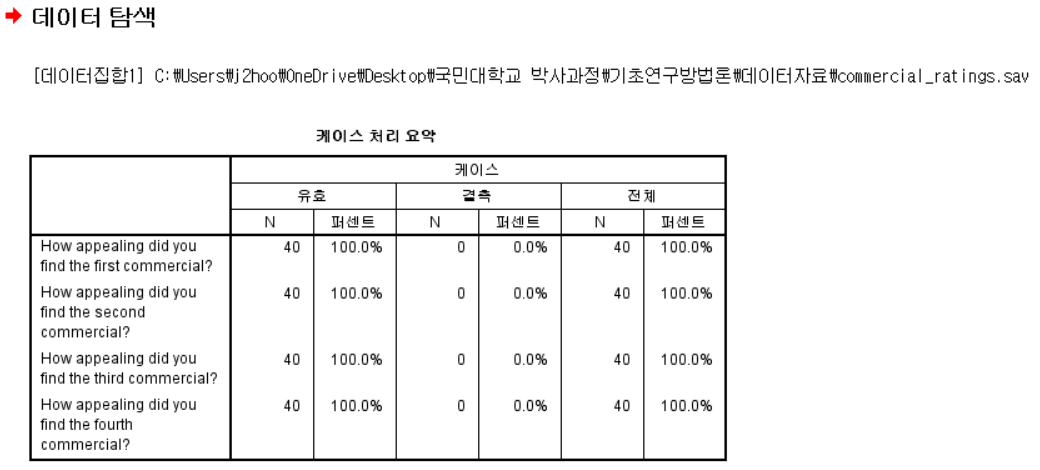
- 데이터가 40개가 넘으므로 정규성 검토를 할 필요가 없음
만약에 정규성 분포를 한다고 하면 어떻게 할까?
- 일반선형모형 - 반복측정’
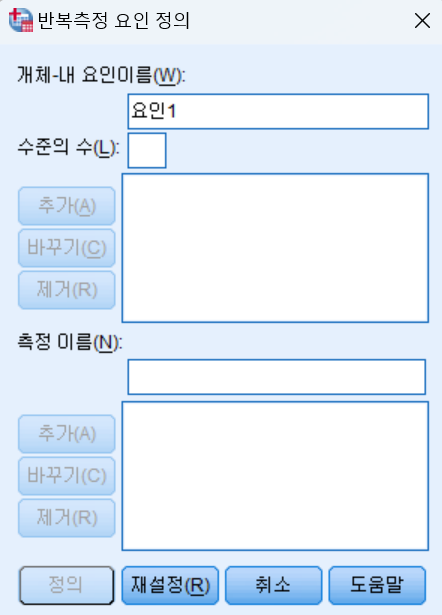
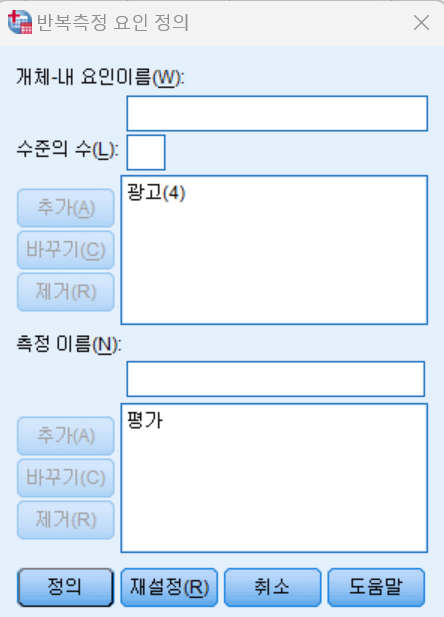
- 여기에서 수준의 수를 정의하는 것이 1차 핵심이다.
- 총 광고의 종류는 4개이므로 요인의 수는 4가 된다.
- 요인의 이름은 문맥에 맞게 저장한다
- 측정 이름도 결과에 맞게 저장한다.
- 예) 매력도, 평가 등
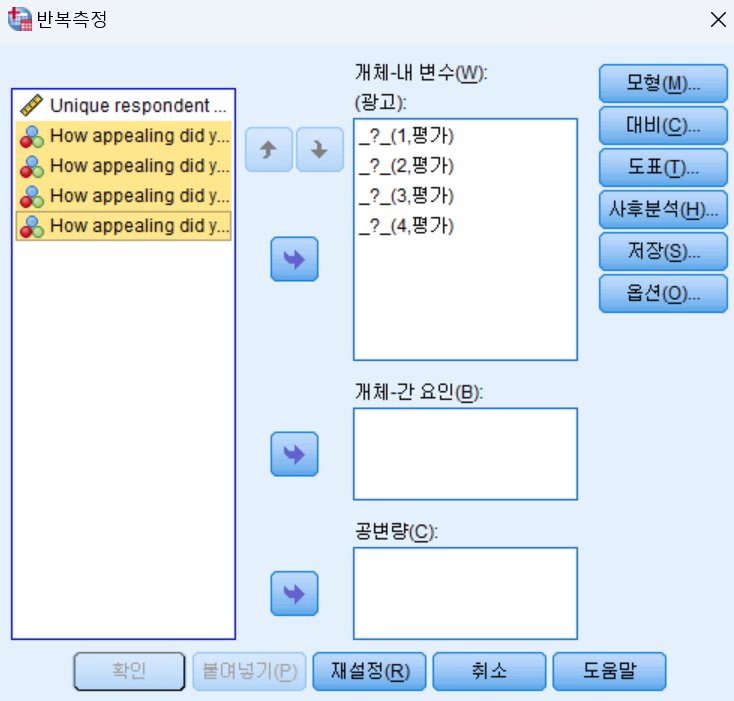
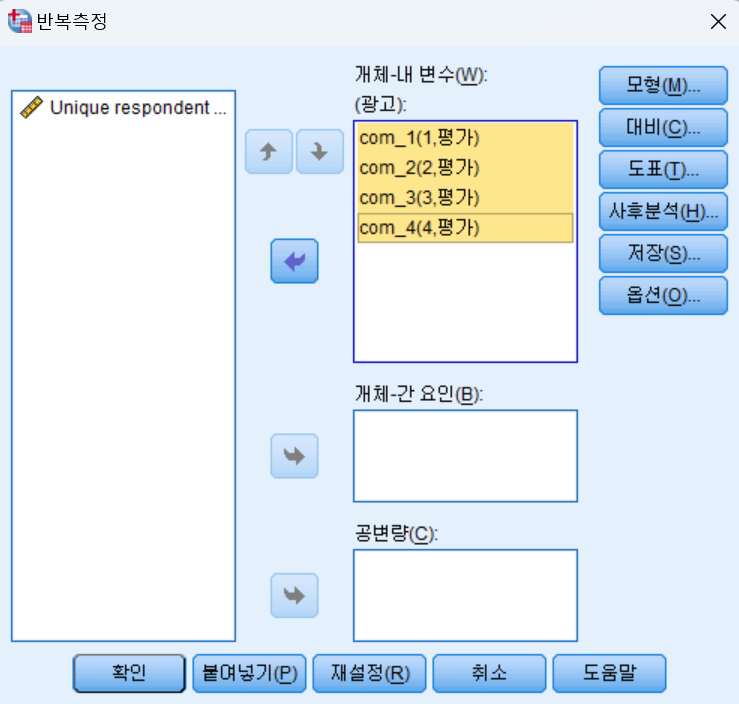
- 1차 준비는 나온 것이다. 그런데, 개체-내 변수가 정의되어 있지 않다. 이 때, 왼쪽 설문조사 항목등을 모두 왼쪽에서 오른쪽으로 보내면 된다.
- 저장 버튼을 누른 후, 잔차-표준화나 클릭 후 계속 버튼을 누르고 확인 버튼을 누른다.
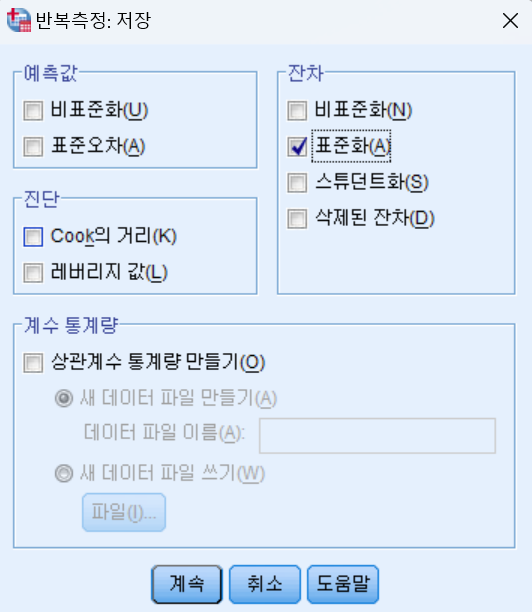
- ZRE_1, ZRE_2, ZRE_3, ZRE_4 결괏값을 확인 후 데이터 탐색을 다시 설정한다.
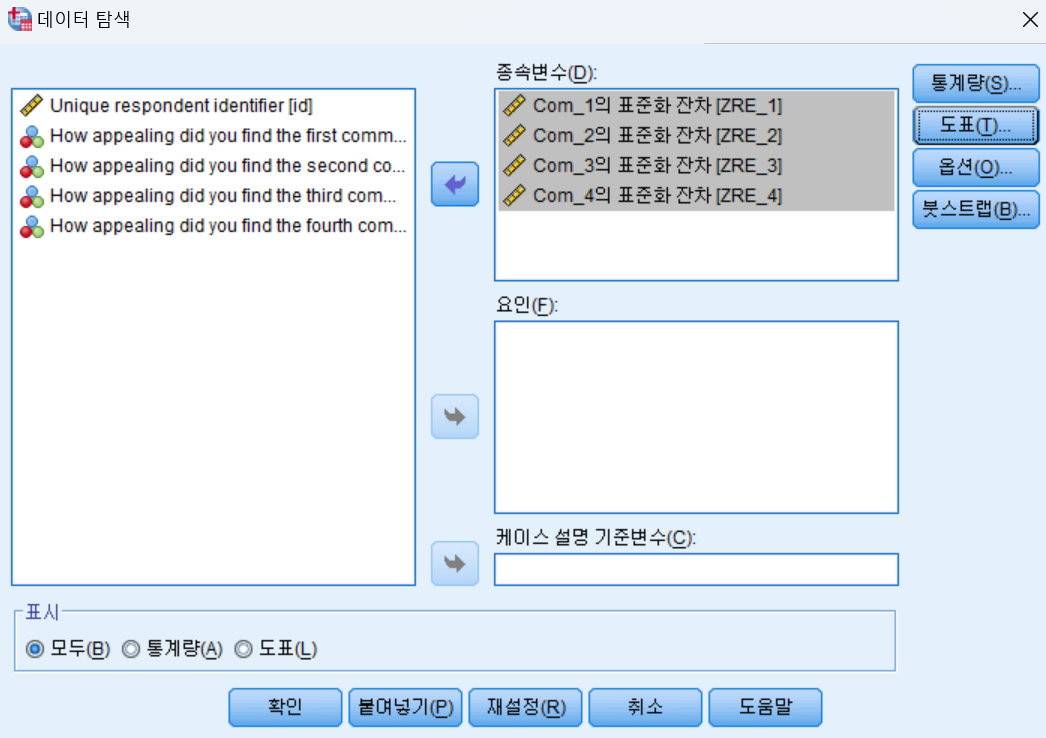
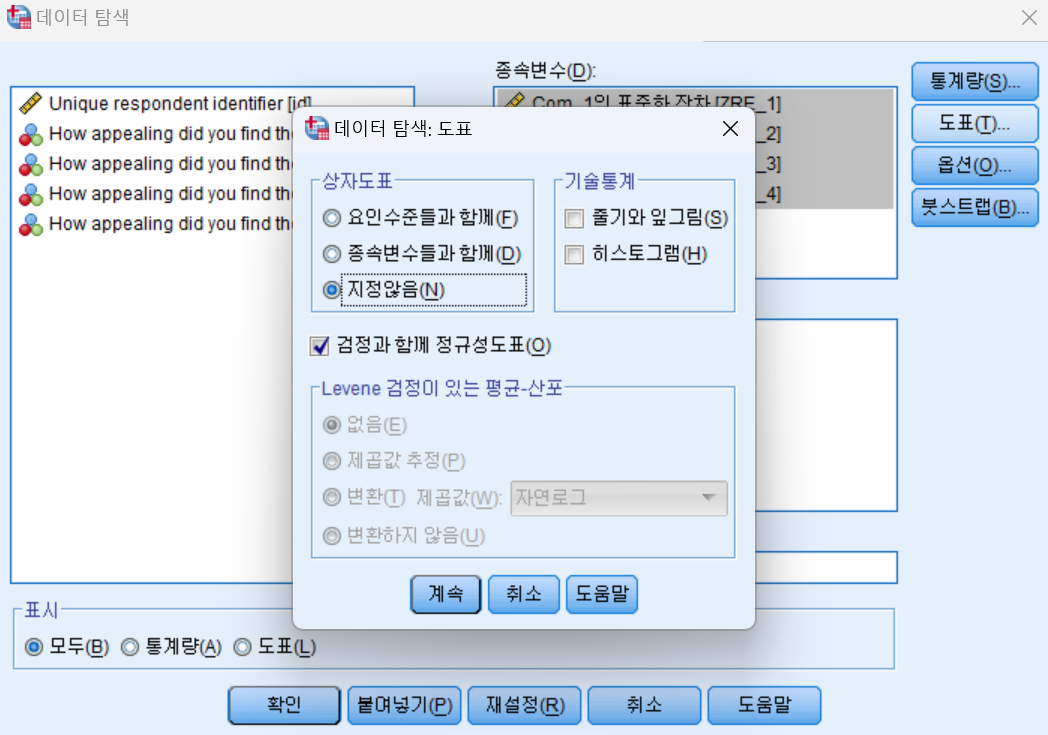
- 도표를 클릭 후, 아래와 같이 설정하고 결과를 확인한다.
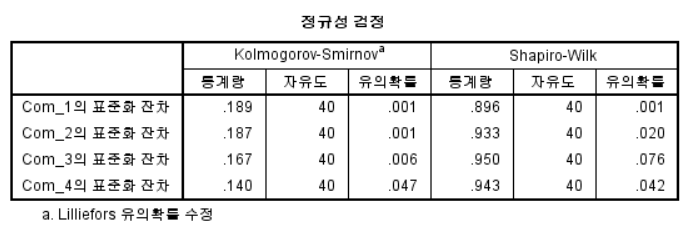
- 결과만 놓고 보면 정규성 검정이 의심스러울수도 있다. 그러나, 중심극한정리에서 의해 N이 40개 이므로 정규성 검정은 만족하고 진행한다.
반복측정
- 반복측정 - 저장 - 잔차에서 클릭된 표준화는 삭제하고 다시 원상태로 놓는다.
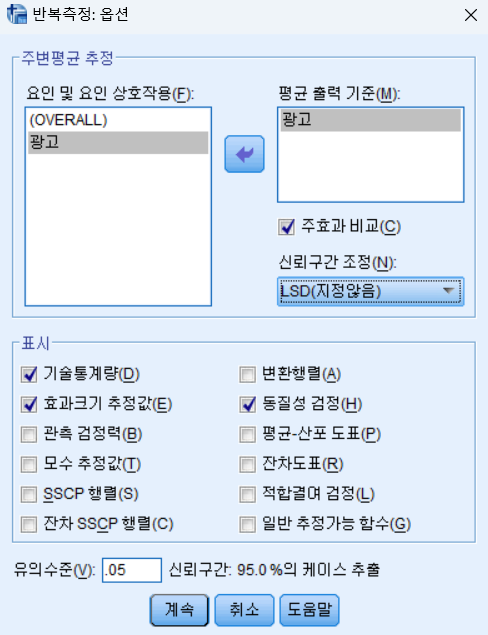
- 옵션 버튼을 누르고, 기술통계량, 효과크기 추정값, 동질성 검정을 누른다.
- 도표에서는 아래와 같이 설정한다.
- 요인 - 수평축 변수 - 추가 버튼을 순차적으로 누른다.
결과 해석
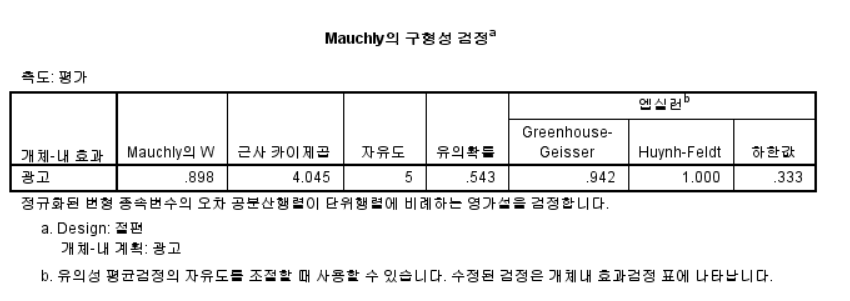
- Mauchly의 구형성 검정을 가장 먼저 해석해야 한다.
-
p값이 0.05보다 크면 구형성 검정을 만족하고, p값이 0.05보다 작으면 구형성 가정을 만족하지 못한다.
- 유의확률이 0.543이므로 개체-내 효과 검정에서 구형성 가정 탭만 확인하도록 한다.
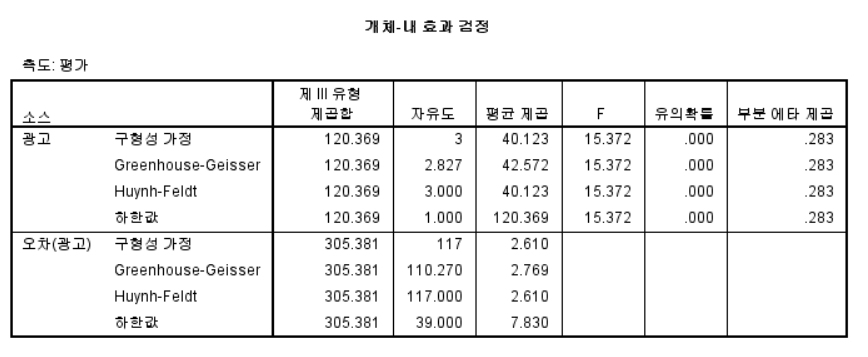
- 만약 유의확률이 0.05 이하면, Greenhouse Geisser, Huynh-Feldt, 하한 값 중 어느 수치를 활용해도 무방한다.
- 광고 유형별로 결과가 다 같지는 않음, 즉 사후검정 활용
- 구형성 가정에서 유의확률이 0.05 이하이기 때문에 사후분석을 진행한다.
- EM 평균을 보는 것이다.
- 만약 EM 평균 버튼이 없는 경우 옵션 탭에서 아래와 같이 설정한다.
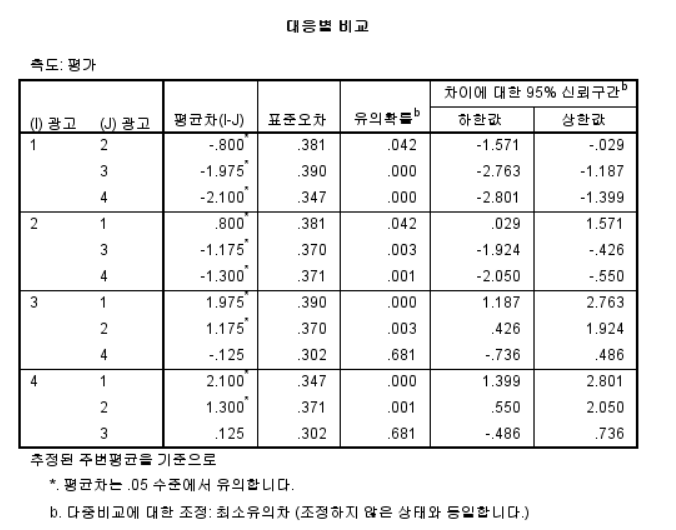
- 위 표에서 *된 표시가 된 것만 확인한다.
