ch 13 - Reliability
Page content
Intro
- PLS-SEM의 분석과정에서 척도(측정변수와 잠재변수)의 신뢰도와 타당도를 확보하는 것은 매우 중요하며, 신뢰도와 타당도가 확보되지 않으면 모델 추정 결과가 의미가 없기 때문임
- 즉, 구조모델의 추정을 실행하려면 사전에 반드시 측정모델에 대한 평가과정을 통해 신뢰도와 타당도 확보 필요
I. 주요 개념
(1) 신뢰도
- 잠재변수의 측정에 있어서 얼마나 일관성이 있는가의 정도 의미
- 검사도구의 일관성을 말하며, 일관성이란 잠재변수를 여러 번에 걸쳐 측정했을 때 매번 같은 결과를 도출할 수 있는 정도.
- 내적 일관성 신뢰(Internal Consistency Reliability)로 평가
(2) 타당도
- 타당도의 기본 정의는 실제 측정하고자 하는 잠재변수를 정확하게 측정하고 있는 정도
- PLS-SEM에서는 집중타당도(
Convergent Validity)와 판별타당도(Discriminant Validity)를 사용한다. - 전자는 하나의 잠재변수를 측정하기 위해 사용되는 척도의 구성항목들 간에 상관관계가 높아야 집중타당도가 있다고 볼 수 있고, 후자는 하나의 잠재변수와 다른 잠재변수간 상관관계가 낮을수록 판별 타당도가 높다고 판단함.
- PLS-SEM에서는 집중타당도(
(3) PLS-SEM 분석 결과의 쳬계적인 평가 단계
- 반영적 측정모델: 내적 일관성 신뢰도, 집중타당도, 판별타당도
- 형성적 측정모델: 집중타당도, 다중공선성, 외부가중치와 외부적재치의 유의성과 적합성
- 구조모델의 평가기준: 다중공선성, 결정계수 $R^2$, 효과크기 $f^2$, 예측적 적합성 $Q^2$, 경로계수의 유의성과 적합성
- PLS-SEM의 평가 단계: 제 1단계는 측정모델(Outer Model)을 평가하는 것이며, 제 2단계는 구조모델(Inner Model)을 평가하는 것이다.
II. 설문조사 데이터 분석
- 이제 설문지를 분석해본다.
- 필수 패키지를 확인한다.
library(readr)
library(dplyr)
library(kableExtra)
library(psy) # 신뢰도
library(corrplot) # 상관계수
library(psychometric) # 타당도
(1) 데이터 수집
- 먼저 수집된 설문조사 데이터를 확인한다.
data <- read_csv('data/thesis_mater.csv') %>%
distinct() %>% # 중복데이터 제거
rename(Position = founder_employee, # 출력을 위한 변수명 정리
Age = age_of_respondent,
Education = Education_Level) %>%
slice(-c(1:10)) %>%
dplyr::select(-c(Firm_Age:Business_Area))
data %>%
head() %>%
kable() %>%
kable_styling("striped") %>%
scroll_box(width = "100%")
| EI_1 | EI_2 | EI_3 | EP_1 | EP_2 | EP_3 | ER_1 | ER_2 | ER_3 | SS_1 | SS_2 | SS_3 | SC_1 | SC_2 | SC_3 | SR_1 | SR_2 | SR_3 | F1 | F2 | F3 | NF1 | NF2 | NF3 | Firm_Age | Firm_Size | WE1 | WE2 | WE3 | gender | founder_employee | age_of_respondent | Education_Level | Business_Area |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 3 | 3 | 4 | 3 | 2 | 4 | 1 | 1 | 3 | 3 | 3 | 3 | 2 | 2 | 1 | 2 | 2 | 3 | 3 | 1 | 3 | 5 years above | Above 15 members | No, I don't have experience | Yes | Yes | Female | Employee | 30-39 | Undergraduate School | Others |
| 5 | 5 | 2 | 3 | 5 | 3 | 4 | 4 | 4 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 2 | 2 | Less than 2 years | Less than 5 members | No, I don't have experience | No | Yes | Male | Employee | Younger than 30 | Undergraduate School | Media and Entertainment |
| 1 | 2 | 2 | 1 | 1 | 2 | 1 | 2 | 1 | 2 | 2 | 1 | 1 | 2 | 2 | 1 | 2 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 5 years above | Less than 5 members | As founder or employee, I have startup experiences more than 3 times | No | Yes | Female | Founder of Company | Younger than 30 | Undergraduate School | Others |
| 3 | 3 | 2 | 1 | 2 | 1 | 2 | 1 | 3 | 2 | 1 | 3 | 1 | 1 | 1 | 2 | 3 | 3 | 3 | 3 | 2 | 3 | 2 | 2 | Less than 2 years | Less than 5 members | No, I don't have experience | Yes | Yes | Male | Employee | Younger than 30 | Undergraduate School | Others |
| 5 | 3 | 5 | 2 | 5 | 4 | 4 | 4 | 4 | 4 | 5 | 4 | 5 | 5 | 5 | 5 | 5 | 5 | 4 | 5 | 4 | 4 | 5 | 5 | 3-4 years | Less than 5 members | As founder or employee, I have startup experiences more than 3 times | No | Yes | Male | Founder of Company | 30-39 | Undergraduate School | Others |
| 1 | 3 | 3 | 1 | 3 | 3 | 2 | 3 | 1 | 4 | 1 | 2 | 3 | 3 | 1 | 2 | 2 | 1 | 1 | 2 | 3 | 1 | 3 | 1 | 5 years above | 5-9 members | As founder or employee, I have startup experience, one time | No | No | Female | Employee | Younger than 30 | Undergraduate School | Others |
(2) 상관관계 확인
- 각 척도(Item)에서의 상관관계를 확인해본다.
M <- cor(data)
corrplot(M, type="upper", order="hclust",
col=RColorBrewer::brewer.pal(n=8, name="RdBu"))

- 전체적으로 상관관계가 양의 상관관계를 나타나고 있는 것으로 확인된다.
(3) 내적 신뢰도: 크론바하 알파
- 크론바하 알파는 내적 일관성 신뢰도에 관한 평가기준 중 하나이며, 0.6~0.9가 일반적인 수용 범위를 나타낸다.
- 0.6 미만: 낮은 신뢰도
- 0.6 이상: 수용 가능한 신뢰도
- 0.7 이상: 바람직한 신뢰도
- 0.8~0.9 이상: 높은 신뢰도
cronbach(data)
## $Alpha
## [1] 0.970241
##
## $N
## [1] 93
- 그러나 위 데이터는 전체 데이터셋에 대한 것을 나타나는 것이다.
조금 더 구체적으로 확인해보자.
result <- psych::alpha(data)
print(result$total)
## raw_alpha std.alpha G6(smc) average_r S/N ase mean
## 0.970241 0.9705169 0.9815482 0.5783387 32.91772 0.004431653 1.990143
## sd median_r
## 0.8575819 0.5683649
- 위 값을 보면, 처음 구했던 값과 동일하게
0.970241과 동일한 것을 확인할 수 있다.- 해석: 문항들의 내적일관성에 기초하여 추정되는 신뢰도 지수의 하나이다.
0.97이라는 점수는 신뢰도가 매우 높다는 것을 의미한다.
- 해석: 문항들의 내적일관성에 기초하여 추정되는 신뢰도 지수의 하나이다.
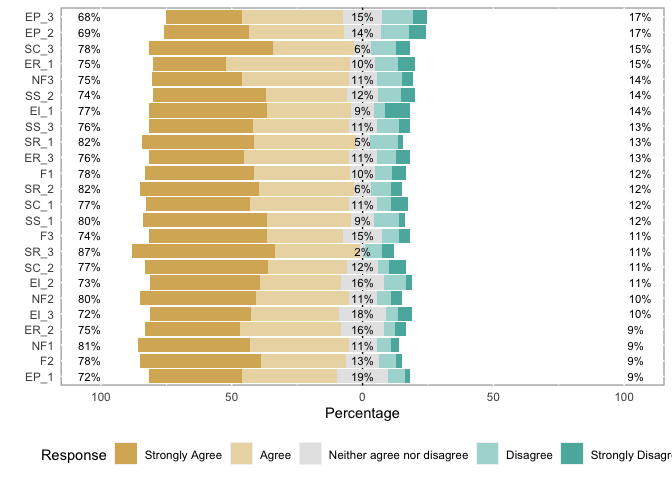
(4) 문항표 시각화
- 문항표에 대한 시각화를 진행해본다.
mylevels <- c("Strongly Agree", "Agree", "Neither agree nor disagree", "Disagree", "Strongly Disagree")
data2 <- lapply(data, factor, labels = mylevels) %>% as.data.frame()
p <- likert(data2)
plot(p)
III. Reference
신건권. (2018). 석박사학위 및 학술논문 작성 중심의 SmartPLS 3.0 구조방정식모델링. 서울: 청람.
