xgboost and kaggle with R
개요
- R 강의를 진행하면서
xgboost를 R로 구현하고 싶었다. kaggle에 있는 데이터를 불러와서 제출까지 가는 과정을 담았으니 입문자들에게 작은 도움이 되기를 바란다.
XGBoost 개요
- 논문 제목 - XGBoost: A Scalable Tree Boosting System
- 논문 게재일: Wed, 9 Mar 2016 01:11:51 UTC (592 KB)
- 논문 저자: Tianqi Chen, Carlos Guestrin
- 논문 소개
Tree boosting is a highly effective and widely used machine learning method. In this paper, we describe a scalable end-to-end tree boosting system called XGBoost, which is used widely by data scientists to achieve state-of-the-art results on many machine learning challenges. We propose a novel sparsity-aware algorithm for sparse data and weighted quantile sketch for approximate tree learning. More importantly, we provide insights on cache access patterns, data compression and sharding to build a scalable tree boosting system. By combining these insights, XGBoost scales beyond billions of examples using far fewer resources than existing systems.
- 효과적인 머신러닝 방법
- 확장가능한 머신러닝 모형
- A novel sparsity-aware algorithm
- Cache access patterns, Data compression and Sharding
- 위 조합을 통해 기존 시스템보다 훨씬 더 적은 리소스를 투입해도 좋은 성과를 낼 수 있도록 구현함.
논문 주요 내용 요약
XGboost는GBM에서 나온 출발한 알고리즘- 논문에 있는 주요 내용을 요약한다.
(1) 과적합 규제
- 표준 GBM의 경우 과적합 규제 기능이 없으나 XGBoost는 자체에 과적합 규제 기능으로 과적합에 좀 더 강한 내구성 가짐.
- The additional regularization term helps to smooth the final learnt weights to avoid over-fitting. Intuitively, the regularized objective will tend to select a model employing simple and predictive functions.
(2) shrinkage and Column Subsampling
- 두 기법 모두 과적합 방지용으로 사용됨
- shrinkage: reduces the influence of each individual tree and leaves space for future trees to improve the model.
- Column Subsampling: 랜덤포레스트에 있는 기법, 변수가 많을 때, 변수의 개수를 지정하면 랜덤하게 변수가 투입됨
- 병렬처리에 적합함
Note: 내용이 정리되는대로 계속 업데이트 한다.
실습 코드
- 우선 패키지부터 설치한다.
library(tidyverse)
library(xgboost)
(1) Kaggle API with R
- 먼저
[Kaggle]에 회원 가입을 한다. - 회원 가입 진행 후,
Kaggle에서kaggle.json파일을 다운로드 받는다.

- 그리고 아래와 같이
kaggle.json을RStudio에 등록한다.
# install.packages("pins")
library(pins)
board_register_kaggle(token = "kaggle.json")
-
pins는 일종의
cache를 이용한 자원 관리 패키지이다.- 원어: Pin remote resources into a local cache to work offline, improve speed and avoid recomputing; discover and share resources in local folders, ‘GitHub’, ‘Kaggle’ or ‘RStudio Connect’. Resources can be anything from ‘CSV’, ‘JSON’, or image files to arbitrary R objects.
-
이 패키지를 이용하면 보다 쉽게
kaggle데이터를 불러올 수 있다.
(2) 데이터 불러오기
- 이제
titanic데이터를 불러오자- 처음
kaggle대회에 참여하는 사람들은 우선Join Competiton버튼을 클릭한다.
- 처음
- 소스코드로 확인해본다.
pin_find("titanic", board="kaggle")
## # A tibble: 21 x 4
## name description type board
## <chr> <chr> <chr> <chr>
## 1 abhinavralhan/titanic titanic files kagg…
## 2 azeembootwala/titanic Titanic files kagg…
## 3 broaniki/titanic titanic files kagg…
## 4 c/titanic Titanic: Machine Learning fro… files kagg…
## 5 carlmcbrideellis/titanic-all-zero… Titanic all zeros csv file files kagg…
## 6 cities/titanic123 Titanic Dataset Analysis files kagg…
## 7 davorbudimir/titanic Titanic files kagg…
## 8 dushyantkhinchi/titanic-survival Titanic survival files kagg…
## 9 fossouodonald/titaniccsv Titanic csv files kagg…
## 10 harunshimanto/titanic-solution-a-… Titanic Solution: A Beginner'… files kagg…
## # … with 11 more rows
- 캐글에서 검색된
titanic과 관련된 내용이 이렇게 있다.- 여기에서
competition과 관련된 것은c/name_of_competition이기 때문에c/titanic을 입력하도록 한다. - (
pins패키지를 활용해서 함수를 만들어 볼까 잠깐 생각)
- 여기에서
- 이번에는
pin_get()함수를 활용하여 데이터를 불러온다.
pin_get("c/titanic")
## [1] "/Users/username/Library/Caches/pins/kaggle/titanic/gender_submission.csv"
## [2] "/Users/username/Library/Caches/pins/kaggle/titanic/test.csv"
## [3] "/Users/username/Library/Caches/pins/kaggle/titanic/train.csv"
- 출력된 경로에 이미 데이터가 다운받아진 것이다.
- 이제 데이터를 불러온다.
- 이 때,
pin_get을 값을 임의의 변수dataset으로 할당한 후 하나씩 불러오도록 한다.
- 이 때,
- 위 경로는 Mac 사용자에 해당되니 참고하기를 바란다.
library(readr)
dataset <- pin_get("c/titanic")
train <- read_csv(dataset[3])
test <- read_csv(dataset[2])
dim(train); dim(test)
## [1] 891 12
## [1] 418 11
- 데이터가 정상적으로 불러와진 것을 확인할 수 있다.
- 간단한 시각화, 데이터 가공 후, 모형 생성 및 제출까지 진행하도록 해본다.
변수 설명
- survival : 생존유무, target 값. (0 = 사망, 1 = 생존)
- pclass : 티켓 클래스. (1 = 1st, 2 = 2nd, 3 = 3rd)
- sex : 성별
- Age : 나이(세)
- sibsp : 함께 탑승한 형제자매, 배우자 수 총합
- parch : 함께 탑승한 부모, 자녀 수 총합
- ticket : 티켓 넘버
- fare : 탑승 요금
- cabin : 객실 넘버
- embarked : 탑승 항구
(3) 데이터 전처리 (중복값 & 결측치)
- 데이터를 불러온 뒤에는 항상 중복값 및 결측치를 확인한다.
- 먼저 중복값을 확인하자.
- sample code
temp <- data.frame(a = c(1, 1, 2, 3),
b = c("a", "a", "b", "c"))
sum(duplicated(temp))
## [1] 1
- 이와 같은 방식으로 계산할 수 있다.
- 중복값을 제거할 때는
dplyr패키지 내에 있는distinct()사용한다.
dplyr::distinct(temp)
## a b
## 1 1 a
## 2 2 b
## 3 3 c
- 이제 본 데이터에 적용한다.
train <- dplyr::distinct(train); dim(train)
## [1] 891 12
test <- dplyr::distinct(test); dim(test)
## [1] 418 11
- train 데이터의 결측치의 개수를 확인해본다.
colSums(is.na(train))
## PassengerId Survived Pclass Name Sex Age
## 0 0 0 0 0 177
## SibSp Parch Ticket Fare Cabin Embarked
## 0 0 0 0 687 2
- 훈련데이터에서 결측치가 있는 변수는
Cabin,Age,Embarked로 확인되었다. - test 데이터의 결측치의 개수를 확인해본다.
colSums(is.na(test))
## PassengerId Pclass Name Sex Age SibSp
## 0 0 0 0 86 0
## Parch Ticket Fare Cabin Embarked
## 0 0 1 327 0
- 테스트 데이터에서 결측치가 있는 변수는
Cabin,Age,Fare로 확인되었다.
(4) test 데이터 처리법
- 데이터 전처리 시, 테스트 데이터를 어떻게 처리해야 하는지 많은 분들이 궁금해본다.
- 결론부터 말하면,
test데이터는 없다고 생각해야 한다. 실제로는 없는 데이터이지만, 실무에 바로 적용을 하지 못하니, 한번 테스트 한다는 뜻이다. 즉, 어떻게 값이 입력될지 모른다고 판단을 해야 한다.- 따라서, 비록 결측치가 존재하더라도 별도로 처리를 하지 않는다.
Age의 경우train&test데이터에 모두 결측치가 있다고 판단했기 때문에, 결측치는 모두0또는missing values라고 값을 대체 한다.Fare&Embarked탑승요금인데, 우선 평균값 및 최대빈도 값으로 대치를 한다.
- Note: 결측치 처리는 하나의 예시이기 때문에 모든 경우에 적용할 수 있는 것은 아니다. 위 처리 또한 필자의 주관적인 판단이므로, 그저 참고만 해주기를 바란다.
- 우선
Age부터 처리하자.
class(train$Age)
## [1] "numeric"
- 우선 히스토그램으로 데이터의 분포를 확인해보자.
library(ggplot2)
ggplot(train, aes(x = Age)) +
geom_histogram()

- 숫자를 재 범주화 할 필요가 있다.
(5) 도메인 지식의 필요성
Age를 현대적 관점 및 국내 관점에서 바라봐서는 안된다.- 1910년도에는 10대부터 일을 시작했다는 것을 잊지 말자.
- 또한 그들은 위험이 닥쳐도 어느정도 스스로 해결할 수 있는 나이였다는 것을 기억하자.
- 필자가 나눈 연령대는 다음과 같다.
- missing values: non-values
- 0-13: children
- 14-18: teenagers
- 19-64: adults
- over 65: senior
- 이제 코딩을 진행한다.
cut()함수를 활용한다.
age_cut <- function(x) {
data <- x["Age"]
# 지역변수 할당
age_labels <- c("children", "teenagers", "adults", "senior")
if(sum(is.na(x)) > 0) {
# 결측치가 있는 경우 추가
print("결측치가 존재합니다.")
int2cat <- cut(as.integer(data$Age),
breaks=c(0, 13, 18, 64,
max(data$Age, na.rm = TRUE)),
labels=age_labels)
int2cat <- addNA(int2cat)
cat("The levels are:", levels(int2cat))
} else {
print("결측치가 존재 하지 않습니다.")
int2cat <- cut(as.integer(data$Age),
breaks=c(0, 13, 18, 64,
max(data$Age, na.rm = TRUE)),
labels=age_labels)
cat("The levels are:", levels(int2cat))
}
return(int2cat)
}
# 이제 변환을 시도한다.
train$Age <- age_cut(train)
## [1] "결측치가 존재합니다."
## The levels are: children teenagers adults senior NA
test$Age <- age_cut(test)
## [1] "결측치가 존재합니다."
## The levels are: children teenagers adults senior NA
- 동일 작업을 해야했기 때문에 함수를 만들었다.
breaks를 보정하면 조금 더 깔끔한 함수가 나올 수 있을 것 같다.- 그러나, 이쯤에서 정리하도록 한다.
- 이제 마지막으로
summary()함수를 통해 최종적으로 데이터를 확인한다. - 이 외에도 더 많은 변수들을 가공할 수 있지만, 마찬가지로 독자들에게 맡기도록 하겠다.
- 주어진 변수들을 활용하여
single,small family,large family으로 구분하는 도출 변수를 만들어 보자.
- 주어진 변수들을 활용하여
summary(train)
## PassengerId Survived Pclass Name
## Min. : 1.0 Min. :0.0000 Min. :1.000 Length:891
## 1st Qu.:223.5 1st Qu.:0.0000 1st Qu.:2.000 Class :character
## Median :446.0 Median :0.0000 Median :3.000 Mode :character
## Mean :446.0 Mean :0.3838 Mean :2.309
## 3rd Qu.:668.5 3rd Qu.:1.0000 3rd Qu.:3.000
## Max. :891.0 Max. :1.0000 Max. :3.000
## Sex Age SibSp Parch
## Length:891 children : 64 Min. :0.000 Min. :0.0000
## Class :character teenagers: 68 1st Qu.:0.000 1st Qu.:0.0000
## Mode :character adults :564 Median :0.000 Median :0.0000
## senior : 11 Mean :0.523 Mean :0.3816
## NA :184 3rd Qu.:1.000 3rd Qu.:0.0000
## Max. :8.000 Max. :6.0000
## Ticket Fare Cabin Embarked
## Length:891 Min. : 0.00 Length:891 Length:891
## Class :character 1st Qu.: 7.91 Class :character Class :character
## Mode :character Median : 14.45 Mode :character Mode :character
## Mean : 32.20
## 3rd Qu.: 31.00
## Max. :512.33
- 이 때의
NA는 재 가공된NA이다.
(6) 시각화 예제
- 시각화의 기본적인 원리는
타겟변수와의 관계이다. - 머신러닝의 주요 내용이 결국 최적의
feature찾기와 연관이 크기 때문이다. - 시각화 및 기초 통계량 검증을 통해 의미 있는 데이터를 파악하도록 한다.
- 그 외, 다양한 예제는 독자들에게 맡기겠다.
- 간단하게 예시만 확인해본다.
prop.table(table(train$Sex,train$Survived),1)
##
## 0 1
## female 0.2579618 0.7420382
## male 0.8110919 0.1889081
- 교차분석을 통해서 확인할 수 있는 것은 여성들이 살 확률이 더 높았다는 것이다.
Lady First
library(gridExtra)
library(ggplot2)
library(dplyr)
# 성별 막대그래프
p1 <- train %>%
group_by(Sex) %>%
summarise(N = n(), .groups = 'drop') %>%
ggplot(aes(Sex, N)) +
geom_col() +
geom_text(aes(label = N), size = 5, vjust = 1.2, color = "#FFFFFF") +
ggtitle("Bar plot of Sex") +
labs(x = "Sex", y = "Count")
# 성별에 따른 Survived 막대그래프
p2 <- train%>%
dplyr::filter(!is.na(Survived)) %>%
ggplot(aes(factor(Sex), fill = factor(Survived))) +
geom_bar(position = "fill") +
scale_y_continuous(labels = scales::percent) +
scale_fill_brewer(palette = "Set1") +
ggtitle("Survival Rate by Sex") +
labs(x = "Sex", y = "Rate")
grid.arrange(p1, p2, ncol=2)
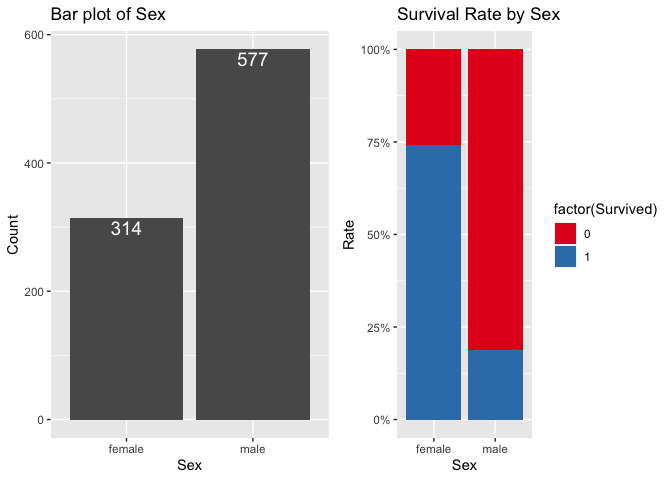
- 교차분석을 통해 확인된 사항을 시각적으로 한번 더 증명하면 된다.
- Note:
summarize함수가dplyr version 1.0.0과 함께 업데이트 되었다.- 현재
.groups를 실험하고 있으며, 만약 기존과 같이 사용하고 싶다면, 아래와 같이 설정한다. 참조: dplyr 1.0.0: last minute additions
- 현재
options(dplyr.summarise.inform = FALSE)
- 시각화는 위와 같은 방식으로 하는 것이 적정하다.
- 통계적 분석 + 시각적 분석 동시에 수행할 때, 보다 데이터가 잘 보인다.
(7) 변수 선택 및 변환
- 변수 선택 시, 기본은 ID와 이름은 제거 한다.
- 또한, 모든 변수가 수치형 또는
factor로 변환 한다.
dplyr::glimpse(train) # test
## Rows: 891
## Columns: 12
## $ PassengerId <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17…
## $ Survived <dbl> 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, …
## $ Pclass <dbl> 3, 1, 3, 1, 3, 3, 1, 3, 3, 2, 3, 1, 3, 3, 3, 2, 3, 2, 3, …
## $ Name <chr> "Braund, Mr. Owen Harris", "Cumings, Mrs. John Bradley (F…
## $ Sex <chr> "male", "female", "female", "female", "male", "male", "ma…
## $ Age <fct> adults, adults, adults, adults, adults, NA, adults, child…
## $ SibSp <dbl> 1, 1, 0, 1, 0, 0, 0, 3, 0, 1, 1, 0, 0, 1, 0, 0, 4, 0, 1, …
## $ Parch <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 1, 0, 0, 5, 0, 0, 1, 0, 0, …
## $ Ticket <chr> "A/5 21171", "PC 17599", "STON/O2. 3101282", "113803", "3…
## $ Fare <dbl> 7.2500, 71.2833, 7.9250, 53.1000, 8.0500, 8.4583, 51.8625…
## $ Cabin <chr> NA, "C85", NA, "C123", NA, NA, "E46", NA, NA, NA, "G6", "…
## $ Embarked <chr> "S", "C", "S", "S", "S", "Q", "S", "S", "S", "C", "S", "S…
- 먼저,
train&test를 각각rbind()활용해 합친다. - 변수 선택을 하도록 하는데, 여기에서는
PassengerId,Name,Ticket은 제거한다.- 값을 출력해보면 알겠지만,
level의 수가 많다.
- 값을 출력해보면 알겠지만,
- 또한
Cabin의 결측치가 많기 때문에 또한 제거한다. - 이제 티겟값을 의미하는
Fare를 제외하고 모든 변수를 범주화를 진행한다. - 이 때,
combi_df$Fare[1044]의 결측치는 하나이기 때문에 중간값으로 대치한다. - 마지막으로
Embarked는addNA()함수를 활용하여 저장한다.
feature_df <- function(train, test) {
# 데이터셋 합치기
test$Survived <- NA
combi_df <- rbind(train, test)
del_vars <- c("PassengerId", "Name", "Ticket", "Cabin")
fct_vars <- c("Survived", "Pclass", "Sex", "SibSp", "Parch", "Embarked")
# which(is.na(combi_df)) = 1044
combi_df$Fare[1044] <- median(combi_df$Fare, na.rm=TRUE)
combi_df <- combi_df %>%
select(-del_vars) %>%
mutate_at(.vars = fct_vars, .funs = as.factor)
combi_df$Embarked <- addNA(combi_df$Embarked)
return(combi_df)
}
master <- feature_df(train, test)
summary(master)
## Survived Pclass Sex Age SibSp Parch
## 0 :549 1:323 female:466 children : 87 0:891 0 :1002
## 1 :342 2:277 male :843 teenagers: 97 1:319 1 : 170
## NA's:418 3:709 adults :837 2: 42 2 : 113
## senior : 13 3: 20 3 : 8
## NA :275 4: 22 4 : 6
## 5: 6 5 : 6
## 8: 9 (Other): 4
## Fare Embarked
## Min. : 0.000 C :270
## 1st Qu.: 7.896 Q :123
## Median : 14.454 S :914
## Mean : 33.281 NA: 2
## 3rd Qu.: 31.275
## Max. :512.329
##
(8) 데이터셋 준비
- 머신러닝 수행 전, xgboost에 맞도록
matrix로 변환해줘야 한다. - 우선Survived값 기준으로 분리 한다.
train <- master %>% filter(is.na(Survived)==FALSE)
test <- master %>% filter(is.na(Survived)==TRUE)
- 다음
xgboost모형에 적합하도록 데이터를 변형한다.data.frame에서DMatrix계열로 변경해줘야 한다.- 또한,
label을 지정해줘야 하는데,label값을0부터 표시해줘야 한다.
- 자세한 설명은 공식 메뉴얼을 참고한다.
train_label <- as.numeric(train$Survived)-1
test_label <- test$Survived
x_train<- model.matrix(~.-1, data = train[,-1]) %>% data.frame
x_test <- model.matrix(~.-1, data = test[,-1]) %>% data.frame
dtrain <- xgb.DMatrix(data = as.matrix(x_train),
label=train_label)
dtest <- xgb.DMatrix(data = as.matrix(x_test))
(9) 모형 적합
- 이제 모형 적합을 진행한다.
- 각 parameters에 대한 구체적인 설명은 공식 홈페이지를 참조 한다.
- XGBoost Parameters
- parameter에 대한 아래 설명은 다음과 같다.
binary:logistic로직스틱 회귀모형으로 반환값을 확률 값으로 반환시킨다.eval_metric:설정한 objective별로 기본 설정값이 지정되어 있는데,logistic은error와 매칭된다.max_depth은 과적합 방지를 위해서 사용되는데 역시 CV를 사용해서 적절한 값이 제시되어야 하고 보통 3-10 사이 값이 적용된다.eta는 일종의 학습률이라고 말한다. 디폴트는 0.3이고, [0, 1] 사이의 값을 지정한다.subsample개별 의사결정나무 모형에 사용되는 임의 표본수를 비율로 지정colsample_bytree개별 의사결정나무 모형에 사용될 변수갯수를 비율로 지정. 보통 0.5 ~ 1이 사용됨.min_child_weight은 과적합(overfitting)을 방지할 목적으로 사용된다. 최소 가중치의 합이라고 하는데, 즉 노드가 더 이상 분할 되는 것을 막아서 과적합을 방지 하도록 하는 것이다.
set.seed(2020)
param <- list(objective = "binary:logistic",
eval_metric = "error",
max_depth = 5,
eta = 0.01,
subsample = 0.8,
min_child_weight = 1)
xgb <- xgb.train(params = param,
data = dtrain,
nrounds = 500,
print_every_n = 1,
verbose = 0)
(10) 모형 예측
- 이제 모형을 예측하자.
- 모형 예측 후에는 확률값으로 떨어지기 때문에,
threshold값을 지정하도록 한다.
XGB_pred <- predict(xgb, dtest)
XGB_pred <- ifelse(XGB_pred >= 0.5, 1, 0)
- 해당 모형에 대한 중요 변수도를 확인해보자.
xgb.importance(colnames(dtrain), model = xgb) %>%
xgb.plot.importance(top_n = 30)

feature중요도를 그래프를 통해 분류모형에 직접적인 영향을 주는 요인을 확인할 수 있다.
(11) 모형 결과 제출
- 최종적인 모형 결과를 제출한다.
submission_titanic <- read_csv(dataset[1])
submission_titanic$Survived <- XGB_pred
write.csv(submission_titanic, file='~/Desktop/submission_titanic.csv', row.names = F)
The More
- 위 코드는 모형 개발 후 바로
Test데이터를 진행한 것이기 때문에train데이터를 다시 분할하여validation데이터를 만들어 검증하는 단계가 필요하다.- 그렇게 하면, 혼동행렬
Matrix및AUC검증을 통해 보다 더 나은 모델을 만들 수 있다. - 이 부분은 추후 보완해서 공유하도록 한다.
- 그렇게 하면, 혼동행렬
R 강의 소개
- 필자의 강의: 왕초보 데이터 분석 with R
- 쿠폰 유효일은 2021년 10월 30일까지입니다.
- 링크: https://www.udemy.com/course/beginner_with_r/?couponCode=5BF397C9A1E46079627D
- 현재 강의를 계속 찍고 있고, 가격은 한 Section이 끝날 때마다 조금씩 올릴 예정입니다.
