Home Credit Default - Data Visualization
공지
- 본 포스트는 재직자 교육을 위해 만든 강의안의 일부입니다.
Introduction
대회 개요
Many people struggle to get loans due to insufficient or non-existent credit histories. And, unfortunately, this population is often taken advantage of by untrustworthy lenders. Home Credit strives to broaden financial inclusion for the unbanked population by providing a positive and safe borrowing experience. In order to make sure this underserved population has a positive loan experience, Home Credit makes use of a variety of alternative data–including telco and transactional information–to predict their clients’ repayment abilities. While Home Credit is currently using various statistical and machine learning methods to make these predictions, they’re challenging Kagglers to help them unlock the full potential of their data. Doing so will ensure that clients capable of repayment are not rejected and that loans are given with a principal, maturity, and repayment calendar that will empower their clients to be successful.
데이터 파일 구조
- 데이터 파일 구조는 크게 2가지로 나뉠 수 있다.
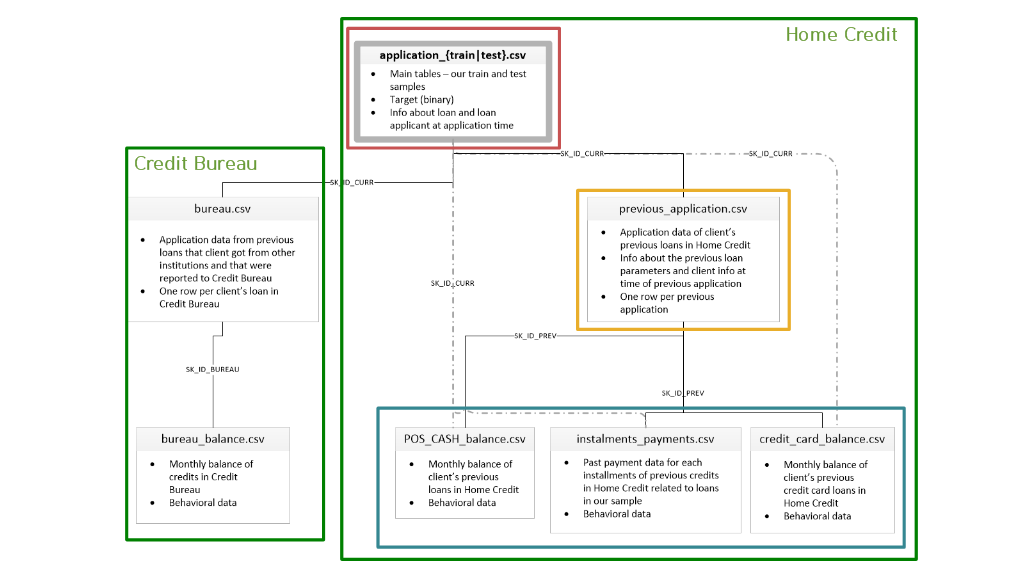
- Credit Bureau 파일 구조와 Home Credit 파일 구조로 분리할 수 있음.
- Bureau (External File)
- Home Credit (Internal File)
- 현재 Home Credit File (Application train/test)
- 이전 Home Credit File (Other’s)
데이터 설명
-
application_{train|test}.csv
- This is the main table, broken into two files for Train (with TARGET) and Test (without TARGET).
- Static data for all applications. One row represents one loan in our data sample.
-
bureau.csv
- All client’s previous credits provided by other financial institutions that were reported to Credit Bureau (for clients who have a loan in our sample).
- For every loan in our sample, there are as many rows as number of credits the client had in Credit Bureau before the application date.
-
bureau_balance.csv
- Monthly balances of previous credits in Credit Bureau.
- This table has one row for each month of history of every previous credit reported to Credit Bureau – i.e the table has (#loans in sample * # of relative previous credits * # of months where we have some history observable for the previous credits) rows.
-
POS_CASH_balance.csv
- Monthly balance snapshots of previous POS (point of sales) and cash loans that the applicant had with Home Credit.
- This table has one row for each month of history of every previous credit in Home Credit (consumer credit and cash loans) related to loans in our sample – i.e. the table has (#loans in sample * # of relative previous credits * # of months in which we have some history observable for the previous credits) rows.
-
credit_card_balance.csv
- Monthly balance snapshots of previous credit cards that the applicant has with Home Credit.
- This table has one row for each month of history of every previous credit in Home Credit (consumer credit and cash loans) related to loans in our sample – i.e. the table has (#loans in sample * # of relative previous credit cards * # of months where we have some history observable for the previous credit card) rows.
-
previous_application.csv
- All previous applications for Home Credit loans of clients who have loans in our sample.
- There is one row for each previous application related to loans in our data sample.
-
installments_payments.csv
- Repayment history for the previously disbursed credits in Home Credit related to the loans in our sample.
- There is a) one row for every payment that was made plus b) one row each for missed payment.
- One row is equivalent to one payment of one installment OR one installment corresponding to one payment of one previous Home Credit credit related to loans in our sample.
-
HomeCredit_columns_description.csv
- This file contains descriptions for the columns in the various data files.
평가 지표
- 제출한 파일은 예측 확률과 기존 관측 대상 사이의 ROC Curve로 평가 한다.
분석 준비
패키지 불러오기
- 주요 패키지를 불러오도록 한다.
library(tidyverse)
library(skimr)
library(GGally)
library(plotly)
library(viridis)
library(caret)
library(DT)
library(data.table)
library(lightgbm)
library(kableExtra)
데이터 불러오기
- 이번에는
fread()를 활용하여 데이터를 불러도록 한다. skim()함수를 활용하면 아래와 같은 결과물을 확인할 수 있다.
na_strings = c("NA", "NaN", "?", "")
train = fread('data/home-credit-default-risk/application_train.csv',
stringsAsFactors = FALSE,
data.table = FALSE, na.strings = na_strings)
train %>% skim()
| Name | Piped data |
| Number of rows | 307511 |
| Number of columns | 122 |
| _______________________ | |
| Column type frequency: | |
| character | 16 |
| numeric | 106 |
| ________________________ | |
| Group variables | None |
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| NAME_CONTRACT_TYPE | 0 | 1.00 | 10 | 15 | 0 | 2 | 0 |
| CODE_GENDER | 0 | 1.00 | 1 | 3 | 0 | 3 | 0 |
| FLAG_OWN_CAR | 0 | 1.00 | 1 | 1 | 0 | 2 | 0 |
| FLAG_OWN_REALTY | 0 | 1.00 | 1 | 1 | 0 | 2 | 0 |
| NAME_TYPE_SUITE | 1292 | 1.00 | 6 | 15 | 0 | 7 | 0 |
| NAME_INCOME_TYPE | 0 | 1.00 | 7 | 20 | 0 | 8 | 0 |
| NAME_EDUCATION_TYPE | 0 | 1.00 | 15 | 29 | 0 | 5 | 0 |
| NAME_FAMILY_STATUS | 0 | 1.00 | 5 | 20 | 0 | 6 | 0 |
| NAME_HOUSING_TYPE | 0 | 1.00 | 12 | 19 | 0 | 6 | 0 |
| OCCUPATION_TYPE | 96391 | 0.69 | 7 | 21 | 0 | 18 | 0 |
| WEEKDAY_APPR_PROCESS_START | 0 | 1.00 | 6 | 9 | 0 | 7 | 0 |
| ORGANIZATION_TYPE | 0 | 1.00 | 3 | 22 | 0 | 58 | 0 |
| FONDKAPREMONT_MODE | 210295 | 0.32 | 13 | 21 | 0 | 4 | 0 |
| HOUSETYPE_MODE | 154297 | 0.50 | 14 | 16 | 0 | 3 | 0 |
| WALLSMATERIAL_MODE | 156341 | 0.49 | 5 | 12 | 0 | 7 | 0 |
| EMERGENCYSTATE_MODE | 145755 | 0.53 | 2 | 3 | 0 | 2 | 0 |
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| SK_ID_CURR | 0 | 1.00 | 278180.52 | 102790.18 | 100002.00 | 189145.50 | 278202.00 | 367142.50 | 456255.00 | ▇▇▇▇▇ |
| TARGET | 0 | 1.00 | 0.08 | 0.27 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| CNT_CHILDREN | 0 | 1.00 | 0.42 | 0.72 | 0.00 | 0.00 | 0.00 | 1.00 | 19.00 | ▇▁▁▁▁ |
| AMT_INCOME_TOTAL | 0 | 1.00 | 168797.92 | 237123.15 | 25650.00 | 112500.00 | 147150.00 | 202500.00 | 117000000.00 | ▇▁▁▁▁ |
| AMT_CREDIT | 0 | 1.00 | 599026.00 | 402490.78 | 45000.00 | 270000.00 | 513531.00 | 808650.00 | 4050000.00 | ▇▂▁▁▁ |
| AMT_ANNUITY | 12 | 1.00 | 27108.57 | 14493.74 | 1615.50 | 16524.00 | 24903.00 | 34596.00 | 258025.50 | ▇▁▁▁▁ |
| AMT_GOODS_PRICE | 278 | 1.00 | 538396.21 | 369446.46 | 40500.00 | 238500.00 | 450000.00 | 679500.00 | 4050000.00 | ▇▂▁▁▁ |
| REGION_POPULATION_RELATIVE | 0 | 1.00 | 0.02 | 0.01 | 0.00 | 0.01 | 0.02 | 0.03 | 0.07 | ▇▇▃▁▁ |
| DAYS_BIRTH | 0 | 1.00 | -16037.00 | 4363.99 | -25229.00 | -19682.00 | -15750.00 | -12413.00 | -7489.00 | ▃▆▇▇▅ |
| DAYS_EMPLOYED | 0 | 1.00 | 63815.05 | 141275.77 | -17912.00 | -2760.00 | -1213.00 | -289.00 | 365243.00 | ▇▁▁▁▂ |
| DAYS_REGISTRATION | 0 | 1.00 | -4986.12 | 3522.89 | -24672.00 | -7479.50 | -4504.00 | -2010.00 | 0.00 | ▁▁▂▅▇ |
| DAYS_ID_PUBLISH | 0 | 1.00 | -2994.20 | 1509.45 | -7197.00 | -4299.00 | -3254.00 | -1720.00 | 0.00 | ▁▆▇▆▅ |
| OWN_CAR_AGE | 202929 | 0.34 | 12.06 | 11.94 | 0.00 | 5.00 | 9.00 | 15.00 | 91.00 | ▇▁▁▁▁ |
| FLAG_MOBIL | 0 | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 | 1.00 | 1.00 | 1.00 | ▁▁▁▁▇ |
| FLAG_EMP_PHONE | 0 | 1.00 | 0.82 | 0.38 | 0.00 | 1.00 | 1.00 | 1.00 | 1.00 | ▂▁▁▁▇ |
| FLAG_WORK_PHONE | 0 | 1.00 | 0.20 | 0.40 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▂ |
| FLAG_CONT_MOBILE | 0 | 1.00 | 1.00 | 0.04 | 0.00 | 1.00 | 1.00 | 1.00 | 1.00 | ▁▁▁▁▇ |
| FLAG_PHONE | 0 | 1.00 | 0.28 | 0.45 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | ▇▁▁▁▃ |
| FLAG_EMAIL | 0 | 1.00 | 0.06 | 0.23 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| CNT_FAM_MEMBERS | 2 | 1.00 | 2.15 | 0.91 | 1.00 | 2.00 | 2.00 | 3.00 | 20.00 | ▇▁▁▁▁ |
| REGION_RATING_CLIENT | 0 | 1.00 | 2.05 | 0.51 | 1.00 | 2.00 | 2.00 | 2.00 | 3.00 | ▁▁▇▁▂ |
| REGION_RATING_CLIENT_W_CITY | 0 | 1.00 | 2.03 | 0.50 | 1.00 | 2.00 | 2.00 | 2.00 | 3.00 | ▁▁▇▁▂ |
| HOUR_APPR_PROCESS_START | 0 | 1.00 | 12.06 | 3.27 | 0.00 | 10.00 | 12.00 | 14.00 | 23.00 | ▁▃▇▆▁ |
| REG_REGION_NOT_LIVE_REGION | 0 | 1.00 | 0.02 | 0.12 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| REG_REGION_NOT_WORK_REGION | 0 | 1.00 | 0.05 | 0.22 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| LIVE_REGION_NOT_WORK_REGION | 0 | 1.00 | 0.04 | 0.20 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| REG_CITY_NOT_LIVE_CITY | 0 | 1.00 | 0.08 | 0.27 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| REG_CITY_NOT_WORK_CITY | 0 | 1.00 | 0.23 | 0.42 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▂ |
| LIVE_CITY_NOT_WORK_CITY | 0 | 1.00 | 0.18 | 0.38 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▂ |
| EXT_SOURCE_1 | 173378 | 0.44 | 0.50 | 0.21 | 0.01 | 0.33 | 0.51 | 0.68 | 0.96 | ▂▇▇▇▃ |
| EXT_SOURCE_2 | 660 | 1.00 | 0.51 | 0.19 | 0.00 | 0.39 | 0.57 | 0.66 | 0.85 | ▂▂▃▇▃ |
| EXT_SOURCE_3 | 60965 | 0.80 | 0.51 | 0.19 | 0.00 | 0.37 | 0.54 | 0.67 | 0.90 | ▂▃▆▇▃ |
| APARTMENTS_AVG | 156061 | 0.49 | 0.12 | 0.11 | 0.00 | 0.06 | 0.09 | 0.15 | 1.00 | ▇▁▁▁▁ |
| BASEMENTAREA_AVG | 179943 | 0.41 | 0.09 | 0.08 | 0.00 | 0.04 | 0.08 | 0.11 | 1.00 | ▇▁▁▁▁ |
| YEARS_BEGINEXPLUATATION_AVG | 150007 | 0.51 | 0.98 | 0.06 | 0.00 | 0.98 | 0.98 | 0.99 | 1.00 | ▁▁▁▁▇ |
| YEARS_BUILD_AVG | 204488 | 0.34 | 0.75 | 0.11 | 0.00 | 0.69 | 0.76 | 0.82 | 1.00 | ▁▁▁▇▅ |
| COMMONAREA_AVG | 214865 | 0.30 | 0.04 | 0.08 | 0.00 | 0.01 | 0.02 | 0.05 | 1.00 | ▇▁▁▁▁ |
| ELEVATORS_AVG | 163891 | 0.47 | 0.08 | 0.13 | 0.00 | 0.00 | 0.00 | 0.12 | 1.00 | ▇▁▁▁▁ |
| ENTRANCES_AVG | 154828 | 0.50 | 0.15 | 0.10 | 0.00 | 0.07 | 0.14 | 0.21 | 1.00 | ▇▃▁▁▁ |
| FLOORSMAX_AVG | 153020 | 0.50 | 0.23 | 0.14 | 0.00 | 0.17 | 0.17 | 0.33 | 1.00 | ▇▃▁▁▁ |
| FLOORSMIN_AVG | 208642 | 0.32 | 0.23 | 0.16 | 0.00 | 0.08 | 0.21 | 0.38 | 1.00 | ▅▇▁▁▁ |
| LANDAREA_AVG | 182590 | 0.41 | 0.07 | 0.08 | 0.00 | 0.02 | 0.05 | 0.09 | 1.00 | ▇▁▁▁▁ |
| LIVINGAPARTMENTS_AVG | 210199 | 0.32 | 0.10 | 0.09 | 0.00 | 0.05 | 0.08 | 0.12 | 1.00 | ▇▁▁▁▁ |
| LIVINGAREA_AVG | 154350 | 0.50 | 0.11 | 0.11 | 0.00 | 0.05 | 0.07 | 0.13 | 1.00 | ▇▁▁▁▁ |
| NONLIVINGAPARTMENTS_AVG | 213514 | 0.31 | 0.01 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| NONLIVINGAREA_AVG | 169682 | 0.45 | 0.03 | 0.07 | 0.00 | 0.00 | 0.00 | 0.03 | 1.00 | ▇▁▁▁▁ |
| APARTMENTS_MODE | 156061 | 0.49 | 0.11 | 0.11 | 0.00 | 0.05 | 0.08 | 0.14 | 1.00 | ▇▁▁▁▁ |
| BASEMENTAREA_MODE | 179943 | 0.41 | 0.09 | 0.08 | 0.00 | 0.04 | 0.07 | 0.11 | 1.00 | ▇▁▁▁▁ |
| YEARS_BEGINEXPLUATATION_MODE | 150007 | 0.51 | 0.98 | 0.06 | 0.00 | 0.98 | 0.98 | 0.99 | 1.00 | ▁▁▁▁▇ |
| YEARS_BUILD_MODE | 204488 | 0.34 | 0.76 | 0.11 | 0.00 | 0.70 | 0.76 | 0.82 | 1.00 | ▁▁▁▇▅ |
| COMMONAREA_MODE | 214865 | 0.30 | 0.04 | 0.07 | 0.00 | 0.01 | 0.02 | 0.05 | 1.00 | ▇▁▁▁▁ |
| ELEVATORS_MODE | 163891 | 0.47 | 0.07 | 0.13 | 0.00 | 0.00 | 0.00 | 0.12 | 1.00 | ▇▁▁▁▁ |
| ENTRANCES_MODE | 154828 | 0.50 | 0.15 | 0.10 | 0.00 | 0.07 | 0.14 | 0.21 | 1.00 | ▇▂▁▁▁ |
| FLOORSMAX_MODE | 153020 | 0.50 | 0.22 | 0.14 | 0.00 | 0.17 | 0.17 | 0.33 | 1.00 | ▇▃▁▁▁ |
| FLOORSMIN_MODE | 208642 | 0.32 | 0.23 | 0.16 | 0.00 | 0.08 | 0.21 | 0.38 | 1.00 | ▅▇▁▁▁ |
| LANDAREA_MODE | 182590 | 0.41 | 0.06 | 0.08 | 0.00 | 0.02 | 0.05 | 0.08 | 1.00 | ▇▁▁▁▁ |
| LIVINGAPARTMENTS_MODE | 210199 | 0.32 | 0.11 | 0.10 | 0.00 | 0.05 | 0.08 | 0.13 | 1.00 | ▇▁▁▁▁ |
| LIVINGAREA_MODE | 154350 | 0.50 | 0.11 | 0.11 | 0.00 | 0.04 | 0.07 | 0.13 | 1.00 | ▇▁▁▁▁ |
| NONLIVINGAPARTMENTS_MODE | 213514 | 0.31 | 0.01 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| NONLIVINGAREA_MODE | 169682 | 0.45 | 0.03 | 0.07 | 0.00 | 0.00 | 0.00 | 0.02 | 1.00 | ▇▁▁▁▁ |
| APARTMENTS_MEDI | 156061 | 0.49 | 0.12 | 0.11 | 0.00 | 0.06 | 0.09 | 0.15 | 1.00 | ▇▁▁▁▁ |
| BASEMENTAREA_MEDI | 179943 | 0.41 | 0.09 | 0.08 | 0.00 | 0.04 | 0.08 | 0.11 | 1.00 | ▇▁▁▁▁ |
| YEARS_BEGINEXPLUATATION_MEDI | 150007 | 0.51 | 0.98 | 0.06 | 0.00 | 0.98 | 0.98 | 0.99 | 1.00 | ▁▁▁▁▇ |
| YEARS_BUILD_MEDI | 204488 | 0.34 | 0.76 | 0.11 | 0.00 | 0.69 | 0.76 | 0.83 | 1.00 | ▁▁▁▇▅ |
| COMMONAREA_MEDI | 214865 | 0.30 | 0.04 | 0.08 | 0.00 | 0.01 | 0.02 | 0.05 | 1.00 | ▇▁▁▁▁ |
| ELEVATORS_MEDI | 163891 | 0.47 | 0.08 | 0.13 | 0.00 | 0.00 | 0.00 | 0.12 | 1.00 | ▇▁▁▁▁ |
| ENTRANCES_MEDI | 154828 | 0.50 | 0.15 | 0.10 | 0.00 | 0.07 | 0.14 | 0.21 | 1.00 | ▇▃▁▁▁ |
| FLOORSMAX_MEDI | 153020 | 0.50 | 0.23 | 0.15 | 0.00 | 0.17 | 0.17 | 0.33 | 1.00 | ▇▃▁▁▁ |
| FLOORSMIN_MEDI | 208642 | 0.32 | 0.23 | 0.16 | 0.00 | 0.08 | 0.21 | 0.38 | 1.00 | ▅▇▁▁▁ |
| LANDAREA_MEDI | 182590 | 0.41 | 0.07 | 0.08 | 0.00 | 0.02 | 0.05 | 0.09 | 1.00 | ▇▁▁▁▁ |
| LIVINGAPARTMENTS_MEDI | 210199 | 0.32 | 0.10 | 0.09 | 0.00 | 0.05 | 0.08 | 0.12 | 1.00 | ▇▁▁▁▁ |
| LIVINGAREA_MEDI | 154350 | 0.50 | 0.11 | 0.11 | 0.00 | 0.05 | 0.07 | 0.13 | 1.00 | ▇▁▁▁▁ |
| NONLIVINGAPARTMENTS_MEDI | 213514 | 0.31 | 0.01 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| NONLIVINGAREA_MEDI | 169682 | 0.45 | 0.03 | 0.07 | 0.00 | 0.00 | 0.00 | 0.03 | 1.00 | ▇▁▁▁▁ |
| TOTALAREA_MODE | 148431 | 0.52 | 0.10 | 0.11 | 0.00 | 0.04 | 0.07 | 0.13 | 1.00 | ▇▁▁▁▁ |
| OBS_30_CNT_SOCIAL_CIRCLE | 1021 | 1.00 | 1.42 | 2.40 | 0.00 | 0.00 | 0.00 | 2.00 | 348.00 | ▇▁▁▁▁ |
| DEF_30_CNT_SOCIAL_CIRCLE | 1021 | 1.00 | 0.14 | 0.45 | 0.00 | 0.00 | 0.00 | 0.00 | 34.00 | ▇▁▁▁▁ |
| OBS_60_CNT_SOCIAL_CIRCLE | 1021 | 1.00 | 1.41 | 2.38 | 0.00 | 0.00 | 0.00 | 2.00 | 344.00 | ▇▁▁▁▁ |
| DEF_60_CNT_SOCIAL_CIRCLE | 1021 | 1.00 | 0.10 | 0.36 | 0.00 | 0.00 | 0.00 | 0.00 | 24.00 | ▇▁▁▁▁ |
| DAYS_LAST_PHONE_CHANGE | 1 | 1.00 | -962.86 | 826.81 | -4292.00 | -1570.00 | -757.00 | -274.00 | 0.00 | ▁▁▂▃▇ |
| FLAG_DOCUMENT_2 | 0 | 1.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_3 | 0 | 1.00 | 0.71 | 0.45 | 0.00 | 0.00 | 1.00 | 1.00 | 1.00 | ▃▁▁▁▇ |
| FLAG_DOCUMENT_4 | 0 | 1.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_5 | 0 | 1.00 | 0.02 | 0.12 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_6 | 0 | 1.00 | 0.09 | 0.28 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_7 | 0 | 1.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_8 | 0 | 1.00 | 0.08 | 0.27 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_9 | 0 | 1.00 | 0.00 | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_10 | 0 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_11 | 0 | 1.00 | 0.00 | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_12 | 0 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_13 | 0 | 1.00 | 0.00 | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_14 | 0 | 1.00 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_15 | 0 | 1.00 | 0.00 | 0.03 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_16 | 0 | 1.00 | 0.01 | 0.10 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_17 | 0 | 1.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_18 | 0 | 1.00 | 0.01 | 0.09 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_19 | 0 | 1.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_20 | 0 | 1.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| FLAG_DOCUMENT_21 | 0 | 1.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | ▇▁▁▁▁ |
| AMT_REQ_CREDIT_BUREAU_HOUR | 41519 | 0.86 | 0.01 | 0.08 | 0.00 | 0.00 | 0.00 | 0.00 | 4.00 | ▇▁▁▁▁ |
| AMT_REQ_CREDIT_BUREAU_DAY | 41519 | 0.86 | 0.01 | 0.11 | 0.00 | 0.00 | 0.00 | 0.00 | 9.00 | ▇▁▁▁▁ |
| AMT_REQ_CREDIT_BUREAU_WEEK | 41519 | 0.86 | 0.03 | 0.20 | 0.00 | 0.00 | 0.00 | 0.00 | 8.00 | ▇▁▁▁▁ |
| AMT_REQ_CREDIT_BUREAU_MON | 41519 | 0.86 | 0.27 | 0.92 | 0.00 | 0.00 | 0.00 | 0.00 | 27.00 | ▇▁▁▁▁ |
| AMT_REQ_CREDIT_BUREAU_QRT | 41519 | 0.86 | 0.27 | 0.79 | 0.00 | 0.00 | 0.00 | 0.00 | 261.00 | ▇▁▁▁▁ |
| AMT_REQ_CREDIT_BUREAU_YEAR | 41519 | 0.86 | 1.90 | 1.87 | 0.00 | 0.00 | 1.00 | 3.00 | 25.00 | ▇▁▁▁▁ |
- 위 코드를 토대로 다른 데이터도 불러와서 확인을 해본다.
주요 변수 시각화
Target
- 우선 Target Variable의 데이터를 확인해본다.
- 먼저 데이터 요약을 해보자.
train %>%
group_by(TARGET) %>%
summarise(Count = n())
## # A tibble: 2 × 2
## TARGET Count
## <int> <int>
## 1 0 282686
## 2 1 24825
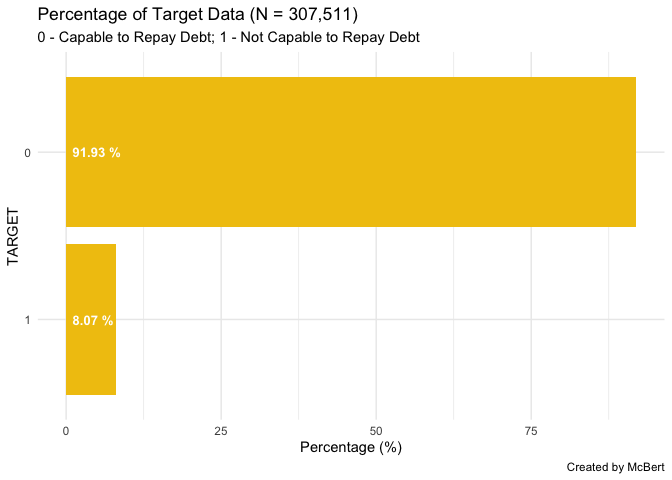
- 전체적인 비율을 구해본다.
# fillColor = "#FFA07A"
# fillColor2 = "#F1C40F"
# fillColorLightCoral = "#F08080"
train %>%
group_by(TARGET) %>%
summarise(Count = n() / nrow(train) * 100) %>%
arrange(desc(Count)) %>%
ungroup() %>%
mutate(TARGET = reorder(TARGET, Count)) %>%
ggplot(aes(x = TARGET, y = Count)) +
geom_bar(stat = "identity", fill = "#F1C40F") +
geom_text(aes(x = TARGET, y = 1, label = paste0(round(Count, 2), " %")),
hjust = 0, vjust = .5, size = 3.5, colour = "white", fontface = "bold") +
coord_flip() +
labs(x = "TARGET",
y = "Percentage (%)",
title = "Percentage of Target Data (N = 307,511)",
subtitle = "0 - Capable to Repay Debt; 1 - Not Capable to Repay Debt",
caption = "Created by McBert") +
theme_minimal()
Gender
- 이번에는 Gender의 숫자를 구해본다.
train %>%
group_by(CODE_GENDER) %>%
summarise(Count = n())
## # A tibble: 3 × 2
## CODE_GENDER Count
## <chr> <int>
## 1 F 202448
## 2 M 105059
## 3 XNA 4
- 이번에는 TARGET ~ TARGET 데이터를 요약해본다.
train %>%
group_by(CODE_GENDER, TARGET) %>%
summarise(Count = n())
## `summarise()` has grouped output by 'CODE_GENDER'. You can override using the `.groups` argument.
## # A tibble: 5 × 3
## # Groups: CODE_GENDER [3]
## CODE_GENDER TARGET Count
## <chr> <int> <int>
## 1 F 0 188278
## 2 F 1 14170
## 3 M 0 94404
## 4 M 1 10655
## 5 XNA 0 4
- 이번에는 시각화를 해본다.
train %>%
group_by(CODE_GENDER, TARGET) %>%
summarise(Count = n() / nrow(train) * 100) %>%
arrange(desc(Count)) %>%
ungroup() %>%
mutate(CODE_GENDER = reorder(CODE_GENDER, Count),
TARGET = as.factor(TARGET)) %>%
ggplot(aes(x = CODE_GENDER, y = Count, fill = TARGET)) +
geom_bar(stat = "identity", position = position_dodge(width = 1)) +
geom_text(aes(x = CODE_GENDER, y = Count + 2, label = paste0(round(Count, 2), " %"), group = TARGET),
position = position_dodge(width = 1), size = 3.5, colour = "black", fontface = "bold") +
labs(x = "Gender",
y = "Percentage (%)",
title = "Percentage of Target ~ Gender Data (N = 307,511)",
subtitle = "0 - Capable to Repay Debt; 1 - Not Capable to Repay Debt",
caption = "Created by McBert") +
scale_fill_manual(values = c("#F5896E", "#7BDCFF")) +
theme_minimal()
## `summarise()` has grouped output by 'CODE_GENDER'. You can override using the `.groups` argument.

AMT CREDIT
- 이번에는 대출 잔액을 확인해본다.
summary(train$AMT_CREDIT)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 45000 270000 513531 599026 808650 4050000
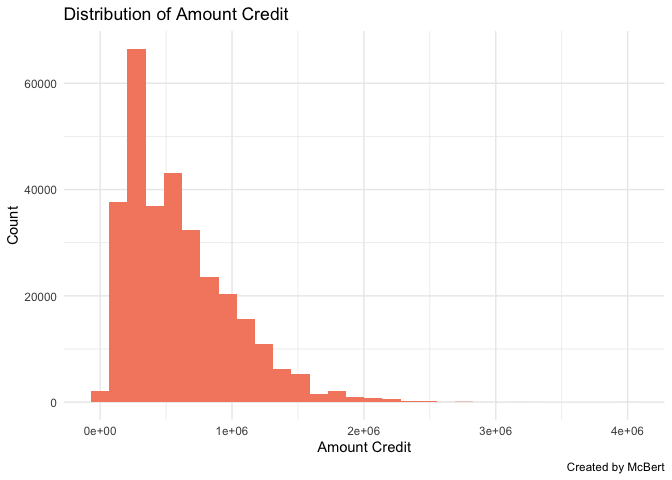
- 데이터의 분포도를 그려보도록 한다.
train %>%
ggplot(aes(x = AMT_CREDIT)) +
geom_histogram(bins = 30, fill = "#F5896E") +
labs(x = "Amount Credit",
y = "Count",
title = "Distribution of Amount Credit",
caption = "Created by McBert") +
theme_minimal()
- 이상치를 제거하도록 한다.
- 상위 2.5%는 제거하도록 한다.
upper_threshold = quantile(train$AMT_CREDIT, 0.975)
cat("Top 2.5% threshold is:", upper_threshold)
## Top 2.5% threshold is: 1574532
train %>%
filter(AMT_CREDIT <= upper_threshold) %>%
ggplot(aes(x = AMT_CREDIT)) +
geom_histogram(bins = 30, fill = "#F5896E") +
labs(x = "Amount Credit",
y = "Count",
title = "Distribution of Amount Credit",
caption = "Created by McBert") +
theme_minimal()

TARGET ~ Age, Gender, Status
- 이번에는 조건문을 활용하여 데이터를 요약하고, 시각화를 진행해본다.
train$DAYS_BIRTH[1:5]
## [1] -9461 -16765 -19046 -19005 -19932
train$CODE_GENDER[1:5]
## [1] "M" "F" "M" "F" "M"
table(train$CNT_FAM_MEMBERS)
##
## 1 2 3 4 5 6 7 8 9 10 11
## 67847 158357 52601 24697 3478 408 81 20 6 3 1
## 12 13 14 15 16 20
## 2 1 2 1 2 2
table(train$NAME_FAMILY_STATUS)
##
## Civil marriage Married Separated
## 29775 196432 19770
## Single / not married Unknown Widow
## 45444 2 16088
train %>%
filter(!is.na(TARGET), CODE_GENDER != "XNA", CNT_FAM_MEMBERS <= 4) %>% # nrow() ~ 303498
group_by(age = -round(DAYS_BIRTH/365, 0),
gender = ifelse(CODE_GENDER == "M", "Male", "Female"),
status = ifelse(NAME_FAMILY_STATUS == "Civil marriage", "Married",
ifelse(NAME_FAMILY_STATUS == "Single / not married", "Single", as.character(NAME_FAMILY_STATUS)))) %>% # select(NAME_FAMILY_STATUS)
summarise(count = n(),
AVG_CREDIT = mean(AMT_CREDIT),
AVG_TARGET = mean(TARGET)) %>%
mutate(AVG_TARGET = pmin(pmax(AVG_TARGET, 0.00), 0.20) * 100) %>%
ggplot(aes(x = age, y = count, fill = AVG_TARGET)) +
geom_histogram(stat = "identity", width = 1) +
facet_grid(gender ~ status) +
scale_fill_gradient("Avg. Default Rate %", low = "white", high = "blue") +
labs(title = "Default Rate of Applicants (N = 303,498)",
subtitle = "Age, Gender, And Marriage Status",
caption = "Created by McBert") +
theme_minimal()
## `summarise()` has grouped output by 'age', 'gender'. You can override using the `.groups` argument.
## Warning: Ignoring unknown parameters: binwidth, bins, pad
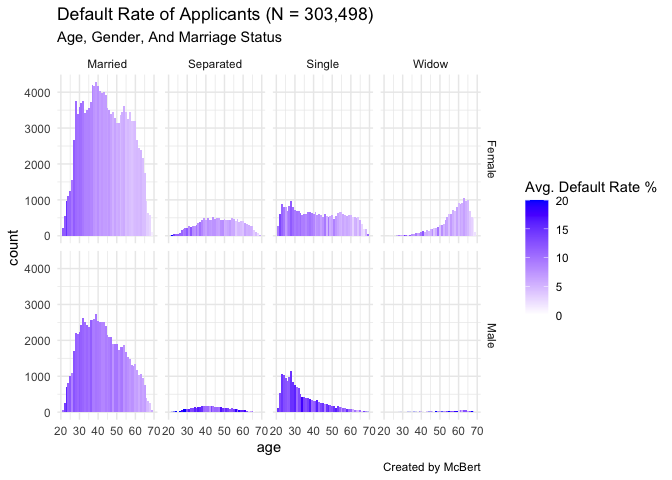
- 상대적으로 Single, Male 그룹이 다른 그룹보다 Default 비율이 높았다.
- 또한, 상대적으로 연령대가 낮을수록 Default 비율이 높았다.
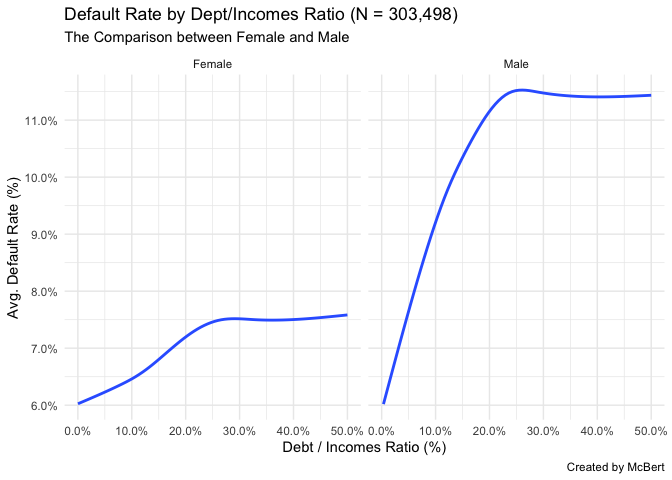
Dept/Incomes Ratio %
- Dept의 비율이 높으면 높으수록 Default 비율도 높을 것으로 예상할 수 있다. 실제로 그런지 확인해본다.
library(scales)
##
## Attaching package: 'scales'
## The following object is masked from 'package:viridis':
##
## viridis_pal
## The following object is masked from 'package:purrr':
##
## discard
## The following object is masked from 'package:readr':
##
## col_factor
train %>%
filter(!is.na(TARGET), CODE_GENDER != "XNA", CNT_FAM_MEMBERS <= 4) %>%
mutate(CODE_GENDER = ifelse(CODE_GENDER == "M", "Male", "Female"),
DEPT_INCOMES_RATIO = AMT_ANNUITY/AMT_INCOME_TOTAL) %>%
select(CODE_GENDER, DEPT_INCOMES_RATIO, TARGET) %>%
ggplot(aes(x = DEPT_INCOMES_RATIO, y = TARGET)) +
geom_smooth(se = FALSE) +
scale_x_continuous(name = "Debt / Incomes Ratio (%)",
limits = c(0, 0.5),
labels = percent_format(accuracy = 0.1)) +
# coord_cartesian(ylim=c(0.00, 0.15)) +
scale_y_continuous(name = "Avg. Default Rate (%)",
breaks = seq(0, 1, 0.01),
labels = percent_format(accuracy = 0.1)) +
facet_grid(~ CODE_GENDER) +
labs(title = "Default Rate by Dept/Incomes Ratio (N = 303,498)",
subtitle = "The Comparison between Female and Male",
caption = "Created by McBert") +
theme_minimal()
## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'
## Warning: Removed 2488 rows containing non-finite values (stat_smooth).
Bureau Data
(과제) 개인별 시각화 인사이트 찾기
- 지금까지의 작성방법을 토대로 다양하게 시각화를 작성해본다.
R 강의 소개
- 필자의 강의: 왕초보 데이터 분석 with R
- 쿠폰 유효일은 2021년 10월 30일까지입니다.
- 링크: https://www.udemy.com/course/beginner_with_r/?couponCode=5BF397C9A1E46079627D
- 현재 강의를 계속 찍고 있고, 가격은 한 Section이 끝날 때마다 조금씩 올릴 예정입니다.
Python 강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

