Ch02 Process Analysis Basic
I. 개요
지난시간에 patients에 관한 데이터를 통해서 프로세스 분석에 대한 일반적인 개념을 접했다.
이번 포스트에서는 bupaR에 대한 이론적인 내용과 함께 간단하게 실습을 진행하도록 한다.
지난시간과 마찬가지로 먼저 데이터를 획득하는 것에서부터 출발한다.
library(bupaR)
library(eventdataR)
patients <- patients
dim(patients)
## [1] 5442 7
5442행과 7개의 열이 확인되었다.
class(patients)
## [1] "eventlog" "tbl_df" "tbl" "data.frame"
그리고, 데이터는 eventlog, tbl_df, data.frame으로 구성된 것을 확인할 수 있다. 기존에 R을 학습한 사람들은 tbl & data.frame에 대해서 한두번쯤 들었을 거라 생각한다. 그러나 eventlog는 생소한 객체임을 알 수 있다.
조금더 구체적으로 확인하기 위해 데이터를 살펴보자.
library(dplyr)
glimpse(patients)
## Rows: 5,442
## Columns: 7
## $ handling <fct> Registration, Registration, Registration, Registrat…
## $ patient <chr> "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", …
## $ employee <fct> r1, r1, r1, r1, r1, r1, r1, r1, r1, r1, r1, r1, r1,…
## $ handling_id <chr> "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", …
## $ registration_type <fct> start, start, start, start, start, start, start, st…
## $ time <dttm> 2017-01-02 11:41:53, 2017-01-02 11:41:53, 2017-01-…
## $ .order <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, …
summary(patients)
## Number of events: 5442
## Number of cases: 500
## Number of traces: 7
## Number of distinct activities: 7
## Average trace length: 10.884
##
## Start eventlog: 2017-01-02 11:41:53
## End eventlog: 2018-05-05 07:16:02
## handling patient employee handling_id
## Blood test : 474 Length:5442 r1:1000 Length:5442
## Check-out : 984 Class :character r2:1000 Class :character
## Discuss Results : 990 Mode :character r3: 474 Mode :character
## MRI SCAN : 472 r4: 472
## Registration :1000 r5: 522
## Triage and Assessment:1000 r6: 990
## X-Ray : 522 r7: 984
## registration_type time .order
## complete:2721 Min. :2017-01-02 11:41:53 Min. : 1
## start :2721 1st Qu.:2017-05-06 17:15:18 1st Qu.:1361
## Median :2017-09-08 04:16:50 Median :2722
## Mean :2017-09-02 20:52:34 Mean :2722
## 3rd Qu.:2017-12-22 15:44:11 3rd Qu.:4082
## Max. :2018-05-05 07:16:02 Max. :5442
##
기존의 데이터프레임과는 많이 다른 것을 확인할 수 있다. 이쯤 되면 여기에서는 패키지 원문을 봐야 정확하게 짚고 넘어가야 한다. 아래 그림을 보자.

위 그림은 Event data Model에 대한 전체적인 설명이다.
즉, bupaR패키지를 활용하려면 전반적인 데이터셋이 위 그림과 같아야 하는데, 전반적으로 데이터가 특정 사건에 대해 시계열처럼 프로세스를 기록한 데이터셋이라고 볼 수 있다.
patterns라는 데이터셋은 병원 응급실에서 발생한 데이터와 연관이 있고, model level, instance level, 그리고 event level로 구성되어 있음을 알 수 있다.
II. EDA - 기초통계량
(1) 환자에 대한 기록
- 우선 5442개의 데이터에서 실제 환자의 수는 몇명일까?
summary에서 확인이 가능했지만,n_cases()함수를 활용하면 쉽게 구할 수 있다.
n_cases(patients)
## [1] 500
- 이번에는 첫번째 환자의 여정을 살펴보도록 한다.
slice(patients, 1)
## Log of 12 events consisting of:
## 1 trace
## 1 case
## 6 instances of 6 activities
## 6 resources
## Events occurred from 2017-01-02 11:41:53 until 2017-01-09 19:45:45
##
## Variables were mapped as follows:
## Case identifier: patient
## Activity identifier: handling
## Resource identifier: employee
## Activity instance identifier: handling_id
## Timestamp: time
## Lifecycle transition: registration_type
##
## # A tibble: 12 x 7
## handling patient employee handling_id registration_ty… time
## <fct> <chr> <fct> <chr> <fct> <dttm>
## 1 Registr… 1 r1 1 start 2017-01-02 11:41:53
## 2 Triage … 1 r2 501 start 2017-01-02 12:40:20
## 3 Blood t… 1 r3 1001 start 2017-01-05 08:59:04
## 4 MRI SCAN 1 r4 1238 start 2017-01-05 21:37:12
## 5 Discuss… 1 r6 1735 start 2017-01-07 07:57:49
## 6 Check-o… 1 r7 2230 start 2017-01-09 17:09:43
## 7 Registr… 1 r1 1 complete 2017-01-02 12:40:20
## 8 Triage … 1 r2 501 complete 2017-01-02 22:32:25
## 9 Blood t… 1 r3 1001 complete 2017-01-05 14:34:27
## 10 MRI SCAN 1 r4 1238 complete 2017-01-06 01:54:23
## 11 Discuss… 1 r6 1735 complete 2017-01-07 10:18:08
## 12 Check-o… 1 r7 2230 complete 2017-01-09 19:45:45
## # … with 1 more variable: .order <int>
slice(patients, 1) 함수를 적용하니, 첫번째 case에 대한 모든 기록이 다 나오는 것을 확인할 수 있다. 상상력을 발휘해서, 환자의 보호자를 떠오르면, handling의 의미(병원 등록부터 수납까지)를 쉽게 파악할 수 있다.
(2) 병원내 활동 현황
두번째로 확인할 수 있는 것은 500명 환자가 활동한 activity에 대한 기초통계량이다.
n_activities(patients)
## [1] 7
우선 총 7개의 활동 영역을 확인 할 수 있다. 그러면 각 활동의 이름은 어떻게 될까?
activity_labels(patients)
## [1] Registration Triage and Assessment Blood test
## [4] MRI SCAN X-Ray Discuss Results
## [7] Check-out
## 7 Levels: Blood test Check-out Discuss Results MRI SCAN ... X-Ray
우선 범주형 벡터로 확인되었고, 병원과 관련있는 용어로 구성되어 있음을 확인했다. 그런데, Triage and Assessment가 있다. 이 용어는 응급환자 분류와 평가에 대한 항목1인데, patients 데이터가 응급환자와 관련된 데이터임을 확인할 수 있다.
그러면, 각 활동의 빈도수는 어떻게 될까? 환자 500명이 각각의 활동을 할 것인데, 분명히 프로세스에 따라 그 빈도수가 차이가 날 것임을 예상할 수 있다.
activities(patients)
## # A tibble: 7 x 3
## handling absolute_frequency relative_frequency
## <fct> <int> <dbl>
## 1 Registration 500 0.184
## 2 Triage and Assessment 500 0.184
## 3 Discuss Results 495 0.182
## 4 Check-out 492 0.181
## 5 X-Ray 261 0.0959
## 6 Blood test 237 0.0871
## 7 MRI SCAN 236 0.0867
당연한 말이지만, 환자가 병원에 오면 무조건 밟아야 하는 기본 절차인 Registration & Triage and Assessment (등록과 응급환자 분류와 평가)는 기본적인 절차이기 때문에 500명, 즉 환자수와 일치하지만, 나머지는 상이한 것을 볼 수 있다.
(3) 프로세스 경로와 관련된 현황
환자가 등록을 하면, 피검사를 할지, X-Ray를 할지 등으로 분류가 될 것이다. 이러한 경로가 몇개 나왔는지 확인을 해본다.
traces(patients)
## # A tibble: 7 x 3
## trace absolute_frequen… relative_frequen…
## <chr> <int> <dbl>
## 1 Registration,Triage and Assessment,X-Ray,… 258 0.516
## 2 Registration,Triage and Assessment,Blood … 234 0.468
## 3 Registration,Triage and Assessment,Blood … 2 0.004
## 4 Registration,Triage and Assessment,X-Ray 2 0.004
## 5 Registration,Triage and Assessment 2 0.004
## 6 Registration,Triage and Assessment,X-Ray,… 1 0.002
## 7 Registration,Triage and Assessment,Blood … 1 0.002
총 7개가 나오는 것으로 확인이 된다.
위 테이블을 시각화를 해본다. 이미 이러한 시각화를 할 수 있도록 processmapR 패키지가 있어서 매우 쉽게 시각화를 할 수 있다.
library(processmapR)
trace_explorer(patients, coverage=1)
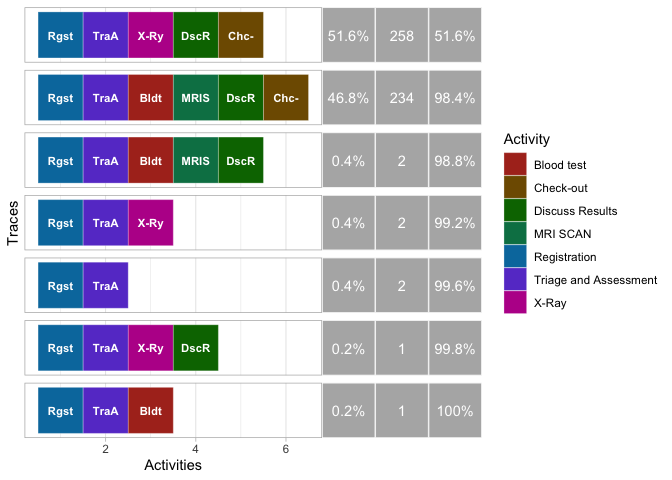
그러면 지난 포스트에서 잠깐 봤던 이미지가 다시 출력되는 것을 확인할 수 있다.
이제 보다 분명하게 이해되었을 것이다. 인수 coverage는 경로 탐색을 위한 전체 빈도수에 대한 누적 퍼센트를 말한다. 다시 말하면 coverage = 1 전체 데이터를 보여 달라는 뜻이고, 여기에서 coverage = 0.??? 값을 조정하여 시각화를 다르게 가져갈 수 있다. 예를 들면, coverage 0.986으로 지정하면 누적 퍼센트 <= 0.986 이하의 데이터만 시각화로 출력이 된다.
trace_explorer(patients, coverage = 0.986)

(4) 프로세스 지도
이번에는 위 데이터의 현황에 대해 전체적인 프로세스가 어떻게 진행되는지 확인해본다.
library(processmapR)
process_map(patients)
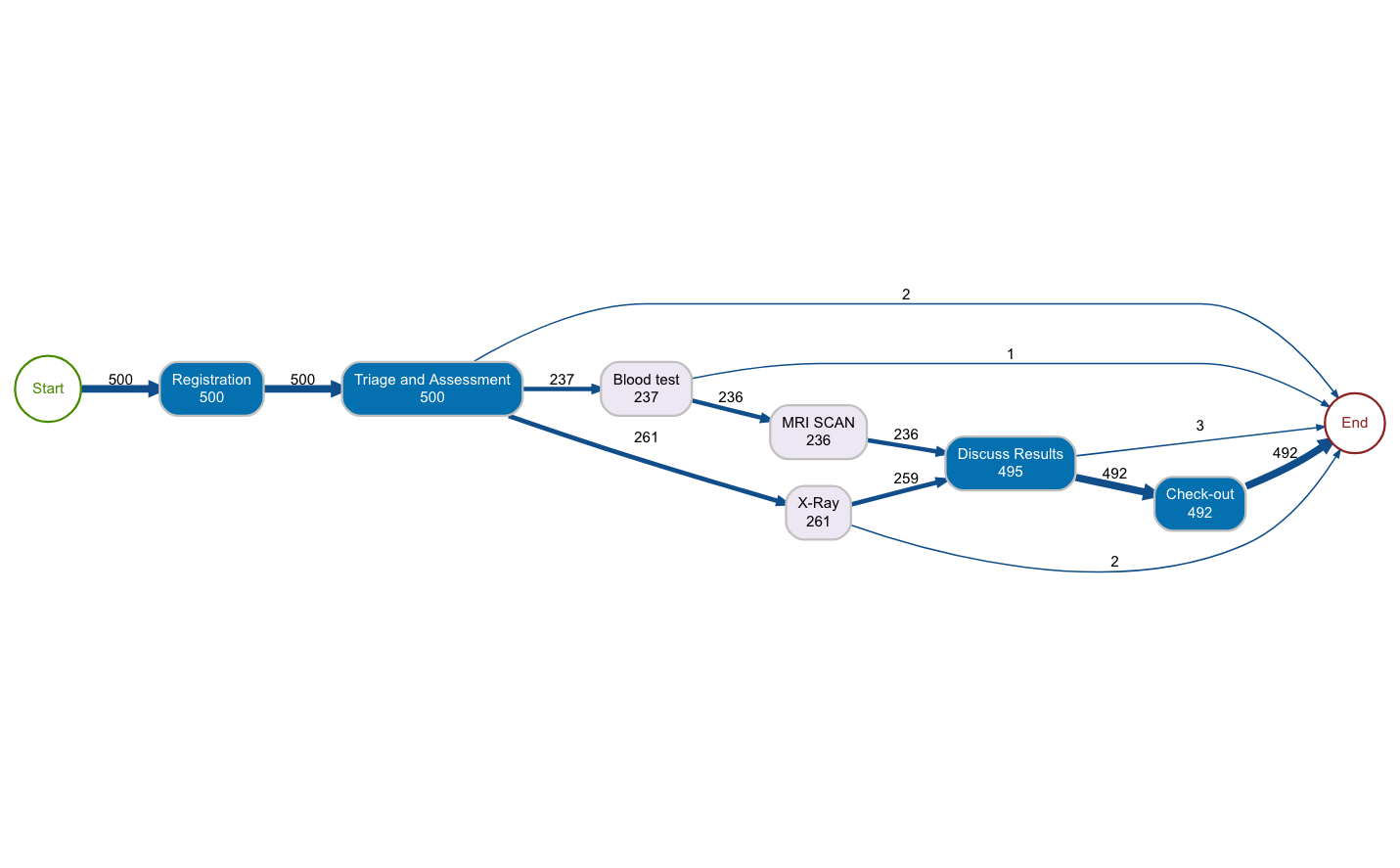
전체적으로 경로 현황에 대해 보다 시각적으로 나타난 것으로 확인이 되었다. 위 시각화에 대한 분석은 각자 맡기도록 한다.
다만, 중요한 것은 이렇게 시각화를 통하여 응급환자의 이동 경로를 매우 쉽고 빠르게 확인할 수 있다는 점이다.
III. 결론
이 부분이 만약 다른 업종과 연계되어 접근이 되면 어떻게 될까? 아니, 다른 업종도 위와 같은 데이터를 구성해서 활용할 수 있을까?
다음 시간에는 event data를 실제로 생성하는 작업을 해보도록 해서 응용하도록 한다.
VI. Reference
R on notast. “Process Mining (Part 1/3): Introduction to BupaR Package.” R, 7 Mar. 2019, www.r-bloggers.com/process-mining-part-1-3-introduction-to-bupar-package/.
Aalst, W.m.p. Van Der, and A.j.m.m. Weijters. “Process Mining: a Research Agenda.” Computers in Industry, vol. 53, no. 3, 2004, pp. 231–244., doi:10.1016/j.compind.2003.10.001.
-
아이라. (2017). KTAS 한국형 외상. 응급환자 분류와 평가(Triage and Assessment). Retrieved from https://m.blog.naver.com/tinaarena/221070718090 ↩︎
