Ch01 Process Analysis Intro
I. Process Mining Intro
모든 비즈니스는 프로세스와 연관이 깊다. 이러한 데이터를 통상적으로 event라고 부르며, 다루는 데이터는 log 데이터와 연관이 깊다. 프로세스 마이닝(Process Mining)은 데이터의 추출, 프로세싱, 그리고 분석의 순으로 진행한다.

데이터 추출 (Extraction):Raw Data를Event Data로 변환시킨다.프로세싱 (Processing): 데이터 가공과 비슷하며, 보통Aggregation,Filtering,Enrichment의 용어가 등장한다.분석 (Analysis): Performance, Control-Flow 등과 연관된 분석이 진행된다.
우선 빠르게 시각화부터 진행해보자.
library(bupaR)
library(httr)
library(processmapR)
library(edeaR)
url <- 'https://github.com/chloevan/datasets/blob/master/log/log_eat_patterns.RDS?raw=true'
patterns <- readRDS(url(url))
trace_explorer(patients, coverage=1)

위 그래프에 대한 해석은 나중에 하더라도, 위 데이터를 보면, Rgst아 TraA는 공통으로 존재하고, 경로에 따라서 X-Ray, Blood Test에 나뉘는 걸 봐서는 환자의 경로에 관한 데이터임을 알 수 있다.
II. Process Mining Overview
일반적으로 프로세스 마이닝은 이벤트 로그를 기반으로 비즈니스 프로세스를 분석할 수 있는 프로세스 관리 기술이라고 할 수 있다. 아래 그림을 살펴보자.
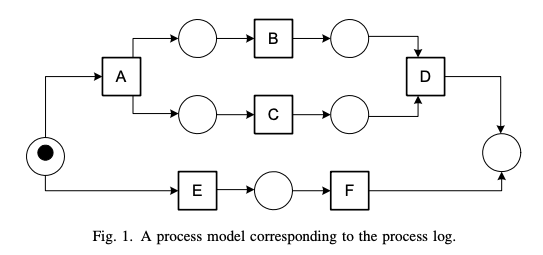
알파벳 글자는 일종의 Task이다. 즉, 각각의 Task가 끝날 때 마다 실제로 어떻게 행동하는지 알아보는 과정이 Process Mining이라 할 수 있다.
Process Mining에서 중요하게 바라봐야 하는 것은 무엇일까? 각 도메인마다 다르겠지만, Patients 데이터의 경우에는 시간이 아닐까?
일반적으로 MRI Scan이 시간이 소요된다는 걸 상식적으로 알고 있다. 그렇다면 진료 시간을 계산하기 위해서 MRI Scan이 있고 없고에 따라서 어떻게 바뀌는지 알아보자.
patients %>%
filter_activity_presence("MRI SCAN") %>%
processing_time(level="log", units="hours")
## min q1 median mean q3 max st_dev iqr
## 21.873056 27.790347 30.769444 30.303944 32.614514 38.245833 3.359803 4.824167
## attr(,"units")
## [1] "hours"
MRI Scan을 할 때, 평균 30.3시간이 걸린 것을 확인할 수 있다. 그렇다면 MRI Scan을 하지 않았을 때 시간은 얼마나 단축이 될까?
patients %>%
filter_activity_presence("MRI SCAN", method="none") %>%
processing_time(level="log", units="hours")
## min q1 median mean q3 max st_dev iqr
## 10.717778 23.285764 25.840139 25.465921 27.898958 33.422500 3.448286 4.613194
## attr(,"units")
## [1] "hours"
이 때에는 평균 25.45시간으로 약 5시간이 단축된 것을 확인할 수 있다.
III. Let’s Begin with Process Mining
이벤트 로그를 통해서 우리는 Process Mining에 대한 간단하게 맛보기를 진행하였다. 이번 포스트를 통해서 어느정도 감을 잡았으면 좋겠다. 강사도 처음 접하는 분석이지만, 실제로 웹로그분석시에는 Google Analytics라는 좋은 Tool을 활용하여 자주 접하는 내용이기도 했다. 내용 자체는 어렵지는 않다. 다만, 그러나, Web log이외의 다른 영역에서 어떻게 Process Mining을 어떻게 다루는지 궁금하던 차에, 관련 논문을 보게 되었고, 이에 한번 본격적으로 다뤄보고자 한다.
VI. Reference
R on notast. “Process Mining (Part 1/3): Introduction to BupaR Package.” R, 7 Mar. 2019, www.r-bloggers.com/process-mining-part-1-3-introduction-to-bupar-package/.
Aalst, W.m.p. Van Der, and A.j.m.m. Weijters. “Process Mining: a Research Agenda.” Computers in Industry, vol. 53, no. 3, 2004, pp. 231–244., doi:10.1016/j.compind.2003.10.001.
