list handling
I. 개요
모든 프로그래밍 언어에는 기본적으로 데이터타입이 존재한다. R도 프로그래밍 언어이기 때문에 데이터 타입의 일반적인 유형이 존재한다.
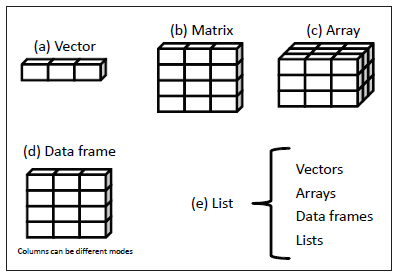
Vector의 기본 개념을 익혔다면, 전반적인 구조에 대해 살피는 시간을 갖도록 한다. 먼저 동일 성질의 Vector가 모여서 matrix도 되고, 데이터프레임도 된다. 그리고 이러한 다양한 데이터의 구조가 모여 리스트를 형성하는데,
리스트를 만드는 것도 중요한 건, 즉 이해다. 리스트에 접근법이 중요한데, 리스트를 잘 다루면, apply 함수 계열을 사용하는데도 큰 도움이 된다.
특히, 100GB 이상의 데이터를 다루게 되면, apply() 함수로 작업해야 하는 일이 종종 발생한다.
II. List 생성
이제 리스트를 작성해보자. 문자형 벡터와 숫자형 벡터를 만든후 리스트에 넣도록 한다.
xNum <- c(1, 3.14, 5, 7)
xChar <- c("A", "B", "C", "D")
xList <- list(xNum, xChar)
print(xList)
## [[1]]
## [1] 1.00 3.14 5.00 7.00
##
## [[2]]
## [1] "A" "B" "C" "D"
이 출력값에서 주의 깊게 봐야 하는 것 [[1]]과 같은 형태이다. 즉, A, 1.00과 같은 실제 값이 들어있는 각각의 원소에 대해 접근을 하려면, [[1]]과 같은 것에 먼저 접근을 해야 하기 때문이다.
실제로 3.14을 출력하도록 해본다.
xList[[1]][2]
## [1] 3.14
출력을 할 때는 위와 같은 형태로 작성을 해야 한다.
그런데, 우리가 궁금한 것은 이러한 접근법이 중요한 것이 아니다. List라는 데이터안에 있는 값에서 의미있는 수치를 뽑아야 하는 것이 데이터 분석가가 하는 일이기 때문이다.
이제 간단한 lappy() 함수를 활용해서 간단하게 통계 수치를 뽑도록 한다.
III. lapply()
lapply() 함수는 추후에 apply 함수 계열에 대해서 자세하게 설명할 때 다시한번 드리도록 하겠다. 각각의 apply함수는 input 데이터구조와 output 데이터 구조에 따라 사용되어야 할 함수 이름이 조금씩 다르다.
참고로 lapply인 이유는 output이 리스트로 반환되기 때문에 그렇다.
(1) 사용설명서
필자는 R의 사용설명서를 좋아한다. 예제와 설명이 주로 박사급 사람들이 작성해서 그런가 가독성이 좋다.
꼭 다음을 실행해서 사용설명서를 읽기를 바란다.
help(lapply)
lappy()의 구조는 다음과 같다.
lapply(객체(vector, dataframe, list), FUNCTION)
(2) Without lapply
이제 함수를 적용한다. 이번에 활용하려는 건, 리스트에 저장되어 있는 xNum값의 summary, max, min, mean값을 구하려고 한다.
아래와 같이 적용해야 할 것이다.
summary(xList[[1]])
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 2.605 4.070 4.035 5.500 7.000
max(xList[[1]])
## [1] 7
min(xList[[1]])
## [1] 1
mean(xList[[1]])
## [1] 4.035
위 코드의 단점은 당연히 확장성이 떨어진다. 즉, 1개의 벡터에만 접근이 가능하기 때문에 실무에서는 당연히 쓰지 않는다.
(3) With lapply
이번에는 lapply을 활용해서 값을 구해보자.
lapply(xList, summary)
## [[1]]
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 2.605 4.070 4.035 5.500 7.000
##
## [[2]]
## Length Class Mode
## 4 character character
문자열까지 조회가 되는 것을 확인할 수 있다. 여기에서 조금더 list를 확장해보자. xList에 xNum2 객체를 추가한다.
xNum2 <- c(2, 3, 4, 5)
xList[[3]] <- xNum2
str(xList)
## List of 3
## $ : num [1:4] 1 3.14 5 7
## $ : chr [1:4] "A" "B" "C" "D"
## $ : num [1:4] 2 3 4 5
이렇게 추가가 된 것을 확인할 수 있다.
이제, 애초에 구하려고 했던, max, min, mean 를 구할 수 있습니다. 결과가 어떻게 나오는지 확인합니다.
- max
lapply(xList, max)
## [[1]]
## [1] 7
##
## [[2]]
## [1] "D"
##
## [[3]]
## [1] 5
- min
lapply(xList, min)
## [[1]]
## [1] 1
##
## [[2]]
## [1] "A"
##
## [[3]]
## [1] 2
- mean
lapply(xList, mean)
## Warning in mean.default(X[[i]], ...): argument is not numeric or logical:
## returning NA
## [[1]]
## [1] 4.035
##
## [[2]]
## [1] NA
##
## [[3]]
## [1] 3.5
문자형이 있어도, apply함수에서는 우선 출력됨을 볼 수 있다. 여기에서 문자형의 값 처리에 대한 설명은 본 포스트의 작성 범위를 넘어서게 된다.
R의 기본함수는 다른 언어와 다르게 데이터 타입마다 엄격하게 적용되는 건 아니다! (Why?) 이 부분이 R의 장점이자, 추후에 단점으로 작용하기도 한다.
(4) Naming
각 벡터에 이제 이름을 지어서 List 작성 하면, 원소의 접근법이 보다 수월해진다.
names(xList) <- c("itemNum", "itemChar", "itemNum2")
이제, $name 또는 [["name"]]과 같은 형태로 원소에 접근할 수 있다.
xList$itemNum
## [1] 1.00 3.14 5.00 7.00
이를 통해서 lapply() 활용하면 조금 더 깔끔하게 출력할 수 있다.
lapply(xList, summary)
## $itemNum
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 2.605 4.070 4.035 5.500 7.000
##
## $itemChar
## Length Class Mode
## 4 character character
##
## $itemNum2
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 2.00 2.75 3.50 3.50 4.25 5.00
VI. 결론
List는 R에서 매우 중요하다. 특히, 데이터셋이 꼭 data.frame만 존재하는 것은 아니다.
지도 데이터는 sp라는 객체로 불리어지고, json타입도 존재한다. 이러한 데이터를 다루는데 적합한 데이터 구조가 list이기 때문에 주기적으로 다룰 필요가 있다.
V. Reference
Chapman, C., & Feit, E. M. D. (2015). R for marketing research and analytics. Cham: Springer.
