Tensorflow 2.0 Tutorial ch9.4 - 초해상도
공지
-
본 Tutorial은 교재
시작하세요 텐서플로 2.0 프로그래밍의 강사에게 국비교육 강의를 듣는 사람들에게 자료 제공을 목적으로 제작하였습니다. -
강사의 주관적인 판단으로 압축해서 자료를 정리하였기 때문에, 자세하게 공부를 하고 싶으신 분은 반드시 교재를 구매하실 것을 권해드립니다.

- 본 교재 외에 강사가 추가한 내용에 대한 Reference를 확인하셔서, 추가적으로 학습하시는 것을 권유드립니다.
Tutorial
이전 강의가 궁금하신 분들은 아래에서 선택하여 추가 학습 하시기를 바랍니다.
- Google Colab Tensorflow 2.0 Installation
- Tensorflow 2.0 Tutorial ch3.3.1 - 난수 생성 및 시그모이드 함수
- Tensorflow 2.0 Tutorial ch3.3.2 - 난수 생성 및 시그모이드 함수 편향성
- Tensorflow 2.0 Tutorial ch3.3.3 - 첫번째 신경망 네트워크 - AND
- Tensorflow 2.0 Tutorial ch3.3.4 - 두번째 신경망 네트워크 - OR
- Tensorflow 2.0 Tutorial ch3.3.5 - 세번째 신경망 네트워크 - XOR
- Tensorflow 2.0 Tutorial ch4.1 - 선형회귀
- Tensorflow 2.0 Tutorial ch4.2 - 다항회귀
- Tensorflow 2.0 Tutorial ch4.3 - 딥러닝 네트워크를 이용한 회귀
- Tensorflow 2.0 Tutorial ch4.4 - 보스턴 주택 가격 데이터세트
- Tensorflow 2.0 Tutorial ch5.1 - 분류
- Tensorflow 2.0 Tutorial ch5.2 - 다항분류
- Tensorflow 2.0 Tutorial ch5.3 - Fashion MNIST
- Tensorflow 2.0 Tutorial ch6.1-2 - CNN 이론
- Tensorflow 2.0 Tutorial ch6.3 - Fashion MNIST with CNN 실습
- Tensorflow 2.0 Tutorial ch6.4 - 모형의 성능 높이기
- Tensorflow 2.0 Tutorial ch7.1 - RNN 이론 (1)
- Tensorflow 2.0 Tutorial ch7.1 - RNN 이론 (2)
- Tensorflow 2.0 Tutorial ch7.3 - 긍정, 부정 감성 분석
- Tensorflow 2.0 Tutorial ch7.4 - (1) 단어 단위 생성
- Tensorflow 2.0 Tutorial ch7.4 - (2) 단어 단위 생성
- Tensorflow 2.0 Tutorial ch8.1 - 텐서플로 허브
- Tensorflow 2.0 Tutorial ch8.2 - 전이 학습과 & Kaggle 대회
- Tensorflow 2.0 Tutorial ch8.3.1 - 컨볼루션 신경망을 사용한 텍스처 합성
- Tensorflow 2.0 Tutorial ch8.3.2 - 컨볼루션 신경망을 사용한 신경 스타일 전이
- Tensorflow 2.0 Tutorial ch9.1-2 - 오토인코더 & MNIST
- Tensorflow 2.0 Tutorial ch9.3 - 클러스터링
I. 개요
- 저해상도에서 고해상도의 이미지로 변환하는 것은 어려운 연산입니다.
- 픽셀로 구성된 이미지는 고해상도로 변환(확대)하면 이미지에서 사각형이 두드러져 보이는 것이 바로 초해상도(
Super Resolution) 작업입니다. - 전통적으로는
interpolation(보간)등의 기법이 있지만, 선명함을 잃고 흐릿해지는 단점이 있습니다. - 오토인코더로 초해상도 작업을 하는 과정을 진행합니다.
- 이 때,
REDNet이라는 네트워크를 사용합니다.
II. REDNet1
REDNet은Residual Encoder-Decoder Network의 약자이며,Residual은ResNet등에서 사용하는 건너뛴 연결(skip-connection)입니다.- 다수의 레이어가 중첩되는 구조에서 앞쪽의 정보를 잃어버리기 않기 위해 뒤쪽에 정보를 그대로 전달해줄 때 건너뛴 연결이 사용됩니다.
- 논문에서 사용한 이미지는
BSD (Berkeley Segmentation Dataset)이며, 책에서도 동일하게 사용합니다.
# 텐서플로 2 버전 선택
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
import numpy as np
import pandas as pd
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import cv2
III. 데이터 불러오기
tf.keras.utils.get_file()데이터를 불러옵니다.
tf.keras.utils.get_file('/content/bsd_images.zip', 'http://bit.ly/35pHZlC', extract=True)
Downloading data from http://bit.ly/35pHZlC
37527552/37520292 [==============================] - 0s 0us/step
'/content/bsd_images.zip'
!unzip /content/bsd_images.zip
Archive: /content/bsd_images.zip
creating: images/
creating: images/test/
inflating: images/test/100007.jpg
inflating: images/test/100039.jpg
.
.
.
.
inflating: images/val/97033.jpg
inflating: images/val/Thumbs.db
- 이미지 경로 저장 및 확인을 합니다.
import pathlib
image_root = pathlib.Path('/content/images')
all_images_paths=list(image_root.glob('*/*'))
print(all_images_paths[:10])
[PosixPath('/content/images/val/62096.jpg'), PosixPath('/content/images/val/361010.jpg'), PosixPath('/content/images/val/Thumbs.db'), PosixPath('/content/images/val/54082.jpg'), PosixPath('/content/images/val/87046.jpg'), PosixPath('/content/images/val/38082.jpg'), PosixPath('/content/images/val/156065.jpg'), PosixPath('/content/images/val/33039.jpg'), PosixPath('/content/images/val/14037.jpg'), PosixPath('/content/images/val/159008.jpg')]
- 각 이미지의 경로는
root디렉터리에서glob()함수를 사용해 하단의 모든 파일을 불러올 수 있습니다. - 각 파일의 경로는
PosixPath라는 객체가 되는데, 이 객체에서 경로를 가져오기 위해서는 문자열로 변환하는str()함수를 사용합니다.
(1) 이미지 시각화
matplotlib.pyplot으로 확인합니다.
import PIL.Image as Image
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 12))
for c in range(9):
plt.subplot(3,3,c+1)
plt.imshow(plt.imread(all_images_paths[c]))
plt.title(all_images_paths[c])
plt.axis('off')
plt.show()
/img/tensorflow2.0/tutorial_09_04/output_7_1.png

- 데이터를 보면 아시겠지만, 가로와 세로 길이가 모두 다릅니다. 또한, 이미지의 내용은 사람, 동물, 자연등으로 다양합니다.
(2) 이미지 경로 분리 저장
BSD500은 200장의 훈련 데이터, 100장의 검증 데이터, 200장의 테스트 데이터로 구성되어 있습니다.tf.data.Dataset를 각 데이터세트마다 만듭니다.
train_path, valid_path, test_path = [], [], []
for image_path in all_images_paths:
if str(image_path).split('.')[-1] != "jpg":
continue
if str(image_path).split('/')[-2]== 'train':
train_path.append(str(image_path))
elif str(image_path).split('/')[-2]=='val':
valid_path.append(str(image_path))
else:
test_path.append(str(image_path))
(3) 원본 이미지 조각 추출, 입력, 출력 데이터 변환 함수 정의
- 현재의 이미지는 고해상도이기 때문에, 저해상도는 일부러 낮추고 원본과 함께 반환하는 함수를 만듭니다.
- 원본 이미지에서 조각을 추출해서 입력, 출력 데이터를 생성하는 구조에 관한 이미지는 교재 360페이지를 확인해봅니다.
def get_hr_and_lr(image_path):
img = tf.io.read_file(image_path)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
hr = tf.image.random_crop(img, [50,50,3])
lr = tf.image.resize(hr, [25, 25])
lr = tf.image.resize(lr, [50,50])
return lr, hr
JPEG이미지는tf.io.read_file()로 불러올 수 있습니다.- 이미지를 불러온 후
decode_jpeg()함수를 사용해서 프로그램이 이해할 수 있는 데이터 형태로 만들어야 하고,convert_image_dtype()함수로 데이터 타입을 딥러닝에서 가장 범용적으로 사용하는float32데이터 타입으로 바꿉니다. - 가로 X 세로 50픽셀의 이미지를
random_crop()이라는 함수로 쉽게 얻을 수 있습니다. - 마지막의 3은 컬러 채널의 수를 의미합니다.
(4) train, valid Dataset 정의
Dataset를 정의할 차례이며, 학습 과정에서 사용할 훈련 데이터와 검증 데이터를 사용하는Dataset를 각각 정의합니다.
train_dataset = tf.data.Dataset.list_files(train_path)
train_dataset = train_dataset.map(get_hr_and_lr)
train_dataset = train_dataset.repeat()
train_dataset = train_dataset.batch(16)
valid_dataset = tf.data.Dataset.list_files(train_path)
valid_dataset = valid_dataset.map(get_hr_and_lr)
valid_dataset = valid_dataset.repeat()
valid_dataset = valid_dataset.batch(1)
- 먼저 파일의 경로 리스트를 가지고 있다면
tf.data.Dataset.list_files()함수의 인수로 파일 경로 리스트를 넣어서Dataset를 쉽게 정의할 수 있습니다. get_hr_and_lr()함수를map()함수를 적용해 새로운Dataset을 만듭니다.- 이렇게 연결되면
Dataset는 먼저train_path리스트의 이미지를 불러온 다음에 저해상도와 고해상도 조각인lr,hr을 반환합니다. 여기까지 선언하면 쉽게 사용할 수 있는Dataset을 1차로 완성한 것입니다.
(5) REDNet-30의 정의
REDNet-30에 대한 구조에 대한 설명은 교재 362-363 p를 확인합니다. 다음 소스코드로 네트워크 정의를 합니다.
def REDNet(num_layers):
conv_layers = []
deconv_layers = []
residual_layers = []
inputs = tf.keras.layers.Input(shape=(None, None, 3))
conv_layers.append(tf.keras.layers.Conv2D(3, kernel_size=3, padding='same', activation='relu'))
for i in range(num_layers-1):
conv_layers.append(tf.keras.layers.Conv2D(64, kernel_size=3, padding='same', activation='relu'))
deconv_layers.append(tf.keras.layers.Conv2DTranspose(64, kernel_size=3, padding='same', activation='relu'))
deconv_layers.append(tf.keras.layers.Conv2DTranspose(3, kernel_size=3, padding='same'))
# 인코더 시작
x = conv_layers[0](inputs)
for i in range(num_layers-1):
x = conv_layers[i+1](x)
if i % 2 == 0:
residual_layers.append(x)
# 디코더 시작
for i in range(num_layers-1):
if i % 2 == 1:
x = tf.keras.layers.Add()([x, residual_layers.pop()])
x = tf.keras.layers.Activation('relu')(x)
x = deconv_layers[i](x)
x = deconv_layers[-1](x)
model = tf.keras.Model(inputs=inputs, outputs=x)
return model
- 위 함수를 통해서,
REDNet-10, REDNet-20, REDNet-30등 다양한 네트워크를 함수 호출 한 번으로 만들 수 있습니다. num_layers는 컨볼루션 레이어와 디컨볼루션 레이어의 수입니다. 같은 수의 컨볼루션 레이어가 존재하기 때문에,REDNet-30이라면num_layers=15를 입력하면 됩니다.
conv_layers=[]
deconv_layers=[]
residual_layers=[]
먼저 세 개의 리스트에 각각 컨볼루션 레이어, 디컨볼루션 레이어, 잔류(residual)레이어를 저장합니다.
각 레이어를 따로 저장할 리스트가 별도로 필요로 합니다.
...
inputs = tf.keras.layers.Input(shape=(None, None, 3))
conv_layers.append(tf.keras.layers.Conv2D(3, kernel_size=3, padding='same', activation='relu'))
for i in range(num_layers-1):
conv_layers.append(tf.keras.layers.Conv2D(64, kernel_size=3, padding='same', activation='relu'))
deconv_layers.append(tf.keras.layers.Conv2DTranspose(64, kernel_size=3, padding='same', activation='relu'))
deconv_layers.append(tf.keras.layers.Conv2DTranspose(3, kernel_size=3, padding='same'))
...
- 먼저 입력 레이어를 정의합니다. 입력 레이어의
shape에서 이미지의 높이와 너비를None으로 지정해서 어떤 크기의 이미지라도 입력으로 받을 수 있습니다. - 첫 번째 컨볼루션 레이어와 마지막 디컨볼루션 레이어를 제외한 레이어들은
for문 안에서 정의해서 각 리스트에 저장합니다. - 첫번째 컨볼루션 레이어와 마지막 디컨볼루션 레이어는 필터의 수가 다른데 이는 필터의 수로
RGB채널의 수인3을 그대로 받기 위함입니다. 나머지 레이어에서는 64개의 필터를 사용합니다.
# 인코더 시작
x = conv_layers[0](inputs)
for i in range(num_layers-1):
x = conv_layers[i+1](x)
if i % 2 == 0:
residual_layers.append(x)
# 디코더 시작
for i in range(num_layers-1):
if i % 2 == 1:
x = tf.keras.layers.Add()([x, residual_layers.pop()])
x = tf.keras.layers.Activation('relu')(x)
x = deconv_layers[i](x)
x = deconv_layers[-1](x)
- 여기에서는
x라는 변수에 레이어를 계속 적용해서 함수형API를 사용합니다. 마지막에x는 모든 레이어가 적용된 결과가 되기 때문에 모델의 출력이 됩니다. - 이렇게 하나의 변수 이름을 재사용하여 레이어를 적용해나가는 방법은 케라스의 함수형
API나torch에서 일반적으로 쓰이는 문법입니다. - 첫번째 명령인
x = conv_layers[0](inputs)의 결과로x는 입력 레이어에 첫 번째 컨볼루션 레이어를 적용한 결과가 됩니다.
for i in range(num_layers-1):
x = conv_layers[i+1](x)
if i % 2 == 0:
residual_layers.append(x)
- 그 다음으로는
for문 안에서x에 나머지 컨볼루션 레이어를 계속 적용시키며, 짝수번재 컨볼루션 레이어를 지날 때마다x를 잔류 레이어 리스트에도 저장합니다. - 잔류 레이어에
x를 저장한 다음 스텝에서x는 다시 컨볼루션 레이어를 통과해서 새로운 값이 되지만 잔류 레이어에 이미 저장된 값은 사라지지 않습니다. - 교재 366페이지에 그림설명이 있기 때문에 한번 더 확인하시기를 바랍니다.
# 디코더 시작
for i in range(num_layers-1):
if i % 2 == 1:
x = tf.keras.layers.Add()([x, residual_layers.pop()])
x = tf.keras.layers.Activation('relu')(x)
x = deconv_layers[i](x)
x = deconv_layers[-1](x)
- 두 번째
for문 안에서는 홀수 번째의 디컨볼루션 레이어를 통과할 경우 잔류 레이어 리스트에 저장돼 있던 값을residual_layers.pop()으로 뒤에서부터 하나씩 가져옵니다. 그 다음 합연산과ReLU활성화함수를 통과한 후 다음 디컨볼루션 레이어에 연결시킵니다. - 짝수 번째일 때는 디컨볼루션 레이어만 연결합니다.
model = tf.keras.Model(inputs=inputs, outputs=x)
tf.keras의 함수형API로Model을 만들기 위해서는 입력과 출력만 지정하면 됩니다.- 입력인
inputs는 함수의 가장 앞에서 정의한 입력 레이어로, 출력인outputs는 지금까지 레이어 연산을 쭉 따라온 변수 이름인x로 넣고,model을 반환합니다.
(6) PSNR 계산 공식 및 함수 정의
- 고해상도 이미지가 잘 복원됐는지 알기 위해서 특별한 측정값을 컴파일에 추가해서 테스트할 수 있습니다.
- 이 측정값은
PSNR(Peak Signal-to-Noise Ratio), 즉 “신호 대 잡임비"입니다. PSNR의 계산 공식은 다음과 같습니다.
$$PSNR = 20\ast log_{10}\frac{Max(pixel)}{\sqrt{MSE}}$$
- 여기서
Max(pixel)은 픽셀의 최대값으로, 앞에서float32로 계산했기 때문에 이 값은1.0이 됩니다. MSE는 우리가 잘 알고 있는 평균 제곱 오차(Mean Squared Error)입니다.- 평균 제곱 오차가 로그의 분모에 있기 때문에 이 식은 평균 제곱 오차가 낮을수록 큰 값을 갖게 됩니다.
def psnr_metric(y_true, y_pred):
return tf.image.psnr(y_true, y_pred, max_val=1.0)
Metric은 분류의 정확도(accuracy)처럼tf.keras에 등록되어 있을 경우 그대로 사용하면 되지만PSNR은 지원하지 않기 때문에 함수를 만들어줍니다.y_true는 정답에 해당하는 값이고,y_pred는 네트워크가 학습 결과 예측한 값입니다.- 이 둘의
tf.image.psnr()을 계산해서 반환하는 것이psnr_metric()함수의 역할입니다.
(7) REDNet-30 네트워크 초기화 및 컴파일
- 이제
REDNet()함수로 네트워크를 초기화하고 컴파일합니다.
model = REDNet(15)
model.compile(optimizer=tf.optimizers.Adam(0.0001), loss='mse', metrics=[psnr_metric])
- 컴파일된 네트워크 시각화를 작성해봅니다.
tf.keras.utils.plot_model(model)
(8) REDNet-30 네트워크 학습
- 이제 네트워크를 학습합니다.
history = model.fit_generator(train_dataset,
epochs=1000,
steps_per_epoch=len(train_path)//16,
validation_data=valid_dataset,
validation_steps=len(valid_path),
verbose=2)
WARNING:tensorflow:From <ipython-input-15-11785503027a>:6: Model.fit_generator (from tensorflow.python.keras.engine.training) is deprecated and will be removed in a future version.
Instructions for updating:
Please use Model.fit, which supports generators.
Epoch 1/1000
12/12 - 4s - loss: 0.2467 - psnr_metric: 7.6192 - val_loss: 0.2287 - val_psnr_metric: 8.1383
Epoch 2/1000
12/12 - 3s - loss: 0.1935 - psnr_metric: 8.8387 - val_loss: 0.0982 - val_psnr_metric: 11.4855
.
.
.
Epoch 998/1000
12/12 - 3s - loss: 0.0015 - psnr_metric: 32.7882 - val_loss: 0.0013 - val_psnr_metric: 32.6776
Epoch 999/1000
12/12 - 3s - loss: 0.0015 - psnr_metric: 32.2986 - val_loss: 0.0015 - val_psnr_metric: 32.9123
Epoch 1000/1000
12/12 - 3s - loss: 0.0015 - psnr_metric: 32.4111 - val_loss: 0.0014 - val_psnr_metric: 32.6642
Dataset를 이용한 학습은fit()함수 대신fit_generator()함수를 사용합니다.Dataset에repeat()함수를 사용했기 때문에 한 번의 에포크에 몇 개의 데이터를 학습시킬지를 지정하는steps_per_epoch인수를 설정해야 합니다.batch size가 16이기 때문에steps_per_epoch는len(train_path)//16으로 훈련 데이터의 크기를batch size로 나눕니다.- //는 결과가 정수로 나오는 나눗셈을 의미합니다. 예를 들면 200//16의 결과는 12가 됩니다.
verbose=2의 의미니느 출력제한에 걸리지 않도록 하며, 진행 상황 애니메이션은 생략하고 각 에포크의 결과만 출력합니다.- 학습 결과, 훈련 데이터의
PSNR은 31~32, 검증데이터의 29-32정도가 나옵니다.
(9) 네트워크 학습 결과 확인
학습 겨로가를 확인합니다.
import matplotlib.pyplot as plt
plt.plot(history.history['psnr_metric'], 'b-', label='psnr')
plt.plot(history.history['val_psnr_metric'], 'r--', label='val_psnr')
plt.xlabel('Epoch')
plt.legend()
plt.show()
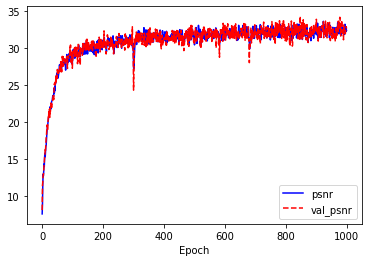
PSNR 수치 모두 학습할수록 증가하는 경향을 보입니다. 이렇게 학습된 데이터가 실제 이미지를 어떻게 복원하는지 확인합니다.
img = tf.io.read_file(test_path[0])
img = tf.image.decode_jpeg(img, channels=3)
hr = tf.image.convert_image_dtype(img, tf.float32)
lr = tf.image.resize(hr, [hr.shape[0]//2, hr.shape[1]//2])
lr = tf.image.resize(lr, [hr.shape[0], hr.shape[1]])
predict_hr=model.predict(np.expand_dims(lr, axis=0))
print(tf.image.psnr(np.squeeze(predict_hr, axis=0), hr, max_val=1.0))
print(tf.image.psnr(lr, hr, max_val=1.0))
tf.Tensor(26.110872, shape=(), dtype=float32)
tf.Tensor(24.853115, shape=(), dtype=float32)
(10) 테스트 이미지에 대한 초해상도 결과 확인
- 테스트 데이터 중 첫 번째 이미지를 불러와서 저해상도 버전을 만든 다음
REDNet-30네트워크에 통과시켜서 복원 이미지를 얻어냅니다. - 결과에서
PSNR점수는 복원 이미지가 저해상도 이미지보다 아주 살짝 높은 것으로 나옵니다. - 이미지를 출력합니다.
plt.figure(figsize=(16,4))
plt.subplot(1,3,1)
plt.imshow(hr)
plt.title('original - hr')
plt.subplot(1,3,2)
plt.imshow(lr)
plt.title('lr')
plt.subplot(1,3,3)
plt.imshow(np.squeeze(predict_hr, axis=0))
plt.title('sr')
plt.show()
- 첫번째 사진이 이미지의 원본이고, 두번째 사진이 저해상도, 세번째 줄이 복원된 이미지입니다.
- 이 작업의 성능을 비교하기 위해
Set5라는 데이터세트가 있습니다. 이 중에서도 자주 쓰이는 나비의 사진을 불러와서 확인합니다.
image_path = tf.keras.utils.get_file('butterfly.png', 'http://bit.ly/2oAOxgH')
img = tf.io.read_file(image_path)
img = tf.image.decode_jpeg(img, channels=3)
hr = tf.image.convert_image_dtype(img, tf.float32)
lr = tf.image.resize(hr, [hr.shape[0]//4, hr.shape[1]//4])
lr = tf.image.resize(lr, [hr.shape[0], hr.shape[1]])
predict_hr = model.predict(np.expand_dims(lr, axis=0))
print(tf.image.psnr(np.squeeze(predict_hr, axis=0), hr, max_val=1.0))
print(tf.image.psnr(lr, hr, max_val=1.0))
plt.figure(figsize=(16,6))
plt.subplot(1, 3, 1)
plt.imshow(hr)
plt.title('original - hr')
plt.subplot(1, 3, 2)
plt.imshow(lr)
plt.title('lr')
plt.subplot(1, 3, 3)
plt.imshow(np.squeeze(predict_hr, axis=0))
plt.title('sr')
Downloading data from http://bit.ly/2oAOxgH
131072/127529 [==============================] - 0s 0us/step
tf.Tensor(20.3429, shape=(), dtype=float32)
tf.Tensor(20.217585, shape=(), dtype=float32)
Text(0.5, 1.0, 'sr')

- 벤치마크답게
PSNR점수에서 성능 차이가 뚜렷하게 드러납니다. - 조금 더 어려운 과제로는 확대 비율을 늘려볼 수 있습니다. 현재는 2배인데, 이를 4배로 늘려봅니다.
(11) 확대비율 4배로 수정, 이미지 보강 REDNet-30 네트워크 학습
Dataset에서는 쉽게 이미지 보강을 할 수 있습니다. 이미지에서 랜덤한 부분을 잘라서 고해상도와 저해상도 버전을 추출하던 get_hr_and_lr() 함수를 다음과 같이 바꿉니다.
import random
def get_hr_and_lr_flip_s4(image_path):
img = tf.io.read_file(image_path)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
hr = tf.image.random_crop(img, [50,50,3])
lr = tf.image.resize(hr, [12, 12])
lr = tf.image.resize(lr, [50,50])
if random.random() < 0.25:
hr = tf.image.flip_left_right(hr)
lr = tf.image.flip_left_right(lr)
if random.random() < 0.25:
hr = tf.image.flip_up_down(hr)
lr = tf.image.flip_up_down(lr)
return lr, hr
- 앞부분은 축소/확대 비율을 2배에서 4배로 바꾸는 부분을 제외하면
get_hr_and_lr()함수와 같고, 뒤쪽에서25%의 확률로 좌우 반전, 또25%의 확률로 상하 반전을 시켜줍니다. - 결과적으로
Dataset을 다시 정의하고 바뀐 함수를 적용합니다.
(12) REDNet-30 네트워크 학습
train_dataset = tf.data.Dataset.list_files(train_path)
train_dataset = train_dataset.map(get_hr_and_lr_flip_s4)
train_dataset = train_dataset.repeat()
train_dataset = train_dataset.batch(16)
valid_dataset = tf.data.Dataset.list_files(valid_path)
valid_dataset = valid_dataset.map(get_hr_and_lr_flip_s4)
valid_dataset = valid_dataset.repeat()
valid_dataset = valid_dataset.batch(1)
model = REDNet(15)
model.compile(optimizer=tf.optimizers.Adam(0.0001), loss='mse', metrics=[psnr_metric])
history = model.fit_generator(train_dataset,
epochs=4000,
steps_per_epoch=len(train_path)//16,
validation_data=valid_dataset,
validation_steps=len(valid_path),
verbose=2)
12/12 - 3s - loss: 0.0046 - psnr_metric: 27.3362 - val_loss: 0.0050 - val_psnr_metric: 27.4308
Epoch 3548/4000
12/12 - 3s - loss: 0.0046 - psnr_metric: 26.8918 - val_loss: 0.0045 - val_psnr_metric: 26.7091
.
.
.
Epoch 3999/4000
12/12 - 3s - loss: 0.0048 - psnr_metric: 26.8295 - val_loss: 0.0055 - val_psnr_metric: 25.5176
Epoch 4000/4000
12/12 - 3s - loss: 0.0046 - psnr_metric: 27.5956 - val_loss: 0.0048 - val_psnr_metric: 27.2664
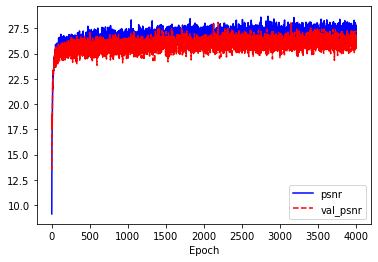
- 이미지 보강으로 데이터가 4배 정도 늘어난 것과 같은 효과이기 때문에 에포크를 1,000에서 4,000으로 늘렸씁니다.
Set5의 나비 이미지를 테스트해보면 다음과 같은 결과가 나옵니다.
(13) 학습 결과 확인 및 Set5 이미지 시각화
import matplotlib.pyplot as plt
plt.plot(history.history['psnr_metric'], 'b-', label='psnr')
plt.plot(history.history['val_psnr_metric'], 'r--', label='val_psnr')
plt.xlabel('Epoch')
plt.legend()
plt.show()
image_path = tf.keras.utils.get_file('butterfly.png', 'http://bit.ly/2oAOxgH')
img = tf.io.read_file(image_path)
img = tf.image.decode_jpeg(img, channels=3)
hr = tf.image.convert_image_dtype(img, tf.float32)
lr = tf.image.resize(hr, [hr.shape[0]//4, hr.shape[1]//4])
lr = tf.image.resize(lr, [hr.shape[0], hr.shape[1]])
predict_hr = model.predict(np.expand_dims(lr, axis=0))
print(tf.image.psnr(np.squeeze(predict_hr, axis=0), hr, max_val=1.0))
print(tf.image.psnr(lr, hr, max_val=1.0))
plt.figure(figsize=(16,6))
plt.subplot(1, 3, 1)
plt.imshow(hr)
plt.title('original - hr')
plt.subplot(1, 3, 2)
plt.imshow(lr)
plt.title('lr')
plt.subplot(1, 3, 3)
plt.imshow(np.squeeze(predict_hr, axis=0))
plt.title('sr')
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
tf.Tensor(22.349665, shape=(), dtype=float32)
tf.Tensor(20.217585, shape=(), dtype=float32)
Text(0.5, 1.0, 'sr')

- 이미지를 불러온 다음 각 이미지에 대한 저해상도 버전과 복원 이미지의
PSNR점수를 구해서 평균을 비교합니다.
image_path = tf.keras.utils.get_file('/content/Set5.zip', 'http://bit.ly/2MEG4kr')
!unzip Set5.zip
Downloading data from http://bit.ly/2MEG4kr
860160/852576 [==============================] - 0s 0us/step
Archive: Set5.zip
creating: Set5/
extracting: Set5/baby.png
extracting: Set5/bird.png
extracting: Set5/butterfly.png
extracting: Set5/head.png
inflating: Set5/woman.png
set5_image_root = pathlib.Path('/content/Set5')
set5_image_paths = list(set5_image_root.glob('*.*'))
sr_psnr = []
lr_psnr = []
for image_path in set5_image_paths:
img = tf.io.read_file(str(image_path))
img = tf.image.decode_jpeg(img, channels=3)
hr = tf.image.convert_image_dtype(img, tf.float32)
lr = tf.image.resize(hr, [hr.shape[0]//4, hr.shape[1]//4])
lr = tf.image.resize(lr, [hr.shape[0], hr.shape[1]])
predict_hr = model.predict(np.expand_dims(lr, axis=0))
sr_psnr.append(tf.image.psnr(np.squeeze(predict_hr, axis=0), hr, max_val=1.0).numpy())
lr_psnr.append(tf.image.psnr(lr, hr, max_val=1.0).numpy())
print('sr:', sr_psnr)
print('sr mean:', np.mean(sr_psnr))
print()
print('lr:', lr_psnr)
print('lr mean:', np.mean(lr_psnr))
WARNING:tensorflow:5 out of the last 5 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7fc446f63158> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings is likely due to passing python objects instead of tensors. Also, tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. Please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.
sr: [28.628256, 22.349665, 25.808668, 27.925306, 30.419857]
sr mean: 27.026352
lr: [28.569517, 20.217585, 24.495182, 27.31659, 29.72251]
lr mean: 26.064276
- 복원 이미지의
PSNR점수가 저해상도 버전보다 전반적으로 높게 나타나는 것을 확인할 수 있습니다. - 4배 확대 초해상도에 대한 벤치마크 사이트에서
REDNet-30은Set5이미지에 대해 최고 31.51점의PSNR점수를 기록하고 있습니다. - 학습을 시킬수록
PSNR점수는 증가하는 경향을 보이기 때문에 과적합되지 않을 정도로 충분한 에포크 동안 학습시키고 입력 이미지를 다양하게 만들어서 더 좋은PSNR점수를 얻을 수 있을 겁니다.
IV. 연습 파일
V. Reference
김환희. (2020). 시작하세요! 텐서플로 2.0 프로그래밍: 기초 이론부터 실전 예제까지 한번에 끝내는 머신러닝, 딥러닝 핵심 가이드. 서울: 위키북스.
-
X. Mao, C. Shen, and Y. Yang. (2016, September 1). Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections. Retrieved from https://arxiv.org/abs/1603.09056 ↩︎
