Tensorflow 2.0 Tutorial ch9.1-2 - 오토인코더 & MNIST
공지
-
본 Tutorial은 교재
시작하세요 텐서플로 2.0 프로그래밍의 강사에게 국비교육 강의를 듣는 사람들에게 자료 제공을 목적으로 제작하였습니다. -
강사의 주관적인 판단으로 압축해서 자료를 정리하였기 때문에, 자세하게 공부를 하고 싶으신 분은 반드시 교재를 구매하실 것을 권해드립니다.

- 본 교재 외에 강사가 추가한 내용에 대한 Reference를 확인하셔서, 추가적으로 학습하시는 것을 권유드립니다.
Tutorial
이전 강의가 궁금하신 분들은 아래에서 선택하여 추가 학습 하시기를 바랍니다.
- Google Colab Tensorflow 2.0 Installation
- Tensorflow 2.0 Tutorial ch3.3.1 - 난수 생성 및 시그모이드 함수
- Tensorflow 2.0 Tutorial ch3.3.2 - 난수 생성 및 시그모이드 함수 편향성
- Tensorflow 2.0 Tutorial ch3.3.3 - 첫번째 신경망 네트워크 - AND
- Tensorflow 2.0 Tutorial ch3.3.4 - 두번째 신경망 네트워크 - OR
- Tensorflow 2.0 Tutorial ch3.3.5 - 세번째 신경망 네트워크 - XOR
- Tensorflow 2.0 Tutorial ch4.1 - 선형회귀
- Tensorflow 2.0 Tutorial ch4.2 - 다항회귀
- Tensorflow 2.0 Tutorial ch4.3 - 딥러닝 네트워크를 이용한 회귀
- Tensorflow 2.0 Tutorial ch4.4 - 보스턴 주택 가격 데이터세트
- Tensorflow 2.0 Tutorial ch5.1 - 분류
- Tensorflow 2.0 Tutorial ch5.2 - 다항분류
- Tensorflow 2.0 Tutorial ch5.3 - Fashion MNIST
- Tensorflow 2.0 Tutorial ch6.1-2 - CNN 이론
- Tensorflow 2.0 Tutorial ch6.3 - Fashion MNIST with CNN 실습
- Tensorflow 2.0 Tutorial ch6.4 - 모형의 성능 높이기
- Tensorflow 2.0 Tutorial ch7.1 - RNN 이론 (1)
- Tensorflow 2.0 Tutorial ch7.1 - RNN 이론 (2)
- Tensorflow 2.0 Tutorial ch7.3 - 긍정, 부정 감성 분석
- Tensorflow 2.0 Tutorial ch7.4 - (1) 단어 단위 생성
- Tensorflow 2.0 Tutorial ch7.4 - (2) 단어 단위 생성
- Tensorflow 2.0 Tutorial ch8.1 - 텐서플로 허브
- Tensorflow 2.0 Tutorial ch8.2 - 전이 학습과 & Kaggle 대회
- Tensorflow 2.0 Tutorial ch8.3.1 - 컨볼루션 신경망을 사용한 텍스처 합성
- Tensorflow 2.0 Tutorial ch8.3.2 - 컨볼루션 신경망을 사용한 신경 스타일 전이
I. 개요
- 오토인코더(
AutoEncoder)는 입력에 대한 출력을 학습해야 한다는 점은 기존 지도학습 네트워크와 동일합니다. - 그러나 그 출력이 입력과 동일하다는 점이 조금 다릅니다.
- 오토인코더는 자기 자신을 재생성하는 네트워크입니다.
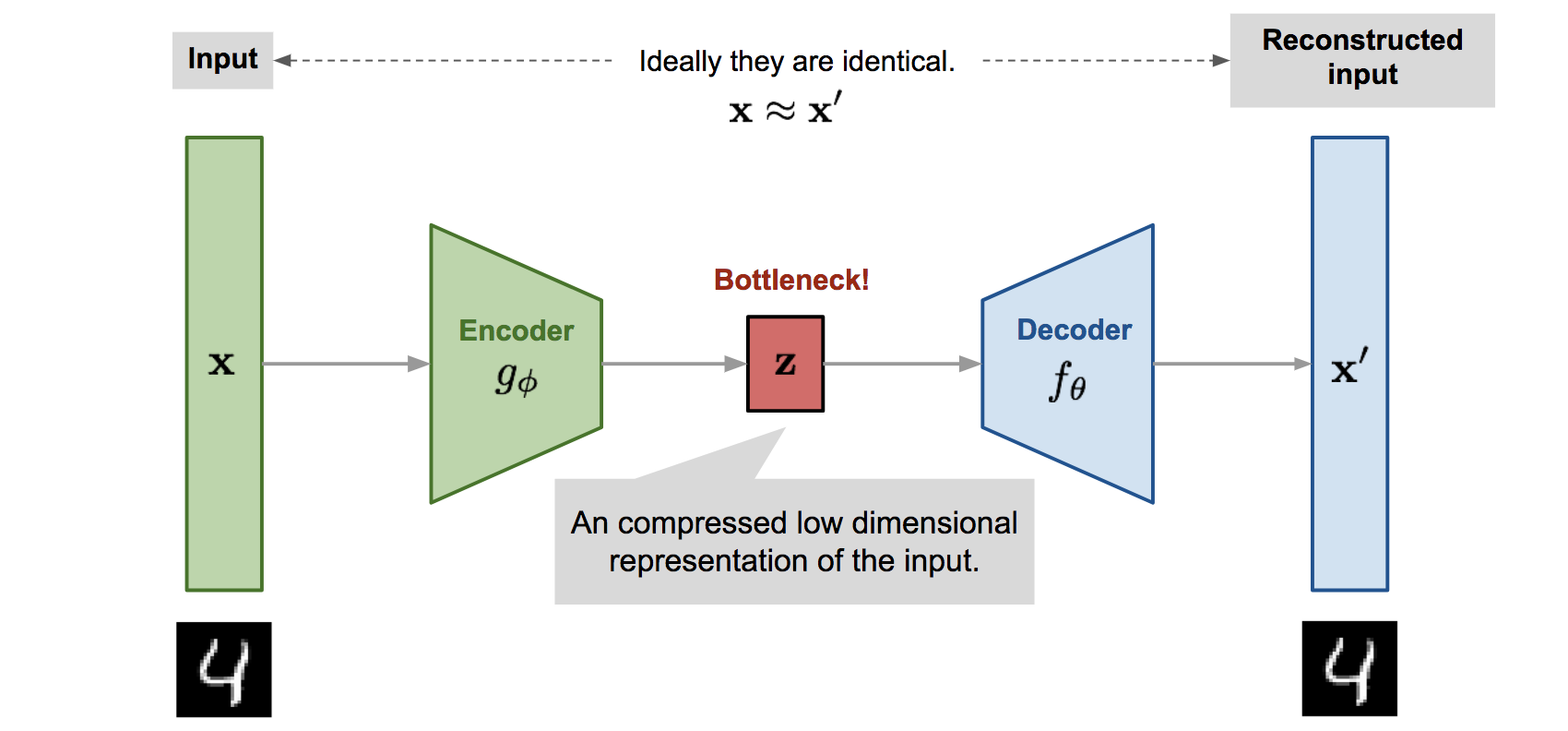
-
위 그림에서 보는 것처럼, 오토인코더는 크게 3가지 부분으로 구성됩니다.
z는 잠재 변수(Latent Vector)를 중심으로, 입력에 가까운 부분을 인코더(Encoder), 출력에 가까운 부분을 디코더(Decoder)라 분류합니다.
-
인코더의 역할은
입력에서잠재 변수를 만드는 것입니다. -
디코더의 역할은
잠재 변수를출력으로 만드는 것입니다. -
위 그림이 잠재변수를 기준으로 하나의 대칭구조를 이루는 것처럼, 레이어 역시 대칭되는 구조로 쌓아올려서 만듭니다.
-
음. 조금 쉽게 얘기하면, 오토인코더는 일종의 파일 압축과 유사합니다. 압축 파일은 압축하기 전과 압축을 해제한 뒤의 내용이 동일합니다. 컴퓨터공학 용어로 이러한 내용을 비손실 압축이라고 합니다. 내용적으로는 그러합니다.
-
그러나,
$x$와$x^i$의 차이점처럼 유사하지만 동일하지는 않습니다. 즉, 오토인코더는 손실 압축이라고 표현합니다. -
딥러닝 생성 모델 중 최근 가장 주목받고 있는 적대적 생성 모델(
Generative Adversarial Network이하GAN)의 생성자에서는 랜덤하게 생성된 변수를 잠재변수처럼 활용해서 새로운 이미지를 얻습니다.
II. MNIST 데이터세트에 적용하기
6장에서 다룬 MNIST 데이터셋을 활용해서 재실습하도록 합니다.
(1) 모듈 설치 및 데이터세트 확인
- 데이터는 (
train_X,train_Y), (test_X,test_Y)처럼 훈련 데이터와 테스트 데이터의 튜플 쌍으로 불러 올 수 있습니다. - 데이터를 로드한 후에
train_X와test_X를 255.0으로 나눠서 픽셀 정규화를 하게 됩니다. - 데이터가 잘 불러와졌는지 시각화를 통해 확인합니다.
# 텐서플로 2 버전 선택
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
import numpy as np
import pandas as pd
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import cv2
(train_X, train_Y), (test_X, test_Y) = tf.keras.datasets.mnist.load_data()
print(train_X.shape, train_Y.shape)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11493376/11490434 [==============================] - 0s 0us/step
(60000, 28, 28) (60000,)
train_X = train_X / 255.0
test_X = test_X / 255.0
plt.imshow(train_X[0].reshape(28, 28), cmap='gray')
plt.colorbar()
plt.show()
print(train_Y[0])
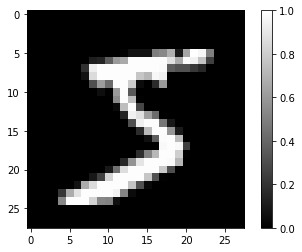
5
MNIST는Fashion MNIST처럼 가로와 세로가 각각 28픽셀인 흑백 이미지를 입력으로 하고, 0~9까지의 숫자를 출력으로 합니다. (5장과 6장 참조)
(2) Dense 오토인코더 모델 정의
Dense 오토인코더 모델을 다음과 같이 정의합니다.
train_X = train_X.reshape(-1, 28 * 28)
test_X = test_X.reshape(-1, 28 * 28)
print(train_X.shape, train_Y.shape)
(60000, 784) (60000,)
model = tf.keras.Sequential([
tf.keras.layers.Dense(784, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(784, activation='sigmoid')
])
model.compile(optimizer=tf.optimizers.Adam(), loss='mse')
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 784) 615440
_________________________________________________________________
dense_4 (Dense) (None, 64) 50240
_________________________________________________________________
dense_5 (Dense) (None, 784) 50960
=================================================================
Total params: 716,640
Trainable params: 716,640
Non-trainable params: 0
_________________________________________________________________
- 입력데이터를 처리하기 위해
Flatten레이어를 사용하는 대신train_X와test_X의 차원을 직접reshape()함수로 변환했습니다. 그 이유는 입력과 출력의 형태가 같아야 하기 때문입니다. - 입력을 변환하지 않은 채로
Flatten레이어를 넣어서 (28, 28) 차원의 입력을 넣으면 뒤에서도 출력의 차원을 (28, 28)로 맞추기 위해Reshape레이어를 사용해야 하는 번거로움이 있습니다. (구조에 대한 이해 필요) - dense와 dense_2의 레이어는 뉴런의 수가 같아서 대칭을 이루며, 각각 인코더와 디코더의 역할을 합니다.
- desne_1는 잠재변수로 뉴런의 수가 적은 것을 확인할 수 있습니다.
(3) Dense 오토 인코더 모델 학습
이제 모형을 학습시킵니다.
model.fit(train_X, train_X, epochs=10, batch_size=256)
Epoch 1/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0507
Epoch 2/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0178
Epoch 3/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0122
Epoch 4/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0101
Epoch 5/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0089
Epoch 6/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0082
Epoch 7/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0077
Epoch 8/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0073
Epoch 9/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0069
Epoch 10/10
235/235 [==============================] - 1s 5ms/step - loss: 0.0067
<tensorflow.python.keras.callbacks.History at 0x7f63a332b0b8>
(4) 모형 시각화
실제로 모형이 잘 학습되었는지 시각화를 통해 확인합니다.
import random
plt.figure(figsize=(4,8))
for c in range(4):
plt.subplot(4, 2, c*2+1)
rand_index = random.randint(0, test_X.shape[0])
plt.imshow(test_X[rand_index].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.subplot(4, 2, c*2+2)
img = model.predict(np.expand_dims(test_X[rand_index], axis=0))
plt.imshow(img.reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
model.evaluate(test_X, test_X)
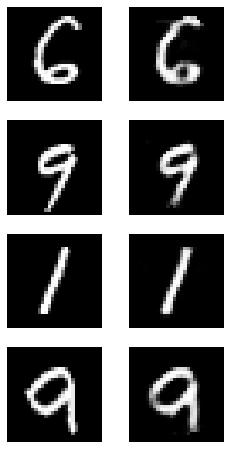
313/313 [==============================] - 1s 2ms/step - loss: 0.0063
0.006336142309010029
(5) CNN 모형 신경망 업데이트
더 좋은 성과를 내기 위해 CNN을 활용하도록 합니다. 모형 정의를 다시 해봅니다.
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=2, strides=(2,2), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=64, kernel_size=2, strides=(2,2), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(7*7*64, activation='relu'),
tf.keras.layers.Reshape(target_shape=(7,7,64)),
tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=2, strides=(2,2), padding='same', activation='relu'),
tf.keras.layers.Conv2DTranspose(filters=1, kernel_size=2, strides=(2,2), padding='same', activation='sigmoid')
])
model.compile(optimizer=tf.optimizers.Adam(), loss='mse')
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 14, 14, 32) 160
_________________________________________________________________
conv2d_1 (Conv2D) (None, 7, 7, 64) 8256
_________________________________________________________________
flatten (Flatten) (None, 3136) 0
_________________________________________________________________
dense_6 (Dense) (None, 64) 200768
_________________________________________________________________
dense_7 (Dense) (None, 3136) 203840
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 14, 14, 32) 8224
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 28, 28, 1) 129
=================================================================
Total params: 421,377
Trainable params: 421,377
Non-trainable params: 0
_________________________________________________________________
하나씩 살펴보도록 합니다.
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
- 먼저,
train_X와train_Y부분에 대한 설명입니다. - 흑백 이미지이기 때문에 마지막 차원의 수는 1입니다.
tf.keras.layers.Conv2D(filters=32, kernel_size=2, strides=(2,2), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=64, kernel_size=2, strides=(2,2), activation='relu'),
...
- Conv2D 레이어를 2개 쌓았습니다.
- 그런데, 풀링 레이어가 빠져 있습니다. 대신에
kernel_size=2,strides=(2,2)로 설정해서 풀링 레이어를 쓰는 것과 같은 효과를 줍니다. - Conv2D를 통과할 때마다 50%씩 감소하여 두번째
Conv2D를 통과하면 이미지의 크지는7X7이 됩니다.
...,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
...
- 3차원의 데이터를 1차원으로 바꿔주기 위해
Flatten()을 통과해야 합니다. - 그 다음에는 잠재 변수를 만들기 위해
Dense오토인코더와 동일한 크기로 64개의 뉴런을 가지는Dense레이어를 배치합니다.
tf.keras.layers.Dense(7*7*64, activation='relu')
- 잠재 변수를 만든 다음에는 디코더를 만듭니다. 디코더는 인코더와 대칭이 되도록 다시 쌓아올립니다. 잠재변수 레이어와 연결된 레이어는
7X7이미지를 만들기 위해 64개의 채널만큼 가지고 있는Conv2D레이어입니다. - 레이어와 뉴런수를 동일하게 만들기 위해서
Dense레이어의 뉴런 수를7*7*64로 넣습니다.
tf.keras.layers.Reshape(target_shape=(7,7,64))
- 1차원인 데이터를 3차원으로 바꿔주기 위해 64개의 채널만큼
Reshape레이어를 사용합니다.
tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=2, strides=(2,2), padding='same', activation='relu'),
tf.keras.layers.Conv2DTranspose(filters=1, kernel_size=2, strides=(2,2), padding='same', activation='sigmoid')
- 마지막으로 이어지는 2개의 레이어는
Conv2DTranspose입니다. - Conv2D레이어가 하는 일의 반대되는 계산으로 이해하면 됩니다. (즉, 이 함수를 쓰는 이유는 대칭 구조를 만들기 위함입니다.)
- 필터의 개수가 1인 것은 흑백이인 출력 이미지와 같습니다.
(6) CNN 모형 학습
- 이제 모형을 학습시킵니다.
model.fit(train_X, train_X, epochs=10, batch_size=256)
Epoch 1/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0757
Epoch 2/10
235/235 [==============================] - 2s 8ms/step - loss: 0.0322
Epoch 3/10
235/235 [==============================] - 2s 8ms/step - loss: 0.0247
Epoch 4/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0222
Epoch 5/10
235/235 [==============================] - 2s 8ms/step - loss: 0.0211
Epoch 6/10
235/235 [==============================] - 2s 8ms/step - loss: 0.0204
Epoch 7/10
235/235 [==============================] - 2s 8ms/step - loss: 0.0200
Epoch 8/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0197
Epoch 9/10
235/235 [==============================] - 2s 8ms/step - loss: 0.0195
Epoch 10/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0193
<tensorflow.python.keras.callbacks.History at 0x7f63a0fa5438>
(7) 오토인코더의 이미지 재생성 및 모형 성능 평가
- 얼마나 잘 재현하는지 확인해봅니다.
import random
plt.figure(figsize=(4,8))
for c in range(4):
plt.subplot(4, 2, c*2+1)
rand_index = random.randint(0, test_X.shape[0])
plt.imshow(test_X[rand_index].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.subplot(4, 2, c*2+2)
img = model.predict(np.expand_dims(test_X[rand_index], axis=0))
plt.imshow(img.reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
model.evaluate(test_X, test_X)

313/313 [==============================] - 1s 3ms/step - loss: 0.0188
0.01879417710006237
보면 알겠지만, 조금 이상합니다. 왜 이상할까요? 이 때 한번 고민해야 하는 것이 활성화함수(=activation)입니다.
- 마지막 레이어를 제외하면
relu를 사용했습니다. relu는 양수는 그대로 반환하고 0이나 음수가 들어오면 0을 반환합니다. 즉, 이말은 뉴런의 계산값 중 음수가 되는 결과가 많을 경우 뉴런의 출력은 무조건 0이 됩니다.- 출력이 0인건 알겠는데, 왜 그게 문제가 될까요? 출력은 다음 레이어의 가중치에 곱해지기 때문에 출력이 0이면 가중치의 효과를 모두 0으로 만들어버립니다. (교재 340페이지 문제점에 대해 이미지로 표현되었으니 꼭 확인 바랍니다.
- 이러한 문제점을 해결하고자
elu라는 개념이 도입되었습니다. (이론은 교재 340페이지를 확인합니다!)- 간단하게 표현하면
Relu와 다르게elu는 0으로 수렴하지 않고-1로 수렴하게 됩니다.
- 간단하게 표현하면
(8) elu의 적용
- 이제
elu로 바꾼 후 모형을 재학습 시킵니다. - 반복되는 내용이기 때문에 전체 코드로 시각화까지 확인합니다.
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32, kernel_size=2, strides=(2,2), activation='elu', input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(filters=64, kernel_size=2, strides=(2,2), activation='elu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='elu'),
tf.keras.layers.Dense(7*7*64, activation='elu'),
tf.keras.layers.Reshape(target_shape=(7,7,64)),
tf.keras.layers.Conv2DTranspose(filters=32, kernel_size=2, strides=(2,2), padding='same', activation='elu'),
tf.keras.layers.Conv2DTranspose(filters=1, kernel_size=2, strides=(2,2), padding='same', activation='sigmoid')
])
model.compile(optimizer=tf.optimizers.Adam(), loss='mse')
model.summary()
model.fit(train_X, train_X, epochs=10, batch_size=256)
import random
plt.figure(figsize=(4,8))
for c in range(4):
plt.subplot(4, 2, c*2+1)
rand_index = random.randint(0, test_X.shape[0])
plt.imshow(test_X[rand_index].reshape(28, 28), cmap='gray')
plt.axis('off')
plt.subplot(4, 2, c*2+2)
img = model.predict(np.expand_dims(test_X[rand_index], axis=0))
plt.imshow(img.reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()
model.evaluate(test_X, test_X)
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 14, 14, 32) 160
_________________________________________________________________
conv2d_5 (Conv2D) (None, 7, 7, 64) 8256
_________________________________________________________________
flatten_2 (Flatten) (None, 3136) 0
_________________________________________________________________
dense_10 (Dense) (None, 64) 200768
_________________________________________________________________
dense_11 (Dense) (None, 3136) 203840
_________________________________________________________________
reshape_2 (Reshape) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_transpose_4 (Conv2DTr (None, 14, 14, 32) 8224
_________________________________________________________________
conv2d_transpose_5 (Conv2DTr (None, 28, 28, 1) 129
=================================================================
Total params: 421,377
Trainable params: 421,377
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0574
Epoch 2/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0194
Epoch 3/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0123
Epoch 4/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0103
Epoch 5/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0094
Epoch 6/10
235/235 [==============================] - 2s 8ms/step - loss: 0.0089
Epoch 7/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0085
Epoch 8/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0081
Epoch 9/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0077
Epoch 10/10
235/235 [==============================] - 2s 9ms/step - loss: 0.0075
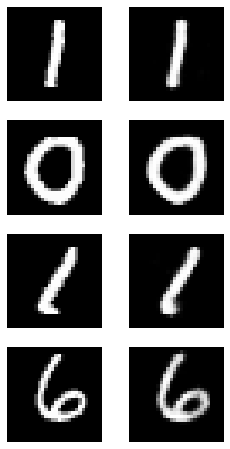
313/313 [==============================] - 1s 3ms/step - loss: 0.0072
0.007230293471366167
relu와 다르게 이전의 각진 모습은 거의 찾아볼 수 없고,loss역시 보다 낮게 측정된 것을 확인할 수 있습니다.
III. 연습 파일
VI. Reference
김환희. (2020). 시작하세요! 텐서플로 2.0 프로그래밍: 기초 이론부터 실전 예제까지 한번에 끝내는 머신러닝, 딥러닝 핵심 가이드. 서울: 위키북스.
