삼성카드 대회 Track-2 - matplotlib 막대 그래프
Page content
대회 소개

- 삼성카드 데이터분석 공모전이 시행되고 있다.
- 대회에 처음 참여하는
아시아경제-수강생들을 위해 일종의 가이드라인으로 제안하고자 한다.
- 대회에 처음 참여하는
- 본 포스트에서는 기본적인 내용만 전달하고자 함을 밝힌다.
- Track2 과정은 마케팅 전략 제안이 중요하다!
환경 세팅
- 먼저, 데이터가 모두 한글로 구성이 되어 있기 때문에 한글파일 설정부터 진행한다.
- 한글파일 설정이 완료되면 구글 드라이브와 연동한다.
- 데이터 시각화를 진행한다.
%config InlineBackend.figure_format = 'retina'
!sudo apt-get -qq -y install fonts-nanum
fonts-nanum is already the newest version (20170925-1).
The following package was automatically installed and is no longer required:
libnvidia-common-440
Use 'apt autoremove' to remove it.
0 upgraded, 0 newly installed, 0 to remove and 39 not upgraded.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import matplotlib.font_manager as fm
/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
plt.rcParams["figure.figsize"] = (20, 10)
mpl.font_manager._rebuild()
mpl.pyplot.rc('font', family='NanumGothic')
fm._rebuild()
- 여기까지 실행하였으면 구글 코랩에서
런타임-런타임 다시 시작을 클릭한다.
구글 드라이브 연동
- 이제 구글 드라이브를 연동한다.
# Mount Google Drive
from google.colab import drive # import drive from google colab
ROOT = "/content/drive" # default location for the drive
print(ROOT) # print content of ROOT (Optional)
drive.mount(ROOT) # we mount the google drive at /content/drive
/content/drive
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
# import join used to join ROOT path and MY_GOOGLE_DRIVE_PATH
from os.path import join
# path to your project on Google Drive
MY_GOOGLE_DRIVE_PATH = 'My Drive/Colab Notebooks/samsung/datasets'
PROJECT_PATH = join(ROOT, MY_GOOGLE_DRIVE_PATH)
print(PROJECT_PATH)
/content/drive/My Drive/Colab Notebooks/samsung/datasets
%cd "{PROJECT_PATH}"
/content/drive/My Drive/Colab Notebooks/samsung/datasets
%ls
'[기타] SCDC_공모전 테이블 설명.xlsx' '[Track1_데이터4] variable_dtype.xlsx'
'[Track1_데이터1] mrc_info.csv' '[Track2_데이터1] trend_w_demo.csv'
'[Track1_데이터2] samp_train.csv' '[Track2_데이터2] 업종_예시.xlsx'
'[Track1_데이터3] samp_cst_feat.csv'
데이터 불러오기
- 패키지를 불러오기 위해
pandas패키지를 활용하여[Track2_데이터1]데이터를 불러온다. - 파일을 불러 올 때,
encoding="EUC-KR"를 설정해서 가져온다.
import pandas as pd
trend_w_demo = pd.read_csv('[Track2_데이터1] trend_w_demo.csv', encoding="EUC-KR")
trend_w_demo.head()
| YM | Category | 성별구분 | 연령대 | 기혼스코어 | 유아자녀스코어 | 초등학생자녀스코어 | 중고생자녀스코어 | 대학생자녀스코어 | 전업주부스코어 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 202005 | 할인점 | 0 | F | high | low | high | mid | low | low |
| 1 | 202005 | 취미 | 0 | B | high | low | mid | mid | low | low |
| 2 | 202005 | 오픈마켓/소셜 | 1 | D | mid | mid | mid | mid | low | mid |
| 3 | 202005 | 뷰티 | 0 | D | mid | mid | mid | mid | low | low |
| 4 | 202005 | 오픈마켓/소셜 | 0 | G | high | low | mid | mid | mid | low |
trend_w_demo['기혼스코어'].value_counts()
high 314088
mid 107368
low 30582
Name: 기혼스코어, dtype: int64
- 위 데이터는 전형적으로 범주형으로 구성이 되어 있다.
- 위 변수에서 고려할 것이 있다.
Category,성별구분,연령대는 명목형 변수인데 반해기혼스코어:전업주부스코어의 경우는 확률이다.
- 각 스코어의 확률에 대한 정의는 다음과 같다.
- 기혼스코어 : 카드 이용 고객이 기혼일 확률
- 유아자녀스코어 : 카드 이용 고객이에게 유아자녀가 있을 확률
- 초등학생자녀스코어 : 카드 이용 고객이에게 초등학생 자녀가 있을 확률
- 중고생자녀스코어 : 카드 이용 고객이에게 중고생 자녀가 있을 확률
- 대학생자녀스코어 : 카드 이용 고객이에게 대학생 자녀가 있을 확률
- 전업주부스코어 : 카드 이용 고객이 전업주부일 확률
- 위 스코어의 데이터는 단순히
명목형이라고 보기는 어렵다. 즉, 순위(서열)형 척도/등간척도로 봐야 할 것이다.
측정척도의 유형과 내용
- 명목척도: 범주형 데이터로 측정된 측정대상을 단순히 범주로 분류하기 위한 목적으로 숫자를 부여한 척도(수학적 가감승제 계산 안 됨)
- 예시 - 성별, 종교, 직업, 혈액형
- 순위(서열)척도: 범주형 데이터로 명목척도의 기능뿐 아니라 각 범주 간의 대소관계, 순위(서열성)에 관하여 숫자를 부여한 척도(수학적 가감승제 계산 안 됨)
- 예시 - 학력, 건강상태 등
- 등간척도: 연속형 데이터로 절대적 영점(
absoulute zero)이 없으며 대상이 갖는 양적인 정도의 차이에 따라 등간격으로 숫자를 부여한 척도(수학적 가감승제 계산 안 됨)- 예시 - 온도, 만족도(리커트척도), 충성도(리커트척도), 물가지수, 생산지수 등
- 비율척도: 연속형 데이터로 절대적 영점이 존재하며, 비율계산이 가능한 숫자를 부여한 척도(수학적 가감승제 계산 가능)
- 매출액, 무게, 가격, 소득, 길이, 부피 등)
(1) 척도와 분석 간의 관계
- 척도와 분석 간의 관계에 관한 표는 아래와 같다 (신건권, 2018).
| 독립변수 | 종속변수 | 분석방법 |
|---|---|---|
| 범주형 변수(명목, 서열) | 범주형 변수(명목, 서열) | 교차분석, 카이제곱 |
| 범주형 변수(명목, 서열) | 연속형 변수(등간, 비율) | t-검증, 분산분석, 다변량분산분석 |
| 연속형 변수(등간, 비율) | 범주형 변수(명목, 서열) | 판별분석, 군집분석, 로지스틱회귀분석 |
| 연속형 변수(등간, 비율) | 연속형 변수(등간, 비율) | 상관분석, 회귀분석, 경로분석/구조방정식모델링분석 |
- 즉, 위 표를 기준으로 삼성카드를 매우 단순하게 본다면
교차분석외에는 쓸만한 분석방법이 떠오르지 않는다. - 그러나, 연도,
Category,성별구분,연령대를 제외하고는 나머지 변수들을 서열 또는 등간으로 본다면 조금 더 다양한 분석 방법이 생길 수 있다.
(2) 시각화 방법
- 순위 및 서열척도를 다루는 데이터에 대한 시각화는 주로 다음과 같다.
- Bar Chart
- Pie Chart / Waffle Chart
- Tables
- Mosaic Plots
- Bump Chart
(3) 모수 VS 비모수 통계
- 통계 분석 방법은 매우 중요하다. 일종의 가이드라인이기 때문이다.
- 모수 통계는 기본적으로 평균들의 차이를 파악해야 하기 때문에 연속형 자료형이 필요하다. 또한, 이러한 자료는 대개 정규분포라는 형태로 잘 포장되어야 하지만, 실상은 그렇지 않다.
- 이러한 경우 비모수적 검정을 실시한다.
- 비모수적 검정의 기본 조건은 모수 통계를 할 수 없는 상황이 생기면, 보다 완화된 조건으로 해석하는 것이 옳은 방법이다. (가정을 무시하는 것은 아니다!)
- 비모수 검정에는 크게 윌콕슨 순위합 검정, 윌콕슨 부호순위 검정, 프리드먼 검정, 그리고 크러스컬-월리스 검정 등이 사용된다.
- 정규성 검정에 따른 모수와 비모수 검정 방법은 다음과 같다.
- T검정
- 모수적 방법: 독립표본 T검정, 대응표본 T검정
- 비모수적 방법: 윌콕슨(Wilcoxon) 검정, 맨-휘트니(Mann-Whitney) 검정
- 분산분석
- 모수적 방법: 일원 배치 분산분석
- 비모수적 방법: 크루스칼-윌리스(Kruskal-Wallis)검정
- 관계분석
- 모수적 방법: 피어슨의 상관분석
- 비모수적 방법: 스피어만의 로 상관분석
- 삼성카드의 데이터는 일반적인 모수적 방법으로는 통계검정을 하기에는 어려움이 있다. 즉, 비모수 통계에 대한 기본적인 숙지가 필요하며, 파이썬에서 비모수 통계 소스코드 예제는 추후에 다시 정리한다.
범주형 데이터 시각화를 통한 EDA 보고서
- 범주형 데이터 시각화를 진행한다.
matplotlib모듈을 활용한다.
(1) Label이 있는 그룹 막대 그래프 (예제)
- 막대그래프를 그린, 라벨링까지 적용해본다.
- 먼저 공식 튜토리얼에 있는 것을 확인해본다.
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
labels = ['G1', 'G2', 'G3', 'G4', 'G5']
men_means = [20, 34, 30, 35, 27]
women_means = [25, 32, 34, 20, 25]
x = np.arange(len(labels)) # x축 라벨의 위치를 말한다.
y_labels = [0, 5, 10, 15, 20, 25, 30, 35] # y축 라벨의 위치를 말한다.
width = 0.35 # 막대의 너비를 말한다.
fig, ax = plt.subplots() # 객체를 설정하는 것이다.
rects1 = ax.bar(x - width/2, men_means, width, label = "Men")
rects2 = ax.bar(x + width/2, women_means, width, label = "Women")
- 먼저, rects1 / rects2를 확인해본다. 독립된 형태의 막대 그래프를 의미한다.
fig, ax는 선언함으로써, 계층적으로 시각화 레이어를 올릴 수 있음을 선언하는 것이다.- 이 때,
x-width/2/x+width/2는 여러개의 막대가 있을 때 위치를 잡아준다.- 만약 3개라면,
x-width/2,x,x+width/2와 같은 형태가 될 것이다.
- 만약 3개라면,
fig, ax = plt.subplots() # 객체를 설정하는 것이다.
rects2 = ax.bar(x - width/2, women_means, width, label = "Women")
rects1 = ax.bar(x + width/2, men_means, width, label = "Men")
- 이제 옵션을 추가한다.
- x, y 축 라벨을 붙여보도록 한다.
fig, ax = plt.subplots() # 객체를 설정하는 것이다.
rects2 = ax.bar(x - width/2, women_means, width, label = "Women")
rects1 = ax.bar(x + width/2, men_means, width, label = "Men")
ax.set_yticklabels(y_labels, fontsize = 18)
ax.set_ylabel('Scores', fontsize = 18)
ax.set_title('Scores by group and gender', size = 24)
ax.set_xticks(x)
ax.set_xticklabels(labels, fontsize = 18)
ax.legend()
<matplotlib.legend.Legend at 0x7f9733f4bb70>
- 이제 마지막으로 각 막대 그래프에 위해 숫자에 해당하는 label를 생성한다.
- 이 때에는
for-loop를 써야하며 가급적 사용자 정의함수로 정의한다.
def autolabel(rects):
"""Attach a text label above each bar in *rects*, displaying its height."""
for rect in rects:
height = rect.get_height()
ax.annotate('{}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize = 18)
fig, ax = plt.subplots() # 객체를 설정하는 것이다.
# 막대 그래프 그리기
rects2 = ax.bar(x - width/2, women_means, width, label = "Women")
rects1 = ax.bar(x + width/2, men_means, width, label = "Men")
# 제목, 축 설정 하기
ax.set_yticklabels(y_labels, fontsize = 18)
ax.set_ylabel('Scores', fontsize = 18)
ax.set_title('Scores by group and gender', size = 24)
ax.set_xticks(x)
ax.set_xticklabels(labels, fontsize = 18)
ax.legend()
# 라벨링 진행하기
autolabel(rects1)
autolabel(rects2)
fig.tight_layout()
plt.show()
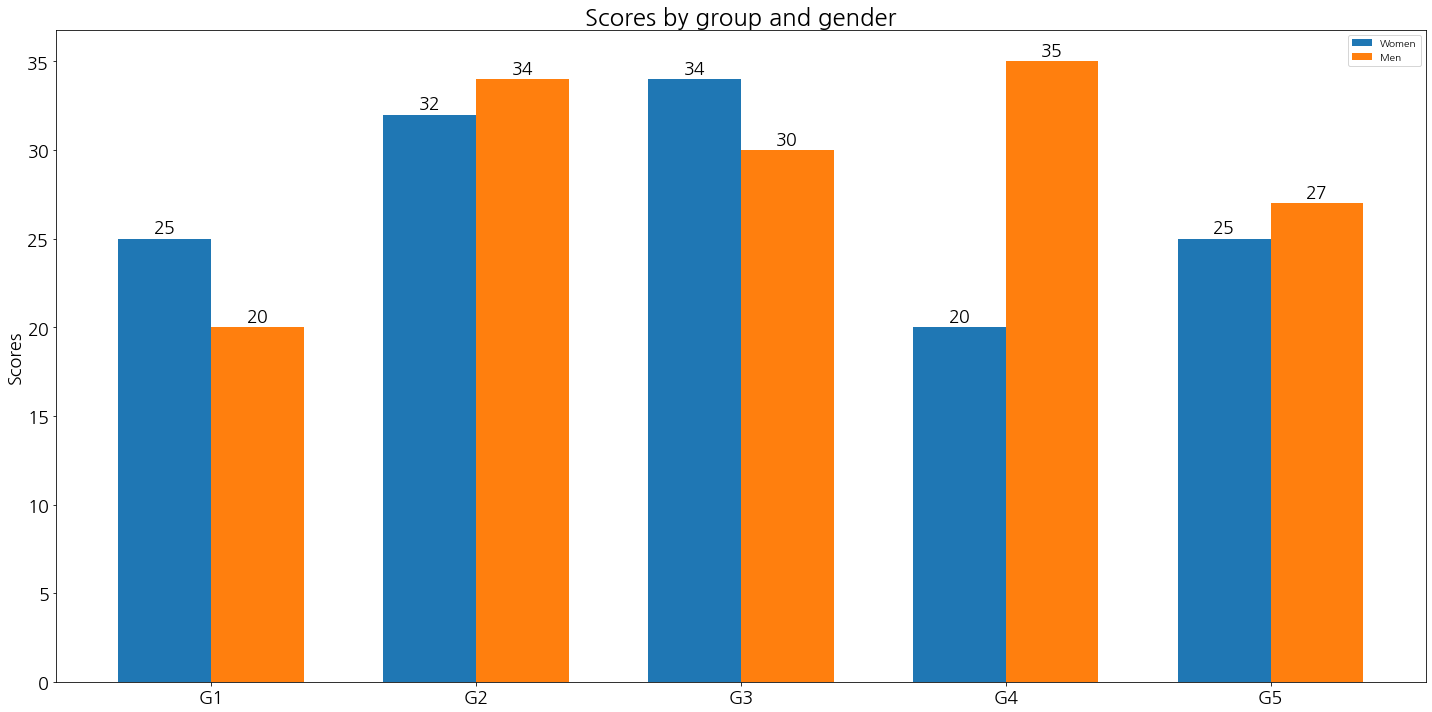
(2) 삼성카드 데이터 적용 - 막대 그래프
- 이제 삼성카드에 적용해보자.
- 이 때 중요한 것은 판다스를 활용하여 피벗테이블을 만들어야 한다.
trend_w_demo.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 452038 entries, 0 to 452037
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 YM 452038 non-null int64
1 Category 452038 non-null object
2 성별구분 452038 non-null int64
3 연령대 452038 non-null object
4 기혼스코어 452038 non-null object
5 유아자녀스코어 452038 non-null object
6 초등학생자녀스코어 452038 non-null object
7 중고생자녀스코어 452038 non-null object
8 대학생자녀스코어 452038 non-null object
9 전업주부스코어 452038 non-null object
dtypes: int64(2), object(8)
memory usage: 34.5+ MB
pivot_df = trend_w_demo.groupby(['YM', 'Category']).size().reset_index(name='Counts')
pivot_df.head()
| YM | Category | Counts | |
|---|---|---|---|
| 0 | 201904 | 디저트 | 22918 |
| 1 | 201904 | 면세점 | 947 |
| 2 | 201904 | 뷰티 | 5734 |
| 3 | 201904 | 오픈마켓/소셜 | 18766 |
| 4 | 201904 | 전문몰 | 30911 |
- 위 그래프를 막대 그래프를 작성하자.
matplotlib에서 필요한 것은list이다.
# category 라벨 추출
categories = pivot_df['Category'].unique().tolist()
# 연도별 데이터 추출 - 201904
df_201904 = pivot_df.loc[pivot_df['YM']== 201904]
counts = df_201904['Counts'].tolist()
counts_201905
[23820, 19343, 31655, 25216]
# category 라벨 추출
categories = pivot_df['Category'].unique().tolist()
# 연도별 데이터 추출 - 201904
df_201904 = pivot_df.loc[pivot_df['YM']== 201904]
counts = df_201904['Counts'].tolist()
# 연도별 데이터 추출 - 201905
df_201905 = pivot_df.loc[pivot_df['YM']== 201905]
counts_201905 = df_201905['Counts'].tolist()
# 연도별 데이터 추출 - 202004
df_202004 = pivot_df.loc[pivot_df['YM']== 202004]
counts_202004 = df_202004['Counts'].tolist()
# 연도별 데이터 추출 - 202005
df_202005 = pivot_df.loc[pivot_df['YM']== 202005]
counts_202005 = df_202005['Counts'].tolist()
cat_lab = np.arange(len(categories)) # x축 라벨의 위치를 말한다.
print(categories)
print(counts)
print(counts_201905)
print(counts_202004)
print(counts_202005)
['디저트', '면세점', '뷰티', '오픈마켓/소셜', '전문몰', '종합몰', '취미', '할인점', '항공/여행사', '호텔/숙박']
[22918, 947, 5734, 18766, 30911, 4189, 5469, 26721, 2132, 2332]
[23820, 926, 6130, 19343, 31655, 4175, 5507, 25216, 2165, 2514]
[20259, 56, 3978, 20909, 31139, 4073, 3341, 15756, 589, 1274]
[22746, 139, 4611, 21724, 32357, 3682, 4132, 16943, 875, 1885]
- 이제 위 그래프를 작성한다.
- 코드가 반복이 되는 것 같다. 이런 경우에는 for-loop를 활용하는 것도 도움이 될 수 있다.
width = 0.2 # 막대의 너비를 말한다.
fig, ax = plt.subplots()
rects_1 = ax.bar(cat_lab - width, counts, width, label = "201904")
rects_2 = ax.bar(cat_lab - width/2. , counts_201905, width, label = "201905")
rects_3 = ax.bar(cat_lab + width/2, counts_202004, width, label = "202004")
rects_4 = ax.bar(cat_lab + width, counts_202005, width, label = "202005")
# 제목, 축 설정 하기
ax.set_ylabel('Counts', fontsize = 18)
ax.set_title('연도별 거래건수', size = 24)
ax.set_xticks(cat_lab)
ax.set_xticklabels(categories, fontsize = 18)
ax.legend()
fig.tight_layout()
plt.show()
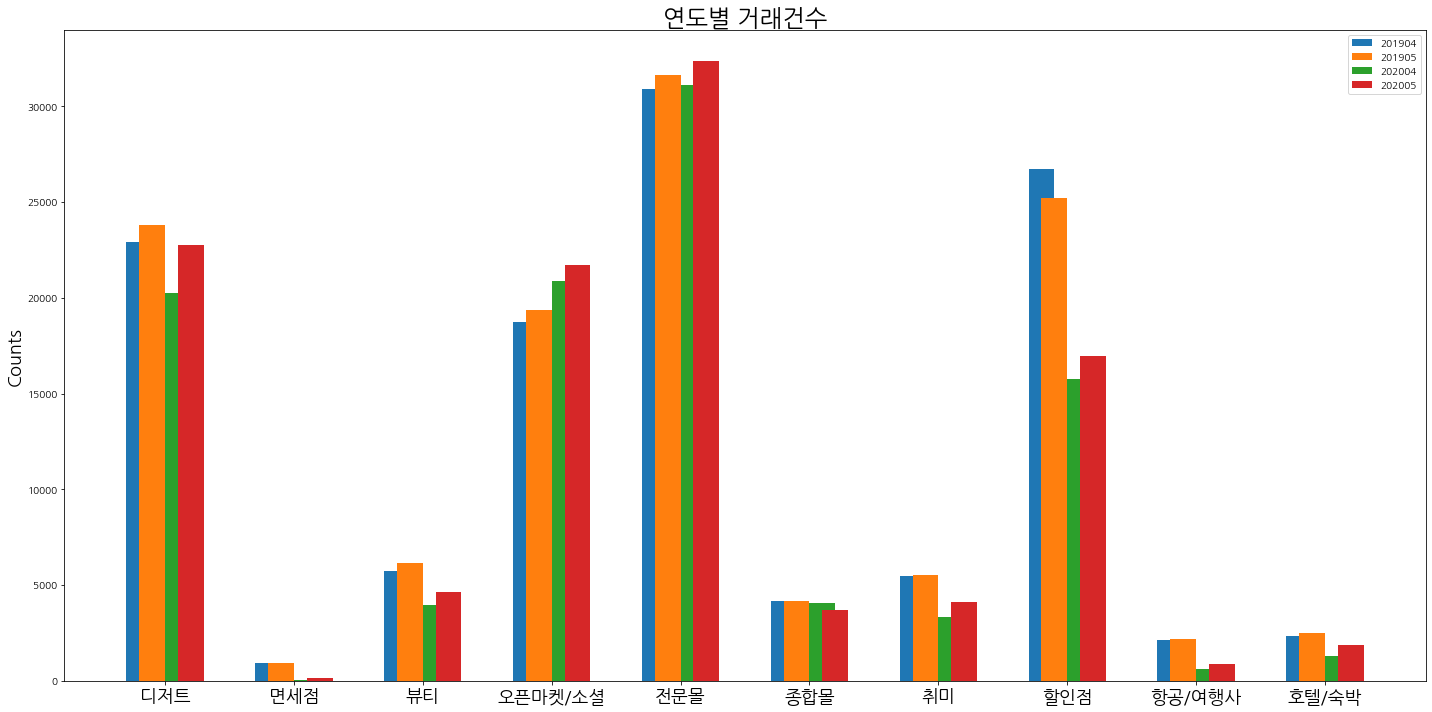
- 우선
EDA용으로는 적합하지만,PPT용으로는 적합하지 않다. - 우선, 거래건수 간 격차가 크기 때문에, 그룹으로 구분 해서 나누도록 해본다.
- 물론 전체적인 추이에 대한 해석은 가능할 것이다.
(3) 재 그룹화 및 그래프 재작성
- 다시 데이터로 돌아와서 그룹화를 한다.
- 거래건수상 vs 거래건수하 데이터로 재 변환한다.
top_categories = ['디저트', '오픈마켓/소셜', '전문몰', '할인점']
countTop = pivot_df.loc[pivot_df['Category'].isin(top_categories)]
- 이번에는 그래프를 다시 그려본다.
# category 라벨 추출
categories = countTop['Category'].unique().tolist()
# 연도별 데이터 추출 - 201904
df_201904 = countTop.loc[countTop['YM']== 201904]
counts = df_201904['Counts'].tolist()
# 연도별 데이터 추출 - 201905
df_201905 = countTop.loc[countTop['YM']== 201905]
counts_201905 = df_201905['Counts'].tolist()
# 연도별 데이터 추출 - 202004
df_202004 = countTop.loc[countTop['YM']== 202004]
counts_202004 = df_202004['Counts'].tolist()
# 연도별 데이터 추출 - 202005
df_202005 = countTop.loc[countTop['YM']== 202005]
counts_202005 = df_202005['Counts'].tolist()
cat_lab = np.arange(len(categories)) # x축 라벨의 위치를 말한다.
width = 0.25 # 막대의 너비를 말한다.
fig, ax = plt.subplots()
rects_1 = ax.bar(cat_lab - width, counts, width/1.5, label = "201904")
rects_2 = ax.bar(cat_lab - width/2.5, counts_201905, width/1.5, label = "201905")
rects_3 = ax.bar(cat_lab + width/2.5, counts_202004, width/1.5, label = "202004")
rects_4 = ax.bar(cat_lab + width, counts_202005, width/1.5, label = "202005")
# 제목, 축 설정 하기
ax.set_ylabel('Counts', fontsize = 18)
ax.set_title('연도별 거래건수', size = 24)
ax.set_xticks(cat_lab)
ax.set_xticklabels(categories, fontsize = 18)
ax.legend()
fig.tight_layout()
plt.show()
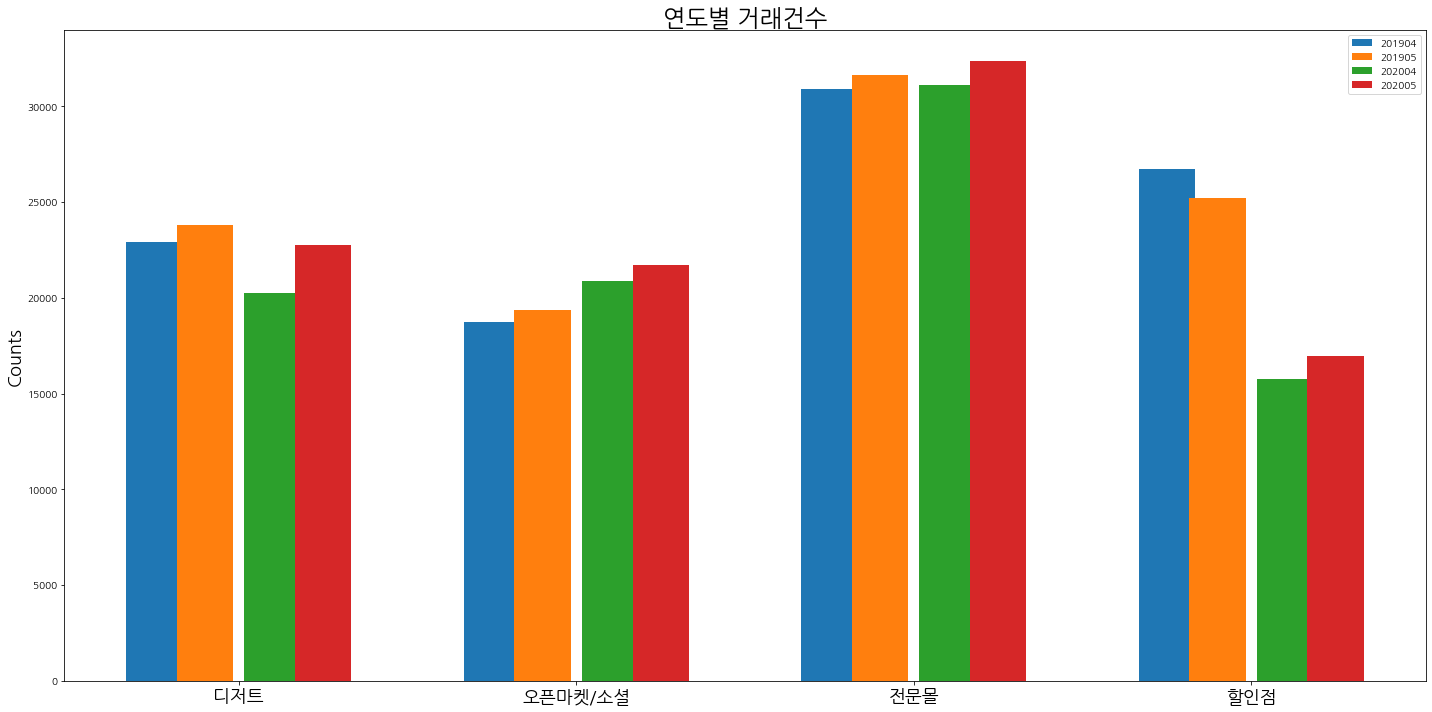
-
위 그래프를 보니, 조금 더 명확하게 보인다.
-
우선,
오픈마켓/전문몰은 계속 상승중이다. -
디저트의 경우에는 일시적으로202004에 거래건수가 떨어졌으나 다시 회복한 것을 볼 수 있다. -
눈여겨 봐야 하는 것은
할인점의 큰폭 하락이다.- 코로나에 의해 가장 큰 타격을 받은 것은
할인점의 거래건수 임을 확인할 수 있었다. - 실제로 오프라인 유통업체의 매출이 크게 떨어진 것을 확인할 수 있는 기사들이 등장하는 것을 볼 때, 위 하락폭은 기정사실화 된 것처럼 보인다. 기사: 코로나 공포감에 백화점·대형마트 매출 4개월째 감소
- 코로나에 의해 가장 큰 타격을 받은 것은
-
이번에는 거래건수가 상대적으로 작은 업종을 확인해본다.
-
이 때,
~를pivot_df앞에 추가하기만 하면 된다.
top_categories = ['디저트', '오픈마켓/소셜', '전문몰', '할인점']
others = pivot_df.loc[~pivot_df['Category'].isin(top_categories)]
# category 라벨 추출
categories = others['Category'].unique().tolist()
# 연도별 데이터 추출 - 201904
df_201904 = others.loc[others['YM']== 201904]
counts = df_201904['Counts'].tolist()
# 연도별 데이터 추출 - 201905
df_201905 = others.loc[others['YM']== 201905]
counts_201905 = df_201905['Counts'].tolist()
# 연도별 데이터 추출 - 202004
df_202004 = others.loc[others['YM']== 202004]
counts_202004 = df_202004['Counts'].tolist()
# 연도별 데이터 추출 - 202005
df_202005 = others.loc[others['YM']== 202005]
counts_202005 = df_202005['Counts'].tolist()
cat_lab = np.arange(len(categories)) # x축 라벨의 위치를 말한다.
width = 0.25 # 막대의 너비를 말한다.
fig, ax = plt.subplots()
rects_1 = ax.bar(cat_lab - width, counts, width/1.5, label = "201904")
rects_2 = ax.bar(cat_lab - width/2.5, counts_201905, width/1.5, label = "201905")
rects_3 = ax.bar(cat_lab + width/2.5, counts_202004, width/1.5, label = "202004")
rects_4 = ax.bar(cat_lab + width, counts_202005, width/1.5, label = "202005")
# 제목, 축 설정 하기
ax.set_ylabel('Counts', fontsize = 18)
ax.set_title('연도별 거래건수', size = 24)
ax.set_xticks(cat_lab)
ax.set_xticklabels(categories, fontsize = 18)
ax.legend()
fig.tight_layout()
plt.show()
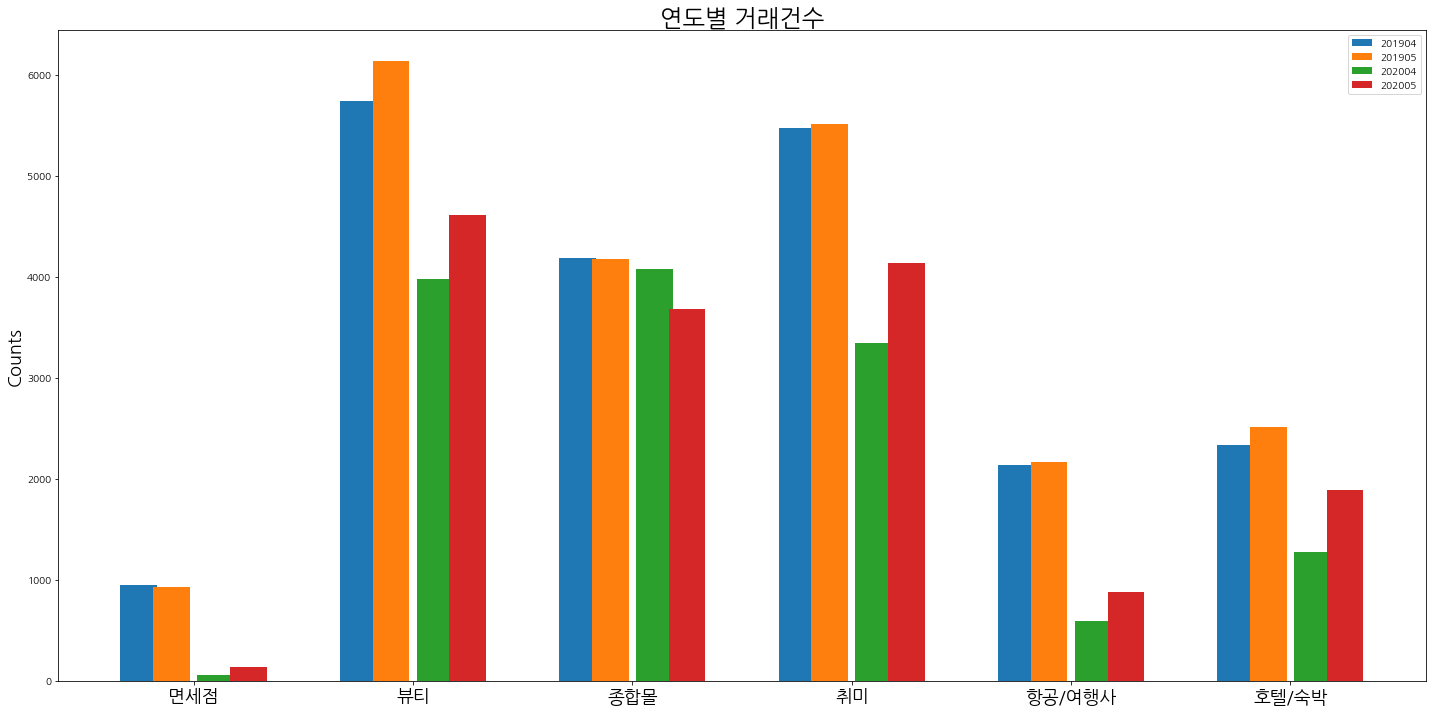
- 이 업종의 특이점은 전년대비 모두 하락했다.
- 업종의 공통점은 여가생활과 관련이 있고, 필수생활과는 큰 관련이 없다.
(4) 결론
seaborn이 아닌matplotlib패키지를 활용해서 구현한다.matploblib에서 그룹 막대 그래프 예제를 확인했다.- 그래프 예제 확인 후 삼성카드 데이터로 재 확인하였다.
- 삼성카드 EDA 진행결과 코로나에도 불구하고 지속적으로 거래건수가 늘어나는 업종은
오픈마켓/소셜과전문몰로 확인 되었다. - 그 외 나머지 업종에서는 모두 전년대비 하락세를 이어가고 있고, 그 중에서도 특히 종합몰의 매출 거래 건수 하락이 지속되는 것으로 확인 되고 있다.
- 이 때 마케팅의 방향이 중요하다.
- 줄어든 매출을 끌어올리는 전략 vs. 계속 상승되는 업종에 관한 매출을 끌어올리는 전략
- 향후 장기적으로
언텍트 비즈니스가 가속화되는 것을 고려할 때 소셜 마켓에 집중하고자 한다.- 그리고, 2020년 자료만 사용한다.
Reference
- 신건권(2018). SmartPLS 3.0: 구조방정식모델링, 서울: 청람.
- What are Nonparametric Tests?
- matplotlib.axes.Axes.bar
- matplotlib.pyplot.bar
- matplotlib.axes.Axes.annotate
- matplotlib.pyplot.annotate
