주요 핵심 머신러닝 리뷰
Page content
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

개요
- 수강생들의 머신러닝을 활용한 웹 개발 프로젝트 전 복습 차원에서 준비함.
- 주 내용은 주요 참고자료를 기반으로 작성하였으며, 참고자료에 없는 코드는 직접 작성하였음을 밝힘.
가장 인기 있는 모델
- XGBoost와 LightGBM
- 그 외, 선형회귀, 로지스틱 회귀, 결정 트리, 앙상블 학습, 랜덤 포레스트, XGBoost, LightGBM
선형 회귀
- 선형 회귀식을 활용한 모델
- 회귀 계수와 절편을 찾는 것이 중요
- 기초통계에서 다루는 선형 회귀와 기본적인 개념에서는 동일하나, 기초통계에서와 예측 모델에서의 쓰임새는 다르다는 것을 기억한다.
데이터 생성
- 단순 선형 회귀식 $y = 3x + 4$에 근사한 데이터 50개 생성
import numpy as np
import pandas as pd
np.random.seed(0) # 시드값 고정
intercept = 4 # 절편
slope = 3 # 기울기
# 변동성 주기 위해 노이즈 생성
noise = np.random.randn(50, 1)
# 50개의 x값 생성
x = 5 * np.random.rand(50, 1) # 0과 5사이의 실숫값 50개 생성
y = slope * x + intercept + noise
# 데이터 프레임 생성
data = pd.DataFrame({'X': x[:, 0], 'Y': y[:, 0]})
print(data.head())
X Y
0 0.794848 8.148596
1 0.551876 6.055784
2 3.281648 14.823682
3 0.690915 8.313637
4 0.982912 8.816293
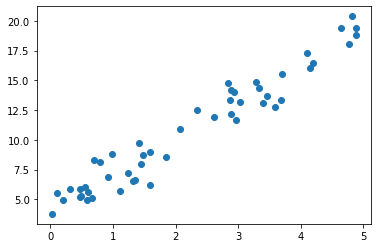
- 위 데이터를 시각화로 구현한다.
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.scatter(data['X'], data['Y'])
plt.show()
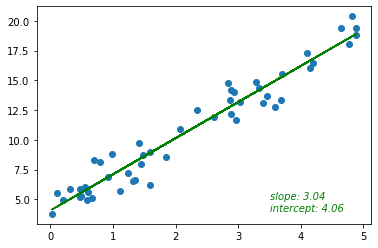
선형회귀 모형 훈련
- 모델 훈련 후, 적절한 회귀계수와 y절편 값을 찾아준다.
- 회귀계수 3과 y절편 4에 근사한 답이 나온다.
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression() # 선형 회귀 모델
lr_model.fit(x, y) # 모델 훈련
print('y절편 :', lr_model.intercept_)
print('회귀계수:', lr_model.coef_)
y절편 : [4.05757639]
회귀계수: [[3.03754061]]
회귀선 확인
# 예측값
y_pred = lr_model.predict(x)
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.plot(x, y_pred, color='green')
# slope, intercept
label = 'slope: {}\nintercept: {}'.format(round(lr_model.coef_[0][0], 2), round(lr_model.intercept_[0], 2))
ax.text(3.5, 4, label, style ='italic',
fontsize = 10, color ="green")
plt.show()
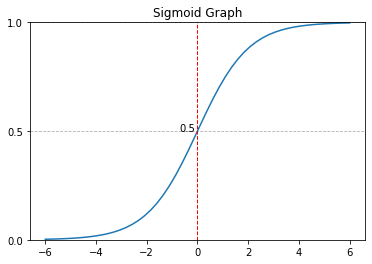
로지스틱 회귀모델
- 선형 회귀 방식을 응용해 분류에 적용한 모델
- 시그모이드 함수를 활용해 타깃값에 포함될 확률을 예측함.
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(arr, scale=1):
arr = np.asarray(arr)
result = 1/(1 + np.exp(-arr*scale))
return result
x = np.linspace(-6, 6)
y = sigmoid(x)
fig, ax = plt.subplots()
ax.plot(x, y)
ax.grid(which='major', axis='y', linestyle='--')
ax.axvline(x=0, color='r', linestyle='--', linewidth=1)
ax.set_ylim(0,1)
ax.set_yticks([0, 1, 0.5])
ax.text(0-0.1, 0.5, '0.5', ha='right')
ax.set_title('Sigmoid Graph')
plt.show()
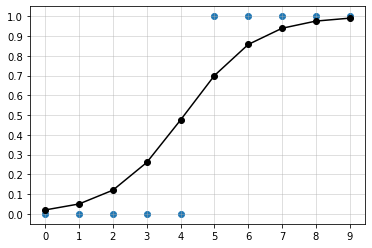
- 이진 분류 문제에선 확률값이 0.5보다 작으면 0(음성), 0.5 이상이면 1(양성)이라고 예측한다.
- 예제를 통해 확인한다.
# 라이브러리 불러오기
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
# 데이터 가져오기
x = np.arange(10).reshape(-1, 1)
y = np.array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
# 모델 생성 및 학습
model = LogisticRegression(solver='liblinear', C=10.0, random_state=0)
model.fit(x, y)
LogisticRegression(C=10.0, random_state=0, solver='liblinear')
- 모형 파라미터 설명
- C: 규제의 강도를 조절함. Default는 1이며, 작은 값일수록 규제의 강도가 커짐.
- solver: 알고리즘을 선택함. 기본값으로 liblinear가 있으며, 그 외에도 ’newton-cg’, ’lbfgs’, ‘sag’, and ‘saga’ 등이 있음.
# 모형 평가
p_pred = model.predict_proba(x)
print("p_pred", p_pred, sep = "\n")
p_pred
[[0.97979027 0.02020973]
[0.94958202 0.05041798]
[0.87976149 0.12023851]
[0.73975066 0.26024934]
[0.52477284 0.47522716]
[0.30020373 0.69979627]
[0.1428487 0.8571513 ]
[0.06080627 0.93919373]
[0.02453462 0.97546538]
[0.00967652 0.99032348]]
y_pred = model.predict(x)
print('y_pred', y_pred)
y_pred [0 0 0 0 0 1 1 1 1 1]
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.plot(x, p_pred[:, 1], color = 'black', marker='o', markersize=6)
ax.plot()
ax.set_xticks(x)
ax.set_yticks(np.arange(0, 1.1, 0.1))
ax.grid(which='major', alpha=0.5)
plt.show()
conf_m = confusion_matrix(y, y_pred)
print(conf_m)
[[5 0]
[0 5]]
cm = confusion_matrix(y, y_pred)
fig, ax = plt.subplots(figsize=(8, 8))
ax.imshow(cm, cmap = 'Pastel2')
ax.grid(False)
ax.xaxis.set(ticks=(0, 1), ticklabels=('Predicted 0', 'Predicted 1'))
ax.yaxis.set(ticks=(0, 1), ticklabels=('Actual 0', 'Actual 1'))
ax.set_ylim(1.5, -0.5)
for i in range(2):
for j in range(2):
ax.text(j, i, cm[i, j], ha='center', va='center', color='black', fontsize=20)
plt.show()

결정 트리
- 분류와 회귀 문제에 모두 사용 가능한 모델
주요 개념
- 작동 원리
- 데이터를 가장 잘 구분하는 조건을 정함.
- 조건을 기준으로 데이터를 두 범주로 나눔
- 나뉜 각 범주의 데이터를 구분하는 조건을 정함
- 각 조건을 기준으로 데이터를 두 범주로 나눔
- 언제까지 계속 분할할지 정한 후, 최종 결정 값을 구함.
- 불순도(Impurity)
- 한 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지 나타냄
- 흰색과 검은색이 50:50으로 섞여 있다. (불순도 최대)
- 흰색과 검은색으로 완전 분리 되었다. (불순도 최소)
- 엔트로피(Entropy)
- 불확실한 정도를 의미함. 0 ~ 1로 정함.
- 흰색과 검은색이 50:50으로 섞여 있다. 엔트로피 1
- 흰색과 검은색으로 완전 분리 되었다. 엔트로피 0
- 정보이득(Information Gain)
- 1에서 엔트로피를 뺀 수치
- 정보 이득을 최대화하는 방향(엔트로피를 최소화 하는 방향)으로 노드를 분할함
- 지니 불순도(Gini Impurity)
- 지니 불순도 값이 클수록 불순도도 높고, 작을수록 불순도도 낮음. 엔트로피와 마찬가지로 지니 불순도가 낮아지는 방향으로 노드 분할함.
DecisionTreeClassifier 파라미터
- criterion : 분할 시, 사용할 불순도 측정 지표
- gini or entropy
- 기본값 = gini
- max_depth : 트리의 최대 깊이
- 분할의 깊이를 정함, 만약 정하지 않으면 불순도가 0이 될 때까지 트리 깊이가 계속 깊어짐. 깊이를 정하지 않으면 과대 적합의 문제가 될 수 있음.
- 기본값 = None
- min_samples_split : 노드 분할 최소 데이터 갯수
- 노드 내 데이터 개수가 지정된 값 보다 작으면 분할하지 않음
- 정수형 : 최소 데이터 개수
- 실수형 : 비율 =
ceil(min_samples_leaf * n_samples)
- min_samples_leaf : 말단 노드가 되기 위한 최소 데이터 개수
- 노드 내 데이터 개수가 지정된 값에 도달하면 말단 노드가 됨.
- 정수형 : 최소 데이터 개수
- 실수형 : 비율 =
ceil(min_samples_leaf * n_samples)
- max_features : 분할에 사용할 피처 개수
- 정수형으로 전달 시 피처 개수
- 실수형으로 전달 시
int(max_features * n_features)개수의 비율 의미 - 만약,
sqrt입력 시,max_features=sqrt(n_features). - 만약,
log2, 입력 시,max_features=log2(n_features). - 만약,
None, 입력 시,max_features=n_features.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import seaborn as sns
# tips 데이터셋
titanic = sns.load_dataset('titanic')
titanic.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 class 891 non-null category
9 who 891 non-null object
10 adult_male 891 non-null bool
11 deck 203 non-null category
12 embark_town 889 non-null object
13 alive 891 non-null object
14 alone 891 non-null bool
dtypes: bool(2), category(2), float64(2), int64(4), object(5)
memory usage: 80.7+ KB
- survived의 비율을 구한다.
- 0 : 사망자
- 1 : 생존자
titanic['survived'].value_counts()
0 549
1 342
Name: survived, dtype: int64
X = titanic[['pclass', 'parch', 'fare']]
y = titanic['survived']
# 훈련데이터, 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, test_size = 0.3, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((623, 3), (268, 3), (623,), (268,))
- 모형을 만든다.
tree_model = DecisionTreeClassifier()
tree_model.fit(X_train, y_train)
acc = tree_model.score(X_test, y_test)
print(f'모형 정확도 : {acc:.3f}') # 정확도 측정
모형 정확도 : 0.675
앙상블 학습
- 다양한 모델이 내린 예측 결과를 결합하는 기법
- 학습 유형 : 보팅, 배깅, 부스팅
- 보팅(Voting: 투표)
- 하드보팅 : 모델 1-5 중, 최빈값으로 결정
- 소프트보팅 : 예측 확률들의 평균을 최종 확률
- 배깅(Bagging) : 개별 모델로 예측한 결과를 결합해 보팅 방식으로 최종 예측값 결정
- 무작위 샘플링한 데이터로 개별 모델 훈련
- 개별 모델로 예측
- 개별 모델의 수만큼 1-2번 작업 반복
- 각 모델이 예측한 값들을 보팅하여 최종 예측값 구함
- 대표적으로 랜덤포레스트가 있음
- 부스팅(Boosting): 가중치 활용해 분류 성능이 약한 모델을 강하게 만드는 기법
- 배깅은 모델끼리 독립적인 관계
- 부스팅은 모델간 유기적인 관계
- 이전 모델이 잘못 예측한 데이터에 가중치를 부여하면서 성능을 향상 시킴.
- 대표적으로 XGBoost와 LightGBM이 있음
- 보팅(Voting: 투표)
랜덤포레스트
- Scikit-Learn
- 분류 모델 : RandomForestClassifier
- 회귀 모델 : RnadomForestRegressor
- 결정트리와 파라미터는 기본적으로 동일하다. 단 하나의 차이가 있다면, 랜덤 포레스트를 구성할 결정 트리 개수 관련 파라미터가 있다.
- n_estimators : 결정 트리 개수 (기본값 = 100)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import seaborn as sns
# tips 데이터셋
titanic = sns.load_dataset('titanic')
X = titanic[['pclass', 'parch', 'fare']]
y = titanic['survived']
# 훈련데이터, 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, test_size = 0.3, random_state=42)
# 모델 훈련
rf_model = RandomForestClassifier(random_state=42) # 랜덤 포레스트 정의
rf_model.fit(X_train, y_train)
acc = rf_model.score(X_test, y_test)
print(f'모형 정확도 : {acc:.3f}') # 정확도 측정
모형 정확도 : 0.675
XGBoost
- 많은 캐글 우승자가 XGBoost를 사용함.
- 주요 모듈은 C와 C++로 작성되었지만, Python에서도 사용할 수 있도록 API 제공
- 그런데, 제공하는 방식이 크게 2가지가 있음.
- Python Wrapper XGboost
- Scikit-Learn Wrapper XGboost
- 공부할 때는 본인에게 맞는 방식을 적용하는 것을 추천함.
- 예) 참조하는 캐글 노트북 방식이 Python Wrapper인지, 아니면 Scikit-Learn 방식인지에 따라 선택.
- 하이퍼파라미터 목록 : https://xgboost.readthedocs.io/en/latest/parameter.html
XGBoost 하이퍼 파라미터
- 약 80개 이상의 파라미터가 존재한다. 따라서, 파라미터를 모두 공부할 수는 없다.
- 파라미터는 크게 3가지로 구분할 수 있다.
- 일반 파라미터 : 스레드의 개수나 silent 모드 등의 선택을 위한 파라미터인데, 기본값을 바꾸는 경우는 많지 않다.
- 예) booster 알고리즘 : 트리기반인 경우 gbtree, dart를 선택하고, 선형 모델인 경우 gblinear를 선택할 수 있다. 일반적으로 gbtree를 사용한다. (기본값 = ‘gbtree’)
- 부스터 파라미터 : 트리 최적화, 부스팅, 규제 등과 같은 파라미터를 말하며, 대부분 주로 여기에 속한다. 몇가지 예를 들면 다음과 같다.
- eta : 학습률(부스팅 스텝을 반복하면서 모델을 업데이트하는 데 사용하는 비율)
- 0~1 사이 값으로 설정 (기본값=0.3)
- max_depth : 개별 트리의 최대 깊이 (기본값=6)
- subsample : 개별 트리 훈련 시 데이터 샘플링 비율. 0 ~ 1 사이 값으로 설정할 수 있고, 기본값 = 1
- colample_bytree : 개별 트리 훈련 시 사용하는 피처 샘플링 비율
- scale_pos_weight : 불균형 데이터 가중치 조정 값, 타깃값이 불균형할 때, 양성(positive)값에 가중치를 줘서 균형을 맞춤. 일반적으로 타깃값 1을 양성 값으로 간주
- num_boost_rounds : 부스팅 반복 횟수. 횟수가 커지면 과대적합 우려가 있고, 작으면 훈련 시간이 짧아짐. 만약 반복 횟수를 늘리면 learning_rate를 줄여야 함.
- eta : 학습률(부스팅 스텝을 반복하면서 모델을 업데이트하는 데 사용하는 비율)
- 학습 태스크 파라미터 : 학습 수행 시 객체 함수 및 평가 지표 설정 파라미터.
- objective : 훈련 목적
- 회귀 문제 :
reg:squarederror - 확률값 이진 분류 :
binary:logistic - 소프트맥스 함수 사용 다중분류 :
multi:softmax - 확률값을 구하는 다중분류 :
multi:softprob
- 회귀 문제 :
- objective : 훈련 목적
- 일반 파라미터 : 스레드의 개수나 silent 모드 등의 선택을 위한 파라미터인데, 기본값을 바꾸는 경우는 많지 않다.
Python Wrapper XGBoost
- 이 때에는 별도의 데이터셋을 생성해야 함.
- XGBoost 사용 시, DMatrix 객체가 필요함.
import xgboost as xgb
from sklearn.model_selection import train_test_split
import seaborn as sns
# tips 데이터셋
titanic = sns.load_dataset('titanic')
X = titanic[['pclass', 'parch', 'fare']]
y = titanic['survived']
# 훈련데이터, 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, test_size = 0.3, random_state=42)
- 여기서부터가 중요하다. 여기부터 Dmatrix로 변환해야 한다.
dtrain = xgb.DMatrix(data = X_train, label = y_train)
dtest = xgb.DMatrix(data = X_test, label = y_test)
params = {'max_depth':3,
'n_estimators':100,
'eta': 0.1,
'objective':'binary:logistic'}
num_rounds = 400
w_list = [(dtrain,'train'),(dtest,'test')]
xgb_ml = xgb.train(params=params, dtrain=dtrain, num_boost_round=num_rounds,\
early_stopping_rounds=100, evals=w_list)
[0] train-error:0.260032 test-error:0.302239
Multiple eval metrics have been passed: 'test-error' will be used for early stopping.
Will train until test-error hasn't improved in 100 rounds.
[1] train-error:0.260032 test-error:0.302239
[2] train-error:0.260032 test-error:0.302239
[3] train-error:0.260032 test-error:0.302239
[4] train-error:0.260032 test-error:0.302239
[5] train-error:0.260032 test-error:0.302239
[6] train-error:0.260032 test-error:0.302239
[7] train-error:0.260032 test-error:0.302239
[8] train-error:0.260032 test-error:0.302239
[9] train-error:0.260032 test-error:0.302239
[10] train-error:0.260032 test-error:0.302239
[11] train-error:0.260032 test-error:0.302239
[12] train-error:0.260032 test-error:0.302239
[13] train-error:0.247191 test-error:0.298507
[14] train-error:0.247191 test-error:0.298507
[15] train-error:0.248796 test-error:0.302239
[16] train-error:0.248796 test-error:0.302239
[17] train-error:0.248796 test-error:0.302239
[18] train-error:0.248796 test-error:0.302239
[19] train-error:0.248796 test-error:0.302239
[20] train-error:0.248796 test-error:0.302239
[21] train-error:0.248796 test-error:0.302239
[22] train-error:0.248796 test-error:0.302239
[23] train-error:0.248796 test-error:0.302239
[24] train-error:0.248796 test-error:0.302239
[25] train-error:0.248796 test-error:0.302239
[26] train-error:0.248796 test-error:0.302239
[27] train-error:0.248796 test-error:0.302239
[28] train-error:0.247191 test-error:0.302239
[29] train-error:0.247191 test-error:0.302239
[30] train-error:0.247191 test-error:0.302239
[31] train-error:0.243981 test-error:0.298507
[32] train-error:0.247191 test-error:0.302239
[33] train-error:0.243981 test-error:0.298507
[34] train-error:0.243981 test-error:0.298507
[35] train-error:0.242376 test-error:0.294776
[36] train-error:0.24077 test-error:0.294776
[37] train-error:0.24077 test-error:0.294776
[38] train-error:0.24077 test-error:0.294776
[39] train-error:0.24077 test-error:0.294776
[40] train-error:0.24077 test-error:0.294776
[41] train-error:0.24077 test-error:0.294776
[42] train-error:0.24077 test-error:0.294776
[43] train-error:0.24077 test-error:0.294776
[44] train-error:0.24077 test-error:0.302239
[45] train-error:0.24077 test-error:0.302239
[46] train-error:0.24077 test-error:0.302239
[47] train-error:0.24077 test-error:0.302239
[48] train-error:0.24077 test-error:0.302239
[49] train-error:0.24077 test-error:0.302239
[50] train-error:0.24077 test-error:0.302239
[51] train-error:0.24077 test-error:0.302239
[52] train-error:0.23435 test-error:0.302239
[53] train-error:0.23435 test-error:0.302239
[54] train-error:0.232745 test-error:0.298507
[55] train-error:0.229535 test-error:0.298507
[56] train-error:0.229535 test-error:0.298507
[57] train-error:0.229535 test-error:0.298507
[58] train-error:0.229535 test-error:0.298507
[59] train-error:0.227929 test-error:0.294776
[60] train-error:0.227929 test-error:0.298507
[61] train-error:0.227929 test-error:0.298507
[62] train-error:0.227929 test-error:0.298507
[63] train-error:0.227929 test-error:0.298507
[64] train-error:0.227929 test-error:0.298507
[65] train-error:0.227929 test-error:0.298507
[66] train-error:0.227929 test-error:0.298507
[67] train-error:0.227929 test-error:0.298507
[68] train-error:0.227929 test-error:0.298507
[69] train-error:0.227929 test-error:0.298507
[70] train-error:0.227929 test-error:0.298507
[71] train-error:0.227929 test-error:0.298507
[72] train-error:0.227929 test-error:0.302239
[73] train-error:0.227929 test-error:0.302239
[74] train-error:0.229535 test-error:0.30597
[75] train-error:0.229535 test-error:0.30597
[76] train-error:0.229535 test-error:0.30597
[77] train-error:0.229535 test-error:0.30597
[78] train-error:0.229535 test-error:0.30597
[79] train-error:0.229535 test-error:0.30597
[80] train-error:0.229535 test-error:0.30597
[81] train-error:0.229535 test-error:0.30597
[82] train-error:0.229535 test-error:0.30597
[83] train-error:0.229535 test-error:0.30597
[84] train-error:0.229535 test-error:0.30597
[85] train-error:0.229535 test-error:0.30597
[86] train-error:0.229535 test-error:0.30597
[87] train-error:0.229535 test-error:0.30597
[88] train-error:0.229535 test-error:0.30597
[89] train-error:0.229535 test-error:0.30597
[90] train-error:0.229535 test-error:0.30597
[91] train-error:0.229535 test-error:0.30597
[92] train-error:0.229535 test-error:0.30597
[93] train-error:0.229535 test-error:0.30597
[94] train-error:0.227929 test-error:0.313433
[95] train-error:0.226324 test-error:0.313433
[96] train-error:0.223114 test-error:0.317164
[97] train-error:0.223114 test-error:0.317164
[98] train-error:0.223114 test-error:0.317164
[99] train-error:0.223114 test-error:0.317164
[100] train-error:0.223114 test-error:0.317164
[101] train-error:0.223114 test-error:0.317164
[102] train-error:0.223114 test-error:0.317164
[103] train-error:0.223114 test-error:0.317164
[104] train-error:0.223114 test-error:0.317164
[105] train-error:0.223114 test-error:0.317164
[106] train-error:0.223114 test-error:0.317164
[107] train-error:0.223114 test-error:0.317164
[108] train-error:0.223114 test-error:0.317164
[109] train-error:0.223114 test-error:0.317164
[110] train-error:0.223114 test-error:0.317164
[111] train-error:0.223114 test-error:0.317164
[112] train-error:0.223114 test-error:0.317164
[113] train-error:0.223114 test-error:0.317164
[114] train-error:0.223114 test-error:0.317164
[115] train-error:0.223114 test-error:0.317164
[116] train-error:0.223114 test-error:0.317164
[117] train-error:0.223114 test-error:0.317164
[118] train-error:0.223114 test-error:0.317164
[119] train-error:0.223114 test-error:0.317164
[120] train-error:0.223114 test-error:0.317164
[121] train-error:0.223114 test-error:0.317164
[122] train-error:0.223114 test-error:0.317164
[123] train-error:0.223114 test-error:0.317164
[124] train-error:0.224719 test-error:0.317164
[125] train-error:0.224719 test-error:0.317164
[126] train-error:0.224719 test-error:0.317164
[127] train-error:0.221509 test-error:0.317164
[128] train-error:0.223114 test-error:0.317164
[129] train-error:0.219904 test-error:0.313433
[130] train-error:0.215088 test-error:0.313433
[131] train-error:0.215088 test-error:0.313433
[132] train-error:0.215088 test-error:0.313433
[133] train-error:0.215088 test-error:0.313433
[134] train-error:0.215088 test-error:0.313433
[135] train-error:0.215088 test-error:0.313433
Stopping. Best iteration:
[35] train-error:0.242376 test-error:0.294776
from sklearn.metrics import accuracy_score
pred_probs = xgb_ml.predict(dtest)
y_pred=[1 if x > 0.5 else 0 for x in pred_probs]
# 예측 라벨과 실제 라벨 사이의 정확도 측정
accuracy_score(y_pred, y_test)
0.6865671641791045
Scikit-Learn Wrapper XGBoost
- XGBClassifier() 클래스를 불러오기만 하면 된다.
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
# model
w_list = [(X_train, y_train), (X_test, y_test)]
model = XGBClassifier(objective = 'binary:logistic',
n_estimators=100,
learning_rate=0.1,
max_depth=3,
num_rounds = 400,
random_state = 32)
model.fit(X_train,
y_train,
eval_set= w_list,
eval_metric='error',
verbose=True)
y_probas = model.predict_proba(X_test)
y_pred=[1 if x > 0.5 else 0 for x in y_probas[:, 1]] # 예측 라벨(0과 1로 예측)
# 예측 라벨과 실제 라벨 사이의 정확도 측정
accuracy_score(y_pred, y_test)
[0] validation_0-error:0.260032 validation_1-error:0.302239
[1] validation_0-error:0.260032 validation_1-error:0.302239
[2] validation_0-error:0.260032 validation_1-error:0.302239
[3] validation_0-error:0.260032 validation_1-error:0.302239
[4] validation_0-error:0.260032 validation_1-error:0.302239
[5] validation_0-error:0.260032 validation_1-error:0.302239
[6] validation_0-error:0.260032 validation_1-error:0.302239
[7] validation_0-error:0.260032 validation_1-error:0.302239
[8] validation_0-error:0.260032 validation_1-error:0.302239
[9] validation_0-error:0.260032 validation_1-error:0.302239
[10] validation_0-error:0.260032 validation_1-error:0.302239
[11] validation_0-error:0.260032 validation_1-error:0.302239
[12] validation_0-error:0.260032 validation_1-error:0.302239
[13] validation_0-error:0.247191 validation_1-error:0.298507
[14] validation_0-error:0.247191 validation_1-error:0.298507
[15] validation_0-error:0.248796 validation_1-error:0.302239
[16] validation_0-error:0.248796 validation_1-error:0.302239
[17] validation_0-error:0.248796 validation_1-error:0.302239
[18] validation_0-error:0.248796 validation_1-error:0.302239
[19] validation_0-error:0.248796 validation_1-error:0.302239
[20] validation_0-error:0.248796 validation_1-error:0.302239
[21] validation_0-error:0.248796 validation_1-error:0.302239
[22] validation_0-error:0.248796 validation_1-error:0.302239
[23] validation_0-error:0.248796 validation_1-error:0.302239
[24] validation_0-error:0.248796 validation_1-error:0.302239
[25] validation_0-error:0.248796 validation_1-error:0.302239
[26] validation_0-error:0.248796 validation_1-error:0.302239
[27] validation_0-error:0.248796 validation_1-error:0.302239
[28] validation_0-error:0.247191 validation_1-error:0.302239
[29] validation_0-error:0.247191 validation_1-error:0.302239
[30] validation_0-error:0.247191 validation_1-error:0.302239
[31] validation_0-error:0.243981 validation_1-error:0.298507
[32] validation_0-error:0.247191 validation_1-error:0.302239
[33] validation_0-error:0.243981 validation_1-error:0.298507
[34] validation_0-error:0.243981 validation_1-error:0.298507
[35] validation_0-error:0.242376 validation_1-error:0.294776
[36] validation_0-error:0.24077 validation_1-error:0.294776
[37] validation_0-error:0.24077 validation_1-error:0.294776
[38] validation_0-error:0.24077 validation_1-error:0.294776
[39] validation_0-error:0.24077 validation_1-error:0.294776
[40] validation_0-error:0.24077 validation_1-error:0.294776
[41] validation_0-error:0.24077 validation_1-error:0.294776
[42] validation_0-error:0.24077 validation_1-error:0.294776
[43] validation_0-error:0.24077 validation_1-error:0.294776
[44] validation_0-error:0.24077 validation_1-error:0.302239
[45] validation_0-error:0.24077 validation_1-error:0.302239
[46] validation_0-error:0.24077 validation_1-error:0.302239
[47] validation_0-error:0.24077 validation_1-error:0.302239
[48] validation_0-error:0.24077 validation_1-error:0.302239
[49] validation_0-error:0.24077 validation_1-error:0.302239
[50] validation_0-error:0.24077 validation_1-error:0.302239
[51] validation_0-error:0.24077 validation_1-error:0.302239
[52] validation_0-error:0.23435 validation_1-error:0.302239
[53] validation_0-error:0.23435 validation_1-error:0.302239
[54] validation_0-error:0.232745 validation_1-error:0.298507
[55] validation_0-error:0.229535 validation_1-error:0.298507
[56] validation_0-error:0.229535 validation_1-error:0.298507
[57] validation_0-error:0.229535 validation_1-error:0.298507
[58] validation_0-error:0.229535 validation_1-error:0.298507
[59] validation_0-error:0.227929 validation_1-error:0.294776
[60] validation_0-error:0.227929 validation_1-error:0.298507
[61] validation_0-error:0.227929 validation_1-error:0.298507
[62] validation_0-error:0.227929 validation_1-error:0.298507
[63] validation_0-error:0.227929 validation_1-error:0.298507
[64] validation_0-error:0.227929 validation_1-error:0.298507
[65] validation_0-error:0.227929 validation_1-error:0.298507
[66] validation_0-error:0.227929 validation_1-error:0.298507
[67] validation_0-error:0.227929 validation_1-error:0.298507
[68] validation_0-error:0.227929 validation_1-error:0.298507
[69] validation_0-error:0.227929 validation_1-error:0.298507
[70] validation_0-error:0.227929 validation_1-error:0.298507
[71] validation_0-error:0.227929 validation_1-error:0.298507
[72] validation_0-error:0.227929 validation_1-error:0.302239
[73] validation_0-error:0.227929 validation_1-error:0.302239
[74] validation_0-error:0.229535 validation_1-error:0.30597
[75] validation_0-error:0.229535 validation_1-error:0.30597
[76] validation_0-error:0.229535 validation_1-error:0.30597
[77] validation_0-error:0.229535 validation_1-error:0.30597
[78] validation_0-error:0.229535 validation_1-error:0.30597
[79] validation_0-error:0.229535 validation_1-error:0.30597
[80] validation_0-error:0.229535 validation_1-error:0.30597
[81] validation_0-error:0.229535 validation_1-error:0.30597
[82] validation_0-error:0.229535 validation_1-error:0.30597
[83] validation_0-error:0.229535 validation_1-error:0.30597
[84] validation_0-error:0.229535 validation_1-error:0.30597
[85] validation_0-error:0.229535 validation_1-error:0.30597
[86] validation_0-error:0.229535 validation_1-error:0.30597
[87] validation_0-error:0.229535 validation_1-error:0.30597
[88] validation_0-error:0.229535 validation_1-error:0.30597
[89] validation_0-error:0.229535 validation_1-error:0.30597
[90] validation_0-error:0.229535 validation_1-error:0.30597
[91] validation_0-error:0.229535 validation_1-error:0.30597
[92] validation_0-error:0.229535 validation_1-error:0.30597
[93] validation_0-error:0.229535 validation_1-error:0.30597
[94] validation_0-error:0.227929 validation_1-error:0.313433
[95] validation_0-error:0.226324 validation_1-error:0.313433
[96] validation_0-error:0.223114 validation_1-error:0.317164
[97] validation_0-error:0.223114 validation_1-error:0.317164
[98] validation_0-error:0.223114 validation_1-error:0.317164
[99] validation_0-error:0.223114 validation_1-error:0.317164
0.6828358208955224
LightGBM
- 마이크로소프트에서 개발함.
- XGBoost와 성능은 비슷하지만, 훈련 속도가 더 빨라서 많이 애용함.
- 대부분의 트리기반 모델은 균형 있게 분할하며 훈련
- 균형을 유지하려면 추가 연산 필요하며, 속도를 저해 시키는 주 요인
- LightGBM은 말단 노드 중심
- 균형을 맞출 필요가 없으니 추가 연산도 불필요.
- 균현 중심 분할에 비해 더 빠름.
- 데이터 갯수가 적을 시 과대적합 발생 가능성 존재.
- XGBoost와 동일하게 Python Wrapper 모듈과 Scikit-Learn Wrapper 모듈 존재
- 하이퍼 파라미터 목록 : https://lightgbm.readthedocs.io/en/latest/Parameters.html
LightGBM 하이퍼 파라미터
- XGBoost와 마찬가지로 약, 80개 이상의 파라미터가 존재한다. 따라서, 파라미터를 모두 공부할 수는 없다.
- 크게 다음과 같은 파라미터로 구성된다.
- Core Parameters : 일반적으로 모델의 훈련 목적, 부스팅 알고리즘 등 모델의 핵심 요소등을 관장하는 코드로 구성되어 있다.
- objective: 훈련 목적을 말하며, 회귀에서는 regression, 이진분류에서는 binary, 다중 분류에서는 multiclass 등을 주로 사용한다.
- boosting_type : 부스팅 알고리즘을 말하며, gbdt, rf, dart, goss 등의 알고리즘이 존재한다. (기본값 = gbdt)
- learning_rate : 학습률을 의미한다. (기본값 = 0.1)
- num_leaves : 개별 트리가 가질 수 있는 최대 말단 노드 개수. (기본 값 = 31)
- Learning Control Parameters : 학습 시, 과대 적합 또는 과소 적합을 방지와 관련된 파라미터 등
- max_depth : 개별 트리의 최대 깊이를 말하며, 트리의 깊이가 깊을수록 모델이 복잡해지고 과대적합될 우려가 존재.
- feature_fraction : 개별 트리를 훈련할 때 사용하는 피처 샘플링 비율
- 그 외에도 IO Parameters, Predict Parameters, Convert Parameters, Objective Parameters, Metric Parameters, Network Parameters, GPU Parameters가 존재한다.
- Core Parameters : 일반적으로 모델의 훈련 목적, 부스팅 알고리즘 등 모델의 핵심 요소등을 관장하는 코드로 구성되어 있다.
Python Wrapper LightGBM
- XGBoost와 유사한 방식을 취한다.
import lightgbm as lgb
from sklearn.model_selection import train_test_split
import seaborn as sns
# tips 데이터셋
titanic = sns.load_dataset('titanic')
X = titanic[['pclass', 'parch', 'fare']]
y = titanic['survived']
# 훈련데이터, 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, test_size = 0.3, random_state=42)
# XGBoost 코드와 유사하다.
dtrain = lgb.Dataset(data = X_train, label = y_train)
dtest = lgb.Dataset(data = X_test, label = y_test)
- 모델링을 적용한다.
- 모델링 적용 시, Parameter 코드가 일부 XGBoost와 다르다.
| 구분 | XGBoost | LightGBM |
|---|---|---|
| 훈련목적 | binary:logistic | binary |
| 학습률 | eta | learning_rate |
params = {'max_depth':3,
'n_estimators':100,
'learning_rate': 0.1,
'objective':'binary',
'metric' : 'binary_error',
'num_boost_round' : 400,
'verbose' : 1}
w_list = [dtrain, dtest]
lgb_ml = lgb.train(params=params, train_set = dtrain,\
early_stopping_rounds=100, valid_sets= w_list)
[1] training's binary_error: 0.383628 valid_1's binary_error: 0.384328
Training until validation scores don't improve for 100 rounds.
[2] training's binary_error: 0.383628 valid_1's binary_error: 0.384328
[3] training's binary_error: 0.354735 valid_1's binary_error: 0.369403
[4] training's binary_error: 0.29695 valid_1's binary_error: 0.354478
[5] training's binary_error: 0.272873 valid_1's binary_error: 0.33209
[6] training's binary_error: 0.272873 valid_1's binary_error: 0.33209
[7] training's binary_error: 0.269663 valid_1's binary_error: 0.317164
[8] training's binary_error: 0.269663 valid_1's binary_error: 0.317164
[9] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[10] training's binary_error: 0.269663 valid_1's binary_error: 0.309701
[11] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[12] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[13] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[14] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[15] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[16] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[17] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[18] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[19] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[20] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[21] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[22] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[23] training's binary_error: 0.271268 valid_1's binary_error: 0.313433
[24] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[25] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[26] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[27] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[28] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[29] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[30] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[31] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[32] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[33] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[34] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[35] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[36] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[37] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[38] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[39] training's binary_error: 0.248796 valid_1's binary_error: 0.309701
[40] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[41] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[42] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[43] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[44] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[45] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[46] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[47] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[48] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[49] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[50] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[51] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[52] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[53] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[54] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[55] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[56] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[57] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[58] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[59] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[60] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[61] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[62] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[63] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[64] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[65] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[66] training's binary_error: 0.243981 valid_1's binary_error: 0.309701
[67] training's binary_error: 0.23435 valid_1's binary_error: 0.309701
[68] training's binary_error: 0.23435 valid_1's binary_error: 0.309701
[69] training's binary_error: 0.23435 valid_1's binary_error: 0.309701
[70] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[71] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[72] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[73] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[74] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[75] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[76] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[77] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[78] training's binary_error: 0.232745 valid_1's binary_error: 0.313433
[79] training's binary_error: 0.232745 valid_1's binary_error: 0.313433
[80] training's binary_error: 0.232745 valid_1's binary_error: 0.313433
[81] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[82] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[83] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[84] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[85] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[86] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[87] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[88] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[89] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[90] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[91] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[92] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[93] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[94] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[95] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[96] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[97] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[98] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
/usr/local/lib/python3.7/dist-packages/lightgbm/engine.py:118: UserWarning: Found `num_boost_round` in params. Will use it instead of argument
warnings.warn("Found `{}` in params. Will use it instead of argument".format(alias))
[99] training's binary_error: 0.221509 valid_1's binary_error: 0.317164
[100] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[101] training's binary_error: 0.23114 valid_1's binary_error: 0.30597
[102] training's binary_error: 0.23114 valid_1's binary_error: 0.30597
[103] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[104] training's binary_error: 0.221509 valid_1's binary_error: 0.317164
[105] training's binary_error: 0.221509 valid_1's binary_error: 0.317164
[106] training's binary_error: 0.224719 valid_1's binary_error: 0.313433
[107] training's binary_error: 0.224719 valid_1's binary_error: 0.317164
[108] training's binary_error: 0.224719 valid_1's binary_error: 0.317164
[109] training's binary_error: 0.224719 valid_1's binary_error: 0.317164
[110] training's binary_error: 0.224719 valid_1's binary_error: 0.317164
[111] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[112] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[113] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[114] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[115] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[116] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[117] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[118] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[119] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[120] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[121] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[122] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[123] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[124] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[125] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[126] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[127] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[128] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[129] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[130] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[131] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[132] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[133] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[134] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[135] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[136] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[137] training's binary_error: 0.219904 valid_1's binary_error: 0.309701
[138] training's binary_error: 0.219904 valid_1's binary_error: 0.309701
[139] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[140] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[141] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[142] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[143] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[144] training's binary_error: 0.221509 valid_1's binary_error: 0.320896
[145] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[146] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
[147] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
[148] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
[149] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
[150] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[151] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[152] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
[153] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[154] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[155] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[156] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[157] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[158] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[159] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[160] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[161] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[162] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[163] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[164] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[165] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[166] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[167] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[168] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[169] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[170] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[171] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[172] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[173] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[174] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[175] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[176] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[177] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[178] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[179] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[180] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[181] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[182] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[183] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[184] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[185] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[186] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[187] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[188] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[189] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[190] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[191] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[192] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[193] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[194] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[195] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[196] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[197] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[198] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[199] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[200] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[201] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
Early stopping, best iteration is:
[101] training's binary_error: 0.23114 valid_1's binary_error: 0.30597
- 모형 평가를 진행한다.
- predict() 함수 사용 시, dtest가 아닌 X_test가 오는 것에 주의한다.
from sklearn.metrics import accuracy_score
pred_probs = lgb_ml.predict(X_test)
y_pred=[1 if x > 0.5 else 0 for x in pred_probs]
# 예측 라벨과 실제 라벨 사이의 정확도 측정
accuracy_score(y_pred, y_test)
0.6940298507462687
Scikit-Learn Wrapper LightGBM
- LGBClassifier() 클래스를 불러오기만 하면 된다.
from lightgbm import LGBMClassifier
from sklearn.metrics import accuracy_score
# model
w_list = [dtrain, dtest]
model = LGBMClassifier(objective = 'binary',
metric = 'binary_error',
n_estimators=100,
learning_rate=0.1,
max_depth=3,
num_boost_round = 400,
random_state = 32)
model.fit(X_train,
y_train,
eval_set = [(X_train, y_train), (X_test, y_test)],
verbose=1,
early_stopping_rounds = 100)
y_probas = model.predict_proba(X_test)
y_pred=[1 if x > 0.5 else 0 for x in y_probas[:, 1]] # 예측 라벨(0과 1로 예측)
# 예측 라벨과 실제 라벨 사이의 정확도 측정
accuracy_score(y_pred, y_test)
[1] training's binary_error: 0.383628 valid_1's binary_error: 0.384328
Training until validation scores don't improve for 100 rounds.
[2] training's binary_error: 0.383628 valid_1's binary_error: 0.384328
[3] training's binary_error: 0.354735 valid_1's binary_error: 0.369403
[4] training's binary_error: 0.29695 valid_1's binary_error: 0.354478
[5] training's binary_error: 0.272873 valid_1's binary_error: 0.33209
[6] training's binary_error: 0.272873 valid_1's binary_error: 0.33209
[7] training's binary_error: 0.269663 valid_1's binary_error: 0.317164
[8] training's binary_error: 0.269663 valid_1's binary_error: 0.317164
[9] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[10] training's binary_error: 0.269663 valid_1's binary_error: 0.309701
[11] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[12] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[13] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[14] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[15] training's binary_error: 0.264848 valid_1's binary_error: 0.309701
[16] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[17] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[18] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[19] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[20] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[21] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[22] training's binary_error: 0.266453 valid_1's binary_error: 0.313433
[23] training's binary_error: 0.271268 valid_1's binary_error: 0.313433
[24] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[25] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[26] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[27] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[28] training's binary_error: 0.258427 valid_1's binary_error: 0.309701
[29] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[30] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[31] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[32] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[33] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[34] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[35] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[36] training's binary_error: 0.255217 valid_1's binary_error: 0.309701
[37] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[38] training's binary_error: 0.255217 valid_1's binary_error: 0.317164
[39] training's binary_error: 0.248796 valid_1's binary_error: 0.309701
[40] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[41] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[42] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[43] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[44] training's binary_error: 0.248796 valid_1's binary_error: 0.313433
[45] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[46] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[47] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[48] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[49] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[50] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[51] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[52] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[53] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[54] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[55] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[56] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[57] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[58] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[59] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[60] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[61] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[62] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[63] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[64] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[65] training's binary_error: 0.247191 valid_1's binary_error: 0.313433
[66] training's binary_error: 0.243981 valid_1's binary_error: 0.309701
[67] training's binary_error: 0.23435 valid_1's binary_error: 0.309701
[68] training's binary_error: 0.23435 valid_1's binary_error: 0.309701
[69] training's binary_error: 0.23435 valid_1's binary_error: 0.309701
[70] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[71] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[72] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[73] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[74] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[75] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[76] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[77] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[78] training's binary_error: 0.232745 valid_1's binary_error: 0.313433
[79] training's binary_error: 0.232745 valid_1's binary_error: 0.313433
[80] training's binary_error: 0.232745 valid_1's binary_error: 0.313433
[81] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[82] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[83] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[84] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[85] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[86] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[87] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[88] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[89] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[90] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[91] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[92] training's binary_error: 0.229535 valid_1's binary_error: 0.309701
[93] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[94] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[95] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[96] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[97] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[98] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[99] training's binary_error: 0.221509 valid_1's binary_error: 0.317164
[100] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[101] training's binary_error: 0.23114 valid_1's binary_error: 0.30597
[102] training's binary_error: 0.23114 valid_1's binary_error: 0.30597
[103] training's binary_error: 0.227929 valid_1's binary_error: 0.309701
[104] training's binary_error: 0.221509 valid_1's binary_error: 0.317164
[105] training's binary_error: 0.221509 valid_1's binary_error: 0.317164
[106] training's binary_error: 0.224719 valid_1's binary_error: 0.313433
[107] training's binary_error: 0.224719 valid_1's binary_error: 0.317164
[108] training's binary_error: 0.224719 valid_1's binary_error: 0.317164
[109] training's binary_error: 0.224719 valid_1's binary_error: 0.317164
[110] training's binary_error: 0.224719 valid_1's binary_error: 0.317164
[111] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[112] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[113] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[114] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[115] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[116] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[117] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[118] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[119] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[120] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[121] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[122] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[123] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[124] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[125] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[126] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[127] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[128] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[129] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[130] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[131] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[132] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[133] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[134] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[135] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[136] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[137] training's binary_error: 0.219904 valid_1's binary_error: 0.309701
[138] training's binary_error: 0.219904 valid_1's binary_error: 0.309701
[139] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[140] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[141] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[142] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[143] training's binary_error: 0.223114 valid_1's binary_error: 0.309701
[144] training's binary_error: 0.221509 valid_1's binary_error: 0.320896
[145] training's binary_error: 0.223114 valid_1's binary_error: 0.313433
[146] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
/usr/local/lib/python3.7/dist-packages/lightgbm/engine.py:118: UserWarning: Found `num_boost_round` in params. Will use it instead of argument
warnings.warn("Found `{}` in params. Will use it instead of argument".format(alias))
[147] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
[148] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
[149] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
[150] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[151] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[152] training's binary_error: 0.221509 valid_1's binary_error: 0.313433
[153] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[154] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[155] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[156] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[157] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[158] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[159] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[160] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[161] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[162] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[163] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[164] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[165] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[166] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[167] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[168] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[169] training's binary_error: 0.219904 valid_1's binary_error: 0.324627
[170] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[171] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[172] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[173] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[174] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[175] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[176] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[177] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[178] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[179] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[180] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[181] training's binary_error: 0.221509 valid_1's binary_error: 0.328358
[182] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[183] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[184] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[185] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[186] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[187] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[188] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[189] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[190] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[191] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[192] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[193] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[194] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[195] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[196] training's binary_error: 0.216693 valid_1's binary_error: 0.320896
[197] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[198] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[199] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[200] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
[201] training's binary_error: 0.215088 valid_1's binary_error: 0.317164
Early stopping, best iteration is:
[101] training's binary_error: 0.23114 valid_1's binary_error: 0.30597
0.6940298507462687
하이퍼파라미터 최적화
- 모델의 성능을 극대화할 수 있는 하이퍼파라미터를 찾는 것이 과제임.
- 대표적인 최적화 방법은 그리드서치, 랜덤서치, 베이지안 최적화임.
- 가장 간단한 모형인 DecisionTreeClassifier를 활용하여 수행한다.
그리드 서치
- 그리드 서치는 사용자가 직접 리스트를 작성한 경우의 수를 모두 탐색하는 방법이지만, 오래 걸린다는 단점이 존재한다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
import seaborn as sns
# tips 데이터셋
titanic = sns.load_dataset('titanic')
X = titanic[['pclass', 'parch', 'fare']]
y = titanic['survived']
# 훈련데이터, 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X,
y,
stratify = y,
test_size = 0.3,
random_state=42)
# 하이퍼 파라미터 튜닝
params = {
'max_depth': [2, 3, 5],
'min_samples_leaf': [5, 10, 20],
'criterion': ["gini", "entropy"]
}
# 모형 정의
dt = DecisionTreeClassifier(random_state=42)
gs = GridSearchCV(dt, params, n_jobs = -1)
# 모형 학습
gs.fit(X_train, y_train)
# 모형 평가
print(gs.best_estimator_.score(X_train, y_train))
print(gs.best_estimator_.score(X_test, y_test))
# 최적 파라미터 산출
print(gs.best_params_)
0.7351524879614767
0.6791044776119403
{'criterion': 'entropy', 'max_depth': 5, 'min_samples_leaf': 20}
랜덤 서치
- 그리드 서치의 가장 큰 단점은 매개변수의 값이 수치일 때, 값의 범위를 간격을 미리 정할수가 없다.
- 랜덤 서치에는 매개변수 값의 목록을 전달하는 것이 아닌 확률 분포 객체를 전달한다.
- 이 때 같이 사용할 라이브러리는 scipy를 사용한다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RandomizedSearchCV
import seaborn as sns
from scipy.stats import uniform, randint
# tips 데이터셋
titanic = sns.load_dataset('titanic')
X = titanic[['pclass', 'parch', 'fare']]
y = titanic['survived']
# 훈련데이터, 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X,
y,
stratify = y,
test_size = 0.3,
random_state=42)
# 하이퍼 파라미터 튜닝
params = {
'min_impurity_decrease' : uniform(0.0001, 0.001),
'max_depth': randint(2, 10),
'min_samples_leaf': randint(5, 20),
'criterion': ["gini", "entropy"]
}
# 모형 정의
dt = DecisionTreeClassifier(random_state=42)
rs = RandomizedSearchCV(dt, params, n_jobs = -1)
# 모형 학습
rs.fit(X_train, y_train)
# 모형 평가
print(rs.best_estimator_.score(X_train, y_train))
print(rs.best_estimator_.score(X_test, y_test))
# 최적 파라미터 산출
print(rs.best_params_)
0.7447833065810594
0.6753731343283582
{'criterion': 'entropy', 'max_depth': 8, 'min_impurity_decrease': 0.0007925315900777659, 'min_samples_leaf': 17}
베이지안 최적화
- 베이지안 최적화는 사전 정보를 바탕으로 최적의 하이퍼파라미터 값을 확률적으로 추정하며 탐색함.
- 작업 순서는 다음과 같다.
- 하이퍼파라미터 탐색 범위 설정
- 평가지표 계산 함수 정의
- BayesianOptimization 객체 생성
- 베이지안 최적화 수행
!pip install bayesian-optimization
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: bayesian-optimization in /usr/local/lib/python3.7/dist-packages (1.2.0)
Requirement already satisfied: scikit-learn>=0.18.0 in /usr/local/lib/python3.7/dist-packages (from bayesian-optimization) (1.0.2)
Requirement already satisfied: numpy>=1.9.0 in /usr/local/lib/python3.7/dist-packages (from bayesian-optimization) (1.21.6)
Requirement already satisfied: scipy>=0.14.0 in /usr/local/lib/python3.7/dist-packages (from bayesian-optimization) (1.4.1)
Requirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.18.0->bayesian-optimization) (1.1.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.18.0->bayesian-optimization) (3.1.0)
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from bayes_opt import BayesianOptimization
import seaborn as sns
from scipy.stats import uniform, randint
# tips 데이터셋
titanic = sns.load_dataset('titanic')
X = titanic[['pclass', 'parch', 'fare']]
y = titanic['survived']
# 훈련데이터, 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X,
y,
stratify = y,
test_size = 0.3,
random_state=42)
# Gradient Boosting Machine
def dt_cl_bo(max_depth, max_features):
params_tree = {}
params_tree['max_depth'] = round(max_depth)
params_tree['max_features'] = max_features
dt = DecisionTreeClassifier(random_state=42, **params_tree)
dt.fit(X_train, y_train)
score = dt.score(X_test, y_test)
return score
# Run Bayesian Optimization
params_tree ={
'max_depth':(3, 10),
'max_features':(0.8, 1)
}
dt_bo = BayesianOptimization(dt_cl_bo, params_tree, random_state=111)
dt_bo.maximize(init_points=20, n_iter=4)
print("Best result: {}; f(x) = {}.".format(dt_bo.max["params"], dt_bo.max["target"]))
| iter | target | max_depth | max_fe... |
-------------------------------------------------
| [0m 1 [0m | [0m 0.6642 [0m | [0m 7.285 [0m | [0m 0.8338 [0m |
| [0m 2 [0m | [0m 0.6604 [0m | [0m 6.052 [0m | [0m 0.9539 [0m |
| [95m 3 [0m | [95m 0.694 [0m | [95m 5.067 [0m | [95m 0.8298 [0m |
| [95m 4 [0m | [95m 0.7015 [0m | [95m 3.157 [0m | [95m 0.884 [0m |
| [0m 5 [0m | [0m 0.694 [0m | [0m 4.671 [0m | [0m 0.8675 [0m |
| [0m 6 [0m | [0m 0.6716 [0m | [0m 9.935 [0m | [0m 0.8475 [0m |
| [0m 7 [0m | [0m 0.6828 [0m | [0m 3.568 [0m | [0m 0.9339 [0m |
| [0m 8 [0m | [0m 0.6642 [0m | [0m 7.349 [0m | [0m 0.8549 [0m |
| [0m 9 [0m | [0m 0.6604 [0m | [0m 6.264 [0m | [0m 0.8237 [0m |
| [0m 10 [0m | [0m 0.6828 [0m | [0m 3.518 [0m | [0m 0.9802 [0m |
| [0m 11 [0m | [0m 0.6866 [0m | [0m 8.558 [0m | [0m 0.9681 [0m |
| [0m 12 [0m | [0m 0.6866 [0m | [0m 8.706 [0m | [0m 0.9982 [0m |
| [0m 13 [0m | [0m 0.6642 [0m | [0m 7.041 [0m | [0m 0.9628 [0m |
| [0m 14 [0m | [0m 0.6604 [0m | [0m 5.949 [0m | [0m 0.8055 [0m |
| [0m 15 [0m | [0m 0.6604 [0m | [0m 6.179 [0m | [0m 0.8211 [0m |
| [0m 16 [0m | [0m 0.6866 [0m | [0m 8.721 [0m | [0m 0.9395 [0m |
| [0m 17 [0m | [0m 0.6642 [0m | [0m 6.957 [0m | [0m 0.8548 [0m |
| [0m 18 [0m | [0m 0.6716 [0m | [0m 9.989 [0m | [0m 0.8276 [0m |
| [0m 19 [0m | [0m 0.6642 [0m | [0m 7.308 [0m | [0m 0.897 [0m |
| [0m 20 [0m | [0m 0.6604 [0m | [0m 5.835 [0m | [0m 0.9456 [0m |
| [0m 21 [0m | [0m 0.7015 [0m | [0m 3.001 [0m | [0m 0.8255 [0m |
| [0m 22 [0m | [0m 0.7015 [0m | [0m 3.013 [0m | [0m 0.998 [0m |
| [0m 23 [0m | [0m 0.7015 [0m | [0m 3.168 [0m | [0m 0.8004 [0m |
| [0m 24 [0m | [0m 0.6978 [0m | [0m 4.899 [0m | [0m 1.0 [0m |
=================================================
Best result: {'max_depth': 3.1573482718091324, 'max_features': 0.8840448984529116}; f(x) = 0.7014925373134329.
References
- 신백균. (2022). 머신러닝 및 딥러닝 문제해결 전략 (교재 강추)
- Rendyk. (2021). Bayesian Optimization: bayes_opt or hyperopt
