입문자를 위한 머신러닝 - 랜덤 포레스트
Page content
공지
- 본 포스트는 교재
파이썬 머신러닝 완벽 가이드코드를 제 수업을 드는 학생들이 보다 편하게 구글 코랩에서 사용할 수 있도록 만든 예제입니다. - 책 구매하세요!
Random Forest
랜덤 포레스트의 개요
- 배깅의 대표적인 알고리즘
- 랜덤 포레스트는 개별 트리가 학습하는 데이터 세트는 전체 데이터에서 일부가 중첩되게 샘플링 된 데이터 세트
- 부트스트래핑 부할 방식 채택
- 참고 강의 이론
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00240/UCI%20HAR%20Dataset.zip
!unzip 'UCI HAR Dataset.zip'
!mv UCI\ HAR\ Dataset human_activity
--2020-11-27 05:21:51-- https://archive.ics.uci.edu/ml/machine-learning-databases/00240/UCI%20HAR%20Dataset.zip
Resolving archive.ics.uci.edu (archive.ics.uci.edu)... 128.195.10.252
Connecting to archive.ics.uci.edu (archive.ics.uci.edu)|128.195.10.252|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 60999314 (58M) [application/x-httpd-php]
Saving to: ‘UCI HAR Dataset.zip’
UCI HAR Dataset.zip 100%[===================>] 58.17M 33.8MB/s in 1.7s
2020-11-27 05:21:53 (33.8 MB/s) - ‘UCI HAR Dataset.zip’ saved [60999314/60999314]
Archive: UCI HAR Dataset.zip
creating: UCI HAR Dataset/
inflating: UCI HAR Dataset/.DS_Store
creating: __MACOSX/
creating: __MACOSX/UCI HAR Dataset/
inflating: __MACOSX/UCI HAR Dataset/._.DS_Store
inflating: UCI HAR Dataset/activity_labels.txt
inflating: __MACOSX/UCI HAR Dataset/._activity_labels.txt
inflating: UCI HAR Dataset/features.txt
inflating: __MACOSX/UCI HAR Dataset/._features.txt
inflating: UCI HAR Dataset/features_info.txt
inflating: __MACOSX/UCI HAR Dataset/._features_info.txt
inflating: UCI HAR Dataset/README.txt
inflating: __MACOSX/UCI HAR Dataset/._README.txt
creating: UCI HAR Dataset/test/
creating: UCI HAR Dataset/test/Inertial Signals/
inflating: UCI HAR Dataset/test/Inertial Signals/body_acc_x_test.txt
creating: __MACOSX/UCI HAR Dataset/test/
creating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/
inflating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/._body_acc_x_test.txt
inflating: UCI HAR Dataset/test/Inertial Signals/body_acc_y_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/._body_acc_y_test.txt
inflating: UCI HAR Dataset/test/Inertial Signals/body_acc_z_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/._body_acc_z_test.txt
inflating: UCI HAR Dataset/test/Inertial Signals/body_gyro_x_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/._body_gyro_x_test.txt
inflating: UCI HAR Dataset/test/Inertial Signals/body_gyro_y_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/._body_gyro_y_test.txt
inflating: UCI HAR Dataset/test/Inertial Signals/body_gyro_z_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/._body_gyro_z_test.txt
inflating: UCI HAR Dataset/test/Inertial Signals/total_acc_x_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/._total_acc_x_test.txt
inflating: UCI HAR Dataset/test/Inertial Signals/total_acc_y_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/._total_acc_y_test.txt
inflating: UCI HAR Dataset/test/Inertial Signals/total_acc_z_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/Inertial Signals/._total_acc_z_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/._Inertial Signals
inflating: UCI HAR Dataset/test/subject_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/._subject_test.txt
inflating: UCI HAR Dataset/test/X_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/._X_test.txt
inflating: UCI HAR Dataset/test/y_test.txt
inflating: __MACOSX/UCI HAR Dataset/test/._y_test.txt
inflating: __MACOSX/UCI HAR Dataset/._test
creating: UCI HAR Dataset/train/
creating: UCI HAR Dataset/train/Inertial Signals/
inflating: UCI HAR Dataset/train/Inertial Signals/body_acc_x_train.txt
creating: __MACOSX/UCI HAR Dataset/train/
creating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/
inflating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/._body_acc_x_train.txt
inflating: UCI HAR Dataset/train/Inertial Signals/body_acc_y_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/._body_acc_y_train.txt
inflating: UCI HAR Dataset/train/Inertial Signals/body_acc_z_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/._body_acc_z_train.txt
inflating: UCI HAR Dataset/train/Inertial Signals/body_gyro_x_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/._body_gyro_x_train.txt
inflating: UCI HAR Dataset/train/Inertial Signals/body_gyro_y_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/._body_gyro_y_train.txt
inflating: UCI HAR Dataset/train/Inertial Signals/body_gyro_z_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/._body_gyro_z_train.txt
inflating: UCI HAR Dataset/train/Inertial Signals/total_acc_x_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/._total_acc_x_train.txt
inflating: UCI HAR Dataset/train/Inertial Signals/total_acc_y_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/._total_acc_y_train.txt
inflating: UCI HAR Dataset/train/Inertial Signals/total_acc_z_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/Inertial Signals/._total_acc_z_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/._Inertial Signals
inflating: UCI HAR Dataset/train/subject_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/._subject_train.txt
inflating: UCI HAR Dataset/train/X_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/._X_train.txt
inflating: UCI HAR Dataset/train/y_train.txt
inflating: __MACOSX/UCI HAR Dataset/train/._y_train.txt
inflating: __MACOSX/UCI HAR Dataset/._train
inflating: __MACOSX/._UCI HAR Dataset
import pandas as pd
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(),
columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1])
if x[1] >0 else x[0] , axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis=1)
return new_feature_name_df
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용, 신규 피처명 DataFrame생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt',sep='\s+', names=feature_name )
X_test = pd.read_csv('./human_activity/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 결정 트리에서 사용한 get_human_dataset( )을 이용해 학습/테스트용 DataFrame 반환
X_train, X_test, y_train, y_test = get_human_dataset()
print("## 학습 피처 데이터 정보 ##")
print(X_train.info())
## 학습 피처 데이터 정보 ##
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7352 entries, 0 to 7351
Columns: 561 entries, tBodyAcc-mean()-X to angle(Z,gravityMean)
dtypes: float64(561)
memory usage: 31.5 MB
None
- 간단한 랜덤포레스트 모형을 만들어 학습 시킨다.
- 매우 간단한 모형이기 때문에 학습에 시간이 많이 걸리지는 않는다.
# 랜덤 포레스트 학습 및 별도의 테스트 셋으로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train , y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy))
랜덤 포레스트 정확도: 0.9253
하이퍼 파라미터 및 튜닝
- 튜닝이란, 모형이 가지고 있는 여러 조건들을 변형 시키는 것
- 대표적인 파라미터 소개
- n_estimators: 결정 트리의 개수 지정, 디폴트는 10개이며, 많이 설정할수록 좋은 성능 기대 가능, 그러나 시간도 오래 소요됨
- max_features: 최적의 분할을 위해 고려할 피처의 개수
int형으로 지정 시, 대상 피처의 개수,float형으로 지정 시, 대상 피처의 퍼센트- 만약 전체 피처가 16개라면 분할 위해 4개 참조
- max_depth: 트리의 최대 깊이 규정
- min_samples_split: 자식 규칙 노드를 분할해 만들기 위한 최소한의 샘플 데이터 개수
- min_samples_leaf: 말단 노드(Leaf)가 되기 위한 최소한의 샘플 데이터 수
그리드 서치
- GridSearchCV API를 활용하여 모형에 사용되는 하이퍼 파라미터를 순차적으로 입력하며서 편리하게 최적의 파라미터를 도출할 수 있는 방안 제공
- 즉, 랜덤포레스트의 파라미터를 순차적으로 변경 및 조정하면서 모형을 학습시키는 방법
- 이를 통해, 머신러닝 모형 개발자의 코드량을 줄여주는 매우 편리한 기법
- estimator: 머신러닝 모형의 객체가 온다.
- param_grid: 딕셔너리 형태로 조정하며,
estimator의 튜닝을 위해 파라미터명과 사용될 여러 파라미터 값 지정, 이 부분은 각 머신러닝 모형의Manual을 참조한다. - scoring: 예측 성능을 측정할 평가 방법 지정하지만, 대개 별도의 성능 평가 지표 함수 활용
- cv: 교차 검증을 위해 분할되는 학습/테스트 세트의 개수 지정
- 이 때에는 시간이 다소 소요될 수 있다. (5-10분)
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 ) # n_job=-1 현재 모든 CPU를 활용한다는 뜻.
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))
최적 하이퍼 파라미터:
{'max_depth': 10, 'min_samples_leaf': 8, 'min_samples_split': 8, 'n_estimators': 100}
최고 예측 정확도: 0.9180
(옵션 체크) 구글 코랩 개발환경 확인
- 간단하게 구글 코랩 개발환경을 확인한다.
!cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 63
model name : Intel(R) Xeon(R) CPU @ 2.30GHz
stepping : 0
microcode : 0x1
cpu MHz : 2300.000
cache size : 46080 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat md_clear arch_capabilities
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs
bogomips : 4600.00
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 63
model name : Intel(R) Xeon(R) CPU @ 2.30GHz
stepping : 0
microcode : 0x1
cpu MHz : 2300.000
cache size : 46080 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 1
initial apicid : 1
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat md_clear arch_capabilities
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs
bogomips : 4600.00
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
모형의 개수 심기
- 최적의 파라미터를 활용하여
n_estimators의 개수를 100개에서 300개로 늘려봅니다.
rf_clf1 = RandomForestClassifier(n_estimators=300, max_depth=10, min_samples_leaf=8, \
min_samples_split=8, random_state=0)
rf_clf1.fit(X_train , y_train)
pred = rf_clf1.predict(X_test)
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))
예측 정확도: 0.9165
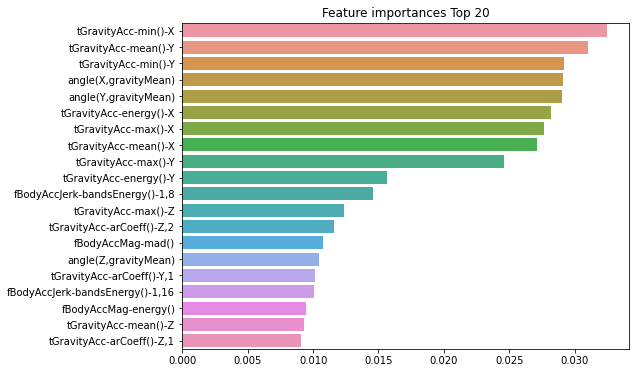
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
ftr_importances_values = rf_clf1.feature_importances_
ftr_importances = pd.Series(ftr_importances_values,index=X_train.columns )
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20 , y = ftr_top20.index)
plt.show()
Reference
권철민. (2020). 파이썬 머신러닝 완벽가이드. 경기, 파주: 위키북스
