Seaborn Intro - Scatterplot, Histogram
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

Seaborn 개요
Matplotlib 라이브러리가 Python에서 제공하는 기본적인 시각화 도구이지만, 기본객체는 리스트 형태를 따르기 때문에, 엑셀 데이터, 즉 데이터 프레임에 익숙한 사용자들에게는 조금 불친절한 것은 아쉬움이 있습니다. 실제, 입문자를 대상으로 강의를 할 때에도 Seaborn부터 알려드리는데, 그 이유는 Pandas를 활용한 데이터 가공 직후에 보다 쉽게 연동할 수 있도록 Seaborn이 개발되었기 때문입니다. 또한, Matplotlib에서는 회귀선과 같은 통계적 내용의 그래프도 보다 쉽게 구현할 수 있도록 제작되었습니다. 보다 정교한 시각적인 디자인을 추가 및 수정하려면, Matplotlib를 보다 더 잘 활용해야 합니다. 이는 마지막 본 포스트의 마지막 장에서 다루도록 합니다.
먼저, 간단한 예제를 통해서 익히도록 합니다.
(1) 라이브러리 불러오기
필요한 모듈을 불러옵니다.
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
(2) 데이터 불러오기
이번에는 seaborn 패키지 내 load_data 데이터를 활용합니다. 실전에서는 csv, excel, 또는 DB에서 직접 데이터를 불러오는 영역이 이 부분이 됩니다.
# tips 데이터셋 가져오기
tips = sns.load_dataset("tips")
# tips 데이터셋 살펴보기
print(tips.head())
print("\n")
print(tips.info())
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null category
3 smoker 244 non-null category
4 day 244 non-null category
5 time 244 non-null category
6 size 244 non-null int64
dtypes: category(4), float64(2), int64(1)
memory usage: 7.3 KB
None
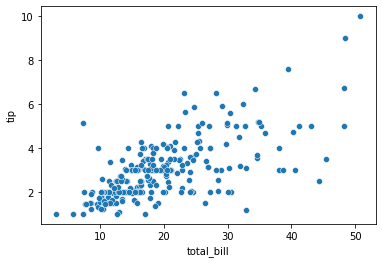
(3) 산점도와 회귀선이 있는 산점도
산점도는 서로 다른 2개의 연속형(=수치형) 변수 사이에 점을 찍는 그래프를 말합니다. 보통은 scatterplot를 사용하기도 하지만, 그 외에도 relplot() 또는 regplot() 사용할 수 있습니다. 먼저, scatterplot()를 활용하여 그래프를 작성합니다.
sns.scatterplot(x = "total_bill", y = "tip", data = tips)
plt.show()
그 이후에는 regplot()를 활용하여 그래프를 작성합니다. 이 때, fit_reg=False를 지정하지 않으면 회귀선이 나오게 됩니다. fit_reg=True와 비교해서 그래프를 보도록 합니다.
# 그래프 객체 생성
fig, ax = plt.subplots(nrows = 1, ncols = 2, figsize=(15, 5))
# 그래프 그리기(선형 회귀선 표시)
sns.regplot(x = "total_bill",
y = "tip",
data = tips,
ax = ax[0],
fit_reg = True)
# 그래프 그리기(선형 회귀선 표시 X)
sns.regplot(x = "total_bill",
y = "tip",
data = tips,
ax = ax[1],
fit_reg = False)
plt.show()
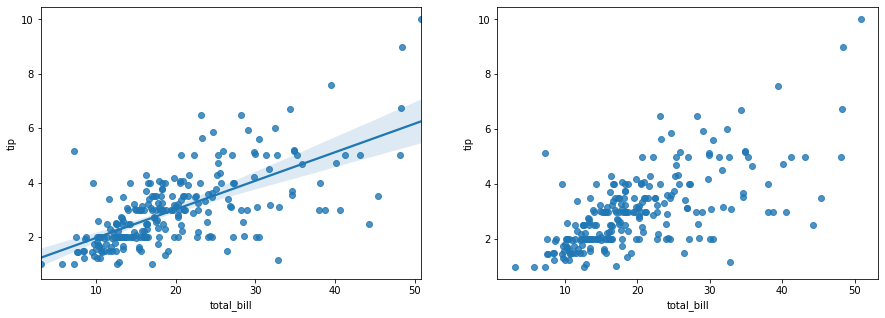
위 시각화를 통해서 두 변수간의 관계의 방향성을 탐색합니다. total_bill의 값이 커지면 커질수록 tip 같이 커지는지, 아니면 작아지는지 하는 관계의 방향성을 알려주는 그래프라고 볼 수 있습니다. 통계적인 내용이 궁금하다면, 상관분석과 회귀분석에 관한 통계적인 내용을 깊게 다루어야 하며, 이는 머신러닝 알고리즘에서 다루도록 합니다.
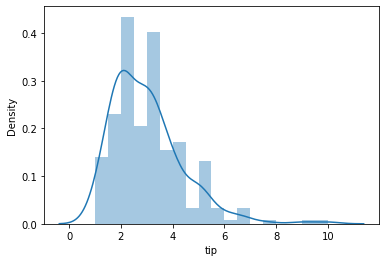
(4) 히스토그램/커널 밀도 그래프
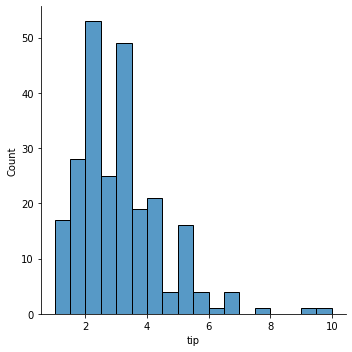
히스토그램은 연속형(=수치형) 데이터의 분포를 정확하게 나타나는데, 막대그래프과 비슷하여 처음 입문하는 사람들이 혼동하기도 합니다. Seaborn에서는 displot() 함수를 이용하여 사용되며, 기본값으로 히스토그램과 커널 밀도 함수를 그래프를 출력. 이 때, 커널 밀도 함수는 그래프의 면적이 1이 되도록 하는 것이 특징입니다. 먼저 기본함수를 활용하여 그래프를 작성해봅니다.
sns.displot(x = "tip", data = tips)
plt.show()
이번에는 히스토그램이 아닌 커널 밀도 그래프를 그리도록 합니다. 이 때에는 hist=False, kde = True라고 명명해야 합니다.
sns.distplot(tips['tip'], hist=False, kde = True)
plt.show()
/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `kdeplot` (an axes-level function for kernel density plots).
warnings.warn(msg, FutureWarning)
만약에, 두 그래프를 동시에 표현하고자 한다면 각각의 인수를 True로 명명하면 됩니다.
sns.distplot(tips['tip'], hist=True, kde = True)
plt.show()
/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)