데이콘 대회 참여 - 제주 신용카드 데이터 경진대회 피벗테이블 작성
Page content
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

공지
- 본 포스트는 필자의 수업을 듣는 사람들을 위해 작성하였습니다.
I. 구글 드라이브와 Colab과 연동
- 구글 드라이브와 Colab과 연동하면 보다 쉽게 데이터에 접근할 수 있다.
- 구글 인증만 하면 된다.
# Google Drive와 마운트
from google.colab import drive
ROOT = '/content/drive'
drive.mount(ROOT)
(1) 데이터 다운로드
- 제주 신용카드 데이터를 다운로드 받는다. (회원가입 필수)
- 웹사이트: 제주 신용카드 빅데이터 경진대회
(2) 구글 드라이브에 다운로드 받은 폴더를 올린다.
- 이 때, 경로통일을 위해
Colab Notebooks/python_elice/dacon/data로 경로 지정을 한다.
# Project Folder 연결
from os.path import join
MY_GOOGLE_DRIVE_PATH = 'My Drive/Colab Notebooks/python_elice/dacon/data'
PROJECT_PATH = join(ROOT, MY_GOOGLE_DRIVE_PATH)
print(PROJECT_PATH)
/content/drive/My Drive/Colab Notebooks/python_elice/dacon/data
- 아래 코드를 반드시 실행시켜야 해당 경로로 이동된다.
%cd "{PROJECT_PATH}"
/content/drive/My Drive/Colab Notebooks/python_elice/dacon/data
- 실제 업로드된 데이터가 있는지 확인한다.
!ls
201901-202003.csv submission.csv
- 만약 에러가 발생이 되면 경로가 잘못 지정된 것이니, 폴더 경로를 재확인한다.
- 경로에러가 발생할 시, 숙련자는 수정이 바로 가능하지만, 비숙련자는 가급적
[런타임 초기화]를 클릭한 후, 처음부터 다시 실행시키는 것을 추천한다.
(3) 데이터 불러오기
- 지난주간 과제로 내주었던 판다스 데이터를 불러오도록 한다.
- 시간이 다소 소요될 수 있다.
import pandas as pd
train = pd.read_csv("201901-202003.csv")
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 24697792 entries, 0 to 24697791
Data columns (total 12 columns):
# Column Dtype
--- ------ -----
0 REG_YYMM int64
1 CARD_SIDO_NM object
2 CARD_CCG_NM object
3 STD_CLSS_NM object
4 HOM_SIDO_NM object
5 HOM_CCG_NM object
6 AGE object
7 SEX_CTGO_CD int64
8 FLC int64
9 CSTMR_CNT int64
10 AMT int64
11 CNT int64
dtypes: int64(6), object(6)
memory usage: 2.2+ GB
(4) 데이터 샘플링
- 전체 데이터를 시각화 등 사용하면 시각화 시, 다소 느리게 출력될 수 있으니, 연습 차원에서는 가급적 샘플링 기법을 적용해서 데이터를 재정한다.
- 약
1000개의 데이터만 객체로 저장한다.
sample_train = train.sample(n=100000, random_state=1)
- 원 데이터와 샘플 데이터의 행의 크기를 비교한다.
len(train)
24697792
len(sample_train)
100000
- 물론, 위 샘플을 조금 늘려도 좋긴하지만, 가급적 시각화 코드가 모두 작성이 된 이후에 해보는 것을 추천한다.
II. 과제 - 피벗테이블
- 판다스 패키지를 활용한다.
AMT는 매출 데이터이다.- 과제 1. 시도별 매출 데이터의 피벗테이블을 작성한다.
- 과제 2. 업종별 매출 데이터의 피벗테이블을 작성한다.
- 마지막 과제 3. 시도별-업종별 매출 데이터의 피벗테이블을 작성한다.
- (옵션), 날짜별로 매출 데이터의 피벗테이블을 작성한다.
(공통) 판다스 피벗 테이블
- 가장 좋은 교재는 메뉴얼이다.
- 주요 파라미터는 다음과 같다.
- data: DataFrame
- values: Column to aggregate
- index: column, array or list
- aggfunc: function, list of functions, dict, default numpy.mean
(1) 시도별 매출 데이터
- 시도별 매출 데이터의 피벗테이블을 작성한다.
pd.pivot_table(sample_train, # 데이터
index='CARD_SIDO_NM', # 기준변수
values = 'AMT', # 타겟변수
aggfunc="sum") # 산술식
- 결과를 확인한다.
(2) 업종별 매출 데이터의 피벗테이블
- 이번에는 업종별 피벗테이블을 작성해본다.
pd.pivot_table(sample_train, # 데이터
index='STD_CLSS_NM', # 기준변수
values = 'AMT', # 타겟변수
aggfunc="sum") # 산술식
- 결과를 확인한다.
(3) 시도별-업종별 매출 데이터의 피벗테이블
- 이 때에는 피벗테이블에서 상위 5개의 데이터만 출력하도록 한다.
- 표시될 행이 많아야 하기 때문에 아래와 같이
setting을 한다.
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_colwidth', -1)
pivoted = pd.pivot_table(sample_train,
index=['CARD_SIDO_NM', 'STD_CLSS_NM'],
values = 'AMT',
aggfunc="sum")
pivoted\
.sort_values(['CARD_SIDO_NM', 'AMT'], ascending=[True, False])\
.groupby('CARD_SIDO_NM').head(5)\
.reset_index()\
.set_index(['CARD_SIDO_NM','STD_CLSS_NM'])
(4) 옵션-날짜별 매출 데이터의 피벗테이블
- 이번에는 날짜별 매출 데이터의 피벗테이블 작성
pd.pivot_table(sample_train, # 데이터
index='REG_YYMM', # 기준변수
values = 'AMT', # 타겟변수
aggfunc="sum") # 산술식
III. 과제 - 시각화
- seaborn 패키지를 활용하여 시각화를 작성한다.
- 한글 그래프가 깨져서 나올 것이다. (해결방안 참조: 데이콘 대회 참여 - 10 데이터 시각화)
- 위 코드를 활용해도 좋다.
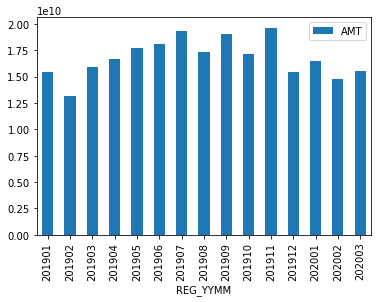
(1) 월별 막대그래프
- 간단한 예제로 옵션-날짜별 매출 데이터의 피벗테이블을 작성한다.
pd.pivot_table(sample_train, index='REG_YYMM', values = 'AMT', aggfunc="sum").plot(kind='bar')
IV. 분석 Report 작성
- 피벗테이블과 시각화를 근거로 간단하게 분석 보고서를 작성한다.
- 양식은 자유롭다.
- 굳이 참고한다면, 코로나 경제 관련 기사를 참조한다.
- 예) 경기도 코로나19 발생 이후 신용카드 매출액 전년 동기 대비 1조 8,821억 감소
