Seaborn Visualisation Tutorial - Basic
Page content
공지
제 수업을 듣는 사람들이 계속적으로 실습할 수 있도록 강의 파일을 만들었습니다. 늘 도움이 되기를 바라며. 참고했던 교재 및 Reference는 꼭 확인하셔서 교재 구매 또는 관련 Reference를 확인하시기를 바랍니다.
시각화 기본적 원리
- 비교, 대조, 차이를 드러내라.
- 인과관계와 상관관계를 보여라.
- 한 도표에 여러 변수를 보여라.
- 텍스트, 숫자, 이미지, 그래프 같은 데이터들을 한 곳에 통합하라.
- 사용된 데이터의 출처를 그래프 안이나 각주로 밝혀라.
- 의미 있는 내용을 담아라.
- 데이터 시각화를 정말 잘하고 싶다면, 책을 구매하는 것을 추천한다.
데이터 변수 종류에 따른 시각화의 종류
- 시각화는 그냥 그리는 것이 아니다. 변수의 종류에 따른 기법이 존재한다.
- 다만, Python & R의 방법론의 차이가 있을 뿐이다.
- 원리를 알면, 다음은 검색 및 연습을 통해 다듬어진다.

Seaborn 개요
- Seaborn 패키지는 Pandas 데이터프레임에 쉽게 연동하기 위해 나온 패키지이다.
- 초보자의 경우, 가급적 공식 홈페이지에 있는 코드를 모두 작성해보는 것이 중요하다.
산점도와 counplot 그래프
- 그래프에서 가장 기본적인 산점도와
countplot을 그려본다.
(1) 산점도 그리기
- 산점도를 그릴 때는 수치형 vs 수치형 데이터를 그릴 때 표현한다.
# 패키지 불러오기
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
url = 'https://raw.githubusercontent.com/chloevan/datasets/master/books/eda_with_python/countries.csv'
countries = pd.read_csv(url)
/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
# 산점도 그리기
sns.scatterplot(x='GDP ($ per capita)', y='Phones (per 1000)', data = countries)
plt.show()
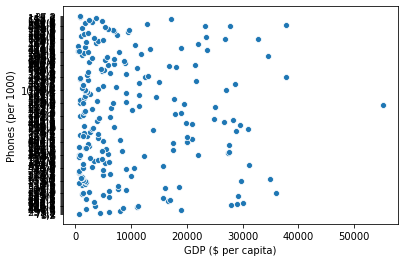
- 산점도를 볼 때, 데이터의 관계를 보도록 한다.
- 해석 요령,
X축으로 값이 커질수록Y값이 커지는지 작아지는지 확인해본다. - 산점도의 점이 어느 곳에 주로 몰려 있는지 확인해본다.
- 해석 요령,
(2) countplot 그래프
-
설문조사를 진행 후, 각 응답에 따른 비율을 구할 수 있다.
-
거미(
Spiders)를 싫어하는가에 대해 리커트 척도를 구한 것이다.1은 매우 동의 &5는 매우 비동의를 표한다.- 그에 따른 빈도그래프를
countplot으로 작성할 수 있다.
-
기본적으로 막대 그래프로 보여준다.
csv_filepath = 'https://raw.githubusercontent.com/chloevan/datasets/master/books/eda_with_python/surveys.csv'
surveys = pd.read_csv(csv_filepath)
sns.countplot(x = "Spiders", data = surveys)
plt.show()
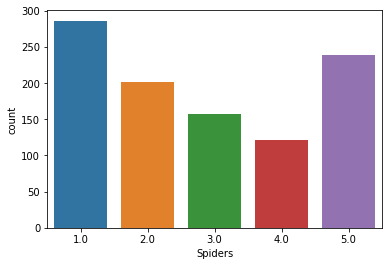
(3) 제 3의 변수 추가 - 산점도
- 시각화의 기본은 비교이다.
- 위 (1) & (2) 그래프의 단점은 1차원 또는 2차원적이다.
- 이 때 비교를 하기 위해서는 제 3의 변수를 추가해본다.
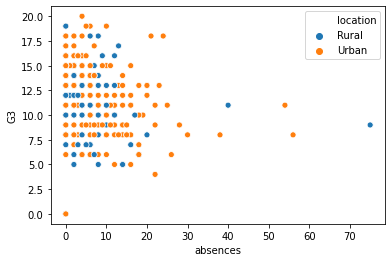
absences는 결석수를 의미하고,G3는 최종성적을 의미한다.- 이 때,
location변수를 추가하여 비교를 보다 쉽게 할 수 있도록 하였다.
url = 'https://raw.githubusercontent.com/chloevan/datasets/master/books/eda_with_python/students.csv'
students = pd.read_csv(url)
sns.scatterplot(x = "absences", y = "G3", data = students, hue = "location", hue_order = ['Rural', 'Urban'])
plt.show()
(4) 제 2의 변수 추가 - countplot
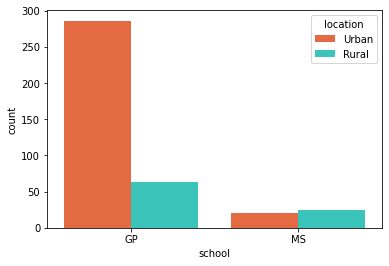
- 이번에는
countplot에location이라는 범수를 추가해본다. - 이 때,
location에 각 범주별로 색상을 추가한다.
sns.countplot(x = "school",
data = students,
hue = "location",
palette = {
"Rural": "#23DBCD",
"Urban": "#FF5C29"
})
plt.show()
그래프 서브그룹 추가
- 이번에는 그래프를 조금 더 분할해서 살펴본다.
- 우선
study_time의 범주의 개수는 4개이며, 이를col형태로 나타날 수 있다.col대신에row형태로 작성해본다.
sns.relplot(x="absences", y="G3",
data=students,
kind="scatter",
row="study_time")
plt.show()
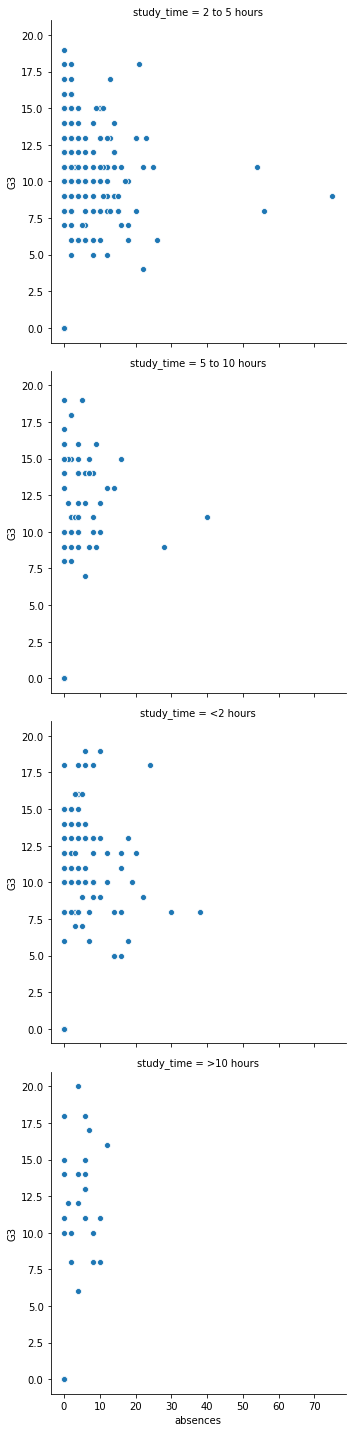
- 이번에는 하나의 변수를 더 추가해본다.
- 즉, 총 4개의 변수가 하나의 그래프안에서 표현된 것이다.
G1은 1학기의 성적을 의미한다.- 즉, 1학기의 성적과 최종성적의 상관관계를 표현하는 것이다.
- 이 때,
schoolsup은 학교에서 지원을 받은 사람,famsup은 가정에서 교육을 받은 사람 이렇게 범주화 해서 그 차이가 있는지를 확인하는 시각화가 된다.
- 여기에서도
그룹간의차이가 있는지를 확인하는 그래프다.
sns.relplot(x="G1", y="G3",
data=students,
kind="scatter",
col="schoolsup",
col_order=["yes", "no"],
row="famsup",
row_order=["yes", "no"])
# Show plot
plt.show()
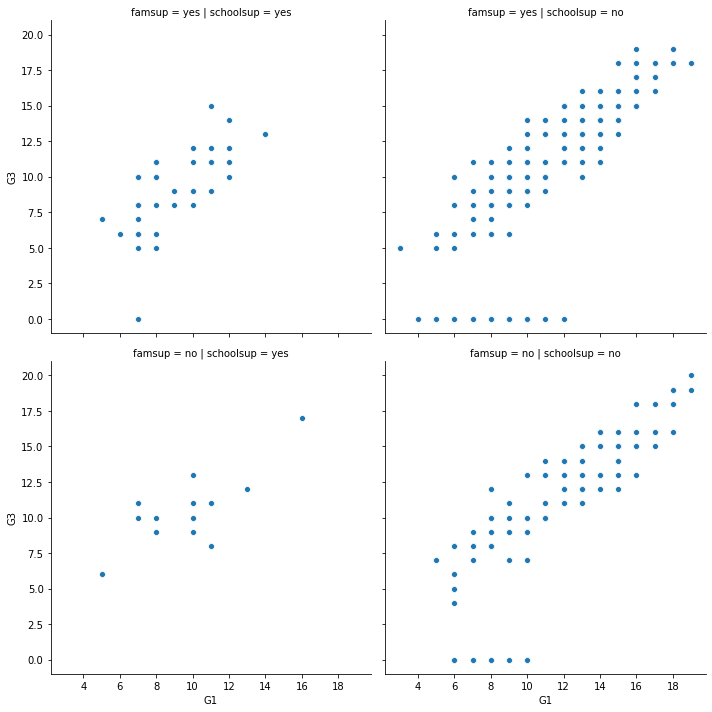
- 위 그래프는 어떻게 해석해야 할까?
박스플롯
- 박스플롯은 기본적으로 수치형 ~ 범주형 데이터의 조합이다.
- 이 때, 두가지를 확인해야 한다.
- 수치형 데이터의 이상치는 없는가?
- 각 범주간의 평균의 차이는 없는가?
# 시간의 순서대로 리스트 재 범주
study_time_order = ["<2 hours", "2 to 5 hours",
"5 to 10 hours", ">10 hours"]
sns.catplot(x = 'study_time',
y = 'G3',
data = students,
kind = 'box',
order = study_time_order)
# Show plot
plt.show()
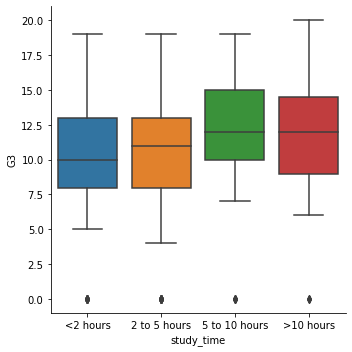
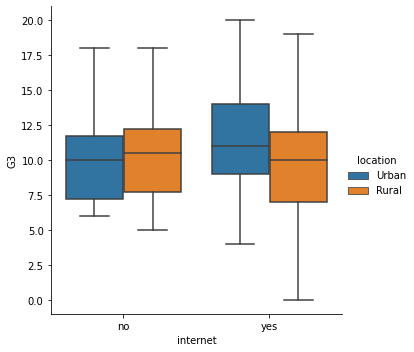
- 이번에는 이상치 데이터를 제거해본다.
- 또한, 하나의 변수(=
location)을 추가해서 나타내면 보다 더 의미를 부여할 수 있다.
sns.catplot(x="internet", y="G3",
data=students,
kind="box",
hue="location",
sym="")
# Show plot
plt.show()
- Seaborn Tutorial은 계속 올리도록 한다.
