Spark Installation on Windows 10
사전준비
- 스파크를 설치하는 과정은 소개 하려고 한다.
- 사전에 파이썬 3만 설치가 되어 있으면 된다.
- 만약, 파이썬이 처음이라면 Anaconda를 설치한다.
다운로드 전 필수 확인사항
- 스파크 설치 전에는 반드시 체크해야 하는 사항이 있다. (System Compatibility)
- 2022년 1월 기준은 아래와 같다.
Get Spark from the downloads page of the project website. This documentation is for Spark version 3.2.0. Spark uses Hadoop’s client libraries for HDFS and YARN. Downloads are pre-packaged for a handful of popular Hadoop versions. Users can also download a “Hadoop free” binary and run Spark with any Hadoop version by augmenting Spark’s classpath. Scala and Java users can include Spark in their projects using its Maven coordinates and Python users can install Spark from PyPI.
If you’d like to build Spark from source, visit Building Spark.
Spark runs on both Windows and UNIX-like systems (e.g. Linux, Mac OS), and it should run on any platform that runs a supported version of Java. This should include JVMs on x86_64 and ARM64. It’s easy to run locally on one machine — all you need is to have java installed on your system PATH, or the JAVA_HOME environment variable pointing to a Java installation.
Spark runs on Java 8/11, Scala 2.12, Python 3.6+ and R 3.5+. Python 3.6 support is deprecated as of Spark 3.2.0. Java 8 prior to version 8u201 support is deprecated as of Spark 3.2.0. For the Scala API, Spark 3.2.0 uses Scala 2.12. You will need to use a compatible Scala version (2.12.x).
For Python 3.9, Arrow optimization and pandas UDFs might not work due to the supported Python versions in Apache Arrow. Please refer to the latest Python Compatibility page. For Java 11, -Dio.netty.tryReflectionSetAccessible=true is required additionally for Apache Arrow library. This prevents java.lang.UnsupportedOperationException: sun.misc.Unsafe or java.nio.DirectByteBuffer.(long, int) not available when Apache Arrow uses Netty internally.
자바 설치
- 자바를 설치한다. 설치 파일은 아래에서 다운로드 받는다.
- 설치 시, 오라클 로그인이 필요 할 수도 있다.
Step 01. 설치
- 다운로드 파일을 관리자로 실행한다. 계속 Next 버튼 클릭 후, 아래 파일에서 경로를 수정한다. (이 때,
Program Files공백이 있는데, 이러한 공백은 환경 설치 시 문제가 될 수 있다.)
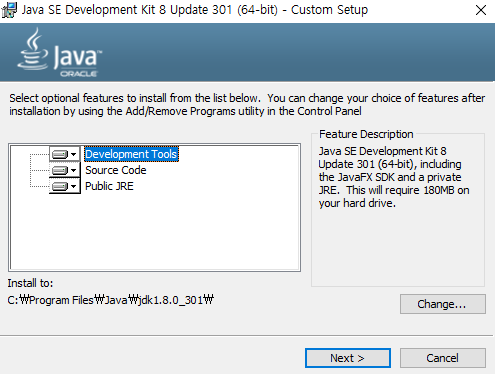
- 경로를 아래와 같이 변경한다.
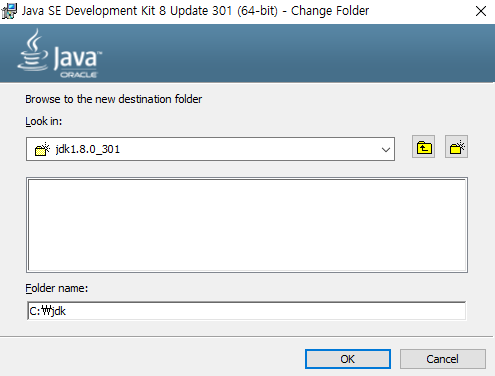
- 이번에는 자바 런타임 환경의 폴더도 동일하게 변경해준다. (변경 클릭 후 수정)
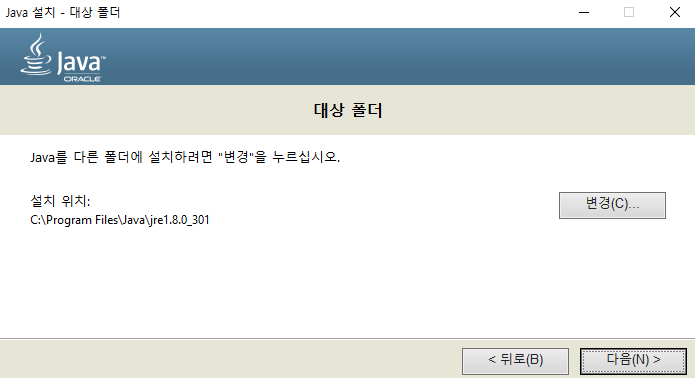
- C드라이브 바로 다음 경로에
jre폴더를 생성하고 저장한다.
Spark 설치
- 이번에는 Spark를 설치한다.
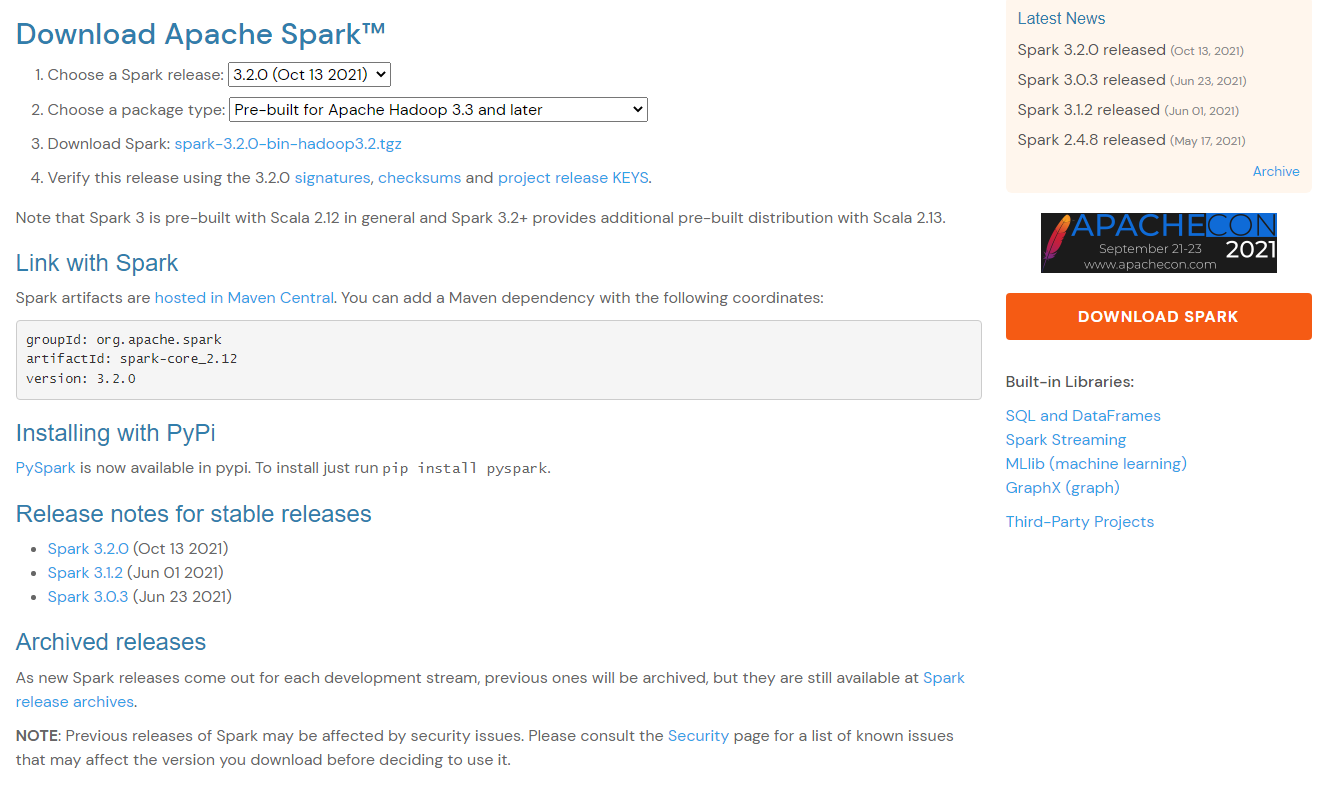
(1) 설치파일 다운로드
Download Spark: [spark-3.2.0-bin-hadoop3.2.tgz](https://www.apache.org/dyn/closer.lua/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz)를 클릭 한 후, 아래 화면에서HTTP 하단페이지를 클릭하면 다운로드를 받을 수 있다.- 설치 URL: https://www.apache.org/dyn/closer.lua/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz (2022년 1월 기준)
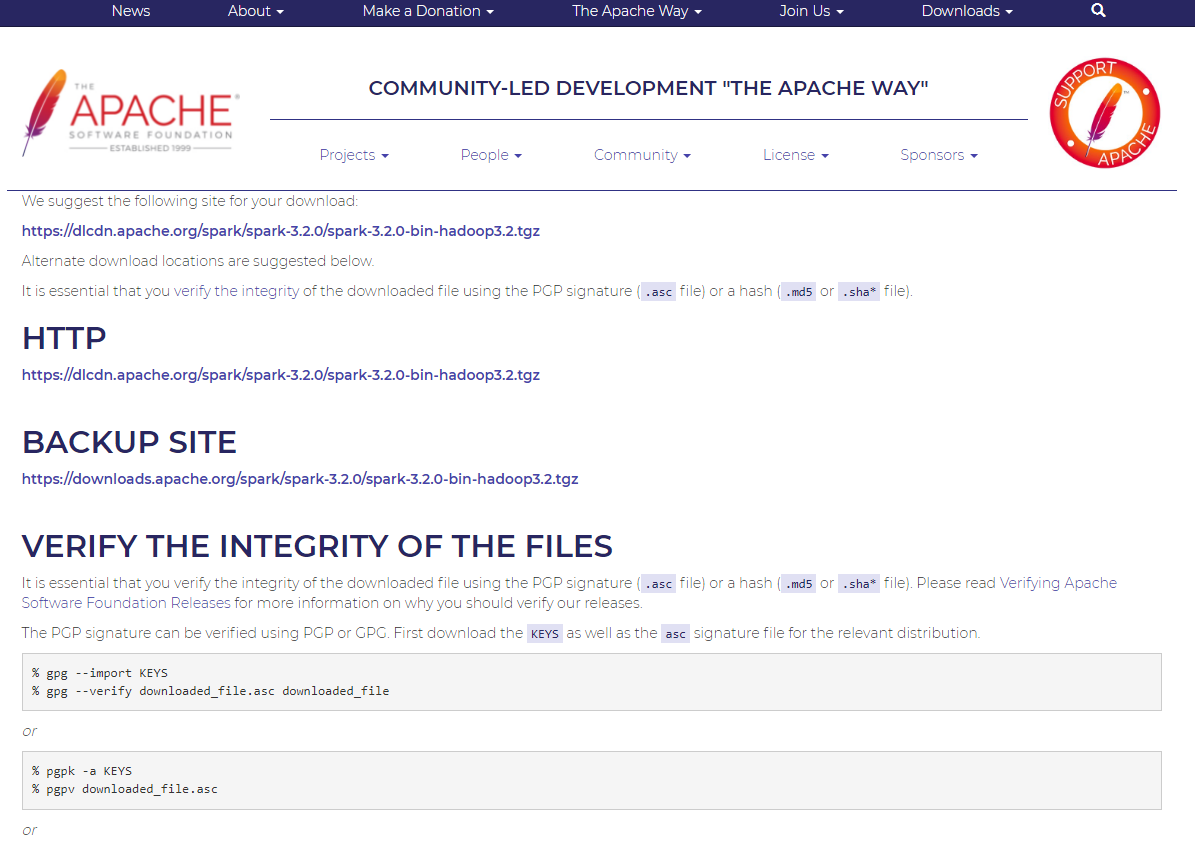
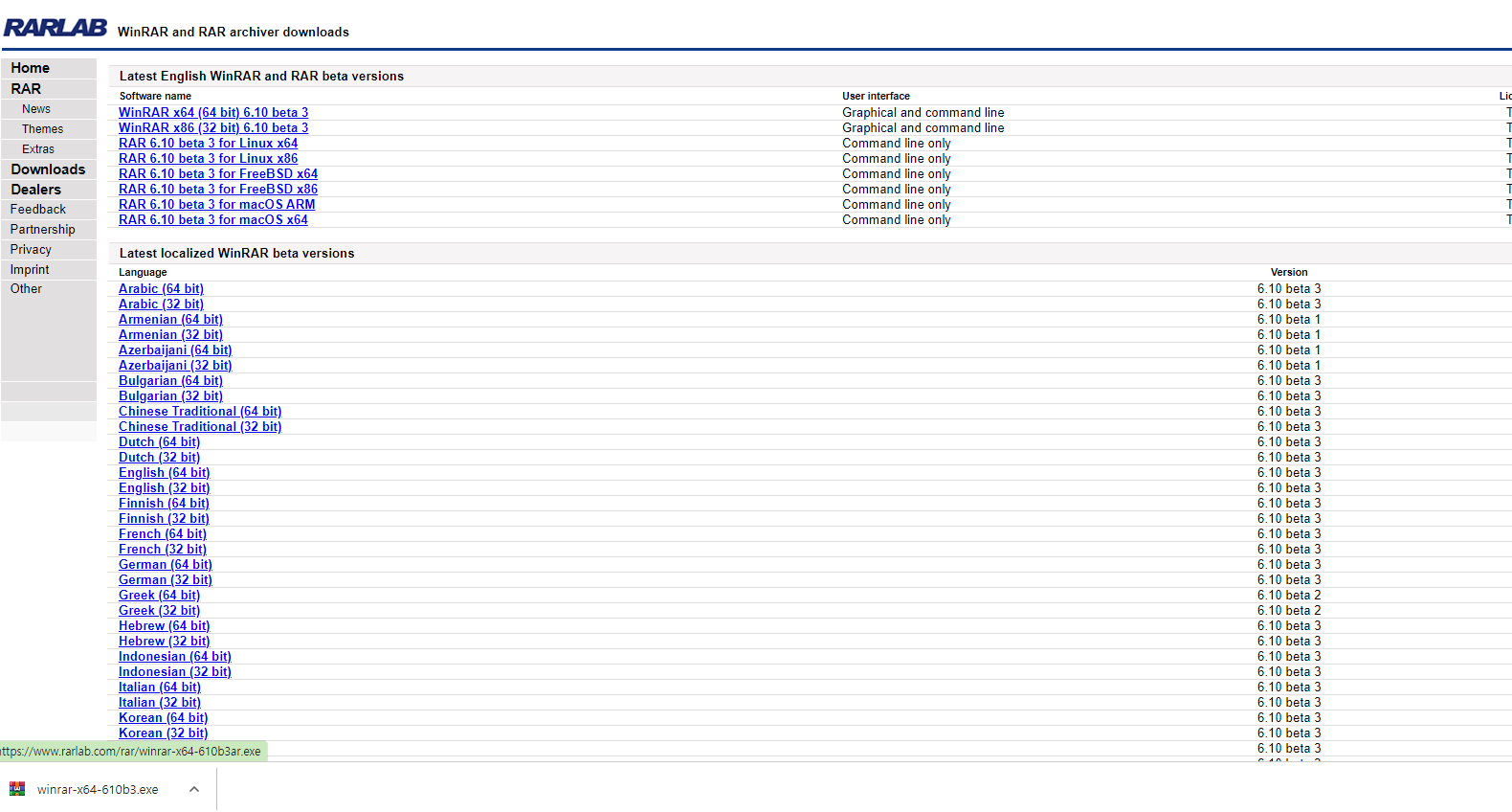
(2) WinRAR 프로그램 다운로드
- 이 때,
.tgz압축파일을 풀기 위해서는WinRAR을 설치한다.- 설치 파일: https://www.rarlab.com/download.htm
- 각 개인 컴퓨터에 맞는 것을 설치한다.
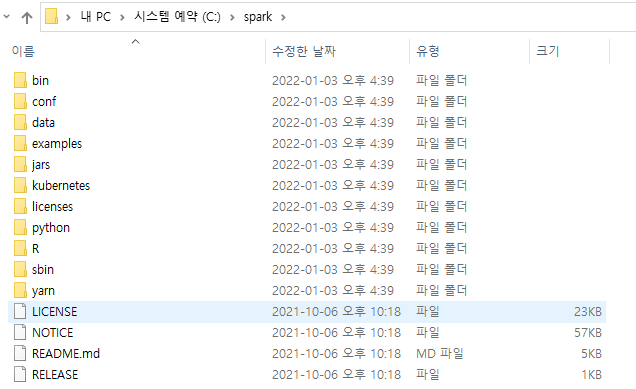
(3) spark 폴더 생성 및 파일 이동
- 파일 이동을 하도록 한다.
- spark-3.2.0-bin-hadoop3.2 폴더 내 모든 파일을 복사한다.
- 그 후, C드라이브 하단에 spark 폴더를 생성한 후, 모두 옮긴다.
(4) log4j.properties 파일 수정
conf-[log4j.properties](http://log4j.properties)파일을 연다.
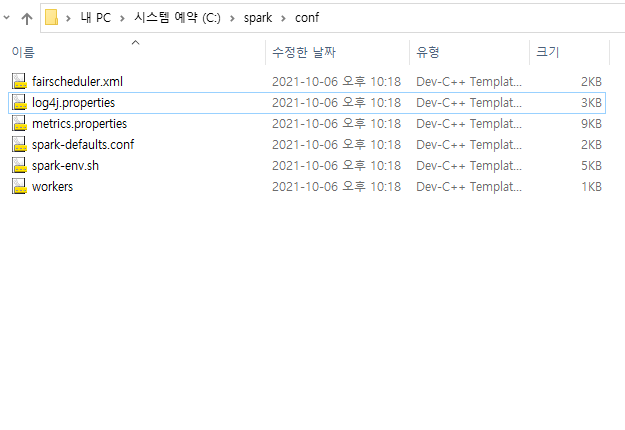
- 해당 파일을 메모장으로 연 후, 아래에서
INFO→ERROR로 변경한다.- 작업 실행 시, 출력하는 모든 logs 값들을 없앨 수 있다.
# Set everything to be logged to the console
# log4j.rootCategory=INFO, console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
winutils 설치
- 이번에는 스파크가 윈도우 로컬 컴퓨터가 Hadoop으로 착각하게 만들 프로그램이 필요하다.
- 설치파일: https://github.com/cdarlint/winutils
- 여기에서 각 설치 버전에 맞는 winutils를 다운로드 받는다.
- 필자는 3.2.0 버전을 다운로드 받았다.
- 설치파일: https://github.com/cdarlint/winutils
- C드라이브에서 winutils-bin 폴더를 차례로 생성한 후, 다운로드 받은 파일을 저장한다.
- 이 파일이 Spark 실행 시, 오류 없이 실행될 수 있도록 파일 사용 권한을 얻도록 한다.
- 이 때에는 CMD 관리자 권한으로 파일을 열어서 실행한다.
- 만약, ChangeFileModeByMask error (3) 에러 발생 시, C드라이브 하단에,
tmp\hive폴더를 차례대로 생성을 한다.
C:\Windows\system32>cd c:\winutils\bin
c:\winutils\bin> winutils.exe chmod 777 \tmp\hive
환경변수 설정
- 시스템 환경변수를 설정한다.
- 각 사용자 계정에
사용자 변수 - 새로 만들기 버튼을 클릭한다.
- 각 사용자 계정에
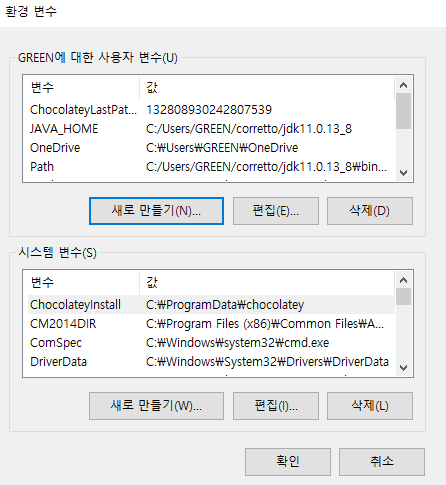
- SPARK_HOME 환경변수를 설정한다.
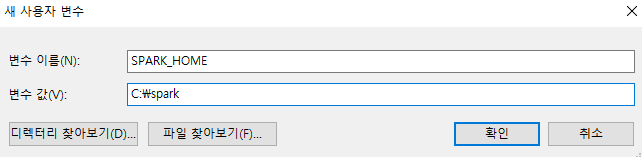
- JAVA_HOME 환경변수를 설정한다.
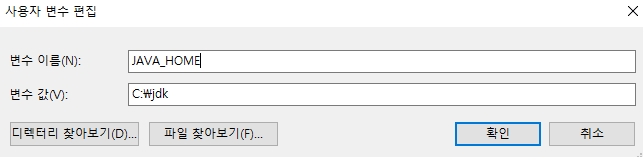
- HADOOP_HOME 환경변수를 설정한다.
-
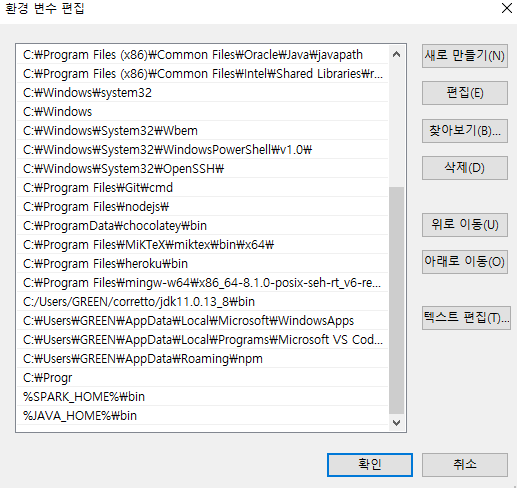
이번에는
PATH변수를 편집한다. 아래코드를 추가한다.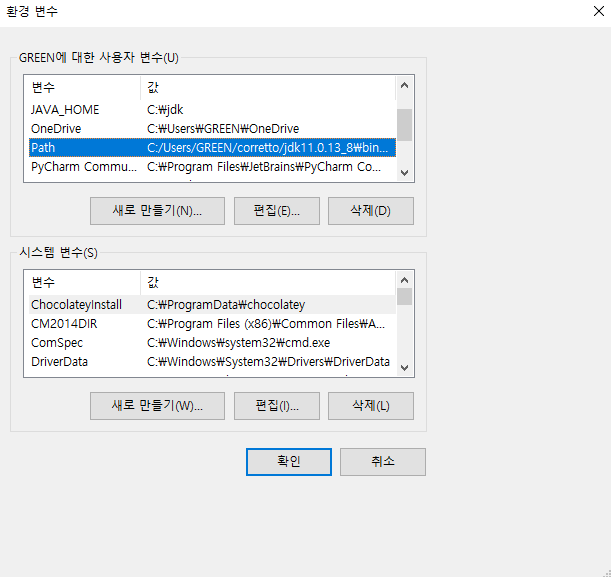
-
아래 코드를 추가한다.
- %SPARK_HOME%\bin
- %JAVA_HOME%\bin
파이썬 환경설정
- Python 환경설정을 추가한다.
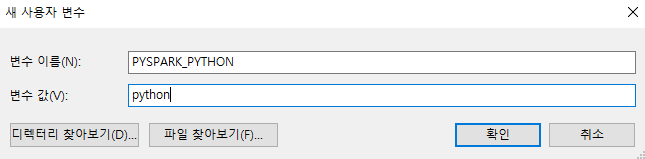
PYSPARK_DRIVER_PYTHON=jupyter
PYSPARK_DRIVER_PYTHON_OPTS=notebook
스파크 테스트
- CMD 파일을 열고
c:\spark폴더로 경로를 설정 한다.
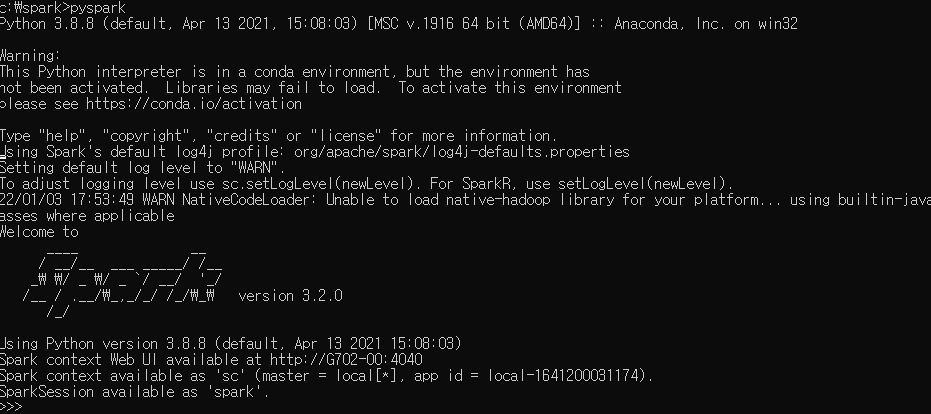
- 이번에는 해당
[README.md](http://README.md)파일을 불러와서 아래 코드가 실행되는지 확인한다.
>>> rd = sc.textFile("README.md")
>>> rd.count()
109
>>>
