Spark Installation on M1 Mac
Page content
사전준비
- M1 Mac에서 스파크를 설치하는 과정을 소개 하려고 한다.
- 필자의 Python 버전은 아래와 같다.
$ python --version
Python 3.8.7
자바 설치
- 자바 설치는 아래에서 다운로드 받았다.
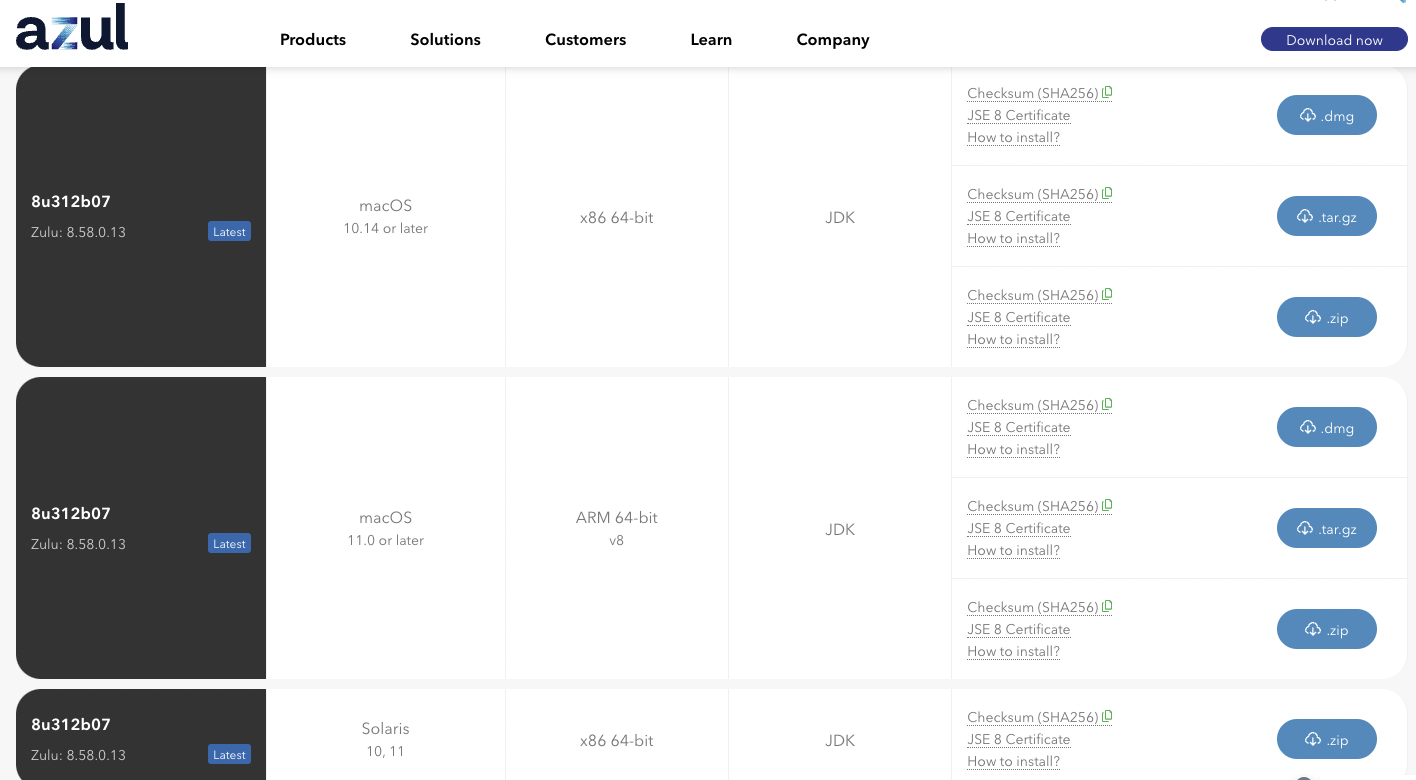
- 그 다음 자바 설치를 확정한다.
$ java --showversion
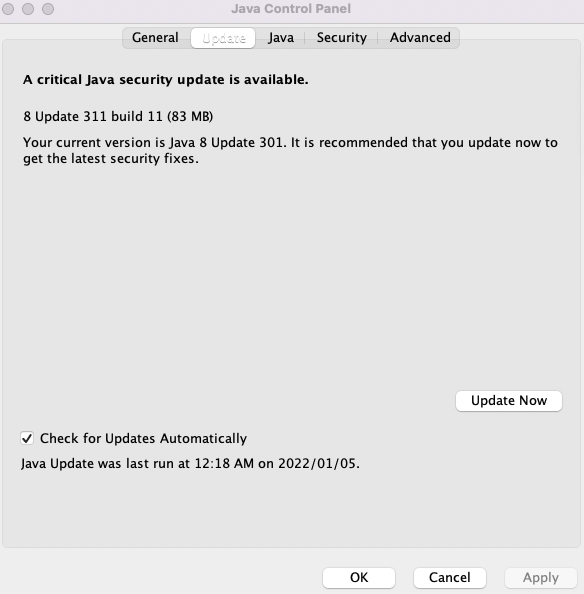
- 만약 에러가 아래와 같은 에러가 발생한다면, 시스템 환경설정 - Java - 업데이트 항목을 순차적으로 클릭한다.
$ java --showversion
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
Spark 설치
- Spark를 다운로드 받는다.
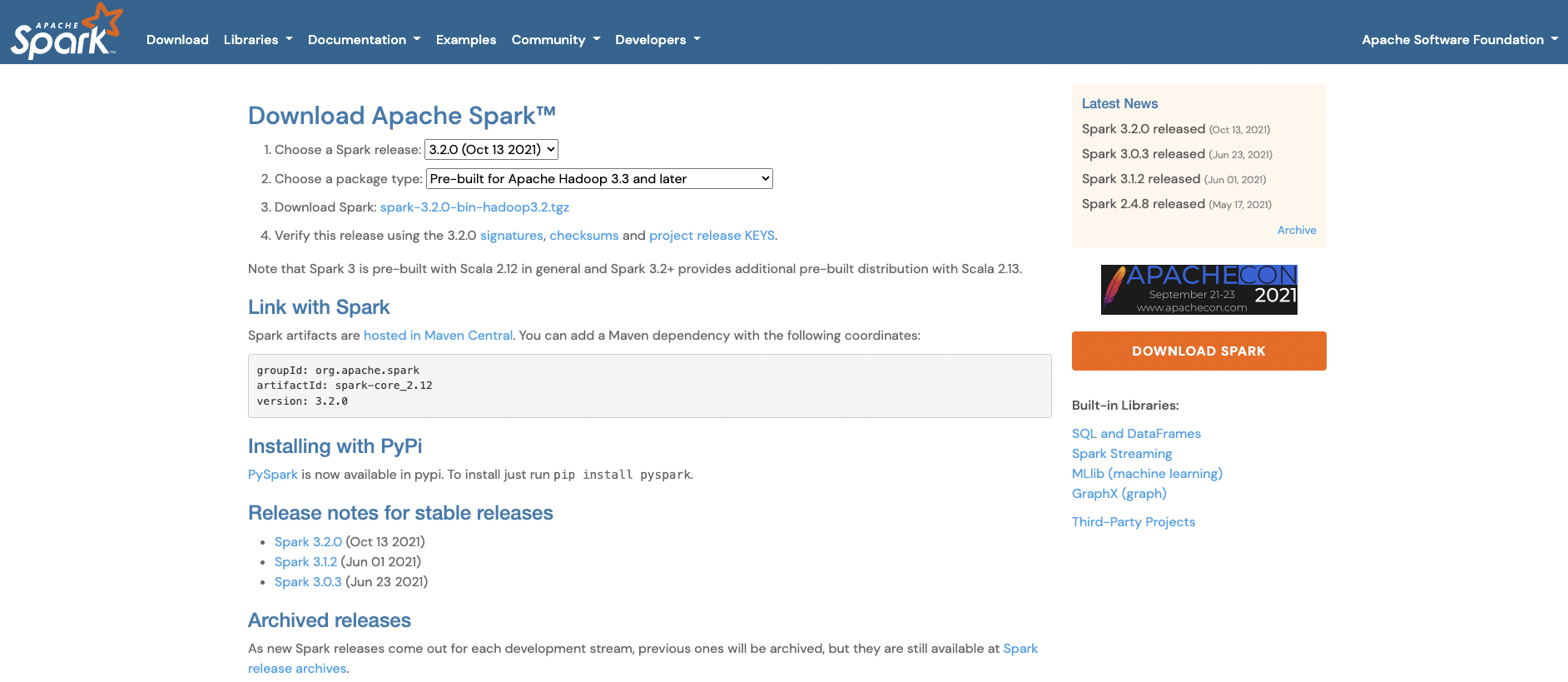
- Download Spark를 클릭하면 아래 페이지에서 HTTP 하단의
https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz파일을 클릭하여 다운로드 받는다. - 이 때 해당 파일의 경로를 Mac의 Root 디렉토리로 옮긴다.
$ cp spark-3.2.0-bin-hadoop3.2.tgz ~/
- 그리고 압축을 푼다.
$ tar -xzf spark-3.2.0-bin-hadoop3.2.tgz
환경변수 설정
- 환경 변수 설정 시 중요한 건 해당 파일을 찾는 것이다. 따라서, 미리 사전에 폴더를 확인하는 것이 좋다.
- 기타 다른 블로그를 활용하여 적용할 때도 마찬가지다.
- vi 에디터를 활용해서 파일을 열고 입력 한 후, 저장한다.
- 필자는 여러 이유로 3개의 자바를 활용 중이다.
JavaVirtualMachines yourname$ ls
jdk-11.0.1.jdk jdk1.8.0_301.jdk zulu-8.jdk
- 여기에서 필자는 M1 Java인 zulu-8.jdk를 환경변수로 설정할 것이다.
- 마찬가지로 spark 환경변수도 해당 파일을 잡는 것이 중요하다.
# export JAVA_HOME_11=$(/usr/libexec/java_home -v11)
export JAVA_HOME=/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home
export PATH=${PATH}:$JAVA_HOME/bin
## SPARK 버전 맞게 써주기
export SPARK_HOME=/spark/spark-3.2.0-bin-hadoop3.2
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_PYTHON=python3
파일 수정
- 필자는 PySpark 실행 전 몇몇 파일을 추가 수정했다.
spark/bin폴더 내부에 있는[load-spark-env.sh](http://load-spark-env.sh)파일을 열어 맨 마지막에 아래코드를 추가했다.
export SPARK_LOCAL_IP="127.0.0.1"
- spark-conf 폴더 내부에 있는
log4j.properties.template파일에서 아래와 같이 수정했다.
# Set everything to be logged to the console
# log4j.rootCategory=INFO, console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
테스트
- 이제 Terminal을 열고 PySpark를 실행한다. Spark 로고가 출력된다면 정상적으로 설치가 완료가 된 것이다.
$ pyspark
Python 3.8.7 (v3.8.7:6503f05dd5, Dec 21 2020, 12:45:15)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.2.0
/_/
Using Python version 3.8.7 (v3.8.7:6503f05dd5, Dec 21 2020 12:45:15)
Spark context Web UI available at http://localhost:4040
Spark context available as 'sc' (master = local[*], app id = local-1641389478631).
SparkSession available as 'spark'.
>>>
- 이번에는 rdd 파일을 열고 다음 코드를 테스트 해본다.
from pyspark import SparkContext
def main():
sc = SparkContext("local", "count app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
counts = words.count()
print("Number of elements in RDD -> %i" % (counts))
if __name__ == "__main__":
main()
- 이제 터미널에서 파일을 실행한다.
- 정상적으로 실행 되었다면, 설정은 끝났다고 보면 된다.
$ python3 pyspark-rdd.py
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Number of elements in RDD -> 8
