Pandas read_csv skiprows 활용
Page content
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

문제 개요
- Kaggle 데이터 New York City Taxi Fare Prediction 데이터를 구글 코랩에서 Loading 하는 중 메모리 문제가 발생함
- 계통추출(Systematic Sampling)을 통해 데이터를 불러오기로 함
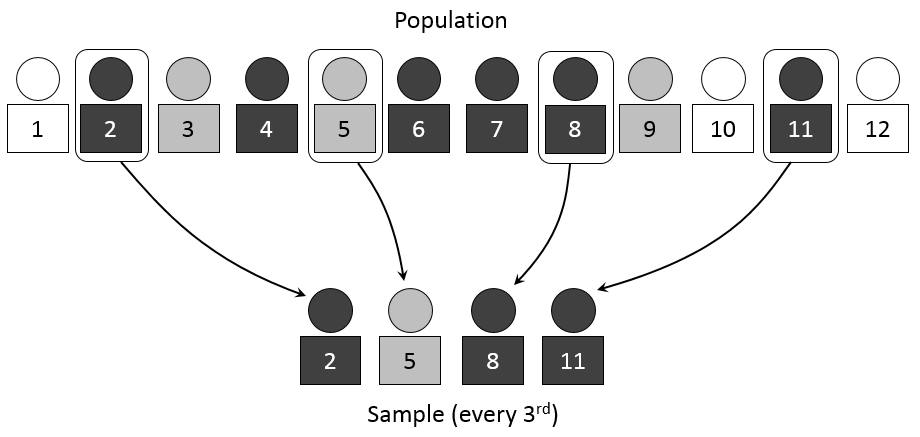
예제 실습
- 아래 예제를 통해서 실제로 데이터가 줄어드는지 확인을 해본다.
- 핵심 코드는
skip_logic함수이며,skiprows = skiprows=lambda x: skip_logic(x, 3)형태로 작성할 수 있다. - IRIS 데이터는 https://www.kaggle.com/saurabh00007/iriscsv 에서 다운로드 받았다.
- iris 데이터외에도 각자 데이터를 가지고 실습을 해도 좋다.
import pandas as pd
def skip_logic(index, skip_num):
if index % skip_num == 0:
return False
return True
def main():
print('**** skiprows 기본 옵션 ****')
iris = pd.read_csv('iris.csv')
print(iris.shape)
print('**** skiprows 인덱스 0, 2, 5만 제외 ****')
iris = pd.read_csv('iris.csv', skiprows=[0, 2, 5])
print(iris.shape)
print('**** skiprows 인덱스 range(3, 20)만 제외 ****')
iris = pd.read_csv('iris.csv', skiprows=[i for i in range(3, 20)])
print(iris.shape)
print('**** skiprows 입력값의 배수에 해당하는 값만 Load ****')
iris = pd.read_csv('iris.csv', skiprows=lambda x: skip_logic(x, 3))
print(iris.shape)
if __name__ == '__main__':
main()
**** skiprows 기본 옵션 ****
(150, 6)
**** skiprows 인덱스 0, 2, 5만 제외 ****
(147, 6)
**** skiprows 인덱스 range(3, 20)만 제외 ****
(133, 6)
**** skiprows 입력값의 배수에 해당하는 값만 Load ****
(50, 6)
실전 적용
- 이제 배운 것을 적용해보자.
데이터 크기
- train.csv 데이터의 크기를 확인해보자.
import os
def convert_bytes(file_path, unit=None):
size = os.path.getsize(file_path)
if unit == "KB":
return print('File size: ' + str(round(size / 1024, 3)) + ' Kilobytes')
elif unit == "MB":
return print('File size: ' + str(round(size / (1024 * 1024), 3)) + ' Megabytes')
elif unit == "GB":
return print('File size: ' + str(round(size / (1024 * 1024 * 1024), 3)) + ' Gigabytes')
else:
return print('File size: ' + str(size) + ' bytes')
file_list = ['train.csv', 'test.csv', 'sample_submission.csv']
for file in file_list:
print("The {file} size: ".format(file=file))
convert_bytes(file)
convert_bytes(file, 'KB')
convert_bytes(file, 'MB')
convert_bytes(file, 'GB')
print("--" * 5)
The train.csv size:
File size: 5697178298 bytes
File size: 5563650.682 Kilobytes
File size: 5433.253 Megabytes
File size: 5.306 Gigabytes
----------
The test.csv size:
File size: 983020 bytes
File size: 959.98 Kilobytes
File size: 0.937 Megabytes
File size: 0.001 Gigabytes
----------
The sample_submission.csv size:
File size: 343271 bytes
File size: 335.226 Kilobytes
File size: 0.327 Megabytes
File size: 0.0 Gigabytes
----------
실전 적용
- 이제 실전 적용을 해본다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
def skip_logic(index, skip_num):
if index % skip_num == 0:
return False
return True
train = pd.read_csv('./train.csv', skiprows=lambda x: skip_logic(x, 4))
print(train.shape)
test = pd.read_csv('./test.csv')
submission = pd.read_csv('./sample_submission.csv')
(13855964, 8)
결론
- 대용량 데이터를 다루는 것은 쉽지 않지만,
skiprows파라미터를 적절히 활용하여 메모리 이슈를 피하자.
