Python - Pandas 병렬처리
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

![]()
공지
제 수업을 듣는 사람들이 계속적으로 실습할 수 있도록 강의 파일을 만들었습니다. 늘 도움이 되기를 바라며. 참고했던 교재 및 Reference는 꼭 확인하셔서 교재 구매 또는 관련 Reference를 확인하시기를 바랍니다.
지난 포스트에서는 lambda의 기본적인 개념에 대해서 익혔다면, 이제 본격적인 데이터 전처리와 관련된 예제를 올리려고 한다.
II. 가상의 데이터셋 만들기
- 25M 행과 5개의 열로 구성된 가상의 숫자 데이터 프레임을 만들어보자.
import pandas as pd
import numpy as np
from tabulate import tabulate
pd_temp = pd.DataFrame(np.random.randint(0, 100, size = (25000000, 5)), columns=list('abcde'))
print(tabulate(pd_temp.head(), tablefmt="pipe", headers="keys"))
| a | b | c | d | e | |
|---|---|---|---|---|---|
| 0 | 44 | 28 | 1 | 17 | 36 |
| 1 | 35 | 93 | 1 | 31 | 45 |
| 2 | 17 | 97 | 56 | 89 | 51 |
| 3 | 53 | 3 | 92 | 35 | 2 |
| 4 | 17 | 87 | 45 | 59 | 95 |
III. 성능 테스트
- 새로운 컬럼(
f)을 만드는데, if condition을 적용해서 실험을 해본다. 우선 새로운 컬럼을 만드는 함수는 아래와 같이 작성해보자.
def add_col_fun(a,b):
if a > 50:
return True
elif b > 75:
return True
else:
return False
(1) apply + lambda
보통 pandas를 활용하면 apply + lambda 사용을 권장한다. 이 때 성능 테스트를 위해 %%time을 활용해보자.
# dataframe 복사
defaul_temp = pd_temp
swfiter_temp = pd_temp
swifter_npartitions_temp = pd_temp
%%time
defaul_temp['f'] = defaul_temp.apply(lambda x: add_col_fun(x['a'], x['b']), axis=1)
print(tabulate(defaul_temp.head(), tablefmt="pipe", headers="keys"))
CPU times: user 12min 3s, sys: 236 ms, total: 12min 3s Wall time: 12min 4s
- 간단하게
2개의 column을 활용하여column1개를 추가 하는데도 약 12분 가까이 걸리는 걸 확인할 수 있다. (솔직히 넘 느리다) - 그러면 어떻게 수정해야 할까?
IV. Introduction to Swifter
먼저 swifter의 공식 문서를 확인해보자. 필자는 패키지를 볼 때마다, 정의 또는 개발 목적을 먼저 확인하는 편이다. 그러면 나머지 필요한 함수는 그 때마다 찾아서 쓰면 된다.
swifter공식 문서: https://pypi.org/project/swifter/
페이지를 방문하면 패키지의 간단한 정의를 확인할 수 있다.
A package which efficiently applies any function to a pandas dataframe or series in the fastest available manner
즉, 위 패키지는 판다스의 dataframe 또는 series를 빠르게 사용할 수 있도록 도와주는 일종의 helper패키지 처럼 보인다.
어떻게 사용할까?
pip install swifter
(1) Application to Swifter
- 이번에는 default
swifter를 사용하여fcolumn을 추가해보자.
%%time
import swifter
swfiter_temp['f'] = swfiter_temp.swifter.apply(lambda x: add_col_fun(x['a'], x['b']), axis=1)
print(tabulate(swfiter_temp.head(), tablefmt="pipe", headers="keys"))
CPU times: user 5.4 s, sys: 6.77 s, total: 12.2 s Wall time: 9min 4s
(2) set_npartitions 적용
-
그런데, 병렬처리는 보통 코어를 할당해주어야 한다.
swifter패키지에는 이러한 코어를 할당해줄 수 있는 함수(set_npartitions())가 존재한다. -
계산방식은 아래와 같다.
$CPUcount \times hyperthreading \times 2$
- 만약 내 컴퓨터의 CPU가 6개이고, hyperthreading이 2개라면 npartitions=24개가 된다.
- CPU를 2개만 사용한다면
npartitions(8)만 추가하면 된다. - 코드는 아래와 같이 작성할 수 있다.
# core 개수 확인
import multiprocessing
multiprocessing.cpu_count()
2
- 구글 코랩에서 구동중이었는데, CPU가 2개였다!
%%time
import swifter
swifter_npartitions_temp['f'] = swifter_npartitions_temp.swifter.set_npartitions(8).apply(lambda x: add_col_fun(x['a'], x['b']), axis=1)
print(tabulate(swifter_npartitions_temp.head(), tablefmt="pipe", headers="keys"))
CPU times: user 4.16 s, sys: 4.89 s, total: 9.05 s Wall time: 8min 36s
swifter에npartitions(8)에 설정할 때, 속도가 약 30-40% 향상 된 것으로 확인된다. 만약CPU개수를 추가하면 추가할 수록 연산 속도가 더 빨라질 것으로 기대할 수 있다.- 간단한 함수 적용으로 연산처리 속도가 향상됨을 볼 수 있다.
- 실제
github페이지에 가면pandas applyVs.Dask applyVs.VectorizedVs.swift apply에 관한 비교 코드가 있으니 실제로 비교해보는 것을 추천한다.- swifter github 문서: https://github.com/jmcarpenter2/swifter
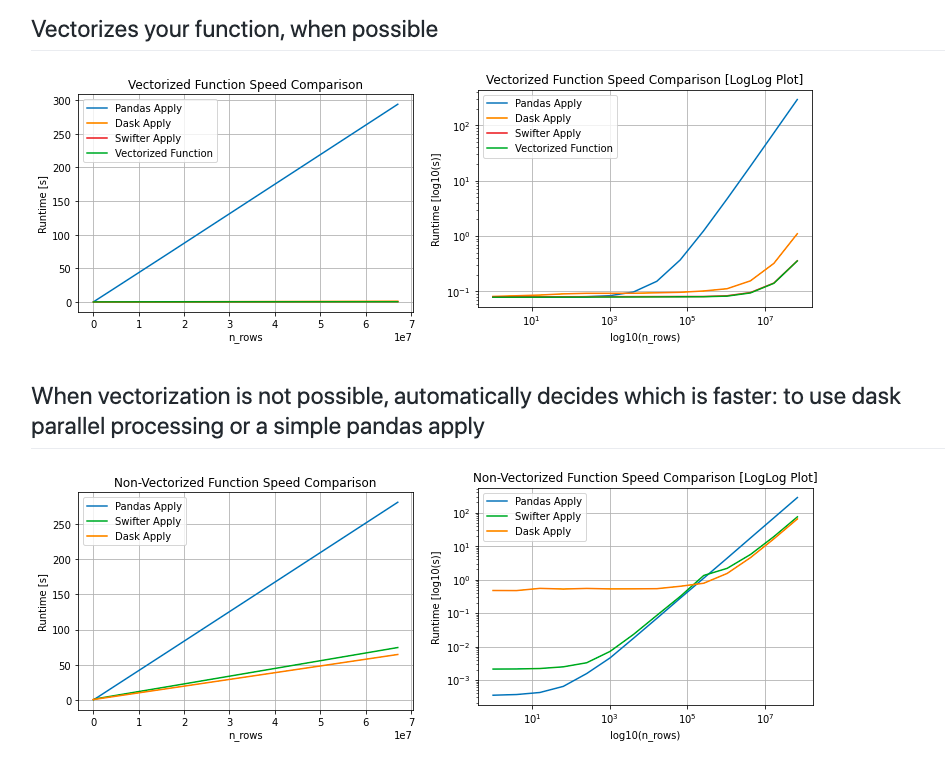
V. 결론
- pandas dataframe을 활용 할 때, 보통
apply + lambda를 활용하는 것은 거의 정규화 되고 있다. 이유는lambda를 사용하는 것이 훨씬 간편하기 때문에 그렇다. - 문제는 속도다. 속도가 느리기 때문에 다른 대체제를 활용하는 경우가 종종 있다. (예:
dask,pyspark등) - 각각의
package를 알고 있다면 도움이 되지만, 문제는 각 패키지에 맞는 문법을 익혀야 하는 것은 부담일 수 있다. - 그러나, 간단하게
swifter패키지를 활용하면 간단한 단어 추가로도 성능을 개선하는데 도움을 줄 수 있다는 것에 주목할 필요가 있다. - 또한, cpu 갯수에 맞게 할당을 해주면 더 좋은 속도 개선을 이룰 수 있음을 확인할 수 있었다.
It’s your turn. Learn by doing.
VI. Reference
jmcarpenter2. swifter. Retrieved from https://github.com/jmcarpenter2/swifter
