정형데이터와 함께하는 텍스트 마이닝
Page content
공지
- 해당 포스트는 취업 준비반 대상 강의 교재로 파이썬 머신러닝 완벽가이드를 축약한 내용입니다.
- 매우 좋은 책이니 가급적 구매하시기를 바랍니다.
개요
Mercari Price Suggestion Challenge는 캐글에서 진행된 과제이며, 제공되는 데이터 세트는 제품에 대한 여러 속성 및 제품 설명 등의 텍스트 데이터로 구성된다.- 데이터 세트는 다음 링크에서 확인한다. https://www.kaggle.com/c/mercari-price-suggestion-challenge/data
데이터 다운로드
- 데이터를 다운로드 받도록 한다.
!pip install kaggle
!sudo apt install p7zip p7zip-full # 7z 파일을 풀기 위한 것이다.
Requirement already satisfied: kaggle in /usr/local/lib/python3.6/dist-packages (1.5.10)
Requirement already satisfied: python-dateutil in /usr/local/lib/python3.6/dist-packages (from kaggle) (2.8.1)
Requirement already satisfied: python-slugify in /usr/local/lib/python3.6/dist-packages (from kaggle) (4.0.1)
Requirement already satisfied: certifi in /usr/local/lib/python3.6/dist-packages (from kaggle) (2020.12.5)
Requirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from kaggle) (2.23.0)
Requirement already satisfied: urllib3 in /usr/local/lib/python3.6/dist-packages (from kaggle) (1.24.3)
Requirement already satisfied: tqdm in /usr/local/lib/python3.6/dist-packages (from kaggle) (4.41.1)
Requirement already satisfied: six>=1.10 in /usr/local/lib/python3.6/dist-packages (from kaggle) (1.15.0)
Requirement already satisfied: text-unidecode>=1.3 in /usr/local/lib/python3.6/dist-packages (from python-slugify->kaggle) (1.3)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->kaggle) (3.0.4)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->kaggle) (2.10)
Reading package lists... Done
Building dependency tree
Reading state information... Done
p7zip is already the newest version (16.02+dfsg-6).
p7zip set to manually installed.
p7zip-full is already the newest version (16.02+dfsg-6).
0 upgraded, 0 newly installed, 0 to remove and 14 not upgraded.
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
# kaggle.json을 아래 폴더로 옮긴 뒤, file을 사용할 수 있도록 권한을 부여한다.
!mkdir -p ~/.kaggle/ && mv kaggle.json ~/.kaggle/ && chmod 600 ~/.kaggle/kaggle.json
Upload widget is only available when the cell has been executed in the current browser session. Please rerun this cell to enable.
Saving kaggle.json to kaggle.json
uploaded file "kaggle.json" with length 64 bytes
!kaggle competitions download -c mercari-price-suggestion-challenge
Warning: Looks like you're using an outdated API Version, please consider updating (server 1.5.10 / client 1.5.4)
Downloading sample_submission.csv.7z to /content
0% 0.00/170k [00:00<?, ?B/s]
100% 170k/170k [00:00<00:00, 63.4MB/s]
Downloading train.tsv.7z to /content
100% 74.0M/74.3M [00:00<00:00, 137MB/s]
100% 74.3M/74.3M [00:00<00:00, 214MB/s]
Downloading sample_submission_stg2.csv.zip to /content
0% 0.00/7.77M [00:00<?, ?B/s]
100% 7.77M/7.77M [00:00<00:00, 124MB/s]
Downloading test.tsv.7z to /content
56% 19.0M/34.0M [00:00<00:00, 195MB/s]
100% 34.0M/34.0M [00:00<00:00, 217MB/s]
Downloading test_stg2.tsv.zip to /content
99% 292M/294M [00:01<00:00, 236MB/s]
100% 294M/294M [00:01<00:00, 215MB/s]
- 여러
zip파일이 있기 때문에for-loop를 활용하여 제공한다.
!ls
sample_data sample_submission_stg2.csv.zip test.tsv.7z
sample_submission.csv.7z test_stg2.tsv.zip train.tsv.7z
!for z in *.zip; do unzip $z; done
Archive: sample_submission_stg2.csv.zip
inflating: sample_submission_stg2.csv
Archive: test_stg2.tsv.zip
inflating: test_stg2.tsv
7z압축 파일을 풀기 위해 프로그램을 설치 받는다.
!for z in *.7z; do 7zr x $z; done
7-Zip (a) [64] 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,64 bits,2 CPUs Intel(R) Xeon(R) CPU @ 2.20GHz (406F0),ASM,AES-NI)
Scanning the drive for archives:
0M Sca 1 file, 174228 bytes (171 KiB)
Extracting archive: sample_submission.csv.7z
--
Path = sample_submission.csv.7z
Type = 7z
Physical Size = 174228
Headers Size = 143
Method = LZMA:12m
Solid = -
Blocks = 1
Everything is Ok
Size: 9595930
Compressed: 174228
7-Zip (a) [64] 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,64 bits,2 CPUs Intel(R) Xeon(R) CPU @ 2.20GHz (406F0),ASM,AES-NI)
Scanning the drive for archives:
0M Sca 1 file, 35617013 bytes (34 MiB)
Extracting archive: test.tsv.7z
--
Path = test.tsv.7z
Type = 7z
Physical Size = 35617013
Headers Size = 122
Method = LZMA2:24
Solid = -
Blocks = 1
8% - test.ts 17% - test.ts 27% - test.ts 38% - test.ts 46% - test.ts 54% - test.ts 62% - test.ts 73% - test.ts 82% - test.ts 91% - test.ts 100% Everything is Ok
Size: 154222160
Compressed: 35617013
7-Zip (a) [64] 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,64 bits,2 CPUs Intel(R) Xeon(R) CPU @ 2.20GHz (406F0),ASM,AES-NI)
Scanning the drive for archives:
0M Sca 1 file, 77912192 bytes (75 MiB)
Extracting archive: train.tsv.7z
--
Path = train.tsv.7z
Type = 7z
Physical Size = 77912192
Headers Size = 122
Method = LZMA2:24
Solid = -
Blocks = 1
3% - train.t 7% - train.t 12% - train.t 17% - train.t 21% - train.t 25% - train.t 29% - train.t 33% - train.t 37% - train.t 40% - train.t 45% - train.t 49% - train.t 53% - train.t 57% - train.t 61% - train.t 65% - train.t 69% - train.t 73% - train.t 78% - train.t 81% - train.t 85% - train.t 89% - train.t 94% - train.t 98% - train.t Everything is Ok
Size: 337809843
Compressed: 77912192
!ls
sample_data sample_submission_stg2.csv.zip test.tsv.7z
sample_submission.csv test_stg2.tsv train.tsv
sample_submission.csv.7z test_stg2.tsv.zip train.tsv.7z
sample_submission_stg2.csv test.tsv
데이터 변수에 대한 개요
-
제공되는 데이터 세트의 속성은 다음과 같다.
train_id: 데이터 idname: 제품명item_condition_id: 판매자가 제공하는 제품의 상태category_name: 카데고리 명brand_name: 브랜드 이름price: 제품 가격, 예측을 위한 타깃 속성shipping: 배송비 무료 여부, 1이면 무료(판매자가 지불), 0이면 유료(구매자 지불)item_description: 제품에 대한 설명
-
이들 중
price가 예측해야 할 타깃 값을 의미한다. -
이 데이터셋이 어려운 이유는
item_description, 즉 텍스트 데이터를 활용해야 하는 부분이기 때문에, 매우 유용한 튜토리얼이 될수가 있다.
데이터 전처리
- 데이터 전처리에
mercari_train.tsv데이터를DataFrame으로 로딩한 후 데이터를 살펴본다.
from sklearn.linear_model import Ridge, LogisticRegression
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import pandas as pd
mercari_df = pd.read_csv('train.tsv', sep='\t')
print(mercari_df.shape)
mercari_df.head(10)
(1482535, 8)
| train_id | name | item_condition_id | category_name | brand_name | price | shipping | item_description | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | MLB Cincinnati Reds T Shirt Size XL | 3 | Men/Tops/T-shirts | NaN | 10.0 | 1 | No description yet |
| 1 | 1 | Razer BlackWidow Chroma Keyboard | 3 | Electronics/Computers & Tablets/Components & P... | Razer | 52.0 | 0 | This keyboard is in great condition and works ... |
| 2 | 2 | AVA-VIV Blouse | 1 | Women/Tops & Blouses/Blouse | Target | 10.0 | 1 | Adorable top with a hint of lace and a key hol... |
| 3 | 3 | Leather Horse Statues | 1 | Home/Home Décor/Home Décor Accents | NaN | 35.0 | 1 | New with tags. Leather horses. Retail for [rm]... |
| 4 | 4 | 24K GOLD plated rose | 1 | Women/Jewelry/Necklaces | NaN | 44.0 | 0 | Complete with certificate of authenticity |
| 5 | 5 | Bundled items requested for Ruie | 3 | Women/Other/Other | NaN | 59.0 | 0 | Banana republic bottoms, Candies skirt with ma... |
| 6 | 6 | Acacia pacific tides santorini top | 3 | Women/Swimwear/Two-Piece | Acacia Swimwear | 64.0 | 0 | Size small but straps slightly shortened to fi... |
| 7 | 7 | Girls cheer and tumbling bundle of 7 | 3 | Sports & Outdoors/Apparel/Girls | Soffe | 6.0 | 1 | You get three pairs of Sophie cheer shorts siz... |
| 8 | 8 | Girls Nike Pro shorts | 3 | Sports & Outdoors/Apparel/Girls | Nike | 19.0 | 0 | Girls Size small Plus green. Three shorts total. |
| 9 | 9 | Porcelain clown doll checker pants VTG | 3 | Vintage & Collectibles/Collectibles/Doll | NaN | 8.0 | 0 | I realized his pants are on backwards after th... |
- 총
1482535개의 레코드를 가지고 있는 데이터 세트이며, 다음으로 피처의 타입과Null여부를 확인한다.
print(mercari_df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1482535 entries, 0 to 1482534
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 train_id 1482535 non-null int64
1 name 1482535 non-null object
2 item_condition_id 1482535 non-null int64
3 category_name 1476208 non-null object
4 brand_name 849853 non-null object
5 price 1482535 non-null float64
6 shipping 1482535 non-null int64
7 item_description 1482531 non-null object
dtypes: float64(1), int64(3), object(4)
memory usage: 90.5+ MB
None
brand_name칼럼의 경우 매우 많은Null값을 가지고 있는 것을 확인 할 수 있다.brand_name은 가격에 영향을 미치는 중요 요인으로 판단될 수 있기 때문에 많은 데이터가Null로 되어 있으며 별도로 처리할 필요가 있다.- 그 외에도
category_name은 약6,300개의 결측치가 존재하지만, 비율적으로 미미한 편이다. item_description의Null값 역시 4건으로 미비하다.
수치형 데이터의 로그변환
Target값인price칼럼의 데이터 분포도를 살펴본다. 회귀에서Target값의 정규 분포도는 매우 중요하며, 왜곡되어 있을 경우 보통 로그를 씌워 변환한다.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
y_train_df = mercari_df['price']
plt.figure(figsize=(6, 4))
sns.distplot(y_train_df, kde = False)
/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
<matplotlib.axes._subplots.AxesSubplot at 0x7f0a6361feb8>
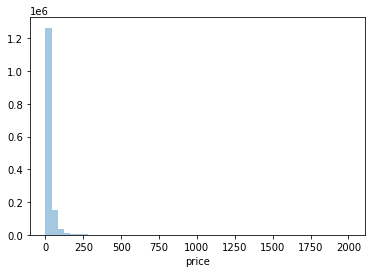
price값이 비교적 적은 가격을 가진 데이터 값에 왜곡돼 분포돼 있다. 이를 로그값으로 변환한 뒤 분포도를 다시 살펴보도록 한다.
import numpy as np
y_train_df = np.log1p(y_train_df)
sns.displot(y_train_df, kde=False)
<seaborn.axisgrid.FacetGrid at 0x7f0a62d9bd30>
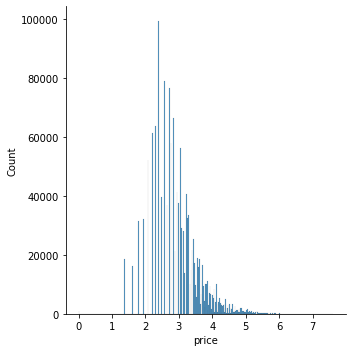
- 로그 값으로 변환한 뒤에는
price값이 비교적 정규 분포에 가까운 데이터를 이루게 되는 것을 확인했다.
mercari_df['price'] = np.log1p(mercari_df['price'])
mercari_df['price'].head(3)
0 1.223156
1 1.603479
2 1.223156
Name: price, dtype: float64
범주형 데이터
shipping의 값도 확인한다.
mercari_df['shipping'].value_counts()
0 819435
1 663100
Name: shipping, dtype: int64
item_condition_id의 값도 확인한다.- 1, 2, 3 값이 주를 이루고 있음을 확인할 수 있다.
mercari_df['item_condition_id'].value_counts()
1 640549
3 432161
2 375479
4 31962
5 2384
Name: item_condition_id, dtype: int64
item_description칼럼도 확인한다.
mercari_df['item_description'].head()
0 No description yet
1 This keyboard is in great condition and works ...
2 Adorable top with a hint of lace and a key hol...
3 New with tags. Leather horses. Retail for [rm]...
4 Complete with certificate of authenticity
Name: item_description, dtype: object
no_describe = mercari_df['item_description'] == 'No description yet'
mercari_df[no_describe]['item_description'].count()
82489
No description의 경우 상당히 많은 결측치가 존재하는 것을 확인할 수 있었다.- 의미 있는 속성값으로 사용될 수 있도록 적절한 값으로 변경해야 한다.
category_name 데이터 전처리
- 우선 category_name을 출력한다.
mercari_df['category_name']
0 Men/Tops/T-shirts
1 Electronics/Computers & Tablets/Components & P...
2 Women/Tops & Blouses/Blouse
3 Home/Home Décor/Home Décor Accents
4 Women/Jewelry/Necklaces
...
1482530 Women/Dresses/Mid-Calf
1482531 Kids/Girls 2T-5T/Dresses
1482532 Sports & Outdoors/Exercise/Fitness accessories
1482533 Home/Home Décor/Home Décor Accents
1482534 Women/Women's Accessories/Wallets
Name: category_name, Length: 1482535, dtype: object
- 첫번째 데이터를 보도록 한다.
Men/Tops/T-shirts
- 우선
/가 2개가 나오는 것을 확인할 수 있다. 이를 기준으로 대/중/소로 구분하는 코드를 작성한다. - 그런데,
Null값을 확인해봅니다.
mercari_df['category_name'].isnull().sum()
6327
- 총
6,327개가 있기 때문에 이에 주의하면서 진행하도록 한다. ifelse를 써도 되지만,try except구문을 활용하도록 한다.
# apply lambda에서 호출되는 값
temp = "Men/Tops/T-shirts"
temp.split('/')
['Men', 'Tops', 'T-shirts']
- 위 속성을 활용하여 이제 함수를 작성한다.
- 이 때 주의해야 하는 것은
Null값이 존재하는 경우split()함수는Error를 발생하므로 이 에러를except catch하여 대, 중, 소 분류 하여Other Null값을 부여하도록 한다.
def split_category(category_name):
try:
return category_name.split('/')
except:
return ['Other_Null', 'Other_Null', 'Other_Null']
- 이제 한꺼번에 대, 중, 소로 분리하는 코드를 작성한다.
mercari_df['category_main'], mercari_df['category_sub'], mercari_df['category_sub_sub'] =\
zip(*mercari_df['category_name'].apply(lambda x: split_category(x)))
- 위 코드는 apply lambda로 반환되는 데이터 세트가 리스트를 요소로 갖는데, 이를 다시
DataFrame의 각각의 칼럼으로 분리해야 코드를 작성한 것이다. - 이를
zip함수를 활용하면 여러 개의 칼럼을 간단하게 분리할 수 있다. - 아래 글에서
Part 3: Multiple Column Creation에서zip의 활용도를 재 확인한다. - 이제 결과값을 확인한다.
print("대분류 유형:\n", mercari_df['category_main'].value_counts())
print("중분류 개수:", mercari_df['category_sub'].nunique())
print("소분류 개수:", mercari_df['category_sub_sub'].nunique())
대분류 유형:
Women 664385
Beauty 207828
Kids 171689
Electronics 122690
Men 93680
Home 67871
Vintage & Collectibles 46530
Other 45351
Handmade 30842
Sports & Outdoors 25342
Other_Null 6327
Name: category_main, dtype: int64
중분류 개수: 114
소분류 개수: 871
결측치 처리
- 마지막으로
brand_name,category_name,item_description의Null값은 몯Other Null로 동일하게 변경하도록 한다.
mercari_df['brand_name'] = mercari_df['brand_name'].fillna(value = 'Other_Null')
mercari_df['category_name'] = mercari_df['category_name'].fillna(value = 'Other_Null')
mercari_df['item_description'] = mercari_df['item_description'].fillna(value = 'Other_Null')
- 마지막으로
Null값을 확인한다.
mercari_df.isnull().sum()
train_id 0
name 0
item_condition_id 0
category_name 0
brand_name 0
price 0
shipping 0
item_description 0
category_main 0
category_sub 0
category_sub_sub 0
dtype: int64
피처 인코딩과 피처 벡터화를 위한 사전 조사
Mercari Price Suggestion에 이용되는 데이터 세트에는 문자열 컬럼이 많은데, 이를 원-핫 인코딩으로 수행하거나 피처 벡터화로 변환할 컬럼을 선별한다.- 이 때, 짧은 텍스트의 경우는
Count기반의 벡터화를 진행하며, 긴 텍스트는 TF-IDF 기반의 벡터화를 적용한다.
칼럼 1, brand_name
- 대부분 명료한 문자열로 되어 있고
brand_name의 종류도 약 4,810건이기 때문에 추후에 원-핫 인코딩으로 변환한다.
print('brand name의 유형 건수:', mercari_df['brand_name'].nunique())
print('brand name sample 5건 : \n', mercari_df['brand_name'].value_counts()[:5])
brand name의 유형 건수: 4810
brand name sample 5건 :
Other_Null 632682
PINK 54088
Nike 54043
Victoria's Secret 48036
LuLaRoe 31024
Name: brand_name, dtype: int64
칼럼 2, name
- 상품명의 경우 종류가 매우 많기 때문에 이를 원핫 인코딩으로 변경할 수는 없다.
print('name의 종류 개수:', mercari_df['name'].nunique())
print('name sample 7건: \n', mercari_df['name'][:7])
name의 종류 개수: 1225273
name sample 7건:
0 MLB Cincinnati Reds T Shirt Size XL
1 Razer BlackWidow Chroma Keyboard
2 AVA-VIV Blouse
3 Leather Horse Statues
4 24K GOLD plated rose
5 Bundled items requested for Ruie
6 Acacia pacific tides santorini top
Name: name, dtype: object
- 비교적 텍스트가 짧기 때문에
Count기반으로 피처 벡터화 변환을 적용한다.
칼럼 3, category_name
- 전처리를 통해서 이미 3가지로 분류했기 때문에, 이를 원-핫 인코딩으로 적용하도록 한다.
칼럼 4 & 5, shipping and item_condition
- 두 칼럼 모두 원-핫 인코딩으로 변환한다.
칼럼 6, Item_description
- 데이터 세트에서 가장 킨 텍스트를 가지고 있는데, 해당 칼럼의 평균 문자열 크기와 2개 정도의 텍스트만 추출하도록 한다.
print('item_description 평균 문자열 크기:', mercari_df['item_description'].str.len().mean())
mercari_df['item_description'][:2]
item_description 평균 문자열 크기: 145.7113889385411
0 No description yet
1 This keyboard is in great condition and works ...
Name: item_description, dtype: object
- 해당 칼럼은
TF-IDF로 변환한다도록 한다.
피처 벡터화 변환
- 이제 피처 벡터화 변환을 진행한다.
- 시간 체크를 위해 아래 함수를 정의한다.
import time
import datetime
def bench_mark(start):
sec = time.time() - start
times = str(datetime.timedelta(seconds=sec)).split(".")
times = times[0]
print(times)
name칼럼의 경우CountVectorizer로 변환한다.
start = time.time()
cnt_vec = CountVectorizer()
X_name = cnt_vec.fit_transform(mercari_df.name)
bench_mark(start)
0:00:08
item_description칼럼은TfidfVectorizer로 변환한다.
start = time.time()
tfidf_descp = TfidfVectorizer(max_features=50000, ngram_range=(1,3), stop_words='english')
X_descp = tfidf_descp.fit_transform(mercari_df['item_description'])
bench_mark(start)
0:02:38
- 이제 변환된 피처의 크기를 확인해봅니다.
print("name vectorization shape:", X_name.shape)
print("item_description vectorization shape:", X_descp.shape)
name vectorization shape: (1482535, 105757)
item_description vectorization shape: (1482535, 50000)
- 위 데이터는 희소 행렬 형태이므로 매우 큽니다.
- 앞으로의 진행 방향은 희소 행렬 객체 변수인
X_name과X_descp를 새로 결합하여 새로운 데이터 세트로 구성해야 하고, 또한 다른 칼럼과 결합하여 ML모델을 실행하는 기반 데이터 세트로 재 구성해야 한다. - 따라서, 대상 칼럼도 밀집 행렬 형태가 아닌 희소 행렬 형태로 인코딩을 적용한 뒤, 결합하도록 한다.
- 사이킷런은 원-핫 인코딩을 위해
OneHotEncoder와LabelBinarizer클래스를 제공한다. 위 함수를 사용한다.
from sklearn.preprocessing import LabelBinarizer
start = time.time()
# 각각의 피처들을 희소 행렬 원-핫 인코딩으로 변환한다.
lb_brand_name = LabelBinarizer(sparse_output=True)
X_brand = lb_brand_name.fit_transform(mercari_df['brand_name'])
lb_item_cond_id = LabelBinarizer(sparse_output=True)
X_item_cond_id = lb_item_cond_id.fit_transform(mercari_df['item_condition_id'])
lb_shipping = LabelBinarizer(sparse_output=True)
X_shipping = lb_shipping.fit_transform(mercari_df['shipping'])
# cat_dae, cat_jung, cat_so 각 피처들을 희소 행렬 원-핫 인코딩 변환
lb_cat_main = LabelBinarizer(sparse_output=True)
X_cat_main = lb_cat_main.fit_transform(mercari_df['category_main'])
lb_cat_sub = LabelBinarizer(sparse_output=True)
X_cat_sub = lb_cat_sub.fit_transform(mercari_df['category_sub'])
lb_cat_sub_sub = LabelBinarizer(sparse_output=True)
X_cat_sub_sub = lb_cat_sub_sub.fit_transform(mercari_df['category_sub_sub'])
bench_mark(start)
0:03:25
- 제대로 변환됐는지 확인해보자.
print(type(X_brand), type(X_item_cond_id), type(X_shipping))
print('X_brand_shape:{0}, X_item_cond_id shape:{1}'.format(X_brand.shape, X_item_cond_id.shape))
print('X_shipping shape:{0}, X_cat_main shape:{1}'.format(X_shipping.shape, X_cat_main.shape))
print('X_cat_sub shape:{0}, X_cat_sub_sub shape:{1}'.format(X_cat_sub.shape, X_cat_sub_sub.shape))
<class 'scipy.sparse.csr.csr_matrix'> <class 'scipy.sparse.csr.csr_matrix'> <class 'scipy.sparse.csr.csr_matrix'>
X_brand_shape:(1482535, 4810), X_item_cond_id shape:(1482535, 5)
X_shipping shape:(1482535, 1), X_cat_main shape:(1482535, 11)
X_cat_sub shape:(1482535, 114), X_cat_sub_sub shape:(1482535, 871)
- 각 변환된 데이터 세트는
CSR형태로 변환된csr_matrix타입이다. - 이제 마지막 단계만 남았다.
변환된 데이터 결합
- 이번에는 피처 벡터화 변환한 데이터와 희소 인코딩 변환된 데이터 세트를
hstack()를 이용해 모두 결합한다.
from scipy.sparse import hstack
import gc
sparse_matrix_list = (X_name, X_descp, X_brand, X_item_cond_id, X_shipping, X_cat_main, X_cat_sub, X_cat_sub_sub)
# hstack 함수를 이용해 인코딩과 벡터화를 수행한 데이터 세트를 모두 결합
# 아래 코드는 추후에 독립변수로 추가하게 된다.
X_features_sparse = hstack(sparse_matrix_list).tocsr()
print(type(X_features_sparse), X_features_sparse.shape)
del X_features_sparse
gc.collect()
<class 'scipy.sparse.csr.csr_matrix'> (1482535, 161569)
0
ML 모델링
- 모델링의 평가에 대한 내용은 길게 서술하지 않겠습니다.
- 평가 식은
RMSLE인데, 오차 값에 로그를 취해RMSE를 구하는 방식입니다.- 이 산식이 도입된 이유는 낮은 가격(price)보다 높은 가격에서 오류가 발생할 경우 오류 값이 더 커지는 것을 억제하기 위해 마련된 방식입니다.
- 평가를 위한 함수를 작성한 후, 모델링을 작성합니다.
- 모델링은 크게
item_description삽입 여부로 비교 분석 하는 코드를 작성한다.
import gc
from scipy.sparse import hstack
def rmsle(y , y_pred):
# underflow, overflow를 막기 위해 log가 아닌 log1p로 rmsle 계산
return np.sqrt(np.mean(np.power(np.log1p(y) - np.log1p(y_pred), 2)))
def evaluate_org_price(y_test , preds):
# 원본 데이터는 log1p로 변환되었으므로 exmpm1으로 원복 필요.
preds_exmpm = np.expm1(preds)
y_test_exmpm = np.expm1(y_test)
# rmsle로 RMSLE 값 추출
rmsle_result = rmsle(y_test_exmpm, preds_exmpm)
return rmsle_result
def model_train_predict(model,matrix_list):
# scipy.sparse 모듈의 hstack 을 이용하여 sparse matrix 결합
X= hstack(matrix_list).tocsr()
X_train, X_test, y_train, y_test=train_test_split(X, mercari_df['price'],
test_size=0.2, random_state=156)
# 모델 학습 및 예측
model.fit(X_train , y_train)
preds = model.predict(X_test)
del X , X_train , X_test , y_train
gc.collect()
return preds , y_test
linear_model = Ridge(solver = "lsqr", fit_intercept=False)
sparse_matrix_list = (X_name, X_brand, X_item_cond_id,
X_shipping, X_cat_main, X_cat_sub, X_cat_sub_sub)
linear_preds , y_test = model_train_predict(model=linear_model ,matrix_list=sparse_matrix_list)
print('Item Description을 제외했을 때 rmsle 값:', evaluate_org_price(y_test , linear_preds))
sparse_matrix_list = (X_descp, X_name, X_brand, X_item_cond_id,
X_shipping, X_cat_main, X_cat_sub, X_cat_sub_sub)
linear_preds , y_test = model_train_predict(model=linear_model , matrix_list=sparse_matrix_list)
print('Item Description을 포함한 rmsle 값:', evaluate_org_price(y_test ,linear_preds))
Item Description을 제외했을 때 rmsle 값: 0.12799038214303954
Item Description을 포함한 rmsle 값: 0.12076787880700189
- 릿지 회귀 모델을 통해 모형을 구현하였으며
Item Description을 포함했던rmsle값이 많이 감소한 것을 확인할 수 있다. 이는Item description의 영향이 중요함을 알 수 있다. - 이제 LightGBM 모형을 구축하고 앙상블을 이용한다. 마찬가지로 각 모형과 기법에 대한 추가 설명은 여기에서 다루지 않는다.
- 결과물에서 보는 것처럼
0.45까지rmsle값을 감소시켰다.
from lightgbm import LGBMRegressor
start = time.time()
## LightGBM 기법
sparse_matrix_list = (X_descp, X_name, X_brand, X_item_cond_id,
X_shipping, X_cat_main, X_cat_sub, X_cat_sub_sub)
lgbm_model = LGBMRegressor(n_estimators=200, learning_rate=0.5, num_leaves=125, random_state=156)
lgbm_preds, y_test = model_train_predict(model = lgbm_model , matrix_list=sparse_matrix_list)
print('LightGBM rmsle 값:', evaluate_org_price(y_test , lgbm_preds))
## 앙상블 기법
preds = lgbm_preds * 0.45 + linear_preds * 0.55
print('LightGBM과 Ridge를 ensemble한 최종 rmsle 값:', evaluate_org_price(y_test , preds))
bench_mark(start)
LightGBM rmsle 값: 0.11749147606180661
LightGBM과 Ridge를 ensemble한 최종 rmsle 값: 0.11588769011873494
0:25:12
Reference
- 권철민. (2020). 파이썬 머신러닝 완벽가이드. 경기, 파주: 위키북스
- Chandrima D, Suggest Automatic Price: Advanced Text Processing. Retrieved From https://www.kaggle.com/chandrimad31/suggest-automatic-price-advanced-text-processing
