[Python] PyCaret Windows 10 아나콘다 설치 방법
Page content
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

1줄 요약
- 관리자 실행해서 아나콘다 가상 환경을 만든 후, 새로운 패키지를 설치한다.
PyCaret 설치 방법 (Windows 10)
- 윈도우 10 환경에서 PyCaret 패키지를 설치해봅니다.
- 아나콘다 설치에 관한 내용은 생략합니다. 다만, 이 때, 필요한 것은 환경변수에 추가가 되어 있어야 합니다.
가상환경 설정
- 새로운 가상환경을 만듭니다. (이게 제일 편합니다.)
명령프롬프트를 관리자로 실행합니다.
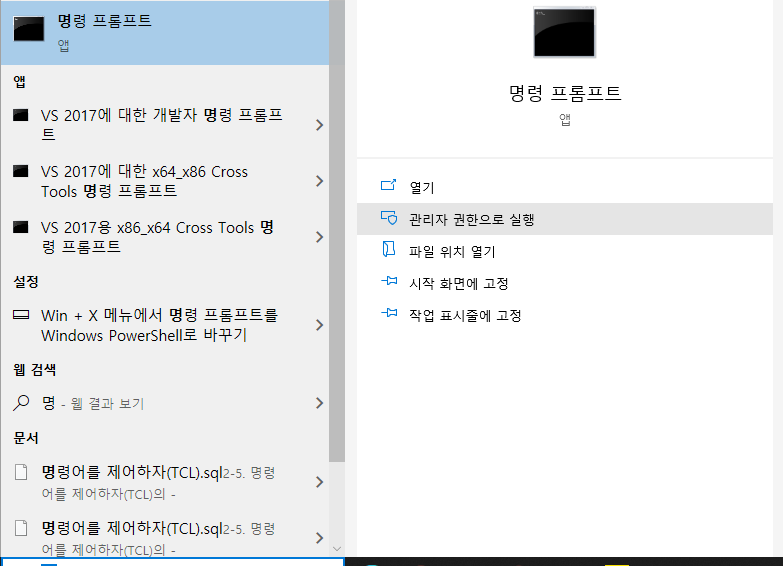
- 현재 경로는 아래와 같습니다.
!echo %cd%
C:\Users\hkit\Desktop\pycaret
- 이 때, 적정한 경로로 이동한 후, 아래 명령어를 입력합니다.
- 먼저 가상환경을 만듭니다.
$ conda create --name yourenvname python=3.8
- 필자는 yourenvname 대신에, pycaret이라고 새로 이름을 지었습니다.
- 그 후에, 가상환경에 접속합니다. (이게 중요합니다!)
$ conda activate yourenvname
- 마지막으로 pycaret을 설치합니다.
$ pip install pycaret

PyCaret을 설치하기 위해서Scikit-Learn,Pandas등을 사전에 먼저 설치할 필요가 없습니다. 만약 설치가 되어 있다면, 버전 충돌이 발생할 수가 있습니다. 즉, 이 때에는 기존에 설치된 패키지를 삭제 후 재 설치를 해야 합니다. 이러한 번거로움을 겪지 않기 위해, 새로운 가상 환경을 아예 만들어 설치하는 것이 훨씬 간편합니다.- 만약 패키지 의존성을 확인하고 싶다면, 패키지 Github의 requirements.txt을 확인하시기를 바랍니다.
- 즉,
pip install pycaret과 함께, 자동으로 설치가 됩니다.
- 즉,
주피터 노트북 실행
- 이제 주피터 노트북을 실행하여 Sample 코드를 작성해봅니다.
- 아나콘다를 관리자로 실행한 후, 아래 화면처럼 방금전에 만든 가상환경 이름을 찾아서 클릭합니다.
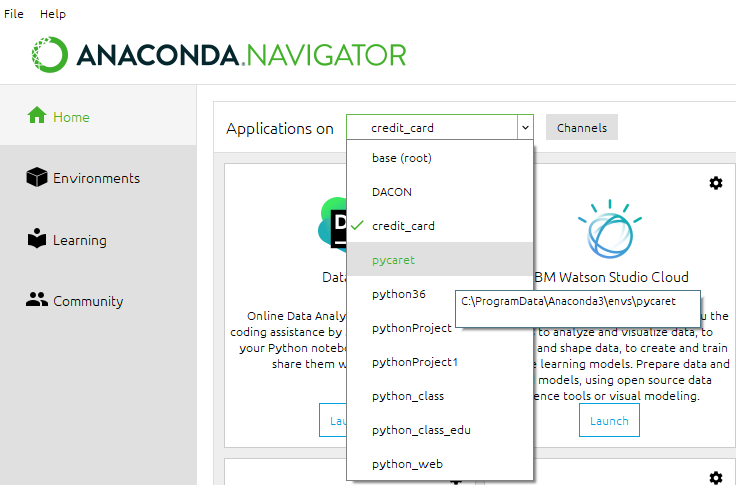
- 처음 작업하는 것이라면, 대개 아래 그림 처럼 Jupyter Notebook이나 Lab에서 설치를 먼저 해줘야 합니다.
- 필자는 Jupyter Lab을 좋아하기 때문에, Jupyter Lab을 설치 실행합니다.
Tutorial 확인
- Binary Classification Tutorial Level Beginner - CLF101.ipynb을 참조합니다.
- 코드 설명은 생략합니다.
from pycaret.datasets import get_data
dataset = get_data('credit')
dataset.shape
| LIMIT_BAL | SEX | EDUCATION | MARRIAGE | AGE | PAY_1 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | default | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20000 | 2 | 2 | 1 | 24 | 2 | 2 | -1 | -1 | -2 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 689.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1 |
| 1 | 90000 | 2 | 2 | 2 | 34 | 0 | 0 | 0 | 0 | 0 | ... | 14331.0 | 14948.0 | 15549.0 | 1518.0 | 1500.0 | 1000.0 | 1000.0 | 1000.0 | 5000.0 | 0 |
| 2 | 50000 | 2 | 2 | 1 | 37 | 0 | 0 | 0 | 0 | 0 | ... | 28314.0 | 28959.0 | 29547.0 | 2000.0 | 2019.0 | 1200.0 | 1100.0 | 1069.0 | 1000.0 | 0 |
| 3 | 50000 | 1 | 2 | 1 | 57 | -1 | 0 | -1 | 0 | 0 | ... | 20940.0 | 19146.0 | 19131.0 | 2000.0 | 36681.0 | 10000.0 | 9000.0 | 689.0 | 679.0 | 0 |
| 4 | 50000 | 1 | 1 | 2 | 37 | 0 | 0 | 0 | 0 | 0 | ... | 19394.0 | 19619.0 | 20024.0 | 2500.0 | 1815.0 | 657.0 | 1000.0 | 1000.0 | 800.0 | 0 |
5 rows × 24 columns
(24000, 24)
data = dataset.sample(frac=0.95, random_state=786)
data_unseen = dataset.drop(data.index)
data.reset_index(inplace=True, drop=True)
data_unseen.reset_index(inplace=True, drop=True)
print('Data for Modeling: ' + str(data.shape))
print('Unseen Data For Predictions: ' + str(data_unseen.shape))
Data for Modeling: (22800, 24)
Unseen Data For Predictions: (1200, 24)
from pycaret.classification import *
exp_clf101 = setup(data = data, target = 'default', session_id=123)
| Description | Value | |
|---|---|---|
| 0 | session_id | 123 |
| 1 | Target | default |
| 2 | Target Type | Binary |
| 3 | Label Encoded | 0: 0, 1: 1 |
| 4 | Original Data | (22800, 24) |
| 5 | Missing Values | False |
| 6 | Numeric Features | 14 |
| 7 | Categorical Features | 9 |
| 8 | Ordinal Features | False |
| 9 | High Cardinality Features | False |
| 10 | High Cardinality Method | None |
| 11 | Transformed Train Set | (15959, 88) |
| 12 | Transformed Test Set | (6841, 88) |
| 13 | Shuffle Train-Test | True |
| 14 | Stratify Train-Test | False |
| 15 | Fold Generator | StratifiedKFold |
| 16 | Fold Number | 10 |
| 17 | CPU Jobs | -1 |
| 18 | Use GPU | False |
| 19 | Log Experiment | False |
| 20 | Experiment Name | clf-default-name |
| 21 | USI | 7858 |
| 22 | Imputation Type | simple |
| 23 | Iterative Imputation Iteration | None |
| 24 | Numeric Imputer | mean |
| 25 | Iterative Imputation Numeric Model | None |
| 26 | Categorical Imputer | constant |
| 27 | Iterative Imputation Categorical Model | None |
| 28 | Unknown Categoricals Handling | least_frequent |
| 29 | Normalize | False |
| 30 | Normalize Method | None |
| 31 | Transformation | False |
| 32 | Transformation Method | None |
| 33 | PCA | False |
| 34 | PCA Method | None |
| 35 | PCA Components | None |
| 36 | Ignore Low Variance | False |
| 37 | Combine Rare Levels | False |
| 38 | Rare Level Threshold | None |
| 39 | Numeric Binning | False |
| 40 | Remove Outliers | False |
| 41 | Outliers Threshold | None |
| 42 | Remove Multicollinearity | False |
| 43 | Multicollinearity Threshold | None |
| 44 | Clustering | False |
| 45 | Clustering Iteration | None |
| 46 | Polynomial Features | False |
| 47 | Polynomial Degree | None |
| 48 | Trignometry Features | False |
| 49 | Polynomial Threshold | None |
| 50 | Group Features | False |
| 51 | Feature Selection | False |
| 52 | Feature Selection Method | classic |
| 53 | Features Selection Threshold | None |
| 54 | Feature Interaction | False |
| 55 | Feature Ratio | False |
| 56 | Interaction Threshold | None |
| 57 | Fix Imbalance | False |
| 58 | Fix Imbalance Method | SMOTE |
best_model = compare_models()
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | TT (Sec) | |
|---|---|---|---|---|---|---|---|---|---|
| ridge | Ridge Classifier | 0.8254 | 0.0000 | 0.3637 | 0.6913 | 0.4764 | 0.3836 | 0.4122 | 0.0300 |
| lda | Linear Discriminant Analysis | 0.8247 | 0.7634 | 0.3755 | 0.6794 | 0.4835 | 0.3884 | 0.4132 | 0.2630 |
| gbc | Gradient Boosting Classifier | 0.8225 | 0.7790 | 0.3548 | 0.6800 | 0.4661 | 0.3721 | 0.4005 | 0.7580 |
| ada | Ada Boost Classifier | 0.8221 | 0.7697 | 0.3505 | 0.6811 | 0.4626 | 0.3690 | 0.3983 | 0.1900 |
| lightgbm | Light Gradient Boosting Machine | 0.8210 | 0.7750 | 0.3609 | 0.6679 | 0.4683 | 0.3721 | 0.3977 | 0.0890 |
| rf | Random Forest Classifier | 0.8180 | 0.7618 | 0.3591 | 0.6531 | 0.4631 | 0.3645 | 0.3884 | 0.4350 |
| et | Extra Trees Classifier | 0.8082 | 0.7381 | 0.3669 | 0.6010 | 0.4553 | 0.3471 | 0.3629 | 0.4750 |
| lr | Logistic Regression | 0.7814 | 0.6410 | 0.0003 | 0.1000 | 0.0006 | 0.0003 | 0.0034 | 0.4370 |
| knn | K Neighbors Classifier | 0.7547 | 0.5939 | 0.1763 | 0.3719 | 0.2388 | 0.1145 | 0.1259 | 0.2240 |
| svm | SVM - Linear Kernel | 0.7285 | 0.0000 | 0.1003 | 0.1454 | 0.0957 | 0.0067 | 0.0075 | 0.1750 |
| dt | Decision Tree Classifier | 0.7262 | 0.6134 | 0.4127 | 0.3832 | 0.3970 | 0.2204 | 0.2208 | 0.0680 |
| qda | Quadratic Discriminant Analysis | 0.4761 | 0.5282 | 0.6208 | 0.2374 | 0.3399 | 0.0377 | 0.0478 | 0.1860 |
| nb | Naive Bayes | 0.3760 | 0.6442 | 0.8845 | 0.2441 | 0.3826 | 0.0608 | 0.1207 | 0.0280 |
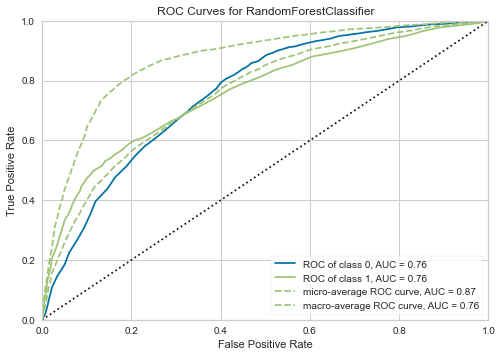
rf = create_model('rf')
plot_model(rf, plot = 'auc')
plot_model(rf, plot = 'confusion_matrix')
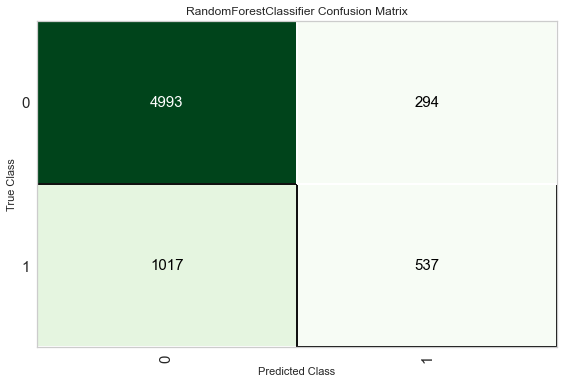
unseen_predictions = predict_model(rf, data=data_unseen)
unseen_predictions.head()
| LIMIT_BAL | SEX | EDUCATION | MARRIAGE | AGE | PAY_1 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | default | Label | Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100000 | 2 | 2 | 2 | 23 | 0 | -1 | -1 | 0 | 0 | ... | 567.0 | 380.0 | 601.0 | 0.0 | 581.0 | 1687.0 | 1542.0 | 0 | 0 | 0.74 |
| 1 | 380000 | 1 | 2 | 2 | 32 | -1 | -1 | -1 | -1 | -1 | ... | 11873.0 | 21540.0 | 15138.0 | 24677.0 | 11851.0 | 11875.0 | 8251.0 | 0 | 0 | 0.98 |
| 2 | 200000 | 2 | 2 | 1 | 32 | -1 | -1 | -1 | -1 | 2 | ... | 3151.0 | 5818.0 | 15.0 | 9102.0 | 17.0 | 3165.0 | 1395.0 | 0 | 0 | 0.87 |
| 3 | 200000 | 1 | 1 | 1 | 53 | 2 | 2 | 2 | 2 | 2 | ... | 149531.0 | 6300.0 | 5500.0 | 5500.0 | 5500.0 | 5000.0 | 5000.0 | 1 | 1 | 0.67 |
| 4 | 240000 | 1 | 1 | 2 | 41 | 1 | -1 | -1 | 0 | 0 | ... | 1737.0 | 2622.0 | 3301.0 | 0.0 | 360.0 | 1737.0 | 924.0 | 0 | 0 | 0.80 |
5 rows × 26 columns
from pycaret.utils import check_metric
check_metric(unseen_predictions['default'], unseen_predictions['Label'], metric = 'Accuracy')
0.8142
- 결론은 가상환경에서 설치를 해야 합니다. 가상환경을 잘 사용합시다.
