matplotlib 03_2 Scatter Plot
Page content
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

산점도 그래프
산점도는 두 수치형 변수의 분포를 비교하고 두 변수 사이에 상관 관계가 있는지 여부를 확인하는 데 사용됩니다. 데이터 내에 구별되는 군집/분할이 있으면 산점도에서도 명확해집니다.
(1) 라이브러리 불러오기
필요한 라이브러리를 불러옵니다.
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
(2) 데이터 생성
이번에는 seaborn 패키지 내 tips 데이터를 활용합니다.
tips = sns.load_dataset("tips")
위 데이터에서 total_bill과 tip을 각각 x, y 다시 저장해줍니다.
x = tips['total_bill']
y = tips['tip']
(3) 그래프 구현
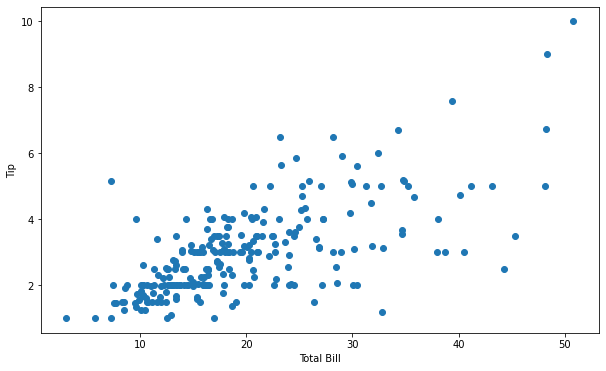
x 와 y 데이터를 가지고 산점도를 그려봅니다.
plt.figure(figsize=(10,6)): 그래프 크기를 가로10, 세로 6으로 지정plt.scatter(x,y): x와 y의 데이터로 산점도를 그림plt.xlabel: x축 라벨링plt.ylabel: y축 라벨링plt.show(): terminal에 그래프를 표시
plt.figure(figsize=(10,6))
plt.scatter(x, y)
plt.xlabel('Total Bill')
plt.ylabel('Tip')
plt.show()
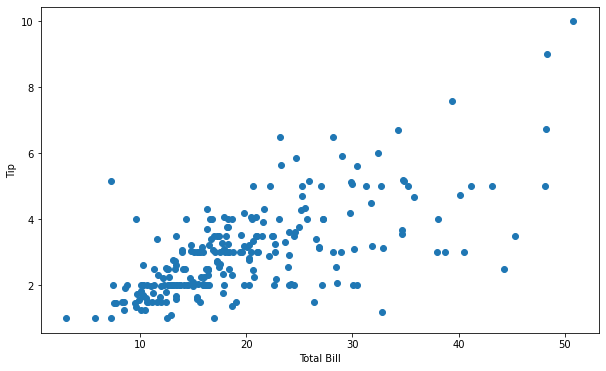
이 그래프는 plt.plot() 방법으로도 그릴 수 있습니다. 하지만, plt.scatter() 방법은 크기, 색상 등이 다른 점들을 각각 사용자 정의할 수 있는 훨씬 더 자유롭습니다.
하지만, 여러가지 변형을 줄 수 있는 대신, 속도가 느려진다는 단점이 있습니다. 따라서, 대규모 데이터 집합의 경우, plt.plot()으로 산점도를 그리는 것이 훨씬 빠를 수 있습니다.
plt.plot: linestyle을 ’none’으로 지정하고 marker를 ‘o’로 설정해 산점도를 그릴 수 있습니다.
plt.figure(figsize=(10,6))
plt.plot(x, y, linestyle='none', marker='o')
plt.xlabel('Total Bill')
plt.ylabel('Tip')
plt.show()
(4) 전체 코드
- 지금까지 작성한 코드를 한 셀에서 작성하면 다음과 같습니다.
tips = sns.load_dataset("tips")
x = tips['total_bill']
y = tips['tip']
plt.figure(figsize=(10,6))
plt.scatter(x, y)
plt.xlabel('Total Bill')
plt.ylabel('Tip')
plt.show()
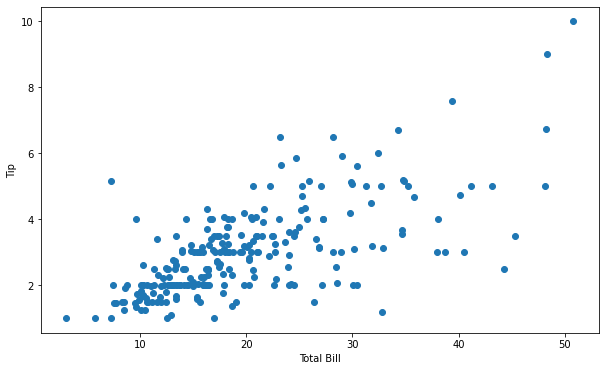
위 산점도를 통해, 희미하지만 전체 결제액이 높아질 수록 팁 금액 또한 늘어나는 양의 상관관계를 보여줍니다. 만약, 두 변수 사이에 상관관계가 없다면 패턴을 찾을 수 없는 산점도를 보여줄 것입니다. 하지만, 더 자세한 상관관계를 찾기 위해서 그룹별 산점도를 살펴볼 수 있습니다.
(5) 그룹별 산점도
- 우선, 반복문이 필요합니다.
- 이유는 Male에 해당하는 데이터와 Female에 해당하는 데이터를 각각 나뉘어서 그려야 하기 때문입니다.
- 그런데, 또한, 여기에 범례를 추가하였습니다.
- 조금 어렵지만, 우선 순차적으로 코드에 대해 설명하면 다음과 같습니다.
- 우선 map( ) 함수를 사용하여 Female에 해당하는 영역에는 RGB 색상인 #0000FF를 삽입하였고, Male은 #00FF00 색상을 삽입하였습니다.
- 즉, 이 부분은 추후에 독자가 데이터의 유형에 따라, 색상을 추가 및 변경할 수 있다는 뜻의 코드이기도 합니다. 이제 반복문을 수행합니다.
- Pandas 문법에 따라 Female과 Male기준으로 두개의 그룹을 만든 뒤, 각 그룹에 따라서 순차적으로 데이터를 그린다는 것을 말합니다.
- legend()를 추가하여 각각의 데이터가 다름을 재차 확인합니다. 마지막으로 alpha값은 투명도를 의미하며, 0-1사이의 실수값으로 표현을 합니다.
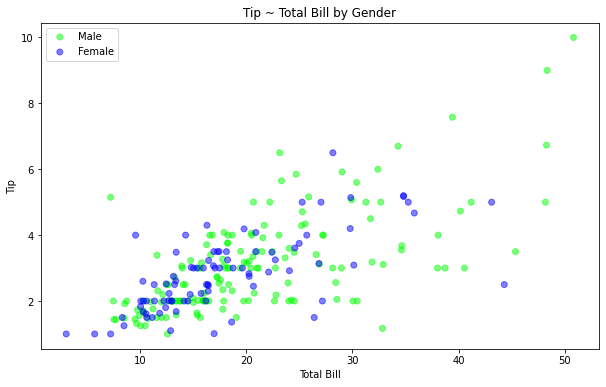
- 분명 똑같은 데이터이지만, 그룹을 추가하여 보다 의미가 더 분명해지는 것을 볼 수 있습니다.
- 보시다시피, Male 그룹이 Female 그룹보다 Total Bill과 Tip이 더 많음을 확인할 수 있습니다.
tips['sex_color'] = tips['sex'].map({"Female" : "#0000FF", "Male" : "#00FF00"})
fig, ax = plt.subplots(figsize=(10, 6))
for label, data in tips.groupby('sex'):
ax.scatter(data['total_bill'], data['tip'], label=label,
color=data['sex_color'], alpha=0.5)
ax.set_xlabel('Total Bill')
ax.set_ylabel('Tip')
ax.set_title('Tip ~ Total Bill by Gender')
ax.legend()
fig.show()