Airflow를 활용한 Data Cleansing 예제
Page content
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

개요
- Pandas와 Airflow를 활용하여 데이터를 정제하는 코드를 구성한다.
- 우선 데이터는 아래에서 CSV 파일을 다운로드 받고, Dags 파일 하단에 위치시킨다.
Raw 데이터 확인
- 간단하게 Raw 데이터를 확인해보도록 한다.
import pandas as pd
df = pd.read_csv("data/scooter.csv", index_col=0)
print(df)
(venv) $ python3 step00_raw_df.py
trip_id region_id vehicle_id ... end_location_name user_id trip_ledger_id
month ...
May 1613335 202 9424537 ... 1899 Roma Ave NE, Albuquerque, NM 87106, USA 8417864 1488546
May 1613639 202 9424537 ... 1111 Stanford Dr NE, Albuquerque, NM 87106, USA 8417864 1488838
May 1613708 202 9424537 ... 1 Domenici Center en Domenici Center, Albuquer... 8417864 1488851
May 1613867 202 9424537 ... 725 University Blvd SE, Albuquerque, NM 87106,... 8417864 1489064
May 1636714 202 8926493 ... 401 2nd St NW, Albuquerque, NM 87102, USA 35436274 1511212
... ... ... ... ... ... ... ...
July 2482235 202 2893981 ... 1418 4th St NW, Albuquerque, NM 87102, USA 42559731 2340035
July 2482254 202 8201542 ... 302 San Felipe St NW, Albuquerque, NM 87104, USA 42457674 2339885
July 2482257 202 5136810 ... 3339 Central Ave NE, Albuquerque, NM 87106, USA 42576631 2342126
July 2482275 202 3125962 ... 1413 4th St SW, Albuquerque, NM 87102, USA 42575656 2340036
July 2482335 202 9449822 ... 3339 Central Ave NE, Albuquerque, NM 87106, USA 42586810 2342161
[34226 rows x 10 columns]
정제 코드 테스트
- Airflow에 테스트를 하기 전, 실제 잘 작동하는지 확인하는 코드를 작업해본다.
- 먼저 함수,
cleanScooter()함수에 대해 살펴본다.- 먼저 데이터셋의 컬러명은 모두 소문자로 변경한다.
- 그 이후, 날짜 데이터를 포맷에 맞춰 변경한다.
- 그리고,
cleanscooter.csv데이터로 내보내기를 진행했다.
- 두번째 함수,
filterData()함수에 대해 살펴본다.- 데이터를 불러온뒤, 각 날짜에 조건문을 적용한 뒤, 데이터를 내보내기 하였다.
- 마지막 함수는 최종 결과물을 콘솔창에 보여주기 위한 것으로 작업했다.
import pandas as pd
def cleanScooter(DATA_PATH):
df = pd.read_csv(DATA_PATH + "scooter.csv", index_col=0)
df.drop(columns=['region_id'], inplace=True)
df.columns=[x.lower() for x in df.columns]
df['started_at'] = pd.to_datetime(df['started_at'], format='%m/%d/%Y %H:%M')
df.to_csv(DATA_PATH + "cleanscooter.csv")
def filterData(DATA_PATH):
df = pd.read_csv(DATA_PATH + "cleanscooter.csv", index_col=0)
from_date = '2019-05-23'
to_date = '2019-06-03'
to_from = df[(df['started_at'] > from_date) & (df['started_at'] < to_date)]
to_from.to_csv(DATA_PATH + "may23-june3.csv")
def check_df(DATA_PATH):
df = pd.read_csv(DATA_PATH + "may23-june3.csv")
print(df)
if __name__ == "__main__":
DATA_PATH = "your_path/data/"
cleanScooter(DATA_PATH)
filterData(DATA_PATH)
check_df(DATA_PATH)
- 위 파일을 실행하면 다음과 같은 결괏값이 나올 것이다.
(venv) $ python3 step01_clean_df.py
month trip_id vehicle_id ... end_location_name user_id trip_ledger_id
0 May 1636714 8926493 ... 401 2nd St NW, Albuquerque, NM 87102, USA 35436274 1511212
1 May 1636780 3902020 ... 3217 Pershing Ave SE, Albuquerque, NM 87106, USA 34352757 1511371
2 May 1636856 5192526 ... 809 Copper Ave NW, Albuquerque, NM 87102, USA 35466666 1511483
3 May 1636912 3902020 ... 802 Wellesley Dr SE, Albuquerque, NM 87106, USA 34352757 1511390
4 May 1637035 5192526 ... 809 Copper Ave NW, Albuquerque, NM 87102, USA 35466666 1511516
... ... ... ... ... ... ... ...
6187 June 1772189 7992415 ... 200 3rd St NW, Albuquerque, NM 87102, USA 35858913 1642397
6188 June 1772212 5216813 ... 6th @ Silver, Albuquerque, NM 87102, USA 35795570 1642192
6189 June 1772216 5637480 ... 413 2nd St SW, Albuquerque, NM 87102, USA 37255146 1642781
6190 June 1772229 2739536 ... 101 Broadway Blvd NE, Albuquerque, NM 87102, USA 38038151 1643073
6191 June 1772254 6016871 ... 1st St NW @, Central Ave NW, Albuquerque, NM 8... 37761291 1642284
[6192 rows x 10 columns]
- 약 3만개의 레코드의 행 갯수가 6000개로 줄어든 것을 확인할 수 있다.
Airflow Code
- 이제
airflow에서 작업을 해보도록 한다. - 파일명은
step05_01_clean_df.py로 명명했다.
import pandas as pd
import datetime as dt
from datetime import timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
def cleanScooter():
df = pd.read_csv("dags/data/scooter.csv", index_col=0)
df.drop(columns=['region_id'], inplace=True)
df.columns=[x.lower() for x in df.columns]
df['started_at'] = pd.to_datetime(df['started_at'], format='%m/%d/%Y %H:%M')
df.to_csv("dags/data/cleanscooter.csv")
def filterData():
df = pd.read_csv("dags/data/cleanscooter.csv", index_col=0)
from_date = '2019-05-23'
to_date = '2019-06-03'
to_from = df[(df['started_at'] > from_date) & (df['started_at'] < to_date)]
to_from.to_csv("dags/data/may23-june3.csv")
default_args = {
'owner': 'evan',
'start_date': dt.datetime(2021, 9, 15),
'retries': 1,
'retry_delay': dt.timedelta(minutes=5),
}
with DAG('Cleaning_Data',
default_args = default_args,
schedule_interval=timedelta(minutes=5),
) as dag:
print_starting = BashOperator(task_id='starting',
bash_command='echo "I am reading the PostgreSQL now....."')
cleanData = PythonOperator(task_id="cleaning_df",
python_callable=cleanScooter)
selectData = PythonOperator(task_id="Filtering_df",
python_callable=filterData)
copyFile = BashOperator(task_id="copy_df",
bash_command='cp $AIRFLOW_HOME/dags/data/may23-june3.csv /your_path/Desktop/')
print_starting >> cleanData >> selectData >> copyFile
- 기존에 작업한 코드와 크게 달라진 것은 없기 때문에, 전체 코드는 생략한다.
dags안에data폴더를 만들어서scooter.csv만 넣었다. 실행 후 어떻게 새로운 데이터가 추가가 되었는지 확인해본다.- 마지막 코드는 최종 결과물을 복사하여 바탕화면에 붙여넣기 하는 코드를 말한다.
(venv) $ ls
scooter.csv
DAG가 완성되었으면, 해당 코드를$AIRFLOW_HOME/dags폴더에 복사하고, 다음 명령들로 웹서버와 스케줄러를 실행한다.
(venv) airflow:evan $ airflow webserver
(venv) airflow:evan $ airflow scheduler
실행결과 확인
- 우선 웹 브라우저로
[http://localhost:8080](http://localhost:8080)에 접속 후, 정상적으로 작업이 되는지 확인한다.
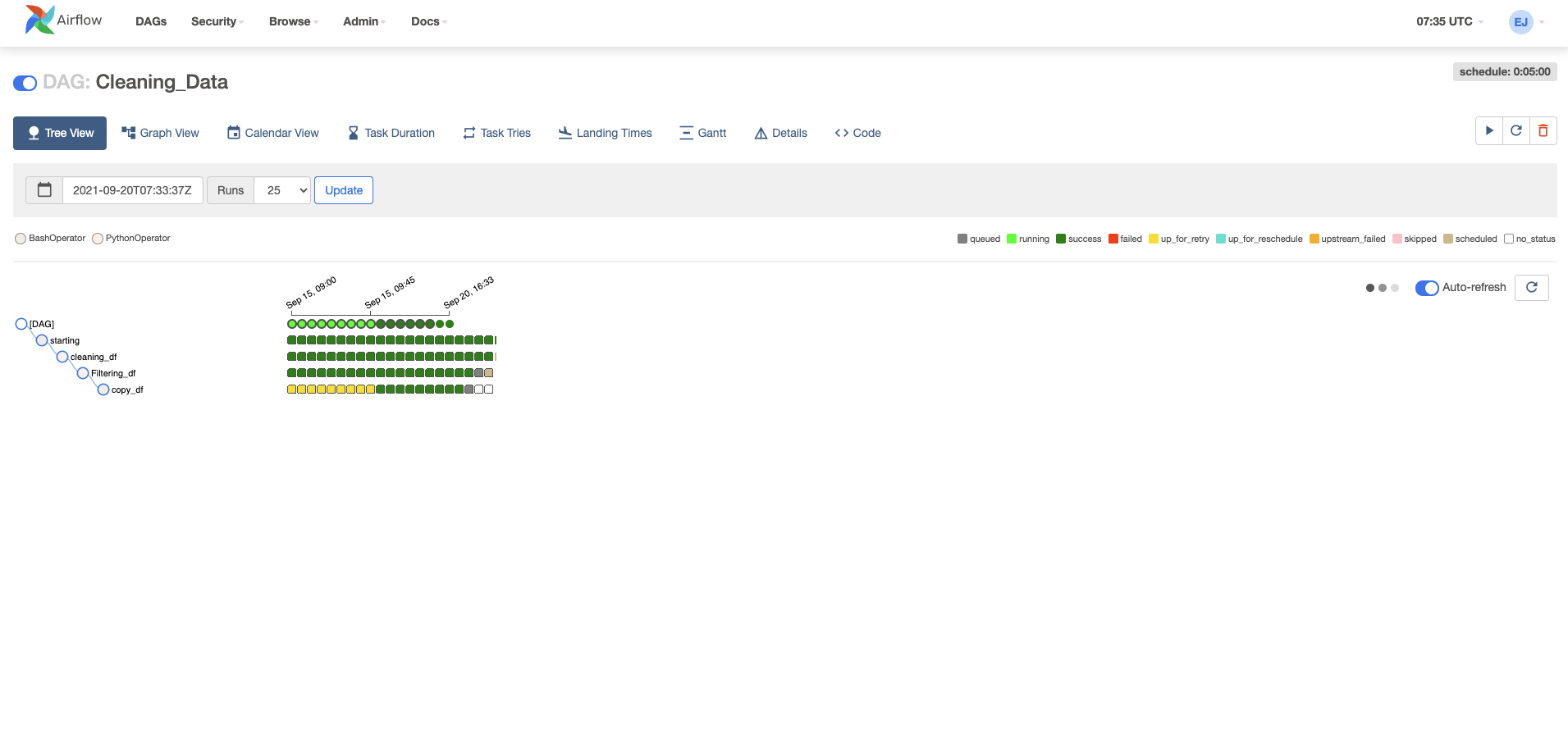
- 마지막으로 Data 폴더를 확인해본다.
(venv) your_path:data (evan)$ ls
cleanscooter.csv may23-june3.csv scooter.csv
References
- Data Engineering with Python by Paul Crickard, https://www.packtpub.com/product/data-engineering-with-python/9781839214189
