데이콘 대회 참여 - 01 제주시 빅데이터 카드 매출 경진대회 데이터 수집 및 저장
Page content
I. 개요
- 본 과정은 직업훈련기관 수업의 일환으로 진행하였음
- 수강생들이 기본적으로 어려워하는 클라우드
DB연동부터 구현하여 빠르게EDA를 활용할 수 있도록 진행함 DB는BigQuery를 활용함.
(1) 대회 참여 및 파일 다운로드 상세
- 데이콘은 국내 빅데이터 경진대회이다.

(2) 대회 개요
Ref. https://dacon.io/competitions/official/235615/overview/
-
주제
- AI 알고리즘 활용 카드 사용 금액 예측
-
목표
- 신용카드 사용 내역 데이터를 활용한 지역별, 업종별 월간 카드 사용 총액 예측
-
배경
- 신용카드 사용량을 분석을 통한 ‘Post COVID-19 시대’ 신용카드 사용량 예측 모델 개발
- 지역 경제 위축 및 중소상공인 경영난 해소를 위한 대책 마련
-
주최/주관
- 주최 : 제주특별자치도청, 제주테크노파크
- 주관 : DACON
-
참가자 대상
- AI, 빅데이터에 관심있는 누구나 참여 가능
-
상금/시상
- 1위 (대상) : 300 만원 / 제주특별자치도지사상
- 2위 (최우수상) : 200 만원 / 제주테크노파크원장상
- 3위 (우수상) : 100 만원 / 제주테크노파크원장상
(3) 규칙
-
평가식
- RMSLE (Root Mean Square Logarithmic Error)
- 제주 지역에 3배 가중치 부여
-
평가
- 가채점 순위 (Public Score) : 1차 테스트 데이터 (2020.04) 로 채점
- 최종 순위 (Private Score) : 2차 테스트 데이터 (2020.07) 로 채점, 대회 종료 후 공개
- 최종 순위는 선택된 파일 중에서 채점되므로, 참가자는 제출 창에서 자신이 최종적으로 채점 받고 싶은 파일을 선택해야 함. (최종 파일 미선택시 처음으로 제출한 파일로 자동 선택됨)
- 리더보드 운영 종료 이후 Private Score 랭킹이 가장 높은 참가자 5팀은 양식에 맞는 코드와 함께 코드 내용을 설명하는 PPT 제출 (대회 종료 후 dacon@dacon.io를 통해 안내)
- 대회 직후 공개되는 Private Score 랭킹은 최종 순위가 아니며 코드 검증 후 최종 수상자가 결정됨
-
외부 데이터
- 공공 데이터와 같은 법적인 제약이 없는 경우에만 사용 가능
- 공공데이터 다운을 받은 경우 링크를 게시해야 함
- 크롤링 시 코드 제출 필수
- 2020.04.30 데이터까지만 사용 가능 (?)
-
개인 및 팀 병합 규정
- 개인 참가 방법 : 팀 신청 없이, 자유롭게 제출 창에서 제출 가능
- 팀 참가 방법 : 팀 배너에서 가능, 상세 내용은 팀 배너에서 팀 병합 정책 확인
- 하나의 대회에는 하나의 팀으로만 등록 가능
- 팀 병합 후 해체 및 개인 참가 불가
- 팀의 수상 요건 충족 시 팀의 대표가 수상
-
코드 제출 규칙
- 입상자는 데이콘에서 안내한 양식에 맞추어 코드 제출
- R user는 R or .rmd. Python user는 .py or .ipynb로 제출
- 코드에 ‘/data’ 데이터 입/출력 경로 포함
- 전체 프로세스를 가독성 있게 정리하여 주석 포함 하나의 파일로 제출
- 제출 코드는 리더보드 점수를 복원할 수 있어야 함
- 모든 코드는 오류 없이 실행되어야 함 (라이브러리 로딩 코드 포함)
- 코드와 주석의 인코딩은 UTF-8 사용
(4) 일정
- 대회 기간 : 2020년 06월 22일 10:00 ~ 2020년 07월 31일 17:59
- 2차 데이터 공개 : 2020년 07월 28일
- 코드 제출 : 2020년 08월 01일 ~ 2020년 08월 09일
- 코드 평가 : 2020년 08월 10일 ~ 2020년 08월 21일
- 최종 순위 발표 : 2020년 08월 24일
- 시상식 : 2020년 11월 중
(5) 상금
- 1위 (대상) : 300 만원 / 제주특별자치도지사상
- 2위 (최우수상) : 200 만원 / 제주테크노파크원장상
- 3위 (우수상) : 100 만원 / 제주테크노파크원장상
II. 데이터 다운로드 및 빅쿼리 연동
(1) 파일 다운로드
-
데이터는 아래에서 다운로드 받는다.
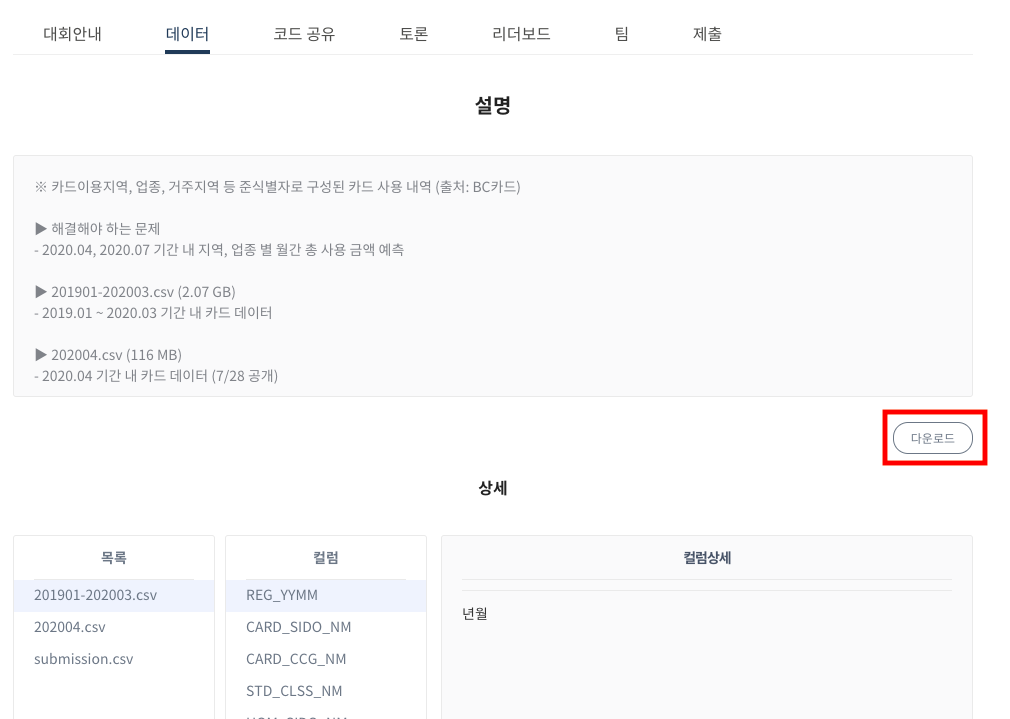
-
6/23일 기준으로 데이터를 받았으나 현재 있는
csv파일은 다음과 같다.- 201901-202003.csv
- submission.csv
(2) Google BigQuery
- BigQuery 웹 UI로 이동한다.
- 탐색 패널에서
데이터세트에 마우스를 가져간 다음 아래쪽 화살표 아이콘 아래쪽 화살표 아이콘 이미지을 클릭한 후새 테이블 만들기를 클릭한다.
 + 이 때, 프로젝트가 없다면 프로젝트 만들기 및 관리에서 새로운 프로젝트를 만든다.
+ 이 때, 프로젝트가 없다면 프로젝트 만들기 및 관리에서 새로운 프로젝트를 만든다.
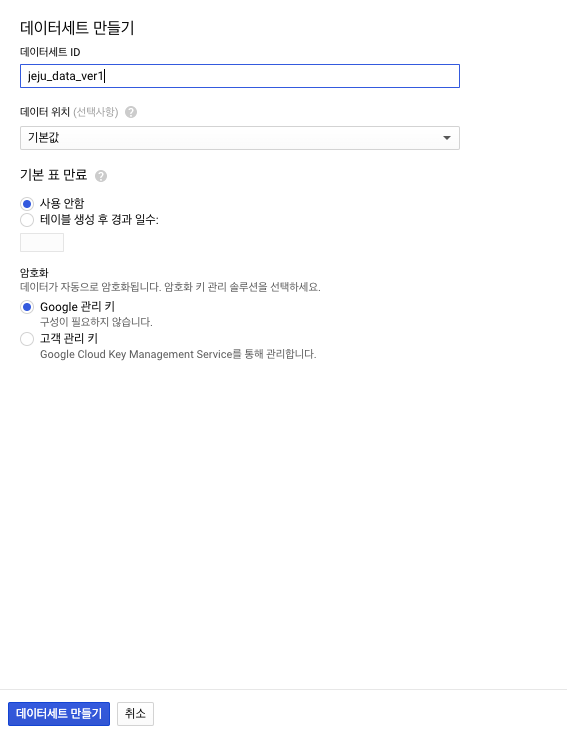
- 테이블세트 ID는
jeju_data_ver1로 이름지었다. (이 부분은 독자의 임의대로 수정할 수 있다.)
(3) Google Colab
-
로컬에서 빅쿼리로 데이터를
Load하는 방법에는 여러가지가 있다.- Local에서 직접 올리기 (단, 10MB 이하)
- Google Stroage 활용
- Pandas 활용
-
Google Stroage를 활용하려면
클라우드 수업으로 진행되기 때문에,Pandas패키지를 활용한다.to_gbq라는 함수를 사용하는데, 이를 위해서는 보통 pandas-gbq package패키지를 별도로 설치를 해야한다.- 다행히도, 구글
Colab에서는 위 패키지는 별도로 설치할 필요가 없다.
-
Google Drive와 연동한다.
# Google Drive와 마운트
from google.colab import drive
ROOT = '/content/drive'
drive.mount(ROOT)
- Project 폴더와 연동한다.
# Project Folder 연결
from os.path import join
MY_GOOGLE_DRIVE_PATH = 'My Drive/Colab Notebooks/your/project/folder'
PROJECT_PATH = join(ROOT, MY_GOOGLE_DRIVE_PATH)
print(PROJECT_PATH)
%cd "{PROJECT_PATH}"
- 여기에서 다음 코드를 순차적으로 입력하고 실행한다.
import pandas as pd
from pandas.io import gbq
# import submission file in Google Drive
submission = pd.read_csv('data/submission.csv')
# Connect to Google Cloud API and Upload DataFrame
submission.to_gbq(destination_table='jeju_data_ver1.submission',
project_id='your_project_id',
if_exists='replace')
# import submission file in Google Drive
train = pd.read_csv('data/201901-202003.csv')
# Connect to Google Cloud API and Upload DataFrame
train.to_gbq(destination_table='jeju_data_ver1.201901_202003_train',
project_id='your_project_id',
if_exists='replace')
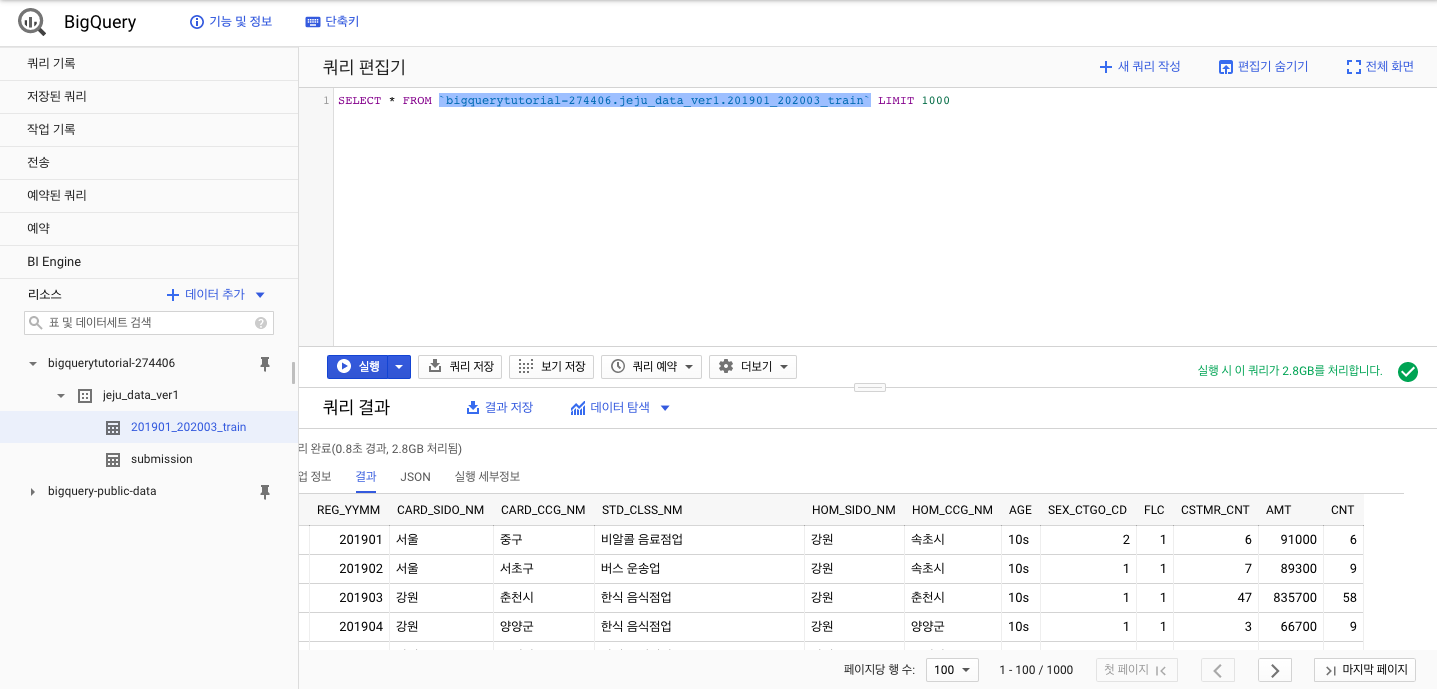
201901_202003_train을BigQuery로Loading시, 약 10분의 시간이 소요되었다.
-
물론, 더 빠르게 하려면, Google Cloud Storage를 활용해야 하지만, 여기에서는 이 부분은 생략하였다.
-
다만, 구글 Colab을 활용하려면 구글 드라이브에 파일이 있어야 하는데, 이러한 부분이 번거롭다면
Local의Jupyter Notebook에서 진행하는 것을 추천한다.
