Python Selenium Crawling Tutorial
Page content
강의소개
- 인프런에서 Streamlit 관련 강의를 진행하고 있습니다.
- 인프런 : https://inf.run/YPniH
개요
- 크롬 드라이버를 활용하여 Selenium을 설치한다.
- 네이버 평점에서 특정 영화(노트북)를 관람한 관람객이 영화에 댓글을 단 영화 수집
크롬 드라이버 설치
- 자신의 크롬 버전과 같은 버전을 설치한다.
- 오른쪽 상단에서 더보기를 클릭한다.
- 도움말 > Chrome 정보를 클릭한다.
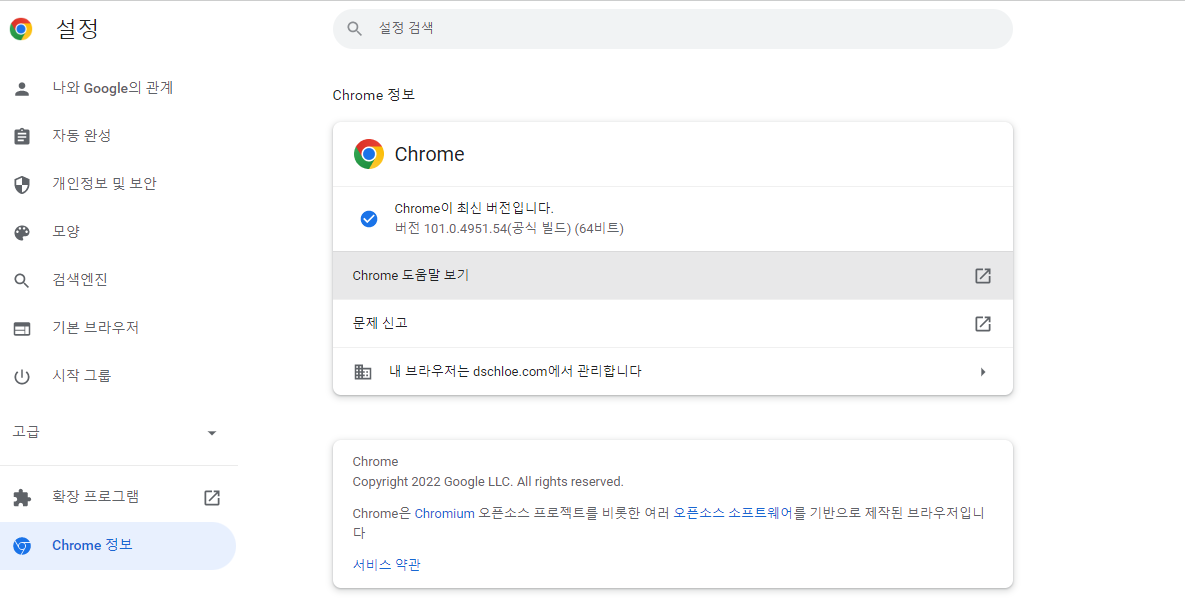
- 이번에는 크롬 드라이버를 다운로드 받는다.
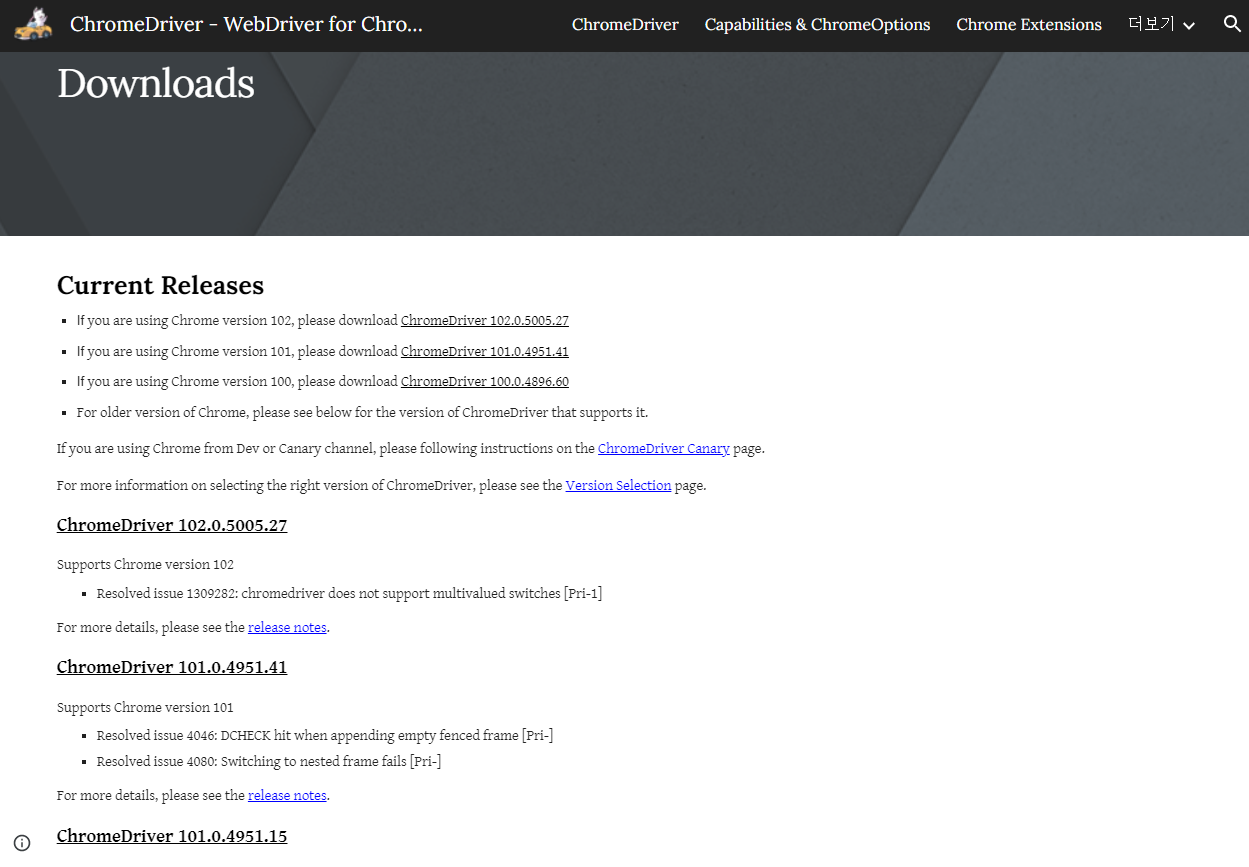
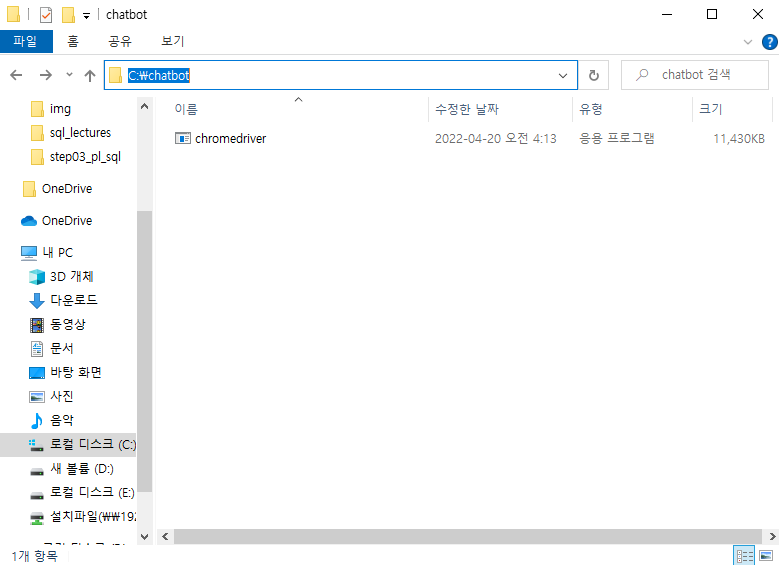
- 다운로드 받은 파일은 C드라이브 하단에 chatbot 폴더에 위치시킨다.
- URL : C:\chatbot
라이브러리 설치
- chatbot 프로젝트를 생성하고, 가상환경을 추가한다 (추가 내용 생략).
- requirements.txt 파일
selenium
lxml
bs4
mlxtend
Jupyter Notebook 실행
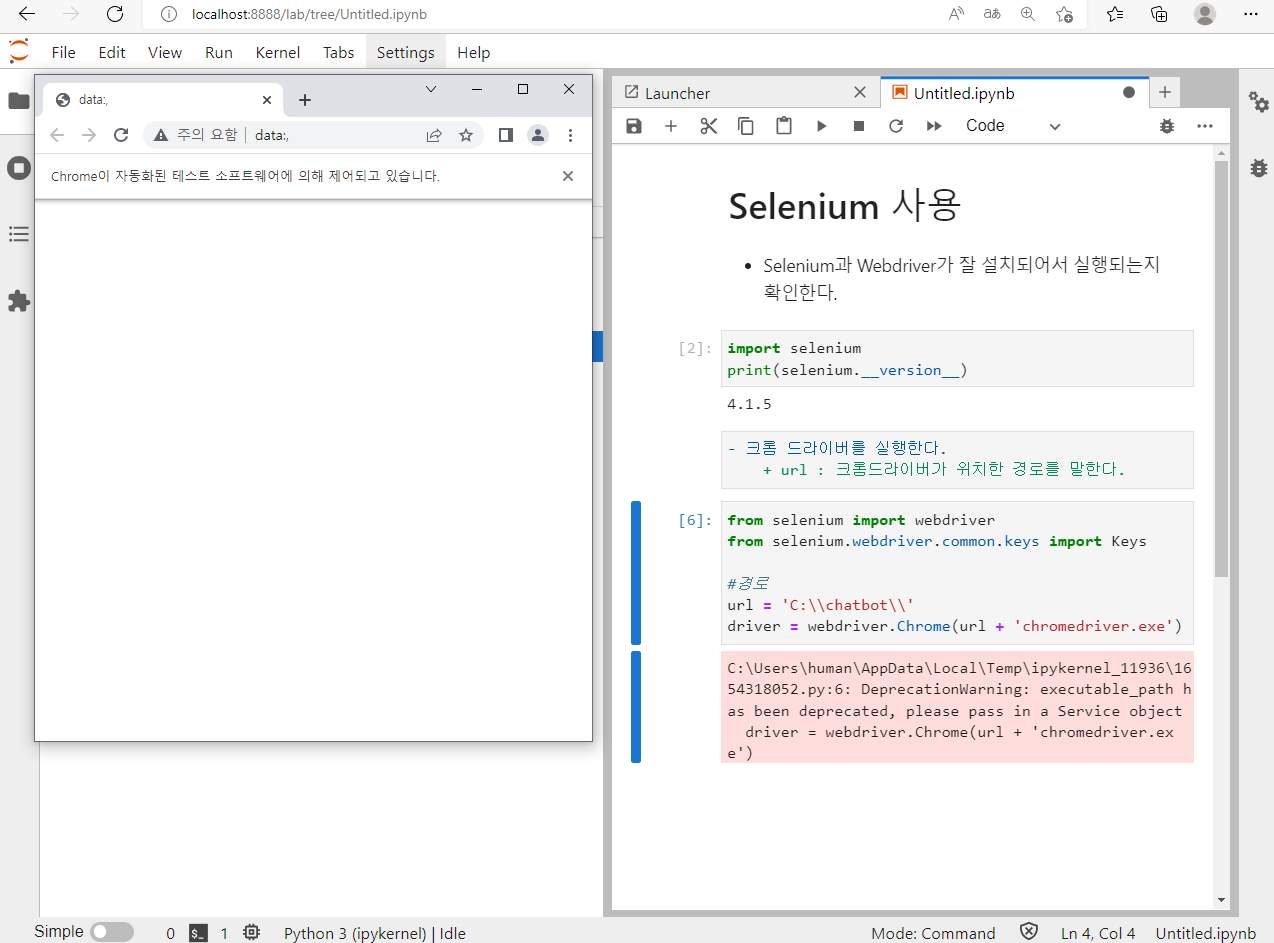
- 다음과 같이 Jupyter Notebook을 실행한다.
- 아래와 같은 코드를 실행하여 Selenium이 정상적으로 작동하는지 확인해본다.
데이터 수집
(1) 크롬 드라이버 실행 확인
- 우선 크롬 드라이버가 정상적으로 실행되는지 확인한다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#경로
url = 'C:\\chatbot\\'
driver = webdriver.Chrome(url + 'chromedriver.exe')
movieURL = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=38899&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false'
driver.get(movieURL)
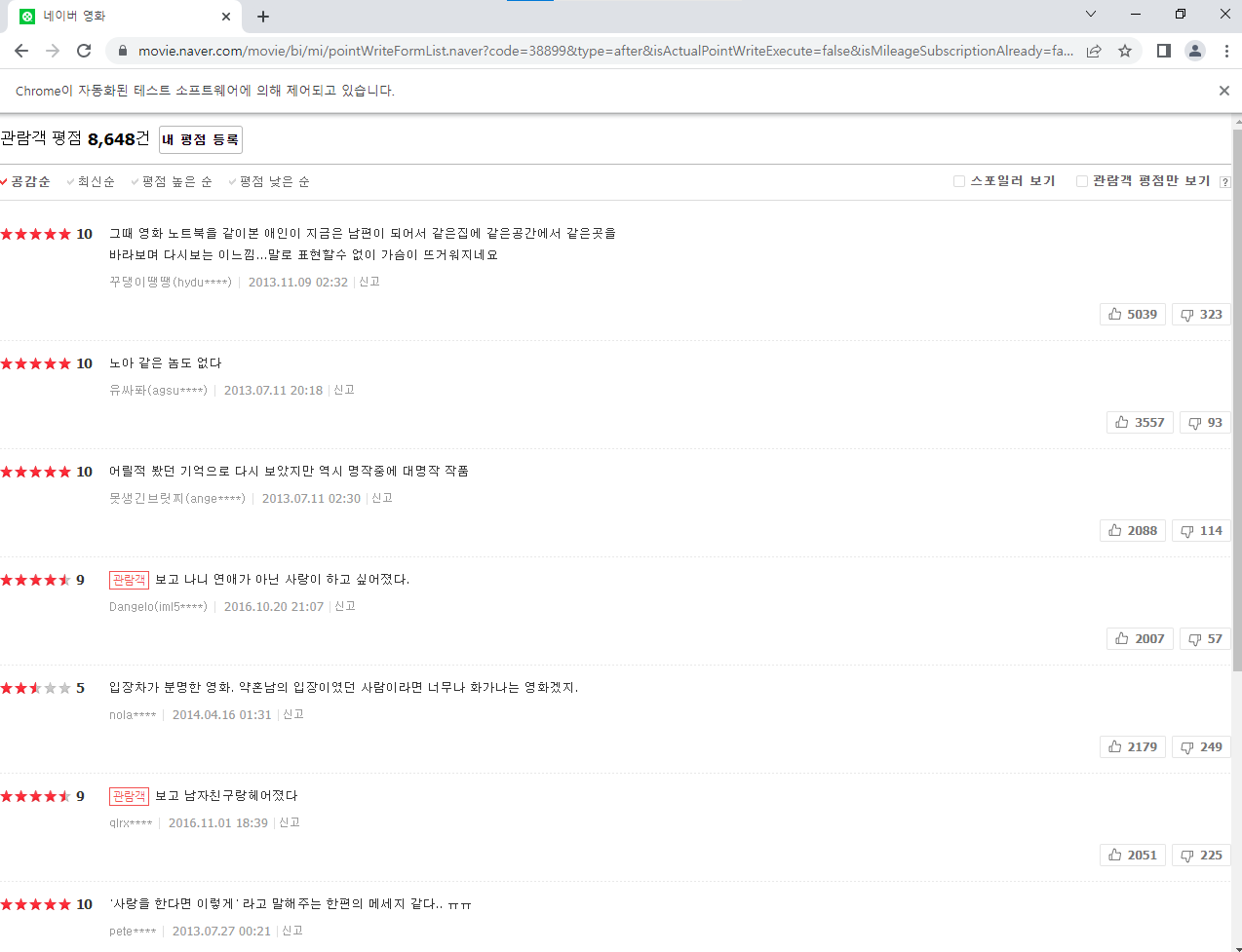
(2) 관람객 평점으로 클릭 리스트 확인
- 관람객 평점으로 클릭하도록 한다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#경로
url = 'C:\\chatbot\\'
driver = webdriver.Chrome(url + 'chromedriver.exe')
movieURL = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=38899&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false'
driver.get(movieURL)
# 관람객 평점으로 클릭
driver.find_element_by_xpath('//*[@id="actualYnLable"]').click()

(3) 댓글 사용자 접속 링크 확인
- 본 프로젝트에서 중요한 건, 댓글 수집이 아니라, 댓글을 단 사용자가 본 영화를 수집하는 것이다.
- 해당 사용자를 클릭하는 코드를 가져오도록 한다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup as bs
import time
#경로
url = 'C:\\chatbot\\'
driver = webdriver.Chrome(url + 'chromedriver.exe')
movieURL = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=38899&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false'
driver.get(movieURL)
# 관람객 평점으로 클릭
driver.find_element_by_xpath('//*[@id="actualYnLable"]').click()
driver.implicitly_wait(1) # 1초 대기
# 영화 리스트 담을 빈 리스트 생성
total_lst = []
# page 링크
for v in range(5):
# page 내 글 리스트
for i in range(10):
time.sleep(.4)
authorURL = '/html/body/div/div/div[5]/ul/li[{num}]/div[2]/dl/dt/em[1]/a/span'.format(num=i+1)
print(authorURL)
watcher = driver.find_element_by_xpath(authorURL)
watcher.click()
time.sleep(0.4)
page = driver.page_source
# 크롬 드라이버 재실행
driver.back()
# print(page)
info = bs(page, 'lxml')
print(info)
- 아래 그림은
authorURL태그를 가져온다.
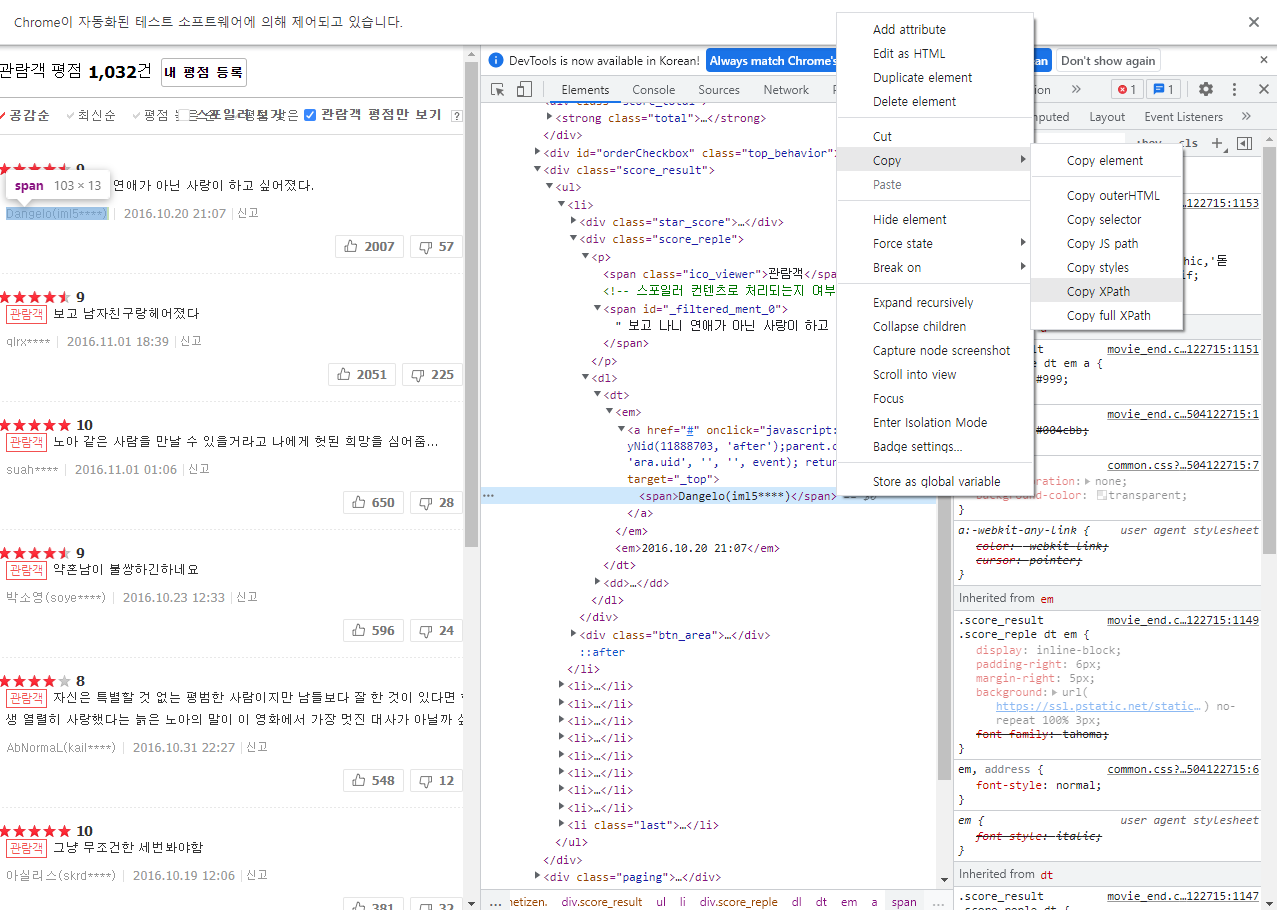
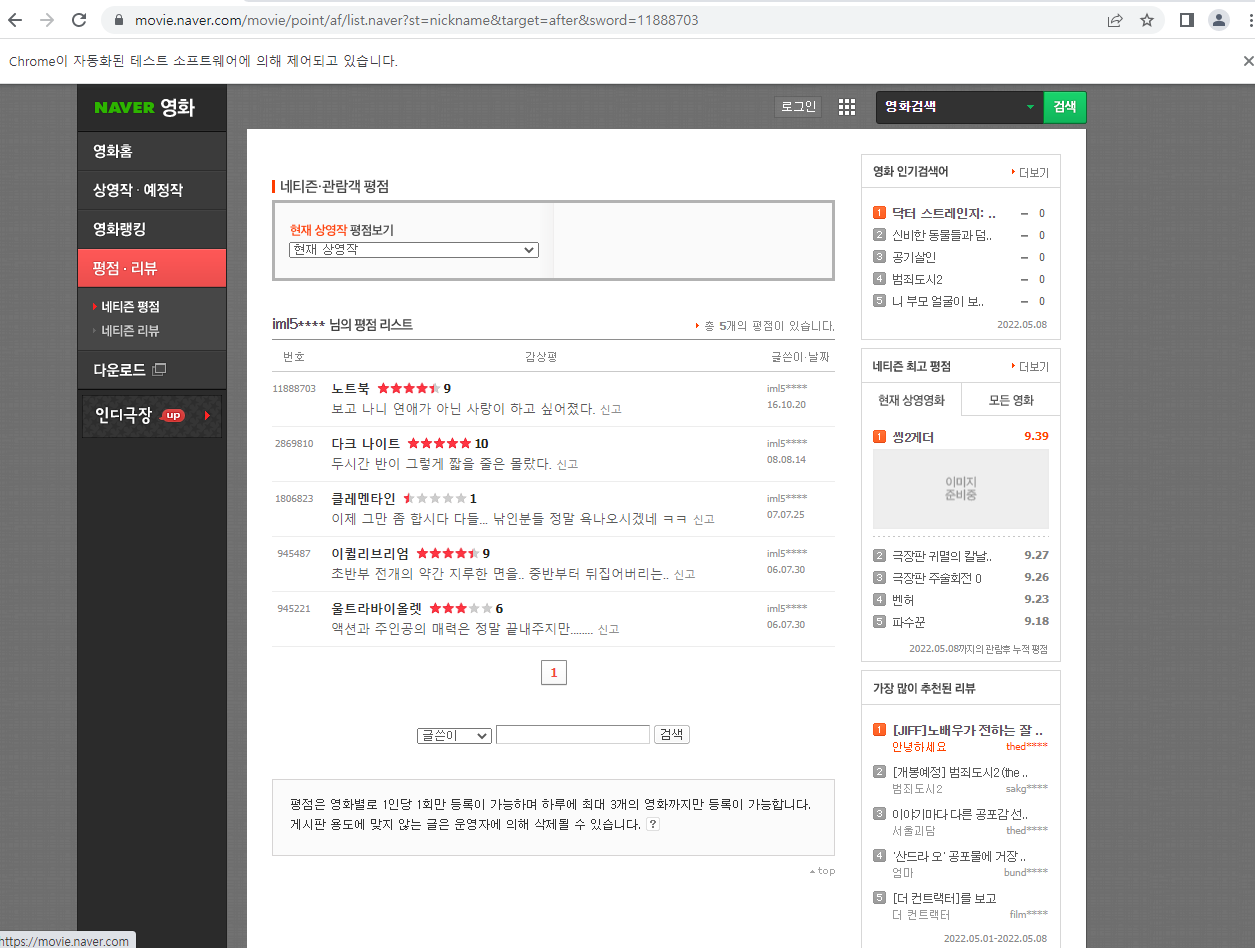
- 아래 그림은 위 코드를 실행했을 때의 완성 코드이다.
- 위 화면이 계속 바뀌게 될 것이다.
(4) 영화 리스트 추출
- 각 관람객의 전체 영화 리스트를 추출하는 코드를 불러온다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup as bs
import time
#경로
url = 'C:\\chatbot\\'
driver = webdriver.Chrome(url + 'chromedriver.exe')
movieURL = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=38899&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false'
driver.get(movieURL)
# 관람객 평점으로 클릭
driver.find_element_by_xpath('//*[@id="actualYnLable"]').click()
driver.implicitly_wait(1) # 1초 대기
# 영화 리스트 담을 빈 리스트 생성
total_lst = []
# page 링크
for v in range(5):
# page 내 글 리스트
for i in range(10):
time.sleep(.4)
authorURL = '/html/body/div/div/div[5]/ul/li[{num}]/div[2]/dl/dt/em[1]/a/span'.format(num=i+1)
print(authorURL)
watcher = driver.find_element_by_xpath(authorURL)
watcher.click()
time.sleep(0.4)
page = driver.page_source
# 크롬 드라이버 재실행
driver.back()
# print(page)
info = bs(page, 'lxml')
# print(info)
# 영화 제목만 가져오도록 한다.
td_list = info.find_all('td', 'title')
lst = []
for i in range(len(td_list)):
lst.append(td_list[i].a.string)
total_lst.append(lst)
time.sleep(0.4)
break
print(total_lst)
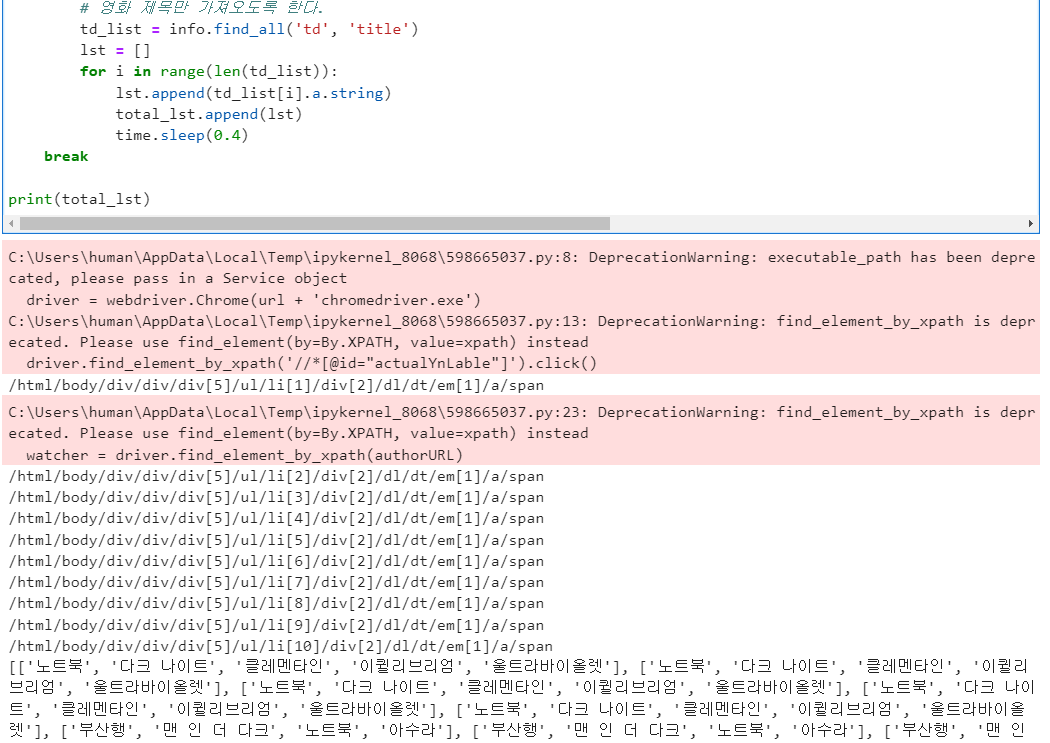
(5) 페이지 링크 추가
- 우선 페이지 링크의 xpath 태그는 아래 그림처럼 pagerTagAnchor에서 숫자가 변동이 된다.
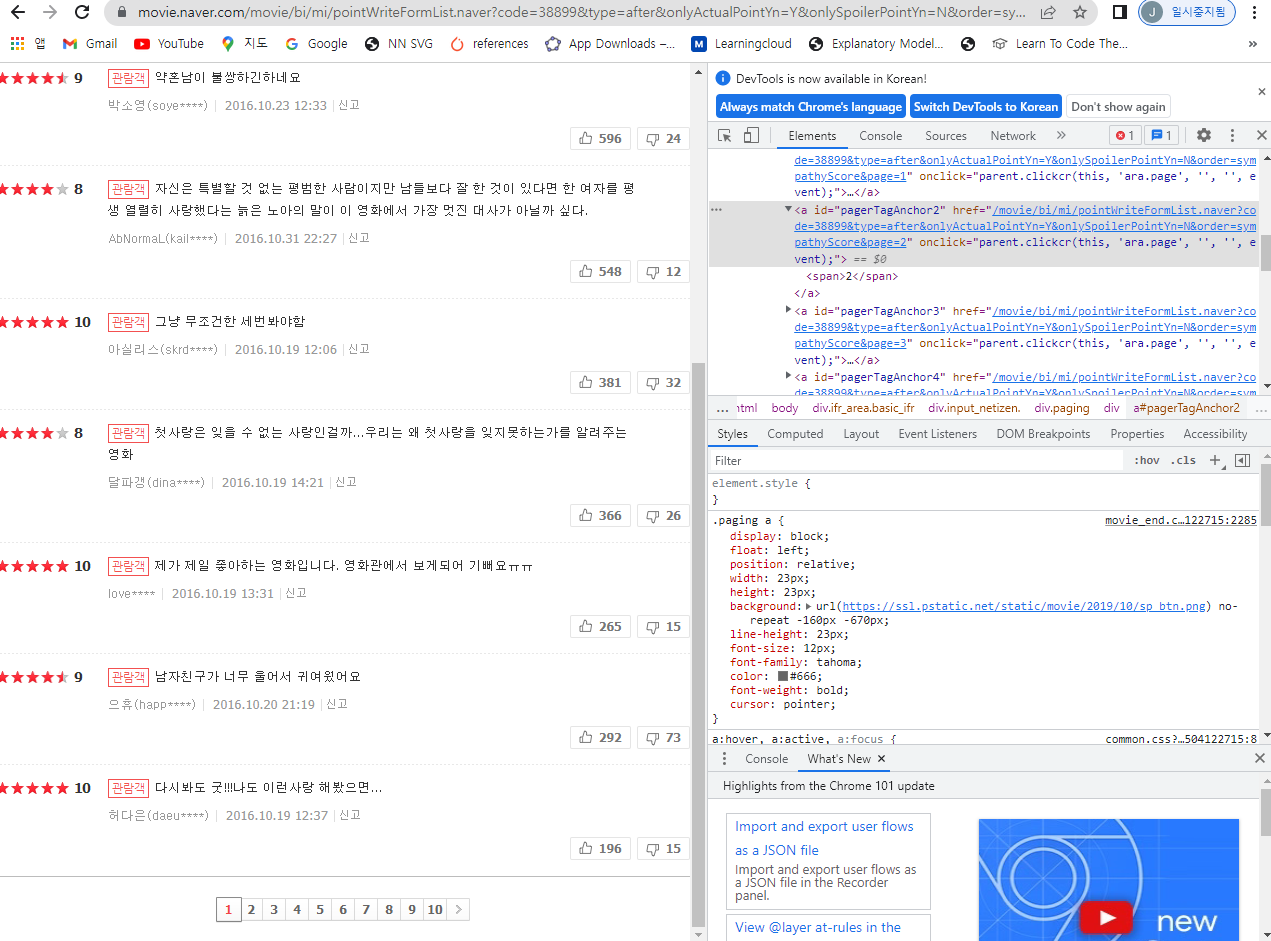
- 이제, 해당 코드를 작성하도록 한다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup as bs
import time
#경로
url = 'C:\\chatbot\\'
driver = webdriver.Chrome(url + 'chromedriver.exe')
movieURL = 'https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=38899&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false'
driver.get(movieURL)
# 관람객 평점으로 클릭
driver.find_element_by_xpath('//*[@id="actualYnLable"]').click()
driver.implicitly_wait(1) # 1초 대기
# 영화 리스트 담을 빈 리스트 생성
total_lst = []
# page 링크
for v in range(5):
# page 내 글 리스트
for i in range(10):
time.sleep(.4)
authorURL = '/html/body/div/div/div[5]/ul/li[{num}]/div[2]/dl/dt/em[1]/a/span'.format(num=i+1)
print(authorURL)
watcher = driver.find_element_by_xpath(authorURL)
watcher.click()
time.sleep(0.4)
page = driver.page_source
# 크롬 드라이버 재실행
driver.back()
# print(page)
info = bs(page, 'lxml')
# print(info)
# 영화 제목만 가져오도록 한다.
td_list = info.find_all('td', 'title')
lst = []
for i in range(len(td_list)):
lst.append(td_list[i].a.string)
total_lst.append(lst)
time.sleep(0.4)
time.sleep(.4)
pageURL = '//*[@id="pagerTagAnchor{num2}"]/em'.format(num2=v+2)
next_page = driver.find_element_by_xpath(pageURL)
time.sleep(.4)
next_page.click()
print(total_lst)
- 마지막으로 출력한다.
f = open('movieList.txt', 'w')
f.write(str(total_lst))
f.close()
참고교재
- 알파(R과 Python)를 활용한 인공지능 챗봇 14, (http://www.yes24.com/Product/Goods/96568020)
