LangChain with Streamlit 논문요약 예제
Page content
개요
- LangChain의 기본 개념에 대해 살펴본다.
- LangChain을 활용하며 간단한 웹앱을 구현한다.
- 각 사용자가 본인의 API를 입력하면 해당 기능을 사용할 수 있도록 구현한다.
LangChain의 기본개념
- LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크입니다.
- 주요 특징과 장점은 다음과 같다.
- 모듈성
- 다양한 LLM과 도구들을 쉽게 통합하고 교체할 수 있다.
- 재사용 가능한 컴포넌트를 제공한다.
- 체이닝(Chaining)
- 여러 컴포넌트를 연결하여 복잡한 워크플로우를 구성할 수 있다.
- 프롬프트, LLM 호출, 출력 파싱 등을 순차적으로 처리한다
- 메모리 관리
- 대화 기록을 저장하고 관리할 수 있다.
- 문맥을 유지하면서 대화형 애플리케이션을 만들 수 있다.
- 다양한 통합
- 여러 AI 모델(OpenAI, Anthropic 등)을 지원한다.
- 데이터베이스, 검색 엔진 등 외부 도구와 연동이 가능하다.
- 개발 편의성
- 파이썬 기반의 직관적인 API를 제공한다.
- 풍부한 문서와 예제가 제공된다.
- 모듈성
LangChain을 활용한 프로젝트 구조 만들기
- API 키를 입력하면 해당 기능을 사용할 수 있도록 구현한다.
- 구현 프로세스
- API 키 입력 화면 구현
- 입력된 API 키를 활용한 기능 구현
- 웹앱 레이아웃 구성
- 사용자 친화적인 인터페이스 제공
- PDF논문 요약 기능 구현
- 논문 PDF 파일 업로드
- 논문 요약 기능 구현
- 요약 결과 표시 (각 챕터별)
- 웹앱 레이아웃 구성
- 사용자 친화적인 인터페이스 제공
- 논문 요약 기능 구현
- 요약 결과 표시
- 먼저 테스트성으로 jupyter notebook으로 구현
- jupyter notebook에서는 .env 파일에 있는 API 키를 불러오는 형태로 구현한다.
- 논문은 files 폴더에 있는 논문 1개를 사용한다.
참고 논문
- 참고 논문은 정부 훈련비 지원 수준이 직업능력개발훈련 성과에 미치는 영향 분석이다.
jupyter notebook 테스트
- 코드는 아래와 같다.
# 필요한 라이브러리 임포트
import os
from langchain.chat_models import ChatOpenAI # OpenAI의 ChatGPT 모델을 사용하기 위한 클래스
from langchain_core.prompts import ChatPromptTemplate # 채팅 프롬프트 템플릿 생성을 위한 클래스
from langchain_core.output_parsers import StrOutputParser # 출력을 문자열로 파싱하기 위한 클래스
from langchain_community.document_loaders import PyPDFLoader # PDF 파일을 로드하기 위한 클래스
from langchain.text_splitter import RecursiveCharacterTextSplitter # 텍스트를 청크로 분할하기 위한 클래스
from docx import Document # Word 문서 생성을 위한 클래스
from dotenv import load_dotenv # 환경 변수 로드를 위한 모듈
from datetime import datetime # 날짜/시간 처리를 위한 클래스
# .env 파일에서 환경 변수 로드
load_dotenv()
# 환경 변수에서 OpenAI API 키 가져오기
openai_api_key = os.getenv("OPENAI_API_KEY")
# API 키가 존재하는지 확인
if not openai_api_key:
raise ValueError("OPENAI_API_KEY 환경 변수를 찾을 수 없습니다. .env 파일을 확인해주세요.")
# files 디렉토리에서 PDF 파일 찾기
pdf_files = [f for f in os.listdir("files") if f.endswith('.pdf')]
if not pdf_files:
raise ValueError("files 디렉토리에서 PDF 파일을 찾을 수 없습니다")
# 첫 번째 PDF 파일의 전체 경로 생성
pdf_path = os.path.join(os.getcwd(), "files", pdf_files[0])
# PDF 파일 로드 및 페이지 분할
loader = PyPDFLoader(pdf_path)
pages = loader.load_and_split()
# 텍스트 분할기 설정 - 큰 청크 사이즈로 설정하여 컨텍스트 유지
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=4000, # 각 청크의 최대 문자 수
chunk_overlap=400, # 청크 간 중복되는 문자 수
length_function=len
)
# 페이지들을 청크로 분할
texts = text_splitter.split_documents(pages)
# 텍스트를 전반부와 후반부 두 개의 파트로 병합
if len(texts) > 2:
# 전반부 텍스트 병합
first_half = " ".join([t.page_content for t in texts[:len(texts)//2]])
# 후반부 텍스트 병합
second_half = " ".join([t.page_content for t in texts[len(texts)//2:]])
texts = [
{"content": first_half, "part": "전반부"},
{"content": second_half, "part": "후반부"}
]
# LangChain의 ChatOpenAI 모델 설정
llm = ChatOpenAI(
openai_api_key=openai_api_key,
model="gpt-3.5-turbo", # GPT-3.5 모델 사용
temperature=0.1, # 낮은 temperature로 일관된 출력 생성
max_tokens=1000 # 충분한 길이의 요약을 위한 토큰 수 설정
)
# 요약을 위한 프롬프트 템플릿 설정
prompt = ChatPromptTemplate.from_messages([
("system", "당신은 전문 학술 연구원입니다. 다음 학술 논문 파트를 주요 포인트와 핵심 발견사항을 중심으로 한글로 포괄적이고 상세하게 요약해주세요."),
("user", "다음 텍스트를 한글로 요약해주세요. 이 텍스트는 논문의 {part}입니다:\n\n{text}\n\n반드시 한글로 요약해주시고, 영어 전문용어가 있다면 한글 설명을 덧붙여주세요.")
])
# 프롬프트, LLM, 출력 파서를 연결하는 체인 생성
chain = prompt | llm | StrOutputParser()
# Word 문서 객체 생성
doc = Document()
doc.add_heading('논문 요약', 0)
# 현재 시간을 파일명에 포함시키기 위한 형식 지정
current_time = datetime.now().strftime("%Y%m%d_%H%M%S")
# 각 파트별로 요약 실행 및 Word 문서에 추가
for i, text in enumerate(texts):
print(f"파트 {i+1}/2 요약 중...")
# 체인을 실행하여 요약 생성
summary = chain.invoke({"text": text["content"], "part": text["part"]})
# Word 문서에 요약 내용 추가
doc.add_heading(f'{text["part"]} 요약', level=1)
doc.add_paragraph(summary)
doc.add_paragraph('-' * 40) # 구분선 추가
# 콘솔에 요약 출력
print(f"\n{text['part']} 요약:")
print(summary)
print("-" * 80)
# 생성된 Word 문서를 저장
output_path = f"논문_요약_{current_time}.docx"
doc.save(output_path)
print(f"\n한글 요약본이 {output_path}에 저장되었습니다")
- 위 코드를 실제 실행하면 다음과 같은 결과가 나온다.
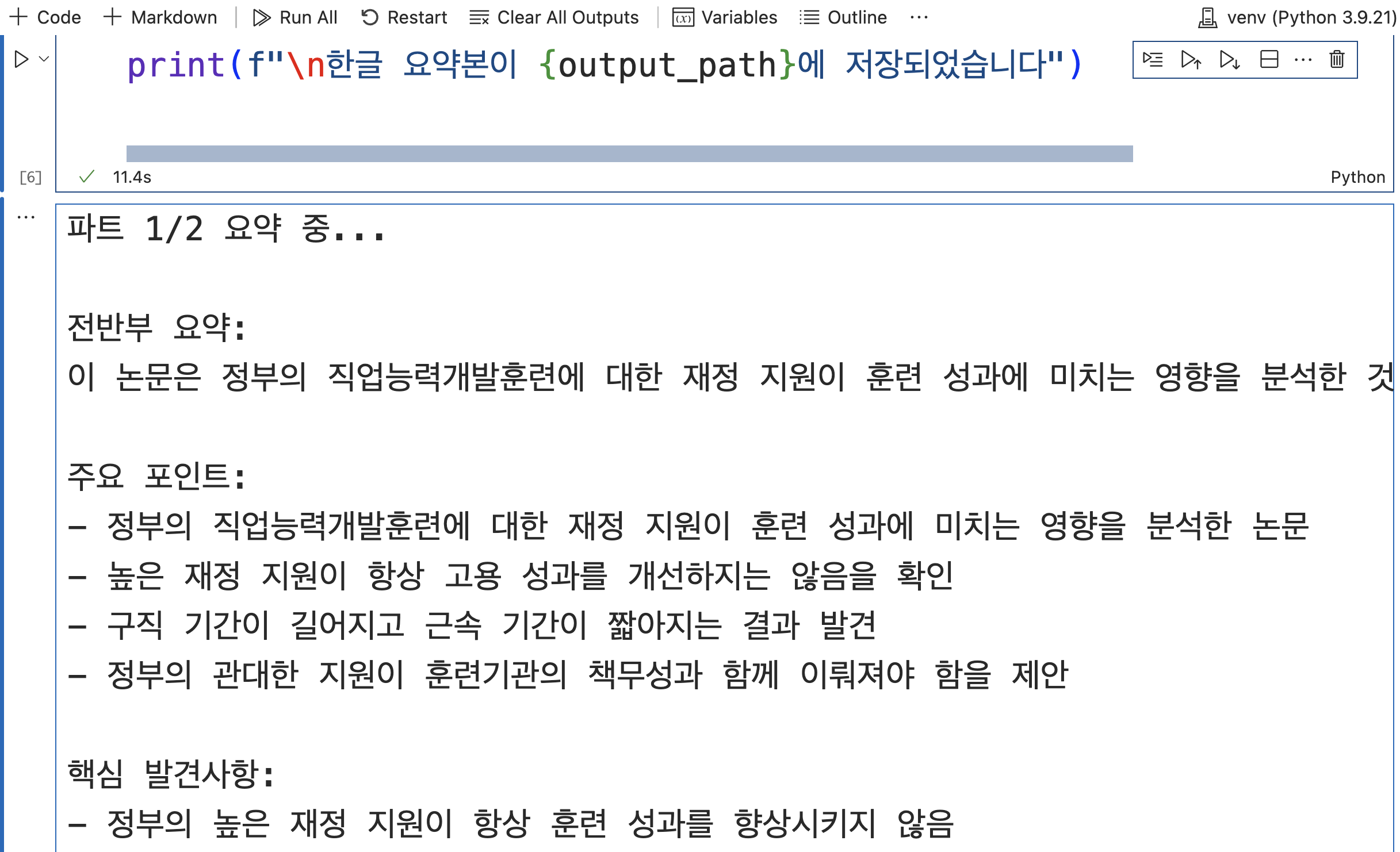
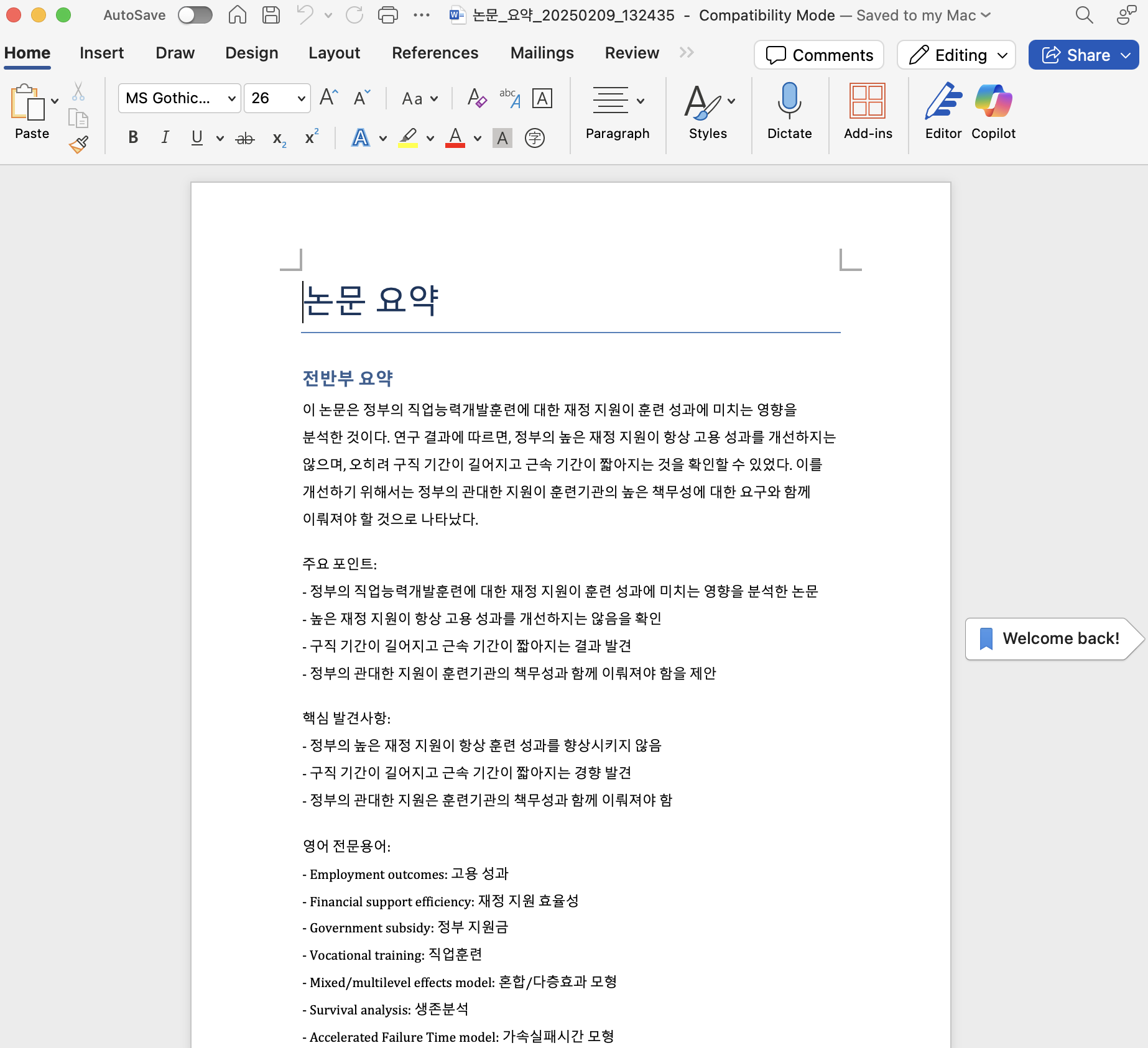
- 위 결과 내용은 워드에서 동일하게 나오는 것을 확인 할 수 있다.
Streamlit App
수행결과 화면
- 앱 실행 결과 화면은 아래와 같다.

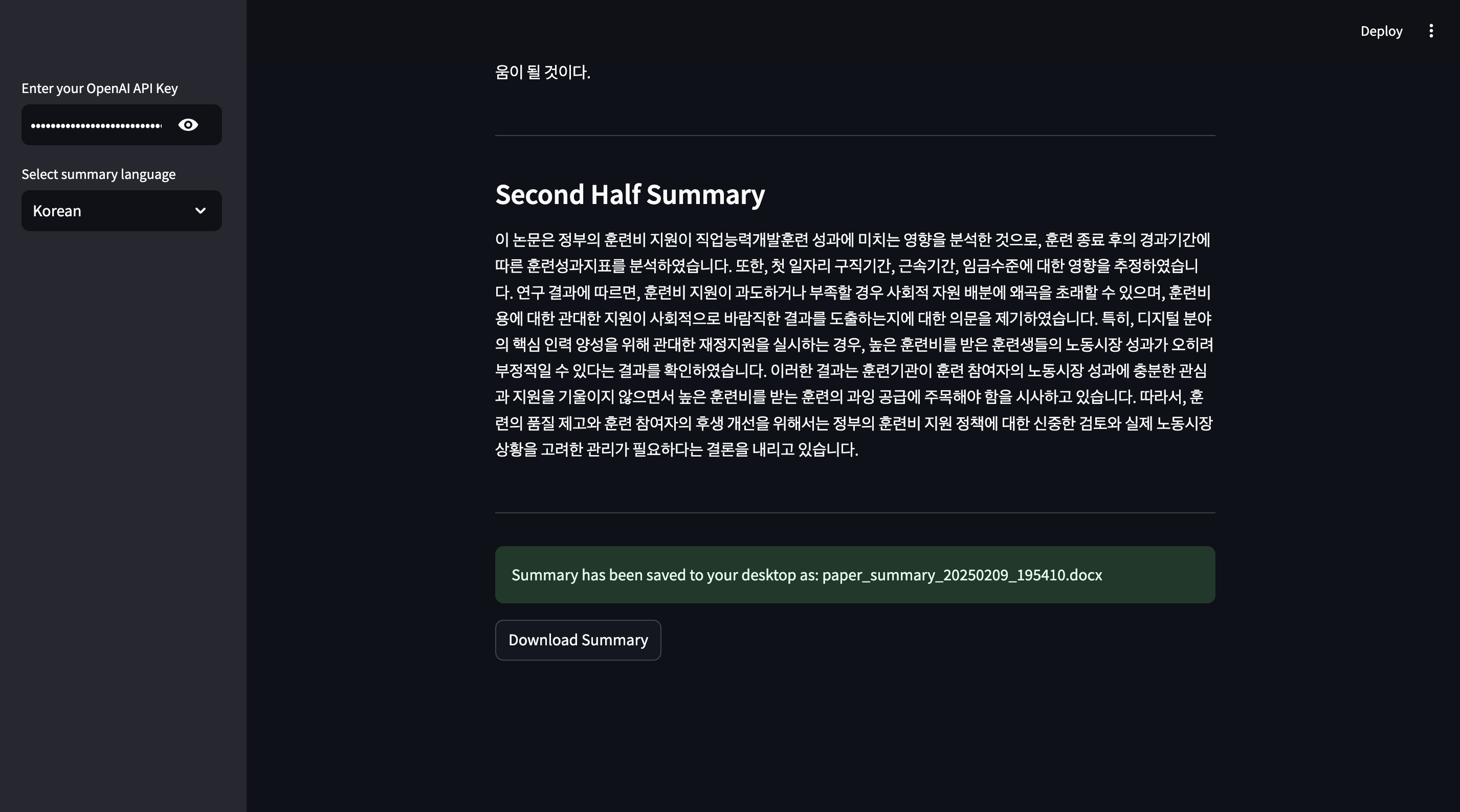
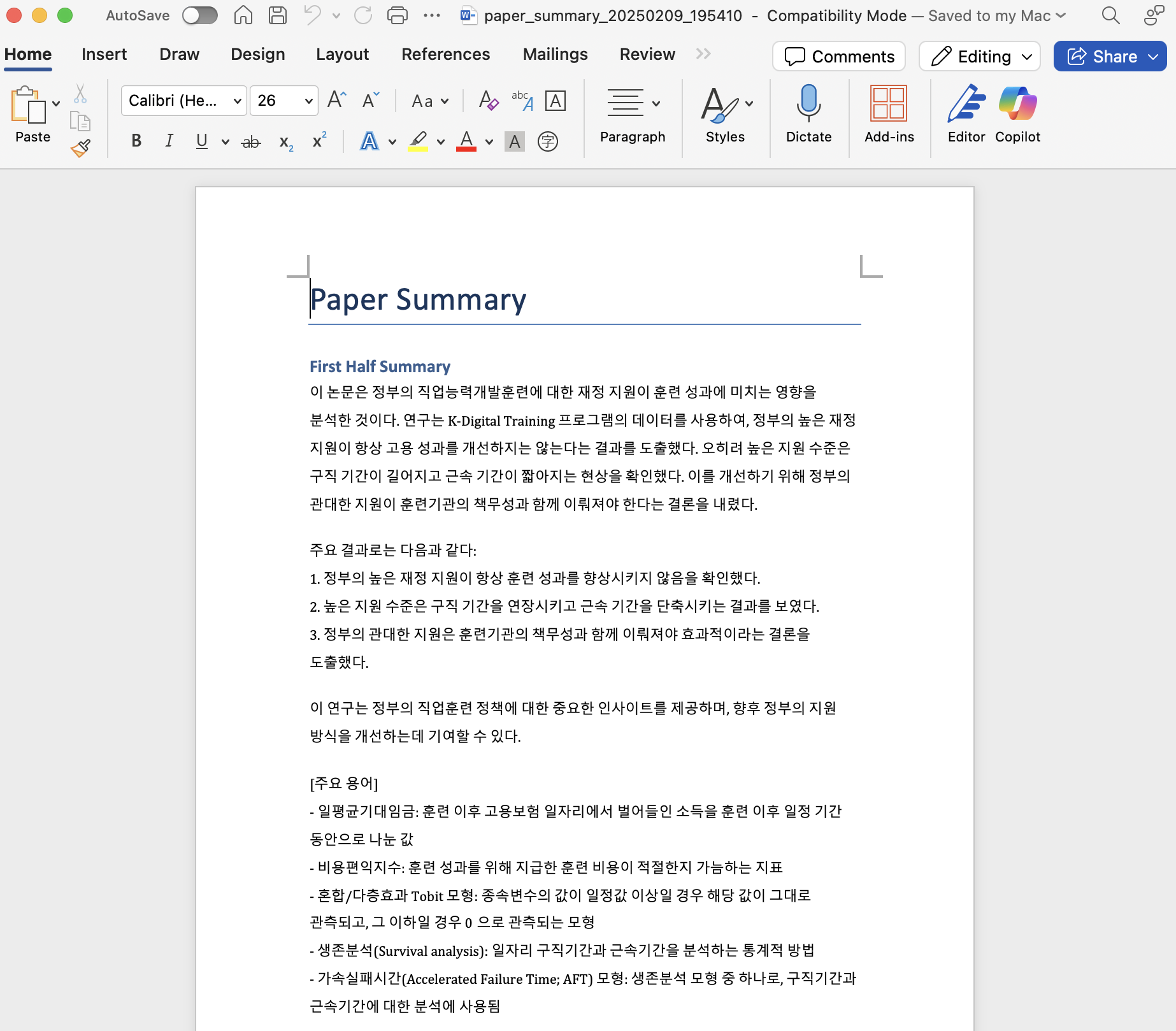
- Download Summary 버튼을 클릭하면 워드 파일을 확인할 수 있다.
실습코드
- 실습 코드는 아래와 같다.
import streamlit as st
import os
from langchain.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from docx import Document
from datetime import datetime
from pathlib import Path
def create_summary_chain(api_key, language="ko"):
"""LangChain 요약 체인을 생성하는 함수
Args:
api_key (str): OpenAI API 키
language (str): 요약 언어 선택 ('ko' 또는 'en')
Returns:
chain: 프롬프트, LLM, 출력 파서가 연결된 LangChain 체인
"""
llm = ChatOpenAI(
openai_api_key=api_key,
model="gpt-3.5-turbo", # GPT-3.5 모델 사용
temperature=0.1, # 낮은 temperature로 일관된 출력 생성
max_tokens=1000 # 최대 토큰 수 제한
)
# 언어에 따른 프롬프트 설정
if language == "ko":
system_message = "당신은 전문 학술 연구원입니다. 다음 학술 논문 파트를 주요 포인트와 핵심 발견사항을 중심으로 한글로 포괄적이고 상세하게 요약해주세요."
user_message = "다음 텍스트를 한글로 요약해주세요. 이 텍스트는 논문의 {part}입니다:\n\n{text}\n\n반드시 한글로 요약해주시고, 영어 전문용어가 있다면 한글 설명을 덧붙여주세요."
else:
system_message = "You are a professional academic researcher. Please provide a comprehensive and detailed summary of the following academic paper part, focusing on key points and findings."
user_message = "Please summarize the following text in English. This is the {part} of the paper:\n\n{text}\n\nPlease provide the summary in English, including explanations of technical terms."
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
("user", user_message)
])
return prompt | llm | StrOutputParser()
def process_pdf(pdf_file, api_key, language):
"""PDF 파일을 처리하고 요약하는 함수
Args:
pdf_file: Streamlit 파일 업로더로 받은 PDF 파일
api_key (str): OpenAI API 키
language (str): 요약 언어 선택
Returns:
tuple: (생성된 파일명, 파일 경로)
"""
# 임시 파일로 PDF 저장
temp_pdf_path = "temp_pdf_file.pdf"
with open(temp_pdf_path, 'wb') as f:
f.write(pdf_file.getvalue())
try:
# PDF 로드 및 페이지 분할
loader = PyPDFLoader(temp_pdf_path)
pages = loader.load_and_split()
# 텍스트 분할 설정
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=4000, # 각 청크의 최대 문자 수
chunk_overlap=400, # 청크 간 중복되는 문자 수
length_function=len # 길이 측정 함수
)
texts = text_splitter.split_documents(pages)
# 텍스트를 전반부와 후반부로 나누기
first_half = " ".join([t.page_content for t in texts[:len(texts)//2]])
second_half = " ".join([t.page_content for t in texts[len(texts)//2:]])
texts = [
{"content": first_half, "part": "First Half"},
{"content": second_half, "part": "Second Half"}
]
# 요약 체인 생성
chain = create_summary_chain(api_key, language)
# Word 문서 생성 및 제목 추가
doc = Document()
doc.add_heading('Paper Summary', 0)
summaries = []
for i, text in enumerate(texts, 1):
with st.spinner(f'Processing part {i}/2...'):
# 각 부분 요약 생성
summary = chain.invoke({"text": text["content"], "part": text["part"]})
summaries.append(summary)
# Word 문서에 요약 내용 추가
doc.add_heading(f'{text["part"]} Summary', level=1)
doc.add_paragraph(summary)
doc.add_paragraph('-' * 40) # 구분선 추가
# Streamlit 웹 페이지에 요약 표시
st.subheader(f'{text["part"]} Summary')
st.write(summary)
st.markdown("---")
# 현재 시간을 포함한 파일명 생성
current_time = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"paper_summary_{current_time}.docx"
# 사용자의 바탕화면 경로 가져오기
desktop = str(Path.home() / "Desktop")
filepath = os.path.join(desktop, filename)
# Word 문서 저장
doc.save(filepath)
return filename, filepath
finally:
# 임시 PDF 파일 정리
if os.path.exists(temp_pdf_path):
os.remove(temp_pdf_path)
def main():
"""메인 애플리케이션 함수"""
st.title("PDF Paper Summarizer")
# 사이드바에 OpenAI API 키 입력 필드 추가
api_key = st.sidebar.text_input("Enter your OpenAI API Key", type="password")
# 요약 언어 선택 옵션
language = st.sidebar.selectbox(
"Select summary language",
["ko", "en"],
format_func=lambda x: "Korean" if x == "ko" else "English"
)
# PDF 파일 업로드 위젯
uploaded_file = st.file_uploader("Upload your PDF paper", type="pdf")
if uploaded_file and api_key:
if st.button("Generate Summary"):
try:
# PDF 처리 및 요약 생성
filename, filepath = process_pdf(uploaded_file, api_key, language)
st.success(f"Summary has been saved to your desktop as: {filename}")
# Word 문서 다운로드 버튼 생성
with open(filepath, "rb") as file:
st.download_button(
label="Download Summary",
data=file,
file_name=filename,
mime="application/vnd.openxmlformats-officedocument.wordprocessingml.document"
)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
elif not api_key:
st.warning("Please enter your OpenAI API key in the sidebar.")
elif not uploaded_file:
st.info("Please upload a PDF file to begin.")
if __name__ == "__main__":
main()
