Streamlit ML Model Prediction Sample (feat. Pipeline)
Page content
강의소개
- 인프런에서 Streamlit 관련 강의를 진행하고 있습니다.
- 인프런 : https://inf.run/YPniH
개요
- tips 데이터셋을 활용하여 Streamlit ML Model을 배포한다.
- 각 코드에 대한 자세한 설명은 여기에서는 생략한다.
모델 개발
- 다음 코드는 모델을 개발하는 코드이다.
- 주어진 데이터셋에서 tip을 예측하는 모델을 구성했다.
- 파일명 :
model.py
- 파일명 :
import streamlit as st
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
from joblib import dump, load
import os
# 데이터셋 불러오기
tips = sns.load_dataset('tips')
# 데이터셋 컬럼 추출
categorical_features = ['sex', 'smoker', 'day', 'time']
numerical_features = ['total_bill', 'size']
# pipeline 모델 만들기
preprocessor = ColumnTransformer(
transformers=[
('num', 'passthrough', numerical_features),
('cat', OneHotEncoder(), categorical_features)
])
pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('model', LinearRegression())])
# 데이터셋 분류 / 종속 변수 tip을 예측하는 모델
X = tips.drop('tip', axis=1)
y = tips['tip']
# 데이터셋 분류
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 학습
pipeline.fit(X_train, y_train)
# 모델 저장
model_directory = 'model'
if not os.path.exists(model_directory):
os.makedirs(model_directory)
model_path = os.path.join(model_directory, 'tip_prediction_pipeline.joblib')
dump(pipeline, model_path)
- 위 코드에서 핵심은 모델을 저장하는 것이다. 마지막 코드이다.
- 해당하는 폴더에
model폴더가 없으면model폴더를 생성하고tip_prediction_pipeline.joblib이름으로 모델을 저장한다. - model.py를 실행한다.
python model.py
- 정상적으로 모델이 만들어졌으면, model 폴더가 생겼을 것이고, 그 다음에 해당 모델이 저장되어 있을 것이다.
Streamlit App 개발
- 다음 코드는 Streamlit App 개발을 하는 코드이다.
- 파일명 :
app.py
- 파일명 :
import streamlit as st
import pandas as pd
from joblib import load
import os
model_directory = 'model'
model_path = os.path.join(model_directory, 'tip_prediction_pipeline.joblib')
def predict_tip(model_path, total_bill, size, sex, smoker, day, time):
# 모델 불러오기
pipeline = load(model_path)
# 예측 데이터 생성
df = pd.DataFrame([{'total_bill': total_bill, 'size': size, 'sex': sex, 'smoker': smoker, 'day': day, 'time': time}])
# 예측값 생성
prediction = pipeline.predict(df)
return prediction[0]
def main():
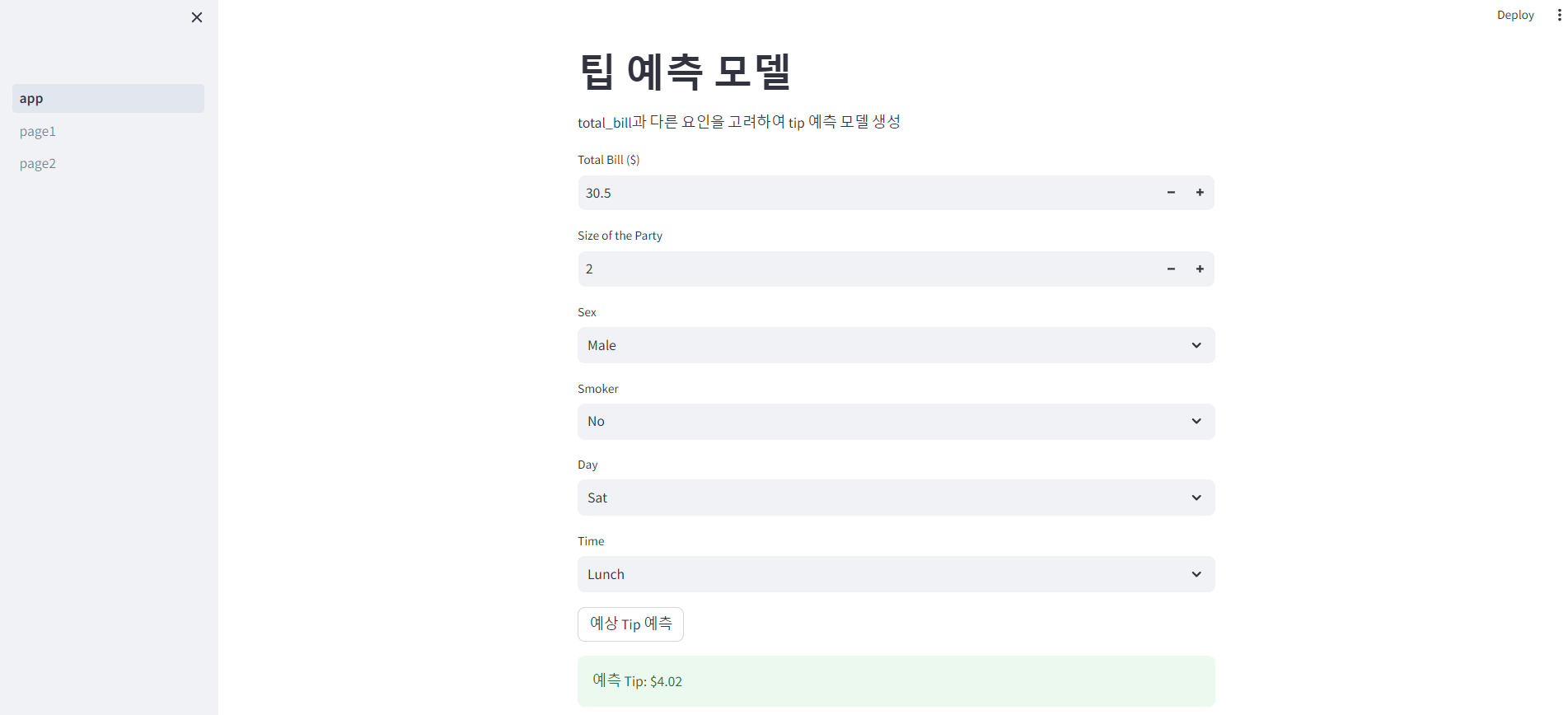
st.title('팁 예측 모델')
st.write('total_bill과 다른 요인을 고려하여 tip 예측 모델 생성')
total_bill = st.number_input('Total Bill ($)', min_value=0.0, format='%f')
size = st.number_input('Size of the Party', min_value=1, step=1)
sex = st.selectbox('Sex', ['Male', 'Female'])
smoker = st.selectbox('Smoker', ['Yes', 'No'])
day = st.selectbox('Day', ['Thur', 'Fri', 'Sat', 'Sun'])
time = st.selectbox('Time', ['Lunch', 'Dinner'])
if st.button('예상 Tip 예측'):
result = predict_tip(model_path, total_bill, size, sex, smoker, day, time)
st.success(f'예측 Tip: ${result:.2f}')
if __name__ == "__main__":
main()
- 위 코드에서 핵심은
predict_tip함수이다.pipeline으로 모델을 설계하면 곧바로predict()저장된 모델을 불러온 후, 함수 사용이 가능하다.
테스트
- 테스트 결과는 아래와 같이 나온다.
streamlit run app.py