Streamlit ML Multiclass Classification Model Prediction Sample (feat. Pipeline)
Page content
개요
- Kaggle 데이터셋을 활용하여 Streamlit ML Multiclass Classification Model을 배포한다.
- 각 코드에 대한 자세한 설명은 여기에서는 생략한다.
데이터 수집
- 이번에 활용하는 캐글 데이터 수집은 아래 대회에서 train 데이터만 가져왔다.
- Multi-Class Prediction of Obesity Risk : https://www.kaggle.com/competitions/playground-series-s4e2
- Dataset Description은 아래에서 확인하도록 한다.
- 링크 : https://www.kaggle.com/competitions/playground-series-s4e2/data
- train.csv 파일만 다운로드 받았다.
모델 개발
- 다음 코드는 모델을 개발하는 코드이다.
- 주어진 데이터셋에서 종속변수
NObeyesdad을 예측하는 모델을 구성했다.- 파일명 :
model.py
- 파일명 :
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report
from joblib import dump, load
import os
DATA_PATH = './data/train.csv'
data = pd.read_csv(DATA_PATH)
# Separate features and target variable
X = data.drop(['id', 'NObeyesdad'], axis=1)
y = data['NObeyesdad']
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Identify numerical and categorical columns
num_columns = X.select_dtypes(include=['float64']).columns
cat_columns = X.select_dtypes(include=['object']).columns
# Create the preprocessing pipeline
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), num_columns),
('cat', OneHotEncoder(handle_unknown='ignore'), cat_columns)
]
)
# Create the full pipeline
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', RandomForestClassifier())
])
# Train the model
pipeline.fit(X_train, y_train)
# 모델 저장
model_directory = 'model'
if not os.path.exists(model_directory):
os.makedirs(model_directory)
model_path = os.path.join(model_directory, 'NObeyesdad_prediction_pipeline.joblib')
dump(pipeline, model_path)
- 위 코드에서 핵심은 모델을 저장하는 것이며, 또한
OneHotEncoder(handle_unknown='ignore')을 지정하는 것이다. - 해당하는 폴더에
model폴더가 없으면model폴더를 생성하고NObeyesdad_prediction_pipeline.joblib이름으로 모델을 저장한다.
파일 실행
model.py를 실행하여 모델을 생성한다.
python model.py
Streamlit App 개발
- 다음 코드는 Streamlit App 개발을 하는 코드이다.
- 파일명 :
app.py
- 파일명 :
import streamlit as st
import pandas as pd
from joblib import load
import os
# Assuming your model is saved in the 'model' directory with the name 'obesity_prediction_pipeline.joblib'
model_directory = 'model'
model_path = os.path.join(model_directory, 'NObeyesdad_prediction_pipeline.joblib')
def predict_NObeyesdad_level(model_path, Gender, Age, Height, Weight, family_history_with_overweight, FAVC, FCVC, NCP, CAEC, SMOKE, CH2O, SCC, FAF, TUE, CALC, MTRANS):
# 모델 불러오기
pipeline = load(model_path)
# 데이터프레임 생성
df = pd.DataFrame([{
'Gender': Gender, 'Age': Age, 'Height': Height, 'Weight': Weight,
'family_history_with_overweight': family_history_with_overweight, 'FAVC': FAVC,
'FCVC': FCVC, 'NCP': NCP, 'CAEC': CAEC, 'SMOKE': SMOKE, 'CH2O': CH2O,
'SCC': SCC, 'FAF': FAF, 'TUE': TUE, 'CALC': CALC, 'MTRANS': MTRANS
}])
# 예측 값 생성
prediction = pipeline.predict(df)
return prediction[0]
def main():
st.title('Obesity Level Prediction Model')
st.write('Predict obesity levels based on personal and health-related attributes.')
# Create input fields for each feature
Gender = st.selectbox('Gender', ['Male', 'Female'])
Age = st.number_input('Age', min_value=0.0, format='%f')
Height = st.number_input('Height (in meters)', min_value=0.0, format='%f')
Weight = st.number_input('Weight (in kg)', min_value=0.0, format='%f')
family_history_with_overweight = st.selectbox('Family history with overweight', ['yes', 'no'])
FAVC = st.selectbox('Frequent consumption of high caloric food', ['yes', 'no'])
FCVC = st.number_input('Frequency of consumption of vegetables', min_value=0.0, max_value=3.0, step=0.1)
NCP = st.number_input('Number of main meals', min_value=1.0, max_value=4.0, step=0.1)
CAEC = st.selectbox('Consumption of food between meals', ['No', 'Sometimes', 'Frequently', 'Always'])
SMOKE = st.selectbox('Do you smoke?', ['yes', 'no'])
CH2O = st.number_input('Consumption of water daily (liters)', min_value=0.0, format='%f')
SCC = st.selectbox('Calories consumption monitoring', ['yes', 'no'])
FAF = st.number_input('Physical activity frequency (per week)', min_value=0.0, format='%f')
TUE = st.number_input('Time using technology devices (hours)', min_value=0.0, format='%f')
CALC = st.selectbox('Consumption of alcohol', ['Never', 'Sometimes', 'Frequently', 'Always'])
MTRANS = st.selectbox('Mode of transportation', ['Automobile', 'Bike', 'Motorbike', 'Public_Transportation', 'Walking'])
if st.button('Predict Obesity Level'):
result = predict_NObeyesdad_level(model_path, Gender, Age, Height, Weight, family_history_with_overweight, FAVC, FCVC, NCP, CAEC, SMOKE, CH2O, SCC, FAF, TUE, CALC, MTRANS)
st.success(f'Predicted Obesity Level: {result}')
if __name__ == "__main__":
main()
- 위 코드에서 핵심은
predict_tip함수이다.pipeline으로 모델을 설계하면 곧바로predict()저장된 모델을 불러온 후, 함수 사용이 가능하다.
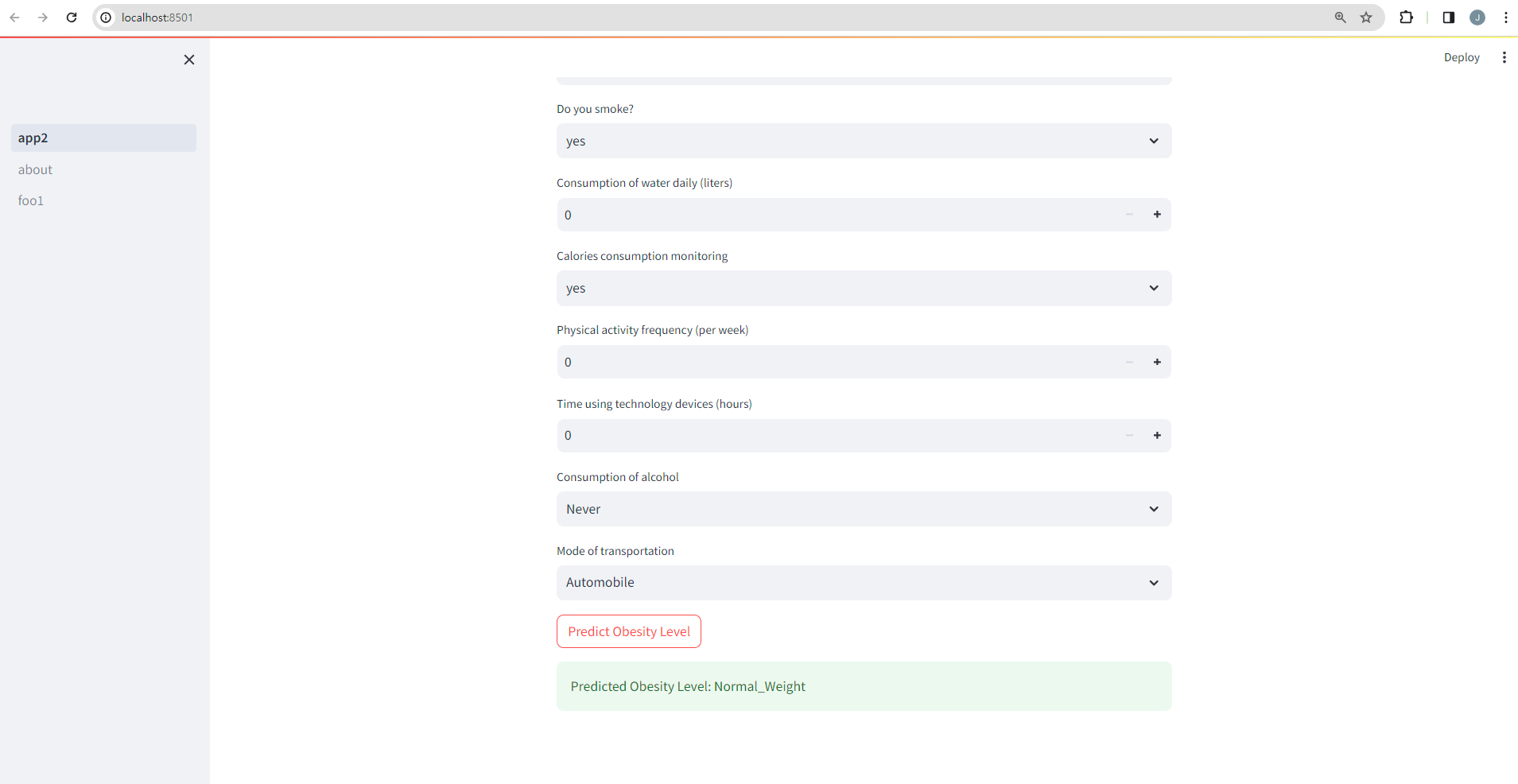
테스트
- 테스트 결과는 아래와 같이 나온다.
streamlit run app.py