statsmodels를 활용한 회귀분석 (feat. 범주형 데이터)
Page content
개요
- statsmodels를 활용하여 범주형 데이터가 포함된 회귀식을 산정해본다.
- 범주형 데이터의 특정 값을 변동하는 방법을 배운다.
- 더불어서 R로 간단한 회귀식도 만들어보자!
강의소개
- 인프런에서 Streamlit 관련 강의를 진행하고 있습니다.
- 인프런 : https://inf.run/YPniH
라이브러리 확인
- statsmodels의 라이브러리는 현재 0.14.1 버전이다.
import statsmodels
import seaborn as sns
import pandas as pd
print(statsmodels.__version__)
print(sns.__version__)
print(pd.__version__)
0.14.1
0.12.2
1.5.3
데이터 불러오기
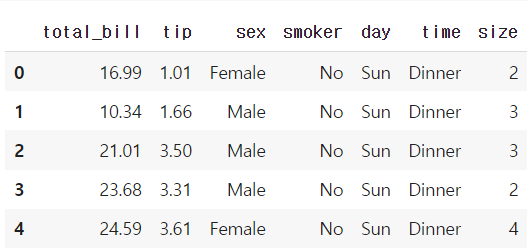
- seaborn에서 tips 데이터를 불러온다.
tips = sns.load_dataset('tips')
tips.head()
회귀모형 적합 및 확인 (첫번째 방식)
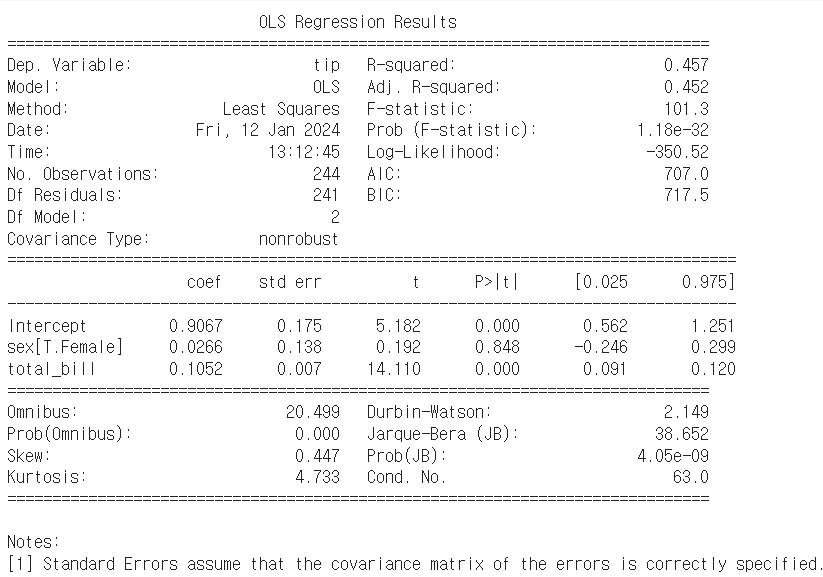
- 이제 회귀모형을 적합해본다.
+ 종속변수 : tip
+ 독립변수는 tips을 제외한 모든 변수 (범주형 데이터 포함)
- 그런데, 일부 값들이 출력이 되지를 않는다. (이유)
+ statsmodels에서는 기본값으로 하나를 무조건 제외하게 설계되었고, 알파벳 상으로 마지막 글자가 생략이 된다.
+ 따라서 sex에서는 Male, day에서는 Thur, time에서는 lunch가 생략된다.
import statsmodels.formula.api as smf
formula = "tip ~ total_bill + sex"
model = smf.ols(formula, data = tips).fit()
print(model.summary())
범주형 데이터 해석
- 범주형 변수 해석은 다음과 같다. (예시 : sex[T.Male])
+ sex[T.Male]이 양수인 경우: 모델에서 다른 요인들을 통제한 상태에서 남성이 여성보다 팁을 더 많이 준다는 것을 나타낸다.
+ sex[T.Male]이 음수인 경우: 모델에서 다른 요인들을 통제한 상태에서 남성이 여성보다 팁을 덜 주는 경향이 있다는 것을 나타낸다.
+ sex[T.Male]이 통계적으로 유의하지 않은 경우 (높은 p-value): 모델에서 다른 요인들을 통제한 상태에서 남성과 여성 간의 팁 금액에 대한 통계적인 차이가 없다는 것을 나타낸다.
회귀모형 적합 및 확인 (두번째 방식)
- 만약 모든 변수를 다 보고 싶다면 어떻게 해야할까?
- 그럴경우 약간의 데이터 가공을 진행해야 한다.
+ One-Hot Encoding을 진행해본다.
- 우선 tips2 데이터를 생성 후, One-Hot Encoding을 진행해본다.
tips2 = tips.loc[:, ['tip', 'total_bill', 'sex']].copy()
data_with_dummies = pd.get_dummies(tips2, drop_first=False)
data_with_dummies.head()
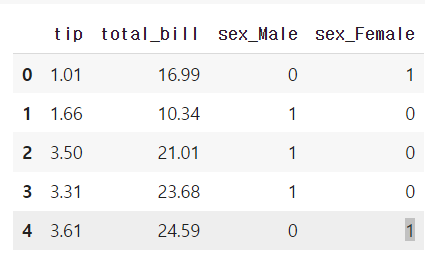
- 데이터가 변경된 것을 확인한다.
+ 위 상태에서 다시 모형을 적합한다.
model = smf.ols('tip ~ total_bill + sex_Female + sex_Male', data=data_with_dummies).fit()
print(model.summary())
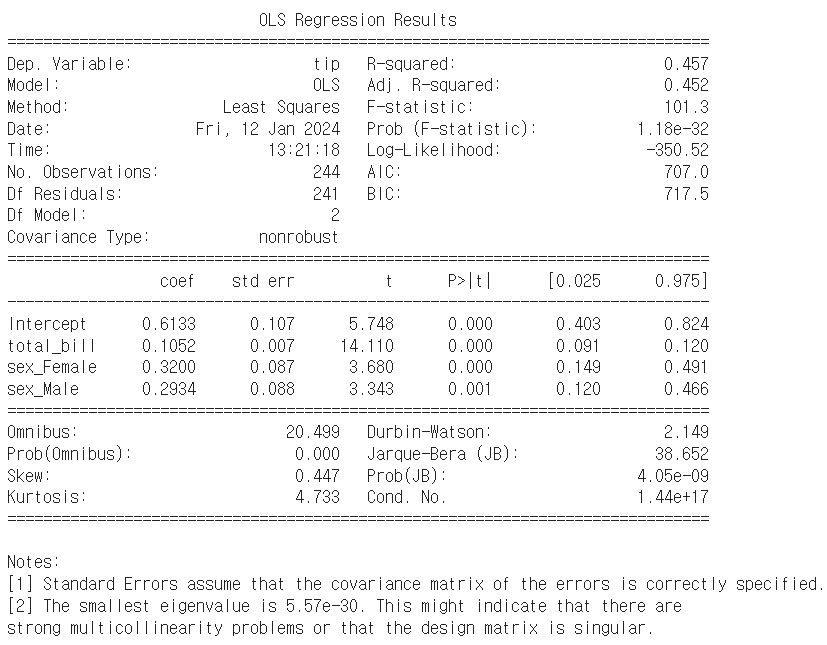
- 이번에는 sex_Male과 sex_Female의 회귀계수가 통계적으로 유의하게 나온것을 확인할 수 있다.
- 그런데 이상하다. 첫번째 방식과 두번째 방식의 해석이 달라지기 때문이다.
뭐가 정답일까?
- 첫번째 방식으로 하는 것이 `옳은 방법`이다.
- 두번째 방식으로 진행하면 변수가 하나 더 생겼다는 뜻이기 때문에 이러한 방식으로 진행하면 결괏값 자체가 아예 이상해진다. 두번째 방식의 코드를 다시 수정해본다.
tips2 = tips.loc[:, ['tip', 'total_bill', 'sex']].copy()
data_with_dummies = pd.get_dummies(tips2, drop_first=True) # False에서 True로 변경
data_with_dummies.head()
- sex_Male 변수를 추가하지 않으면 이제 첫번째 방식의 값과 동일하게 나온 것을 확인할 수 있다.
- 음..? 그럼 굳이 원핫인코딩을 하는 코딩이 좋은 건가? statsmodels 에서 직접 성별을 바꿔서 표현하는 방법은 없는건가?
만약 성별을 바꾸고 싶다면
-
그럼 다음과 같이 코드를 변경해주면 된다.
-
Male을 표현하고자 한다면?
import statsmodels.formula.api as smf
formula = "tip ~ total_bill + C(sex, Treatment(reference='Female'))"
model = smf.ols(formula, data = tips).fit()
print(model.summary())
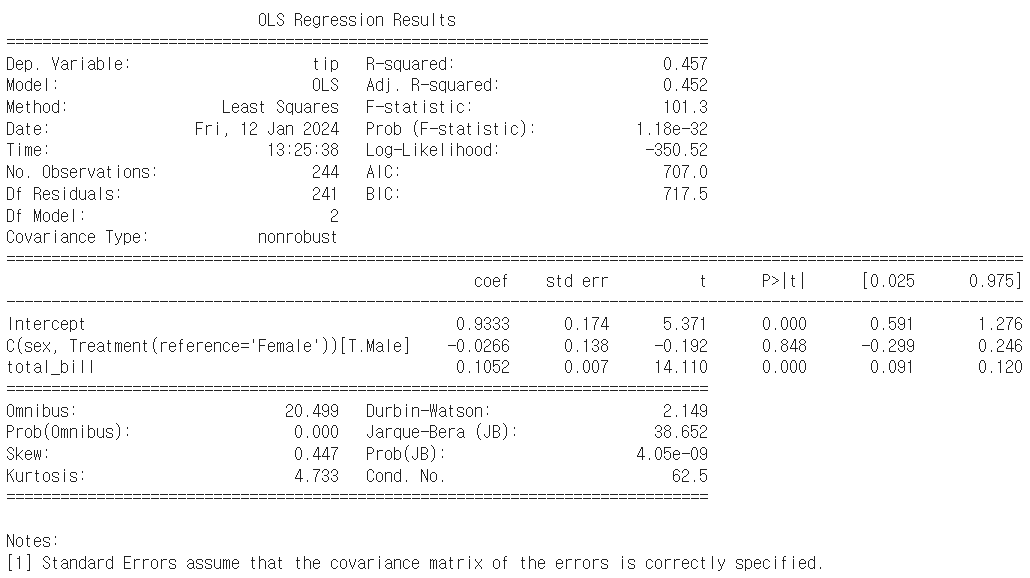
- Female을 표현하고자 한다면?
import statsmodels.formula.api as smf
formula = "tip ~ total_bill + C(sex, Treatment(reference='Male'))"
model = smf.ols(formula, data = tips).fit()
print(model.summary())
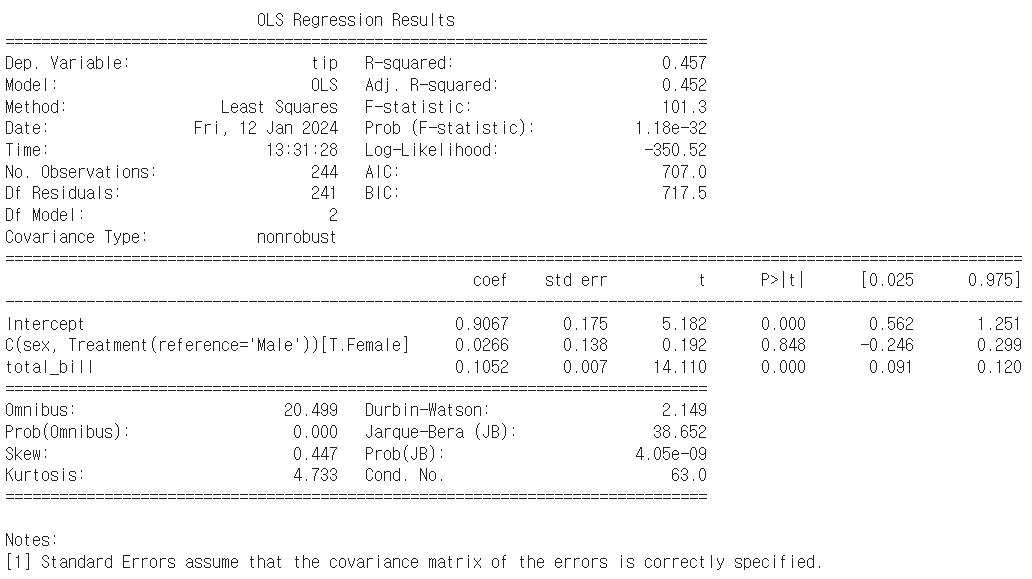
- 그럼 이제 성별이 변경되었지만, 결괏값은 원하던대로 정확히 정반대의 결과가 나오도록 설계된 것을 확인할 수 있다.
(보너스)
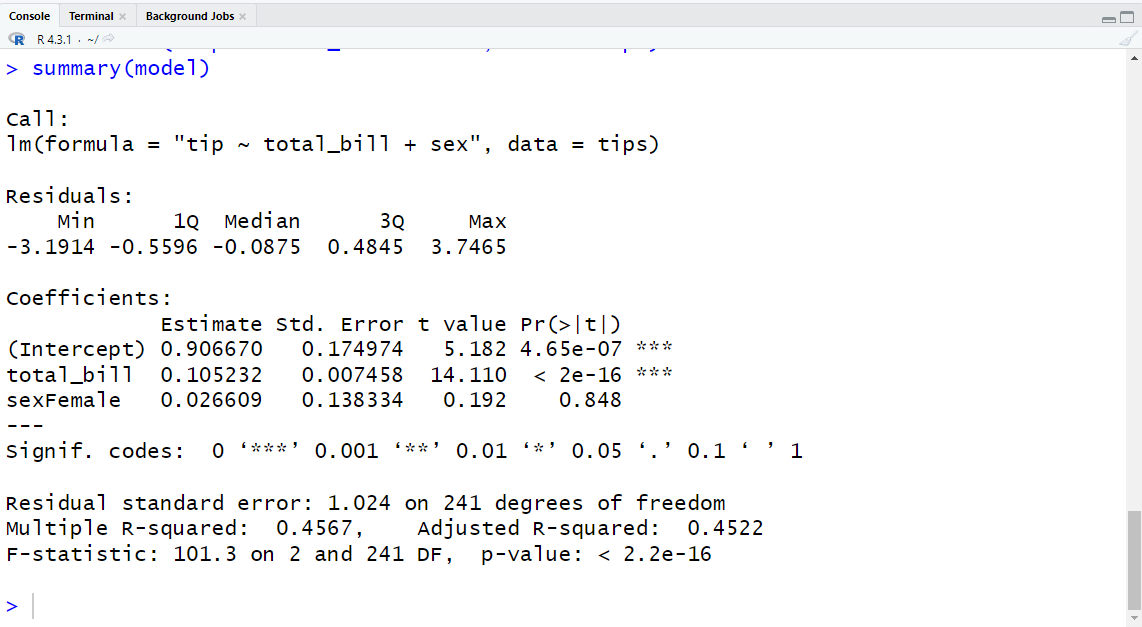
- 혹시나 싶어서 R에서도 돌려보았다.
- 결과는 놀랍게도 동일하다!!
library(dplyr)
data("tips", package = "reshape2")
tips = tips %>%
mutate(sex = relevel(sex, ref = "Male")) # 여성으로 보여주고 싶을 때
model = lm("tip ~ total_bill + sex", data = tips)
summary(model)