Scrapy Tutorial - 기본편
Page content
개요
- Scrapy Tutorial 설치 과정 및 기본 크롤링 과정을 살펴본다.
라이브러리 설치
- 라이브러리 설치는 다음과 같다.
pip install scrapy
프로젝트 시작
- Django와 비슷하게 터미널 명령어는 startproject라고 입력한다.
$ scrapy startproject multiCam_tutorial
New Scrapy project 'multiCam_tutorial', using template directory 'C:\Users\j2hoo\OneDrive\Desktop\your_project_folder\venv\Lib\site-packages\scrapy\templates\project', created in:
C:\Users\j2hoo\OneDrive\Desktop\your_path\multiCam_tutorial
You can start your first spider with:
cd multiCam_tutorial
scrapy genspider example example.com
- 파일 구조는 아래와 같이 여러개의 파일로 구성되었다.

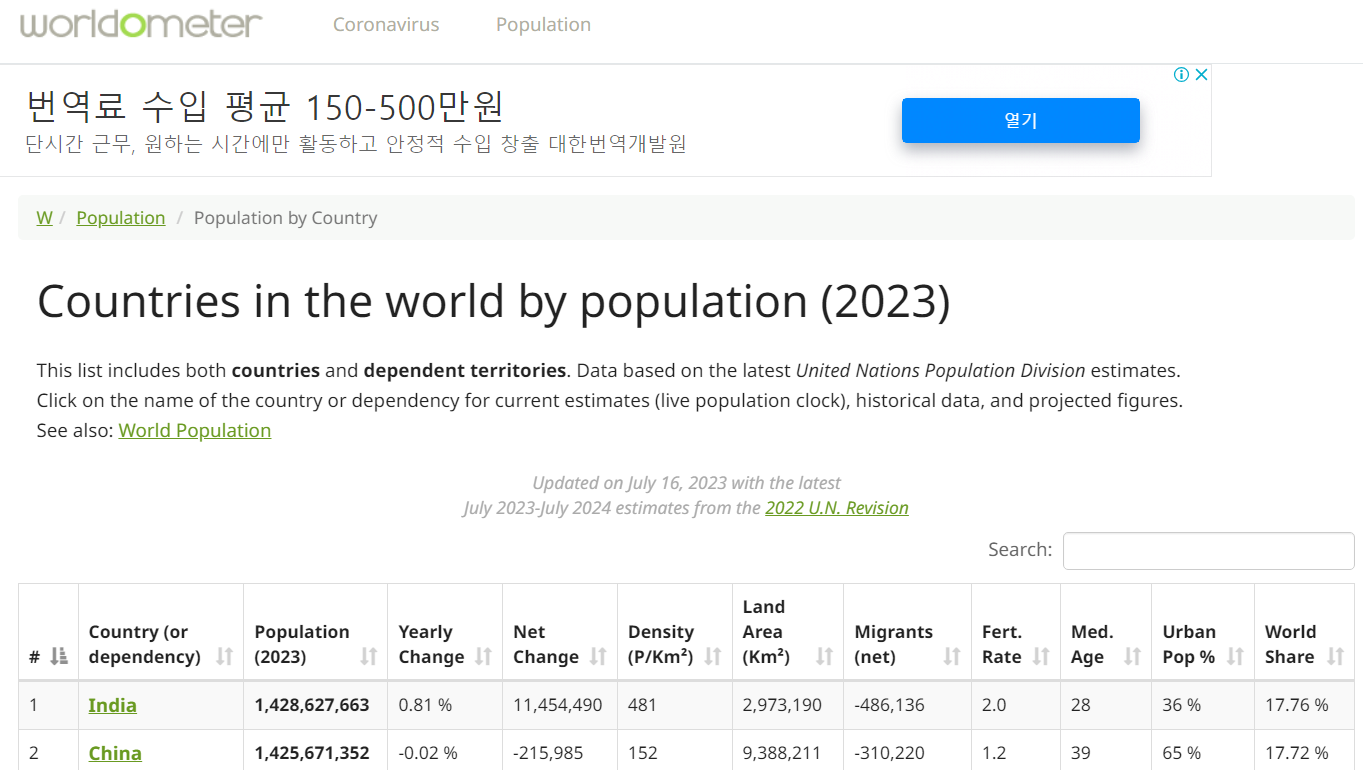
- 타겟 주소는 아래와 같다.
$ scrapy genspider worldometer www.worldometers.info/world-population/population-by-country
Created spider 'worldometer' using template 'basic' in module:
multiCam_tutorial.spiders.worldometer
- 명령어를 실행하고 나면 아래와 같은 새로운 파일이 하나 만들어진다.
- 파일명 : spiders > worldometer.py
- 여기에 아래와 같이 코드를 작성한다.
import scrapy
class WorldometerSpider(scrapy.Spider):
name = "worldometer"
allowed_domains = ["www.worldometers.info/"]
start_urls = ["http://www.worldometers.info/world-population/population-by-country"]
def parse(self, response):
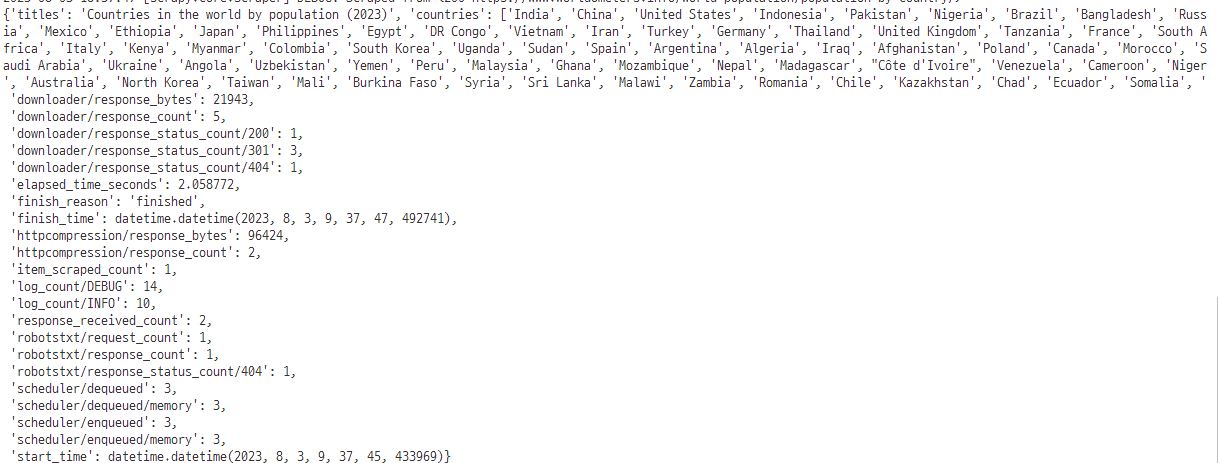
title = response.xpath('//h1/text()').get()
countries = response.xpath('//td/a/text()').getall()
yield {
'titles' : title,
'countries' : countries,
}
- 이제 코드를 실행한다.
- 경로는 worldometer.py가 있는 곳에서 진행한다.
$ ls
__init__.py __pycache__/ worldometer.py
- 코드 실행은 다음과 같다.
$ scrapy crawl worldometer
Multiple links 가져오기
- 이번에는 웹사이트 내의 다양한 링크를 가져오도록 한다.
import scrapy
class WorldometerSpider(scrapy.Spider):
name = "worldometer"
allowed_domains = ["www.worldometers.info/"]
start_urls = ["http://www.worldometers.info/world-population/population-by-country"]
def parse(self, response):
# step02
countries = response.xpath('//td/a')
for country in countries:
country_name = country.xpath(".//text()").get()
link = country.xpath(".//@href").get()
yield {
'country_name' : country_name,
'link' : link,
}
- 코드가 완성되었으면 아래 명령어를 통해 실행한다.
- 경로는 worldometer.py가 있는 곳이다.
$ scrapy crawl worldometer
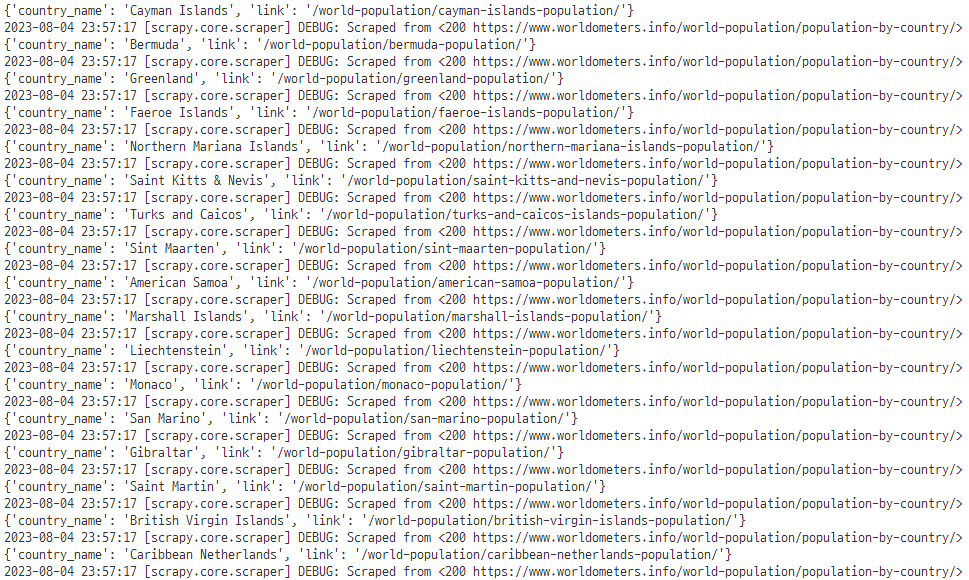
Multiple links 데이터 추출
- 이번에는 데이터를 추출한다.
- 먼저 XPath를 확인한다.
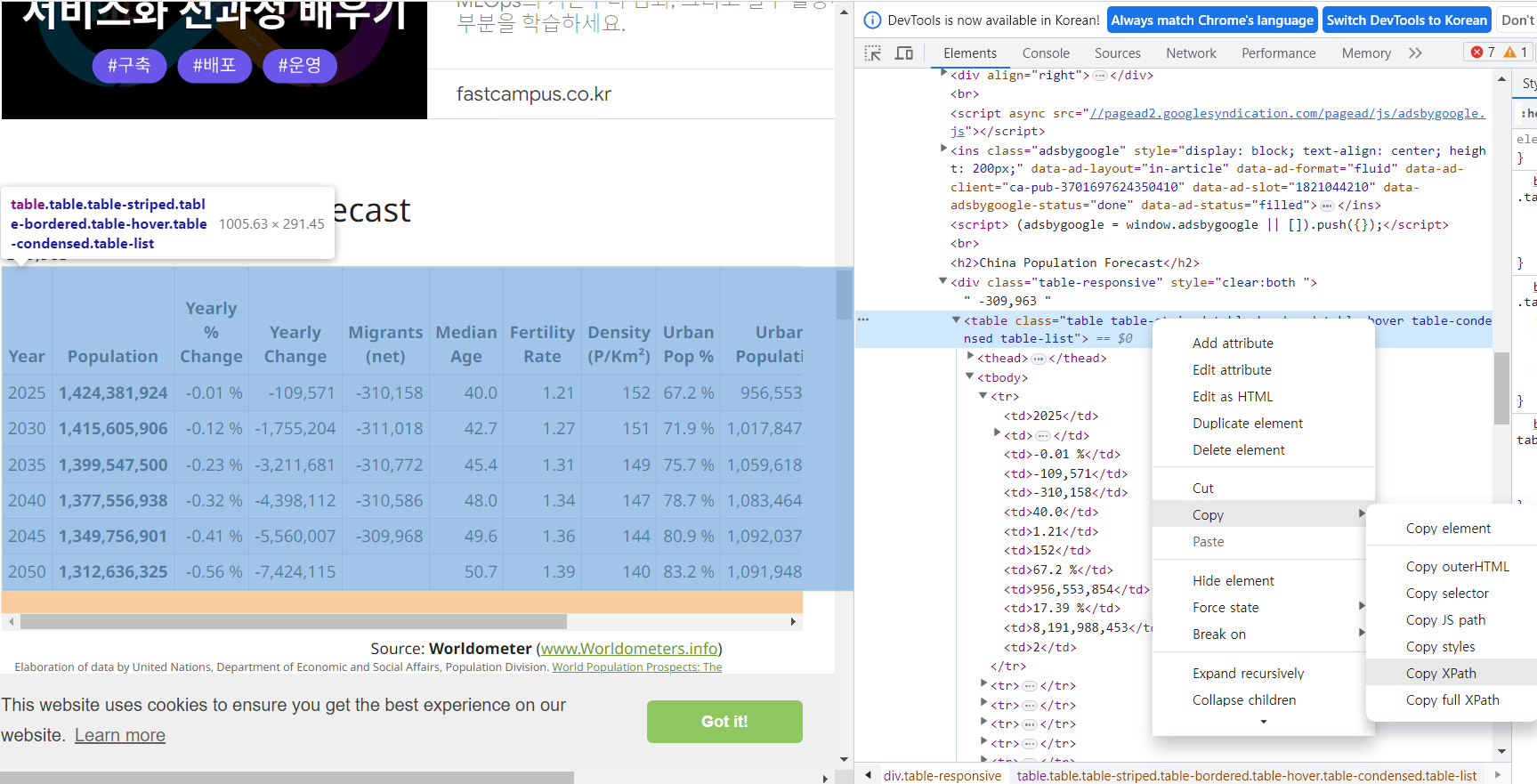
- 위 화면에서 Ctrl + F를 클릭 후 아래와 같이 입력한다.
(//table[@class="table table-striped table-bordered table-hover table-condensed table-list"])[1]

- 이번에는 tr 태그에 접근하도록 아래와 같이 입력한다.
(//table[@class="table table-striped table-bordered table-hover table-condensed table-list"])[1]/tbody/tr
- 방향키를 눌러보면 해당 행씩 클릭되는 걸 알 수 있다.
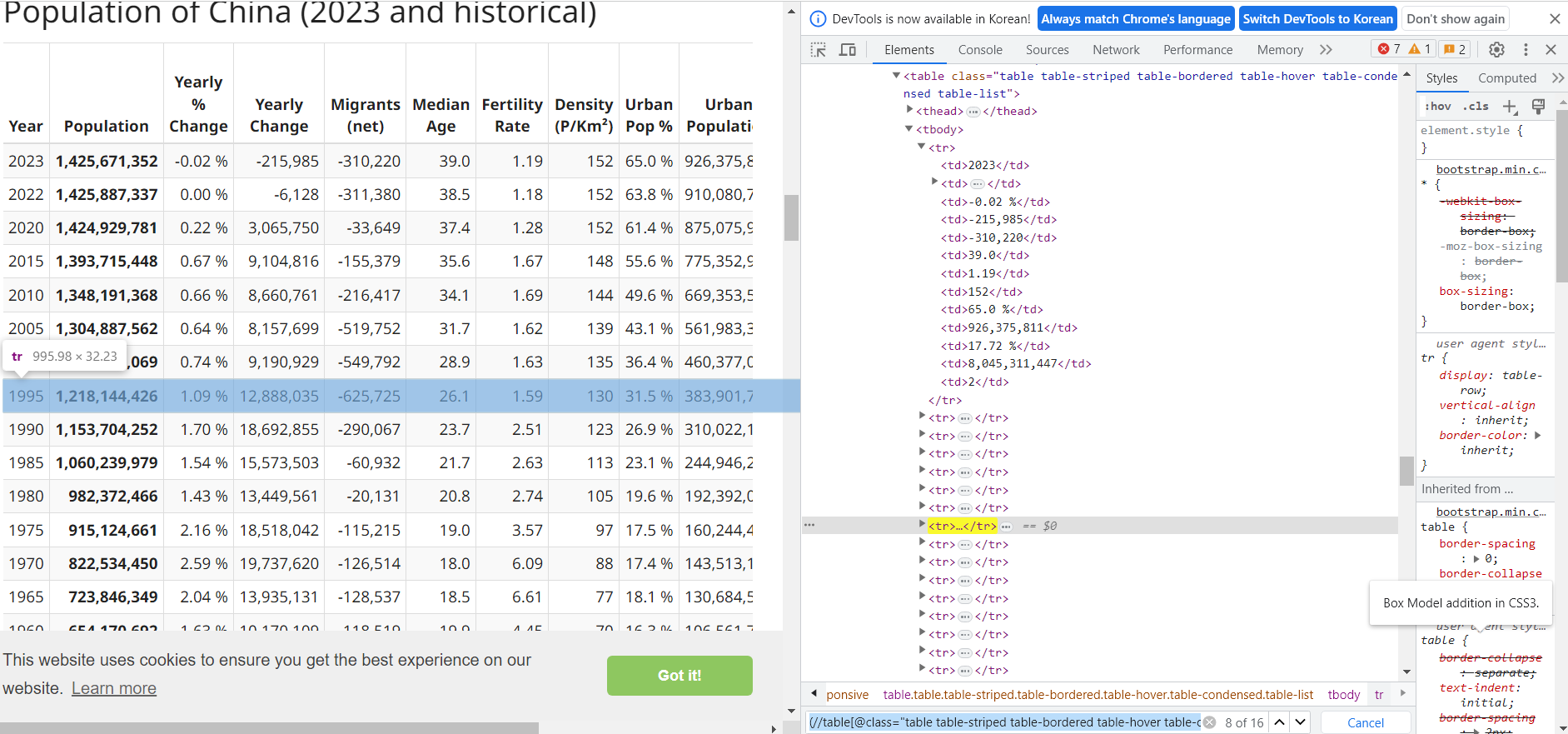
- 전체 코드는 아래와 같다.
import scrapy
class WorldometersSpider(scrapy.Spider):
name = 'worldometer'
allowed_domains = ['www.worldometers.info']
start_urls = ['https://www.worldometers.info/world-population/population-by-country/']
def parse(self, response):
# a 요소 확인
countries = response.xpath('//td/a')
# 반복문
for country in countries:
country_name = country.xpath(".//text()").get()
link = country.xpath(".//@href").get()
# 절대경로
# absolute_url = f'https://www.worldometers.info/{link}' # 방법 1
# absolute_url = response.urljoin(link) # 방법 2
# yield scrapy.Request(url=absolute_url) # sending a request with the absolute url
# 상대경로
yield response.follow(url=link, callback=self.parse_country, meta={'country':country_name})
# Getting data inside the "link" website
def parse_country(self, response):
country = response.request.meta['country']
rows = response.xpath("(//table[contains(@class,'table')])[1]/tbody/tr")
for row in rows:
year = row.xpath(".//td[1]/text()").get()
population = row.xpath(".//td[2]/strong/text()").get()
# Return data extracted
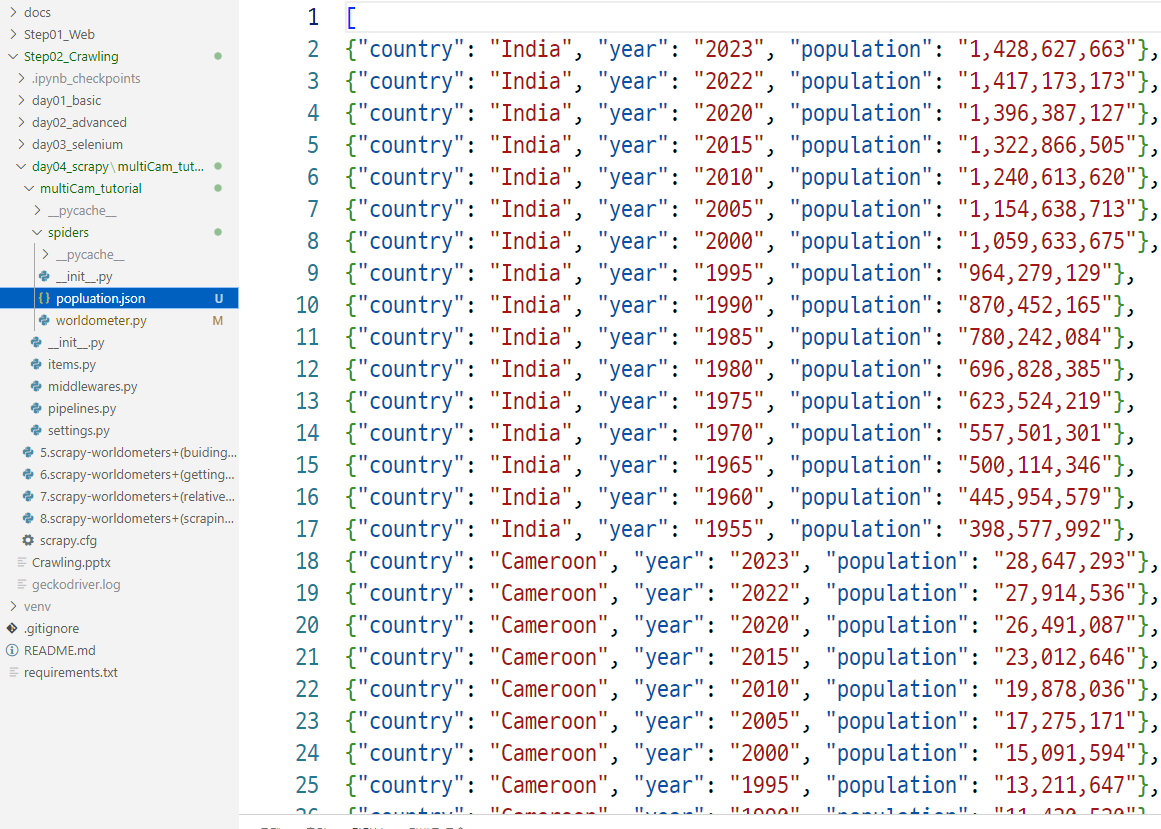
yield {
'country':country,
'year': year,
'population':population,
}
- 명령어는 아래와 같다.
scrapy crawl worldometer -o popluation.json