Django - ExcelCalCulator_6
Page content
개요
Django 한 그릇 뚝딱교재의 내용에서 멀티캠퍼스 강의에 맞게 일부 수정함- 2019년 버전이고 현재는 2023년이기 때문에 소스코드 변경 사항이 필요할 거 같아서 글을 남김
교재 홍보

Step 01 - 이전 글
- 1편 : https://dschloe.github.io/python/2023/08/django_excel_calculator_1/
- 2편 : https://dschloe.github.io/python/2023/08/django_excel_calculator_2/
- 3편 : https://dschloe.github.io/python/2023/08/django_excel_calculator_3/
- 4편 : https://dschloe.github.io/python/2023/08/django_excel_calculator_4/
- 5편 : https://dschloe.github.io/python/2023/08/django_excel_calculator_5/
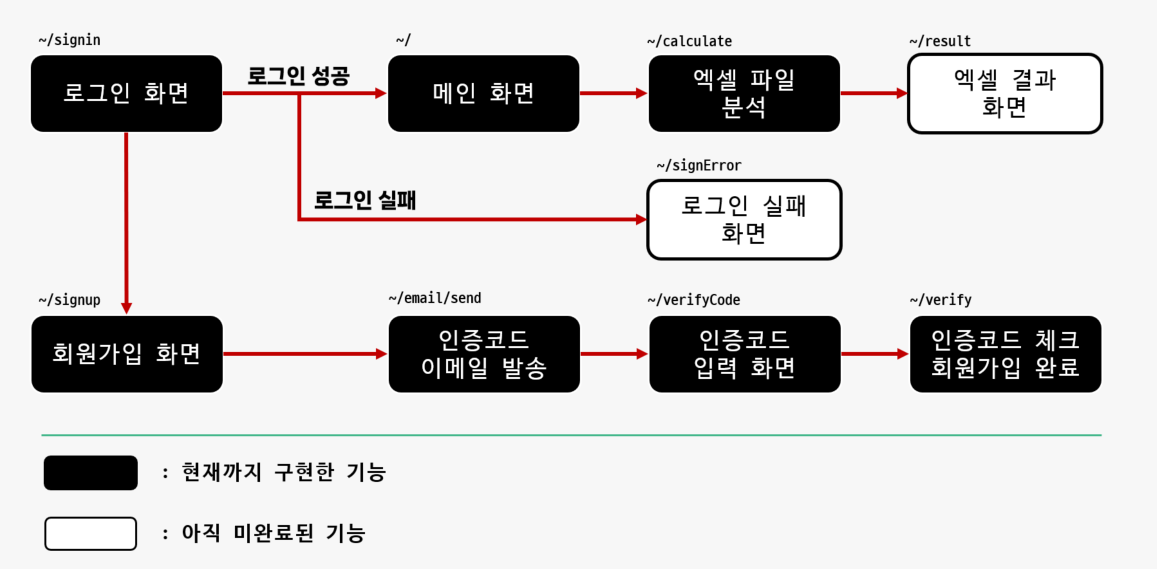
Step 02 - 프로젝트 완성하기
- 지금까지 구현한 기능과 미완료된 기능을 확인한다.
Step 03 - 엑셀 결과 화면 출력 위한 세션값 저장
- 우선 calculate 함수의 마지막에 엑셀 결과 화면으로 데이터와 함께 url을 이동시켜본다.
- views.py에 코드를 추가한다.
- 파일 경로 : ExcelCalculate > calculate > views.py
from django.shortcuts import render, redirect
from django.http import HttpResponse
import pandas as pd
# Create your views here.
def calculate(request):
file = request.FILES['fileInput']
print("# 사용자가 등록한 파일의 이름: ", file)
df = pd.read_excel(file, sheet_name="Sheet1", header=0)
print(df.head())
# grade별 value 리스트 만들기
grade_dic = {}
total_row_num = len(df.index)
for i in range(total_row_num):
data = df.loc[i, :]
if not data.grade in grade_dic.keys():
grade_dic[data.grade] = [data.value]
else:
grade_dic[data.grade].append(data.value)
# print(grade_dic)
# grade별 최솟값 최댓값 평균값 구하기
grade_calculate_dic = {}
for key in grade_dic.keys():
grade_calculate_dic[key] = {}
grade_calculate_dic[key]['min'] = min(grade_dic[key])
grade_calculate_dic[key]['max'] = max(grade_dic[key])
grade_calculate_dic[key]['avg'] = float(sum(grade_dic[key])) / len(grade_dic[key])
# 결과 출력
grade_list = list(grade_calculate_dic.keys())
grade_list.sort()
for key in grade_list:
print("# grade: ", key)
print("min:", grade_calculate_dic[key]['min'], end="")
print("/ max:", grade_calculate_dic[key]['max'], end="")
print("/ avg:", grade_calculate_dic[key]['avg'], end="\n\n")
# 아래 코드와 동일
result = df.groupby('grade')['value'].agg(["min", "max", "mean"])
print(result)
# 이메일 주소 도메인별 인원 구하기
email_domain_dic = {}
for i in range(total_row_num):
data = df.loc[i, :]
email_domain = data['email'].split("@")[1]
if not email_domain in email_domain_dic.keys():
email_domain_dic[email_domain] = 1
else:
email_domain_dic[email_domain] += 1
print("## EMAIL 도메인별 사용 인원")
for key in email_domain_dic.keys():
print("#", key, ": ", email_domain_dic[key], "명")
df['domain'] = df['email'].apply(lambda x : x.split("@")[1])
result2 = df.groupby('domain')['value'].agg("count").sort_values(ascending=False)
print(result2)
# 세션 추가
grade_calculate_dic_to_session = {}
for key in grade_list:
grade_calculate_dic_to_session[int(key)] = {}
grade_calculate_dic_to_session[int(key)]['max'] = float(grade_calculate_dic[key]['max'])
grade_calculate_dic_to_session[int(key)]['avg'] = float(grade_calculate_dic[key]['avg'])
grade_calculate_dic_to_session[int(key)]['min'] = float(grade_calculate_dic[key]['min'])
request.session['grade_calculate_dic'] = grade_calculate_dic_to_session
request.session['email_domain_dic'] = email_domain_dic
# return HttpResponse("calculate, calculate function!")
return redirect('/result')
- 세션 추가 이하의 코드를 살펴보면 다음과 같다.
- pandas의 기본 자료형은 numpy 기반인데, 장고에서는 numpy 기반의 자료형이 아닌 파이썬 기본 자료형으로 변환해주어야 한다.
- 따라서, 정수형 숫자로 된 것으로 int형으로 유리수 형태의 숫자를 float형으로 자료를 변환한다.
- 형 변환을 하고 나서 해당 값들을 결과 화면에서 사용하려고 세션에 저장해준다.
- 마지막으로
redirect(”/result”)로 처리하였다.- 결과 화면을 관리하는 함수는 main app에 있는 result 함수이다. 따라서, 해당 url로 갈 수 있도록 처리한 것이다.
Step 04 - result 함수 수정
-
파일 경로 : ExcelCalculate > main > views.py
- 기존
def result(request): if 'user_name' in request.session.keys(): return render(request, 'main/result.html') else: return redirect('main_signin')- 수정
def result(request): if 'user_name' in request.session.keys(): content = {} # 새로운 객체에 저장 content['grade_calculate_dic'] = request.session['grade_calculate_dic'] content['email_domain_dic'] = request.session['email_domain_dic'] # 기존 세션 삭제 del request.session['grade_calculate_dic'] del request.session['email_domain_dic'] # main/result.html로 결괏값 전달 return render(request, 'main/result.html', content) else: return redirect('main_signin')
Step 05 - result.html 파일 수정
-
파일 경로 : ExcelCalculate > main > templates > main > result.html
- 기존
<div class='body'> <div class="resultDiv"> <h3> * Excel 결과 확인 *</h3> </div> <hr> </div> <div class="panel-footer"> 실전예제로 배우는 Django. Project3-ExcelCalculate </div>- 수정
<div class='body'> <div class="resultDiv"> <h3> * Excel 결과 확인 *</h3> <h4> - grade별 최솟값, 최댓값, 평균값</h4> {% for key, value in grade_calculate_dic.items %} <h5>GRADE: {{ key }}</h5> <p><strong>최솟값 : </strong> {{ value.min }}</p> <p><strong>최댓값 : </strong> {{ value.max }}</p> <p><strong>평균값 : </strong> {{ value.avg }}</p> <br> {% endfor %} <br> <h4> - 이메일별 주소 도메인 인원 </h4> {% for key, value in email_domain_dic.items %} <p><strong>{{ key }}: </strong> {{ value }}명</p> {% endfor %} </div> <hr> </div>
Step 06 - 테스트
- 서버를 재구동하여 테스트를 해본다.


Step 07 - 코드 재수정
- 이번에는 교재의 방식이 아닌 다른 방식으로 구현을 하려고 한다.
- 먼저 결과 페이지부터 확인한다.
- 기존 방식이 아닌 테이블 형태로 내보내는 방향으로 처리를 하고자 한다.
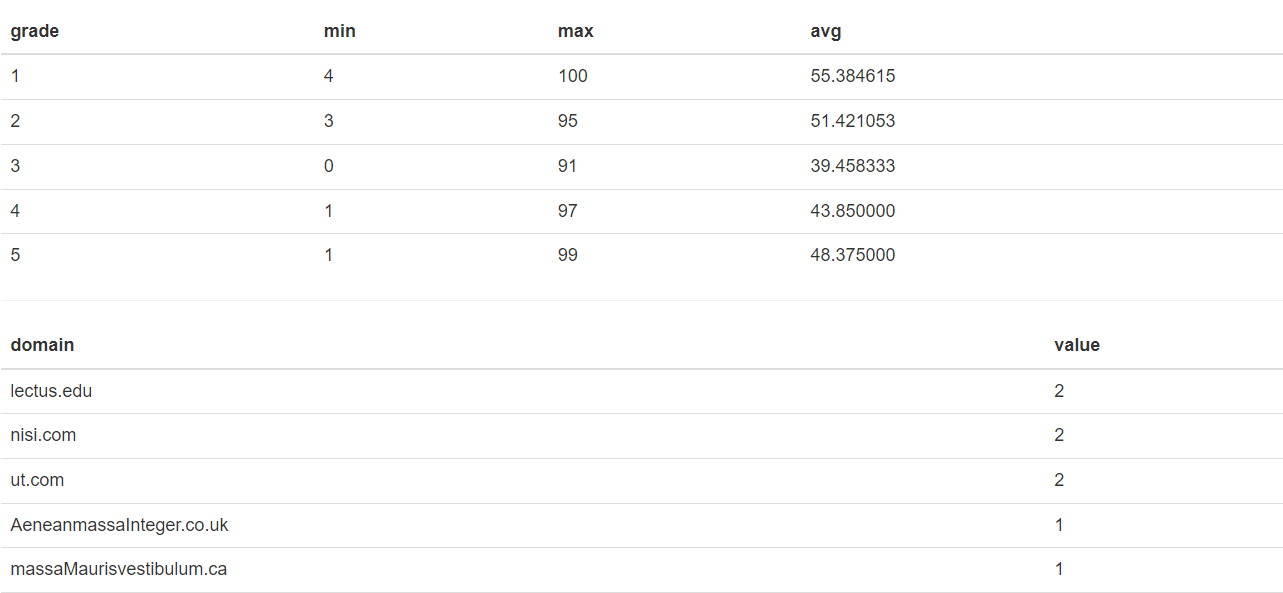
- 기존 코드에서 수정할 것은 크게 없다.
- 아래 코드를 추가한다.
from django.shortcuts import render, redirect
from django.http import HttpResponse
import pandas as pd
import json
# Create your views here.
def calculate(request):
file = request.FILES['fileInput']
print("# 사용자가 등록한 파일의 이름: ", file)
df = pd.read_excel(file, sheet_name="Sheet1", header=0)
print(df.head())
# grade별 value 리스트 만들기
grade_dic = {}
total_row_num = len(df.index)
for i in range(total_row_num):
data = df.loc[i, :]
if not data.grade in grade_dic.keys():
grade_dic[data.grade] = [data.value]
else:
grade_dic[data.grade].append(data.value)
# print(grade_dic)
# grade별 최솟값 최댓값 평균값 구하기
grade_calculate_dic = {}
for key in grade_dic.keys():
grade_calculate_dic[key] = {}
grade_calculate_dic[key]['min'] = min(grade_dic[key])
grade_calculate_dic[key]['max'] = max(grade_dic[key])
grade_calculate_dic[key]['avg'] = float(sum(grade_dic[key])) / len(grade_dic[key])
# 결과 출력
grade_list = list(grade_calculate_dic.keys())
grade_list.sort()
for key in grade_list:
print("# grade: ", key)
print("min:", grade_calculate_dic[key]['min'], end="")
print("/ max:", grade_calculate_dic[key]['max'], end="")
print("/ avg:", grade_calculate_dic[key]['avg'], end="\n\n")
# 이메일 주소 도메인별 인원 구하기
email_domain_dic = {}
for i in range(total_row_num):
data = df.loc[i, :]
email_domain = data['email'].split("@")[1]
if not email_domain in email_domain_dic.keys():
email_domain_dic[email_domain] = 1
else:
email_domain_dic[email_domain] += 1
print("## EMAIL 도메인별 사용 인원")
for key in email_domain_dic.keys():
print("#", key, ": ", email_domain_dic[key], "명")
grade_calculate_dic_to_session = {}
for key in grade_list:
grade_calculate_dic_to_session[int(key)] = {}
grade_calculate_dic_to_session[int(key)]['max'] = float(grade_calculate_dic[key]['max'])
grade_calculate_dic_to_session[int(key)]['avg'] = float(grade_calculate_dic[key]['avg'])
grade_calculate_dic_to_session[int(key)]['min'] = float(grade_calculate_dic[key]['min'])
request.session['grade_calculate_dic'] = grade_calculate_dic_to_session
request.session['email_domain_dic'] = email_domain_dic
# grade별 value 리스트 만들기
grade_df = df.groupby('grade')['value'].agg(["min", "max", "mean"]).reset_index().rename(columns = {"mean" : "avg"})
grade_df = grade_df.astype({'min' : 'int', 'max' : 'int', 'avg' : 'float'})
print(grade_df.dtypes)
grade_df = grade_df.style.hide(axis='index').set_table_attributes('class="table table-dark"')
grade_calculate_pd_to_session = {'grade_df' : grade_df.to_html(justify='center')}
request.session['grade_calculate_pd_dic'] = grade_calculate_pd_to_session
# 이메일 주소 도메인별 인원 구하기
df['domain'] = df['email'].apply(lambda x : x.split("@")[1])
email_df = df.groupby('domain')['value'].agg("count").sort_values(ascending=False).reset_index()
email_df = email_df.style.hide(axis='index').set_table_attributes('class="table table-dark"')
email_calculate_pd_to_session = {'email_df' : email_df.to_html(justify='center')}
request.session['email_calculate_pd_dic'] = email_calculate_pd_to_session
# print(email_df)
# return HttpResponse("calculate, calculate function!")
return redirect('/result')
