(파이썬) 빅데이터 분석기사 실기 - 제2유형, 회귀
Page content
작업형 2유형 최종정리
- 작업형1 : 3문제 (30점), 데이터 전처리
작업형2 : 1문제 (40점), 분류/회귀 예측 모델링- 작업형3 : 2문제 (30점), 가설 검정
주요 라이브러리
- palmerpenguins : 팔머펭귄 데이터셋의 목표는 iris 데이터셋의 대안으로 데이터 탐색 및 시각화를 위한 데이터셋 제공.
- scikit-learn : 머신러닝을 위한 라이브러리
- lightgbm : LightGBM은 Microsoft에서 개발한 오픈 소스 기계 학습 라이브러리로, 대용량 데이터셋에서 빠른 속도와 높은 성능을 제공하는 것이 특징
주의
- 각 코드에 대한 설명은 별도로 하지 않습니다.
데이터 파일 불러오기
import pandas as pd
from palmerpenguins import load_penguins
penguins = load_penguins()
penguins['ID'] = penguins.reset_index().index + 1
penguins.head()
- 컬럼의 순서를 변경한다. ID가 가장 먼저 오도록 한다.
cols = penguins.columns.tolist()
cols = cols[-1:] + cols[:-1]
print(cols)
[결과]
['ID', 'species', 'island', 'bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g', 'sex', 'year']
penguins = penguins[cols]
penguins
데이터 가공
지금까지 열린 대회에서는 결측치가 존재 하지 않았던 것으로 기억
- 만약 잘못된 정보라면 알려주세요
- 결측치를 제거한다.
penguins = penguins.dropna().reset_index(drop=True)
penguins
데이터셋 분리
- 기사시험과 같이 데이터셋을 만들기 위해 데이터셋을 분리하고 저장한다.
from sklearn.model_selection import train_test_split
y = penguins['body_mass_g']
X = penguins.drop(['body_mass_g'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
X_train.to_csv("penguin_reg_X_train.csv", index=False)
X_test.to_csv("penguin_reg_X_test.csv", index=False)
y_train.to_csv("penguin_reg_y_train.csv", index=False)
y_test.to_csv("penguin_reg_y_test.csv", index=False)
회귀모형 만들기 정리
- 기본적으로 아래 데이터셋 불러오기는 제공된다.
import pandas as pd
X_train = pd.read_csv("penguin_reg_X_train.csv")
X_test = pd.read_csv("penguin_reg_X_test.csv")
y_train = pd.read_csv("penguin_reg_y_train.csv")
ID 제거
X_train_id = X_train.pop("ID")
X_test_id = X_test.pop("ID")
데이터 확인
X_train.head()
y_train.head()

X_test.head()
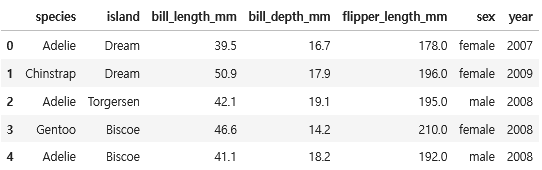
결측치 확인
X_train.isnull().sum()
[결과]
species 0
island 0
bill_length_mm 0
bill_depth_mm 0
flipper_length_mm 0
sex 0
year 0
dtype: int64
X_test.isnull().sum()
[결과]
species 0
island 0
bill_length_mm 0
bill_depth_mm 0
flipper_length_mm 0
sex 0
year 0
dtype: int64
y_train.isnull().sum()
[결과]
body_mass_g 0
dtype: int64
y_train
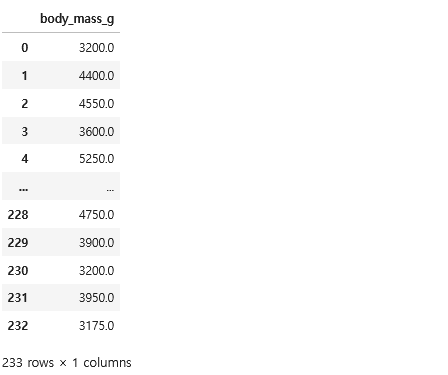
컬럼 분리
- 범주형 컬럼과 숫자형 컬럼으로 분리
import numpy as np
cat_cols = X_train.select_dtypes(exclude = np.number).columns.tolist()
num_cols = X_train.select_dtypes(include = np.number).columns.tolist()
print(cat_cols, num_cols)
[결과]
['species', 'island', 'sex'] ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'year']
- year은 num_cols에서 제거한다.
num_cols.remove("year")
num_cols
[결과]
['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm']
데이터셋 분리
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(
X_train, y_train['body_mass_g'],
stratify = X_train['sex'],
test_size=0.3,
random_state=42
)
X_tr.shape, X_val.shape, y_tr.shape, y_val.shape
[결괴]
((163, 7), (70, 7), (163,), (70,))
회귀모형 만들기
- pipeline을 활용하여 모형을 만들면, 매우 쉽게 작성할 수 있다.
- OrdinalEncoder를 추가할 때는 아래와 같이 작성한다.
ord_encoder영역만 살펴본다.
from sklearn.preprocessing import OrdinalEncoder
from sklearn.compose import ColumnTransformer
column_transformer = ColumnTransformer([
("scaler", StandardScaler(), num_cols),
("ohd_encoder", OneHotEncoder(), cat_cols)
("ord_encoder", OrdinalEncoder(categories=[["Adelie", "Gentoo", "Chinstrap"]]), ['species'])
], remainder="passthrough")
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.utils.fixes import loguniform
from sklearn.metrics import make_scorer, mean_squared_error
from lightgbm import LGBMRegressor
from sklearn.model_selection import RandomizedSearchCV
import numpy as np
def rmse(y_tr, y_val):
return np.sqrt(mean_squared_error(y_tr, y_val))
param_grid = {
"clf__learning_rate": loguniform(0.0001, 0.1),
"clf__n_estimators" : np.arange(30, 50),
"clf__max_depth" : np.arange(3, 30, 2),
"clf__num_leaves" : np.arange(30, 50),
"clf__min_split_gain" : np.arange(0, 1.1, 0.1),
"clf__subsample" : np.arange(0.6, 1.0, 0.1)
}
column_transformer = ColumnTransformer([
("scaler", StandardScaler(), num_cols),
("ohd_encoder", OneHotEncoder(), cat_cols)
], remainder="passthrough")
pipeline = Pipeline([
("preprocessing", column_transformer),
("clf", LGBMRegressor(random_state=42))
])
random_search = RandomizedSearchCV(
estimator=pipeline,
param_distributions = param_grid,
n_iter = 10,
scoring = make_scorer(rmse, greater_is_better=False),
cv=5,
verbose=-1,
n_jobs=-1
)
random_search.fit(X_tr, y_tr)
[결과]
RandomizedSearchCV(cv=5,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder='passthrough',
transformers=[('scaler',
StandardScaler(),
['bill_length_mm',
'bill_depth_mm',
'flipper_length_mm']),
('ohd_encoder',
OneHotEncoder(),
['species',
'island',
'sex'])])),
('clf',
LGBMRegressor(random_state=42))]),
n_jobs=-1,
param_distributions={'clf__lear...
'clf__min_split_gain': array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ]),
'clf__n_estimators': array([30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46,
47, 48, 49]),
'clf__num_leaves': array([30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46,
47, 48, 49]),
'clf__subsample': array([0.6, 0.7, 0.8, 0.9])},
scoring=make_scorer(rmse, greater_is_better=False),
verbose=-1)
평가확인
def get_score(model, X_tr, X_val, y_tr, y_val):
tr_pred = model.predict(X_tr) # 만약 확률로 구할시, predict_proba()[:, 1]
val_pred = model.predict(X_val)
tr_score = rmse(y_tr, tr_pred)
val_score = rmse(y_val, val_pred)
return f"train: {tr_score}, validation: {val_score}"
get_score(random_search, X_tr, X_val, y_tr, y_val)
[결과]
'train: 263.3286702791066, validation: 316.216422332984'
평가제출
final_preds = random_search.predict(X_test)
result = pd.DataFrame({
"ID" : X_test_id,
"preds": final_preds.astype("int64")
})
result.head()
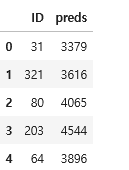
result.to_csv("A수험번호.csv", index=False)
