Streamlit 라이브러리를 활용한 배포 - BigQuery 사용
Page content
개요
- Streamlit 라이브러리와 BigQuery를 사용하여 배포를 진행한다.
- GCP 클라우드 프로젝트 설정 과정은 생략한다.
BigQuery API 사용설정
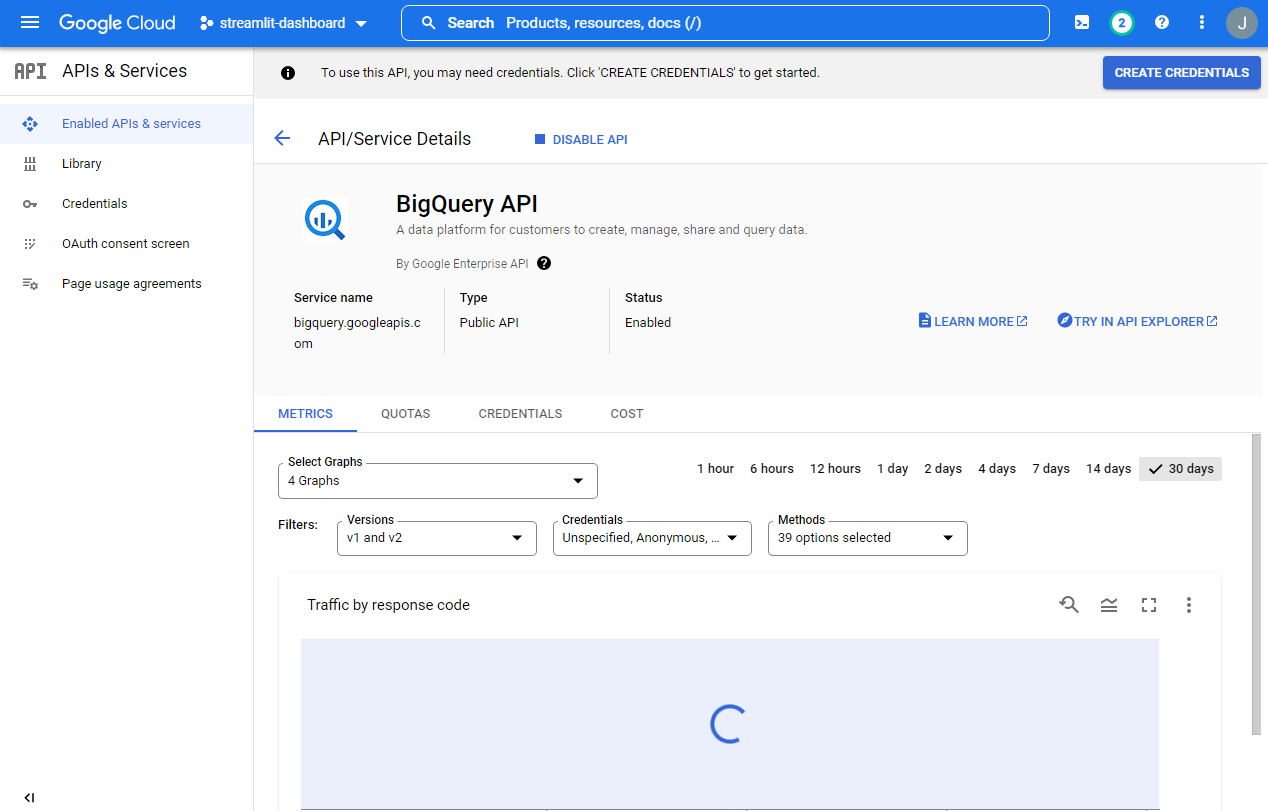
Project API에서ENABLE APIS AND SERVICES버튼을 클릭한다.
- 빅쿼리 API를 탐색한다.
- 키워드명 : BigQuery API
manage버튼을 클릭한다.
- 인증키를 다운로드 받도록 한다. (
CREATE CREDENTIALS클릭)
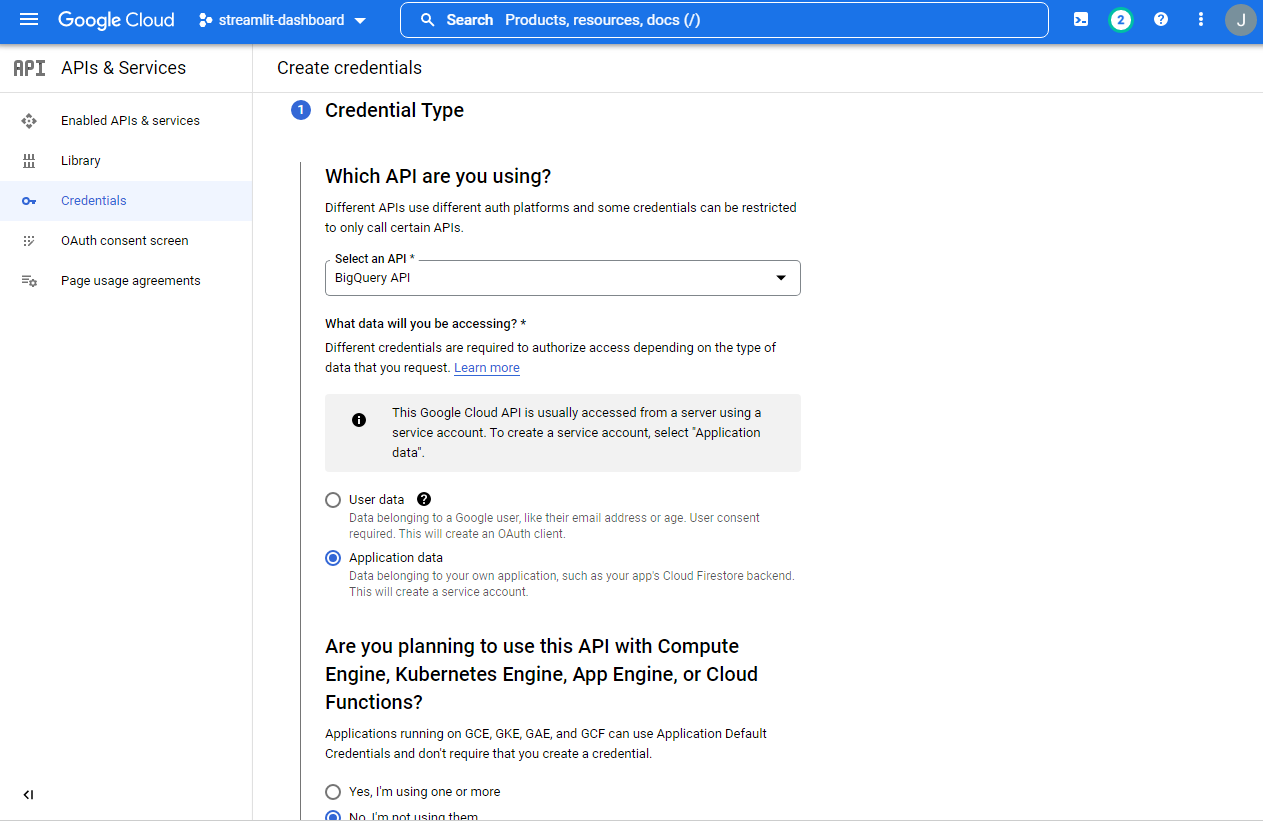
- 아래와 같이 지정 후, 스크롤을 내려서
NEXT버튼을 클릭한다.
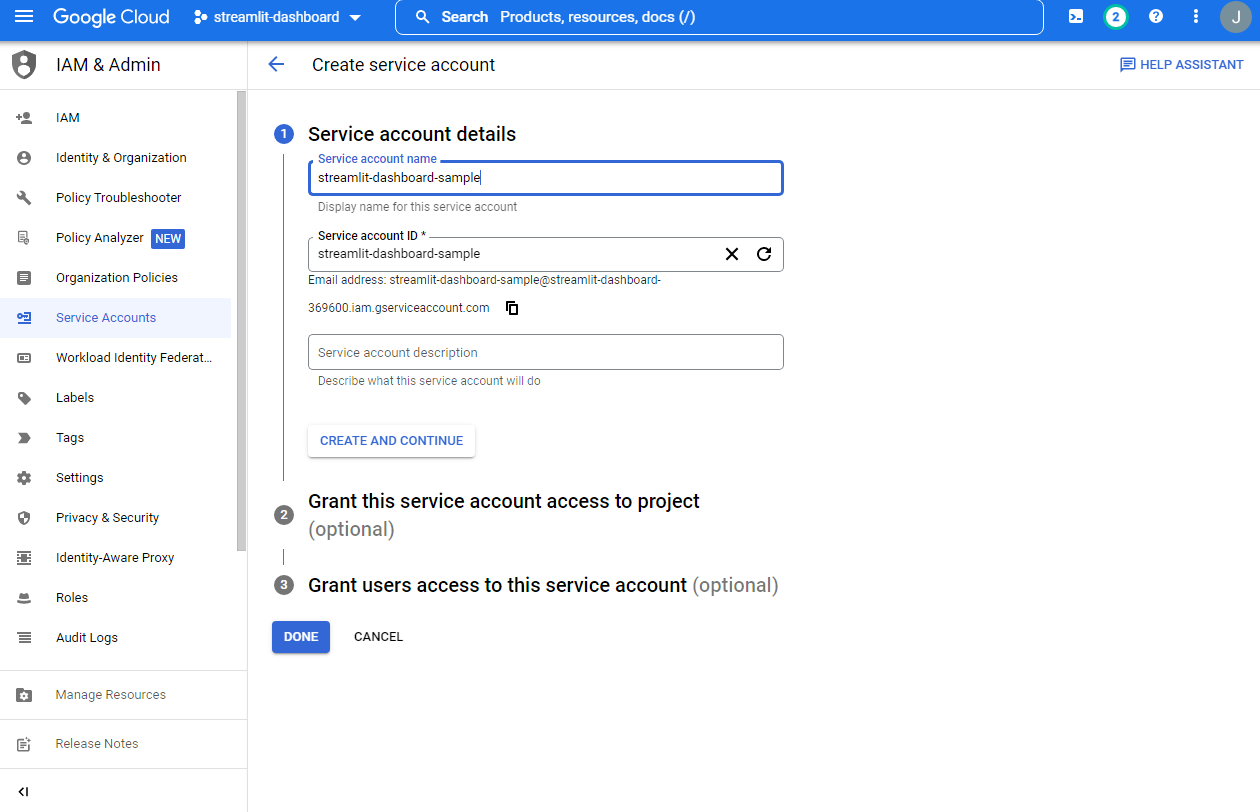
- 임의의
Service account ID작성 후,CREATE AND CONTINUE버튼을 클릭한다.
- 프로젝트 권한을 부여 후,
CONTINUE버튼을 클릭한다.
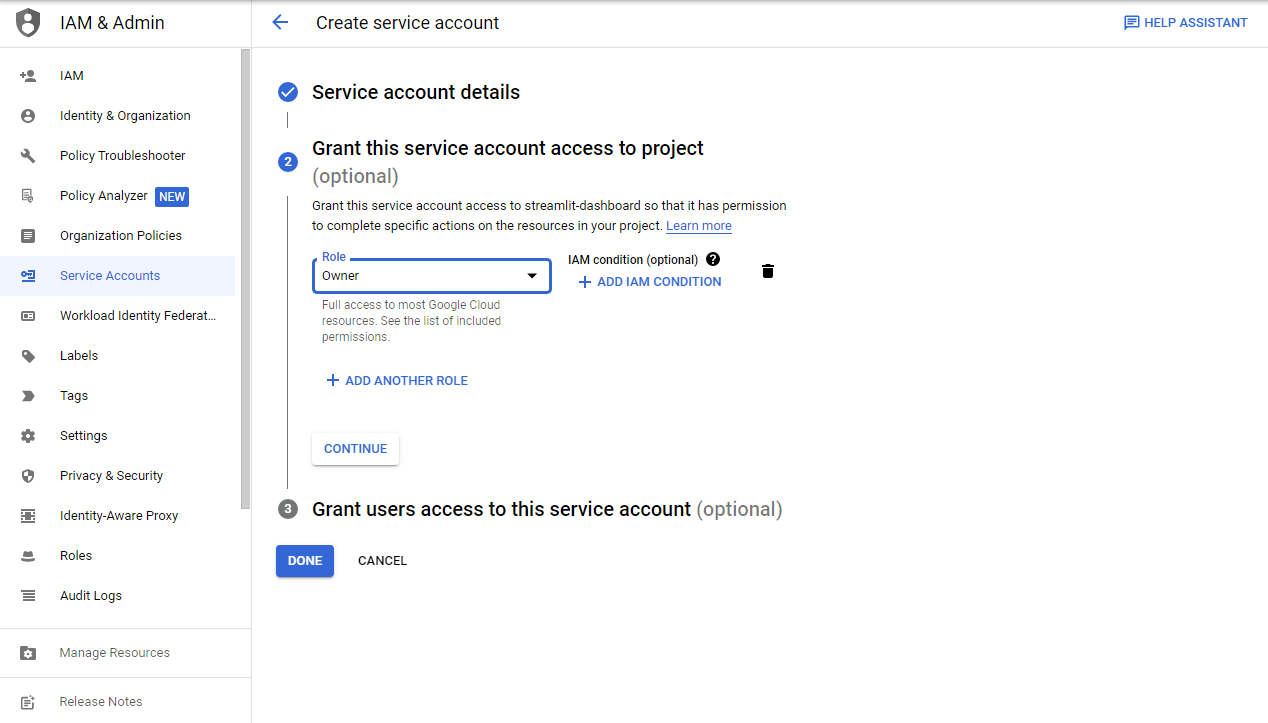
Done버튼을 클릭한다.
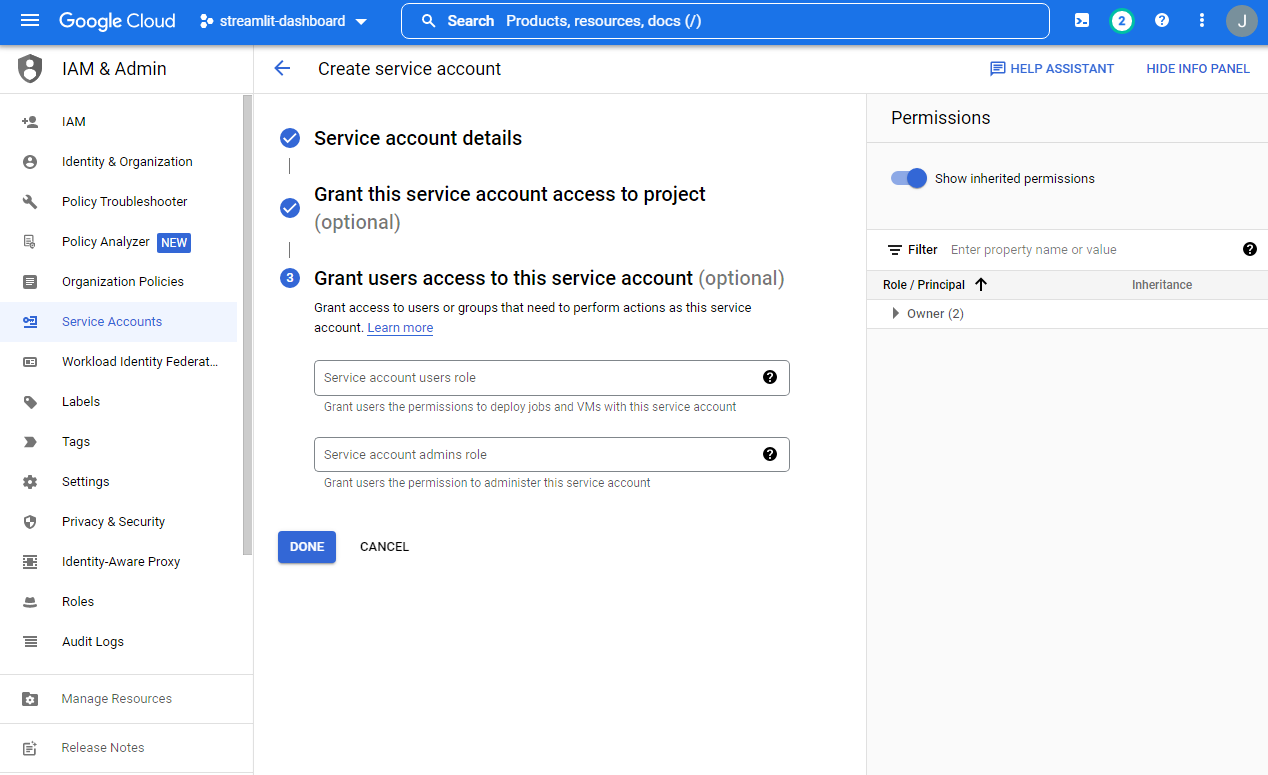
Service Accounts-[우측] Manage keys버튼 클릭
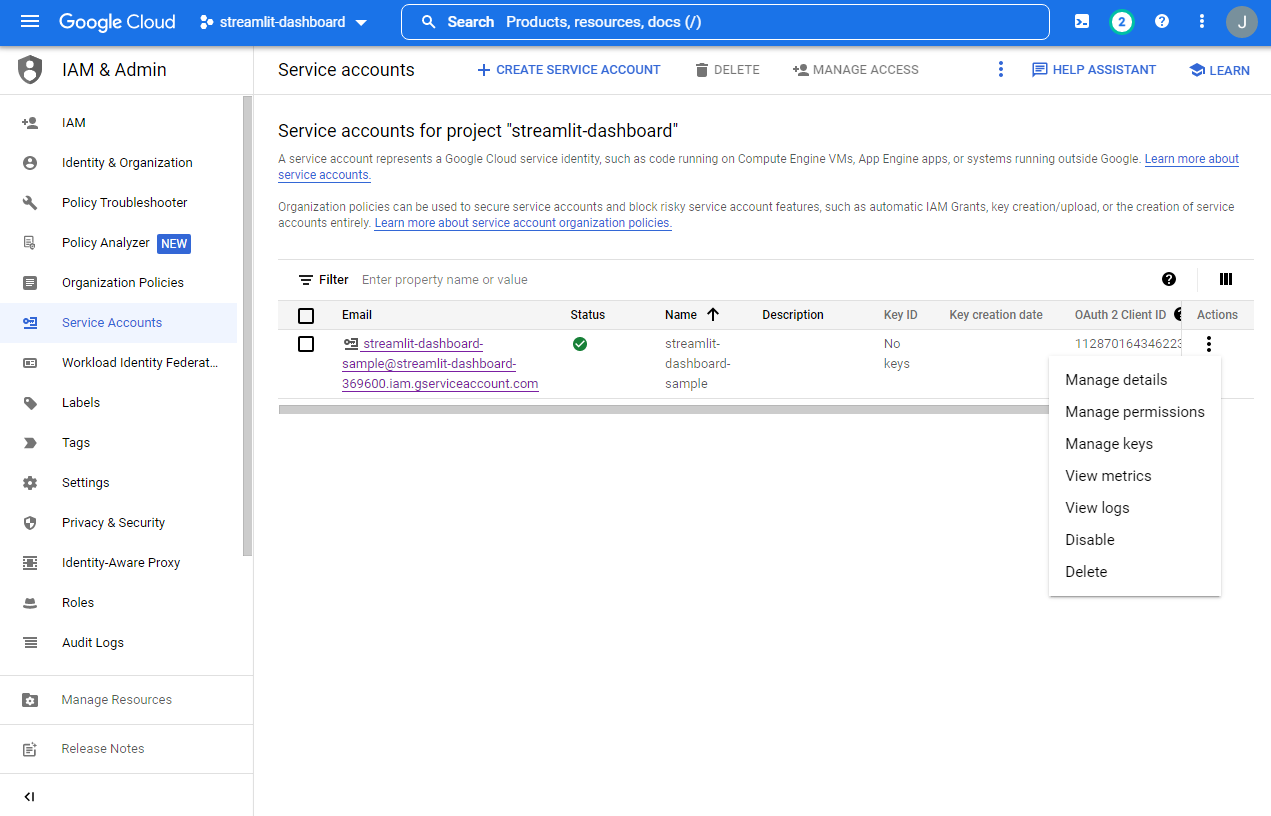
Create new key버튼 클릭
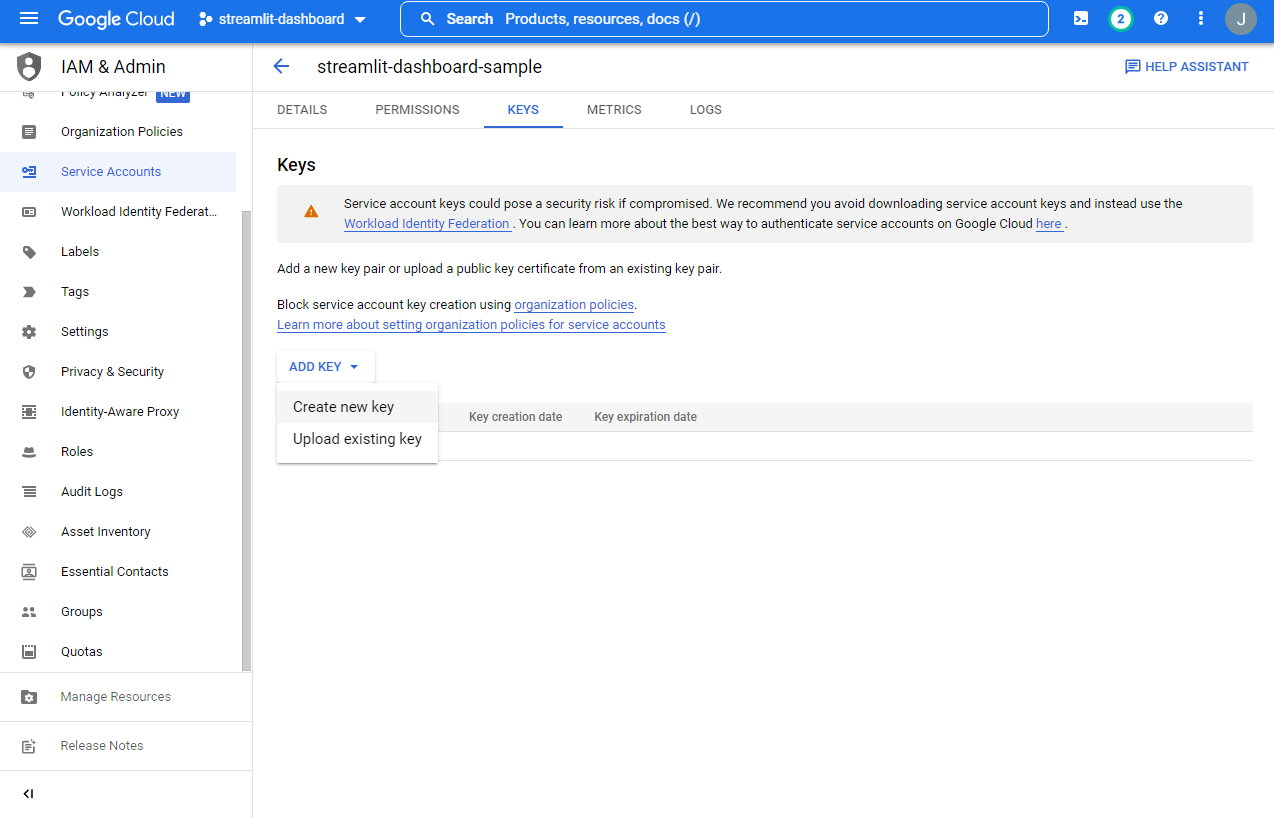
- JSON 클릭

- json 파일을 다운로드 받는다.
Github Repo 생성
- 임의의
Github Repo를 생성하고, 로컬로 다운로드 받는다.- 생성 방법은 생략한다.
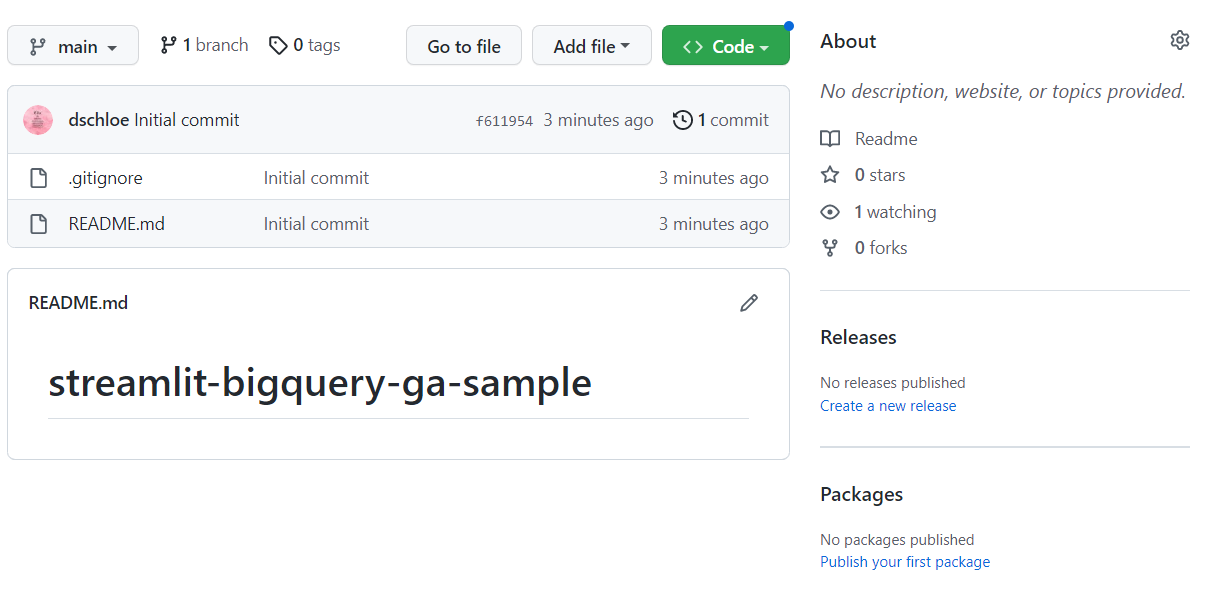
secrets.toml 파일 설정
.streamlit폴더를 생성하고,secrets.toml파일을 생성하여 아래와 같이 작성한다.
# .streamlit/secrets.toml
[gcp_service_account]
type = "service_account"
project_id = "xxx"
private_key_id = "xxx"
private_key = "xxx"
client_email = "xxx"
client_id = "xxx"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "xxx"
- 이때 중요한 것은 위 파일은
.gitignore에 등록한 후,Github Repo에 등록을 해둬야 한다.- 보안은 중요하다.
secrets.toml파일을 아래와 같이 수정한다.
Streamlit 대시보드 생성
- 라이브러리 설치 후, 간단하게 화면을 출력하도록 한다.
$ virtualenv venv
$ source venv/Scripts/activate
(venv) $ pip install numpy pandas matplotlib seaborn altair plotly streamlit joblib scikit-learn google-cloud-bigquery pandas-gbq pycoingecko
- 설치된 라이브러리를
requirements.txt파일로 내보낸다.
(venv) $ pip freeze > requirements.txt
- 라이브러리 설치가 완료되면 아래와 같이 코드를 복사한 뒤,
[app.py](http://app.py)를 설치한다. - 데이터는 빅쿼리 내부
sample datasets를 사용했다.
# streamlit_app.py
import streamlit as st
from google.oauth2 import service_account
from google.cloud import bigquery
# Create API client.
credentials = service_account.Credentials.from_service_account_info(
st.secrets["gcp_service_account"]
)
client = bigquery.Client(credentials=credentials)
# Perform query.
# Uses st.experimental_memo to only rerun when the query changes or after 10 min.
@st.experimental_memo(ttl=600)
def run_query(query):
query_job = client.query(query)
rows_raw = query_job.result()
# Convert to list of dicts. Required for st.experimental_memo to hash the return value.
rows = [dict(row) for row in rows_raw]
return rows
rows = run_query("SELECT word FROM `bigquery-public-data.samples.shakespeare` LIMIT 10")
# Print results.
st.write("Some wise words from Shakespeare:")
for row in rows:
st.write("✍️ " + row['word'])
- 이제 실행한후, 데이터가 정상적으로 나오는지 확인한다.
(venv) $ streamlit run app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.0.20:8501
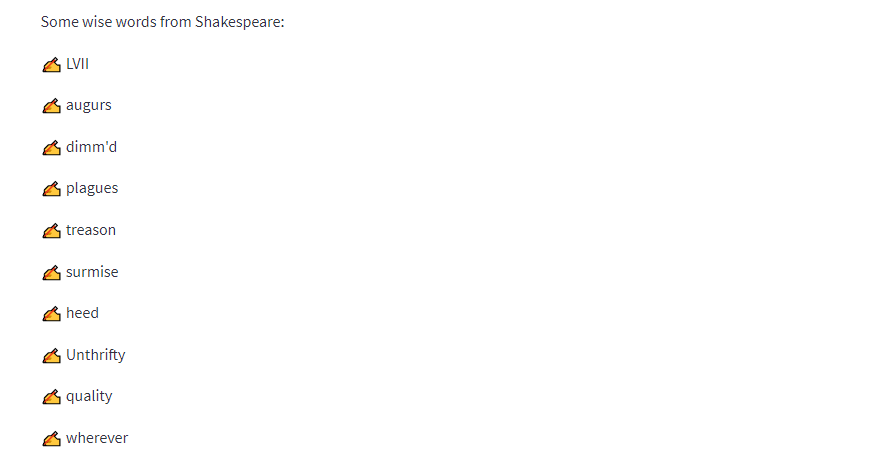
배포
- 배포는 https://share.streamlit.io/signup 에서 진행한다.
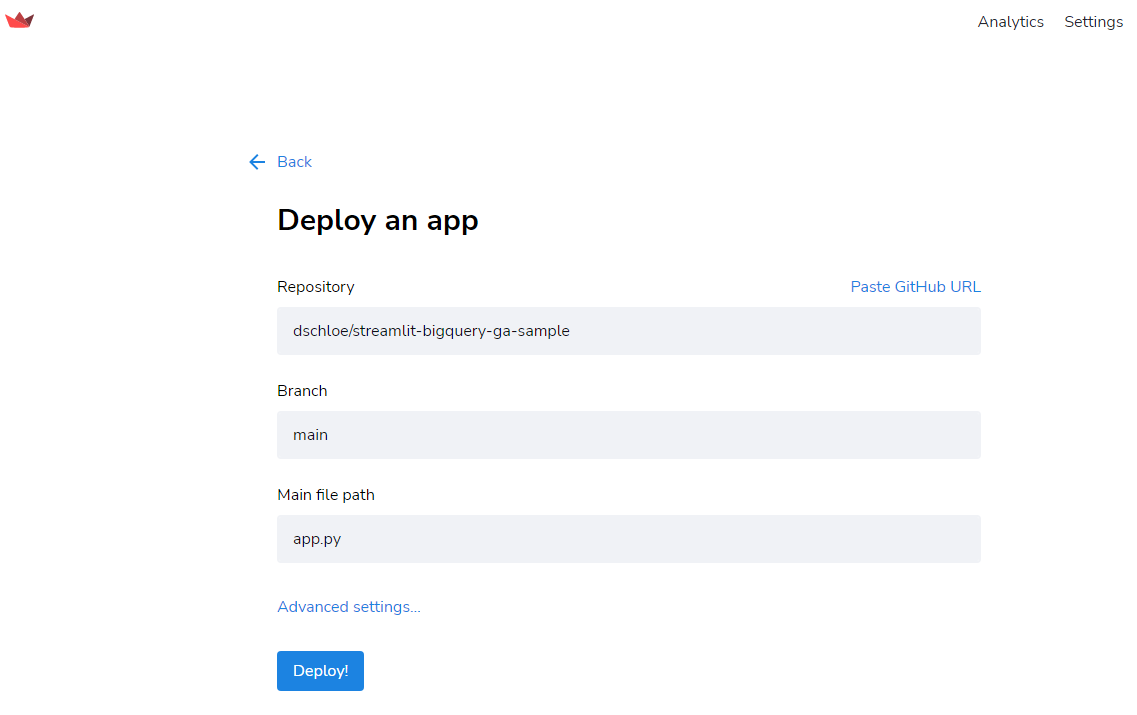
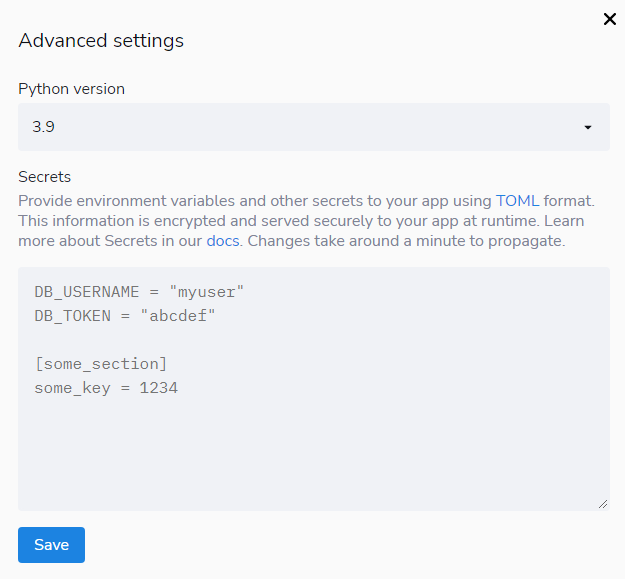
- 빅쿼리에서 다운로드 받은 설정 파일을 지정하기 위해
Advanced Settings를 클릭한다. Secrets에 해당secrets.toml코드를 복사하여 붙여넣는다.
Deploy버튼을 클릭한다.

