Heroku를 활용한 카카오챗봇 배포 - DB조회편
Page content
읽기 전 공지
- 본 글은 2022년 11월 28일까지만 유효합니다. 무료 버전이 사라지기 때문에, 앞으로 어떻게 될지는 현재 글 쓰는 시점에서는 모릅니다. 이 부분에 주의해서 참고 하시기를 바랍니다.
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

- [비전공자 대환영] 캐글 데이터를 활용한 Optuna with MLFlow - 캐글다지기
- 머신러닝 하이퍼파라미터 튜닝 등을 배우고 싶다면 다음 강의를 참고하세요.

개요
- Flask를 활용하여 챗봇을 구현한다.
개요
- Flask를 활용하여 챗봇을 구현한다.
사전준비
- 카카오 챗봇에 가입을 해야 한다.
- Heroku 설정이 되어 있어야 한다.
- 이전 포스트에서 챗봇 인사말 예로 챗봇 배포를 진행했다.
- 이전 포스트에서 사칙연산을 예로 챗봇 배포를 진행했다.
app.py 파일 수정
- 기존 코드에서 다음 코드를 추가한다.
- 주어진 예제는 다음과 같다.
- sepal_length의 특정 길이보다 조회를 한다.
- 컬럼은 sepal_length, species만 조회한다.
- 시나리오는 아래 질문과 같다.
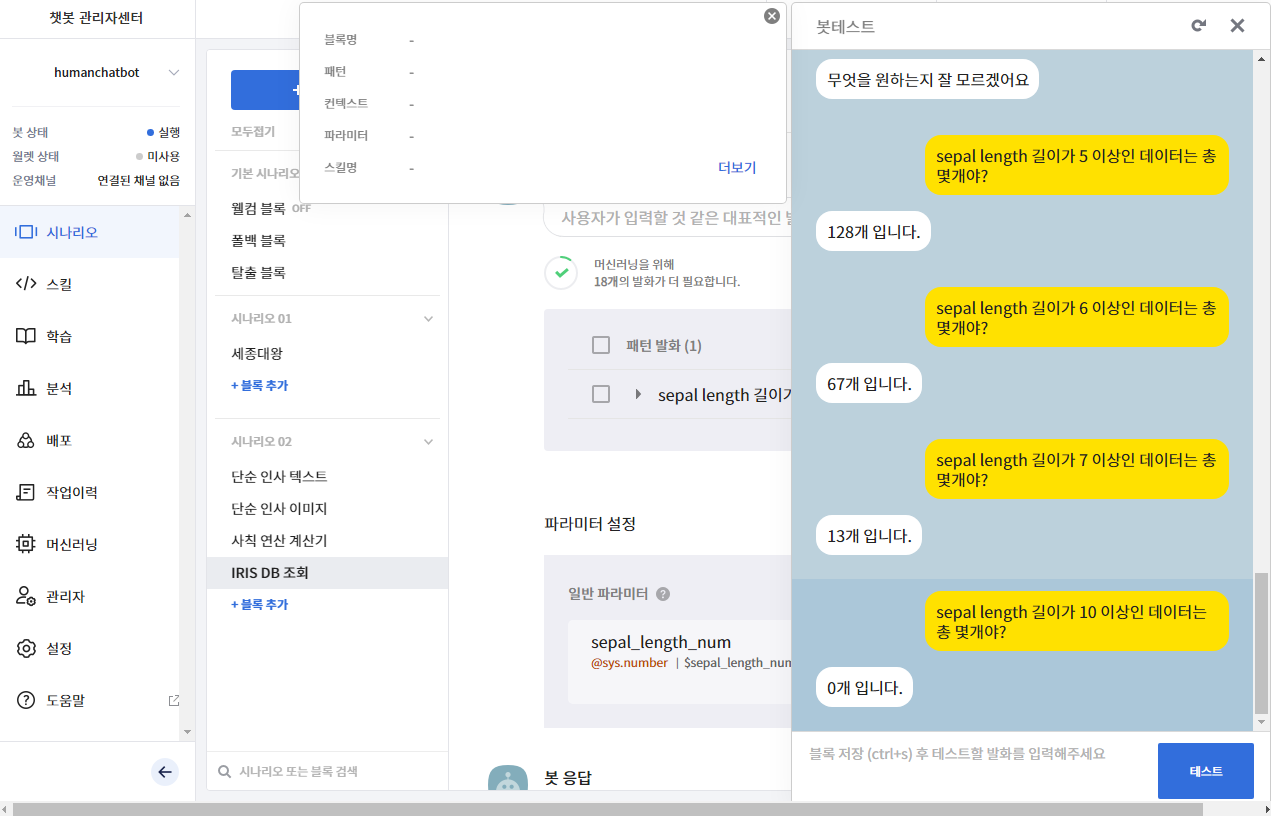
sepal length 길이가 5 이상인 데이터는 총 몇개야?
- 숫자 5를 변수로 활용한다. 즉, 실제 사용자가 숫자 5 대신에 다른 숫자를 입력하면 그게 맞는 결과가 나온다.
.
.
from sqlalchemy.sql import text
.
.
## Query 조회
@application.route('/api/querySQL', methods=['POST'])
def querySQL():
body = request.get_json()
params_df = body['action']['params']
sepal_length_num = str(json.loads(params_df['sepal_length_num'])['amount'])
print(sepal_length_num, type(sepal_length_num))
query_str = f'''
SELECT sepal_length, species FROM iris where sepal_length >= {sepal_length_num}
'''
engine = create_engine("postgresql://your_uri/your_uri", echo = False)
with engine.connect() as conn:
query = conn.execute(text(query_str))
df = pd.DataFrame(query.fetchall())
nrow_num = str(len(df.index))
answer_text = nrow_num
responseBody = {
"version": "2.0",
"template": {
"outputs": [
{
"simpleText": {
"text": answer_text + "개 입니다."
}
}
]
}
}
return responseBody
- 소스코드가 완성이 되었다면, Heroku에 배포를 진행한다.
git add .
git commit -m "updated"
git push && git push heroku main
스킬 등록
- 이제 스킬 등록을 한다.
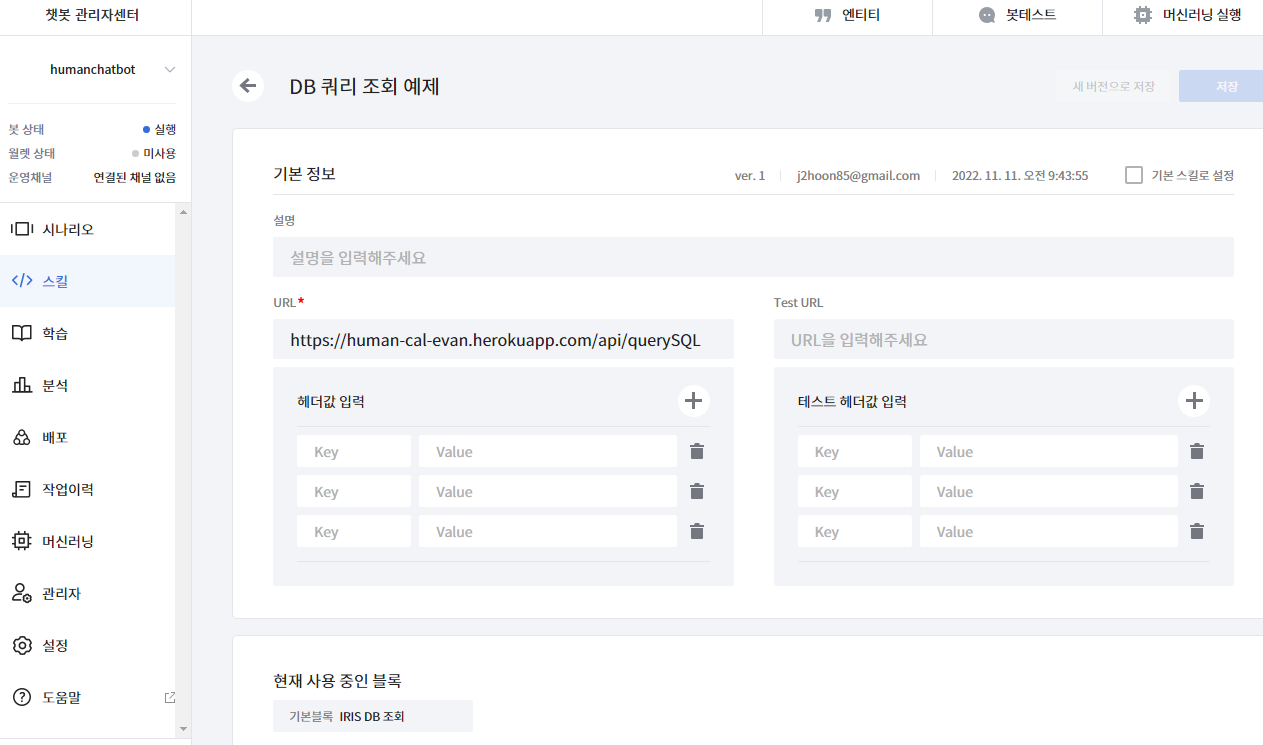
시나리오 작성
- 이제 시나리오를 작성하도록 한다.
- 파라미터 설정에 등록된 스킬을 불러온다.
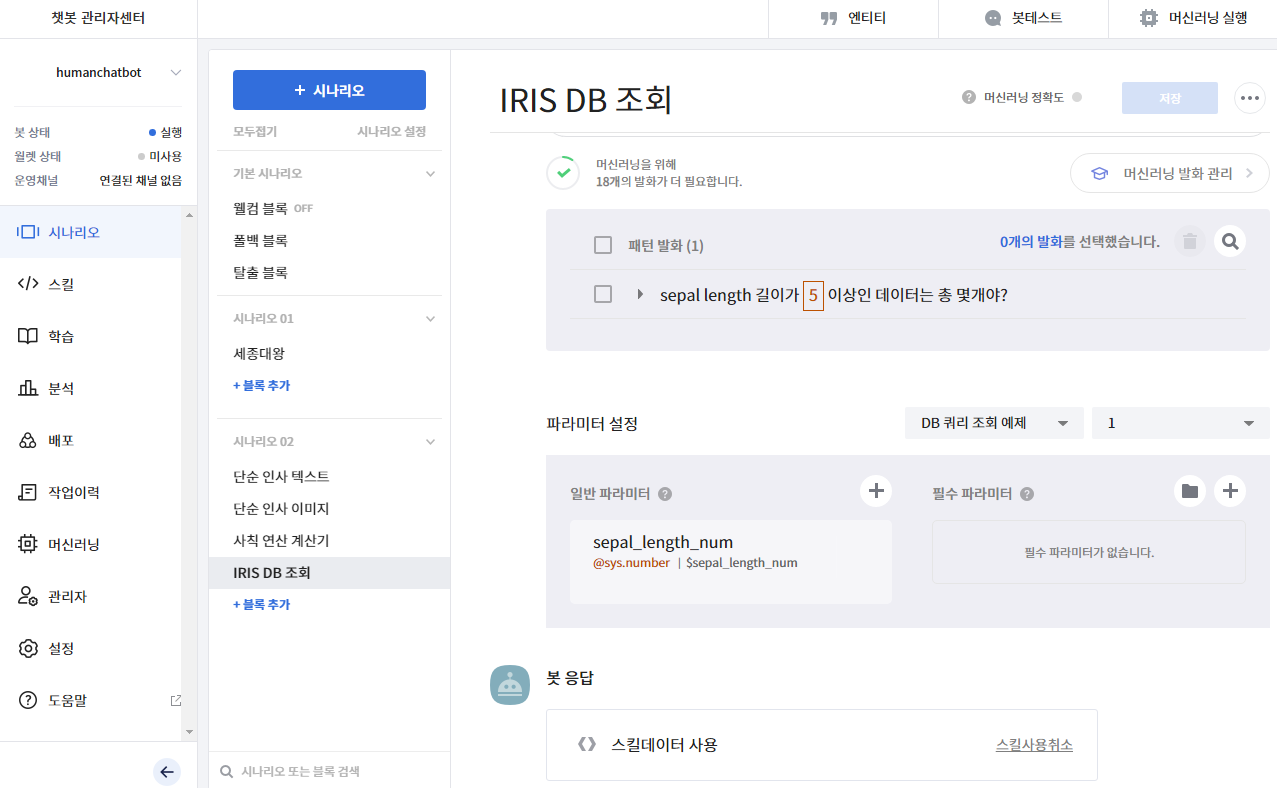
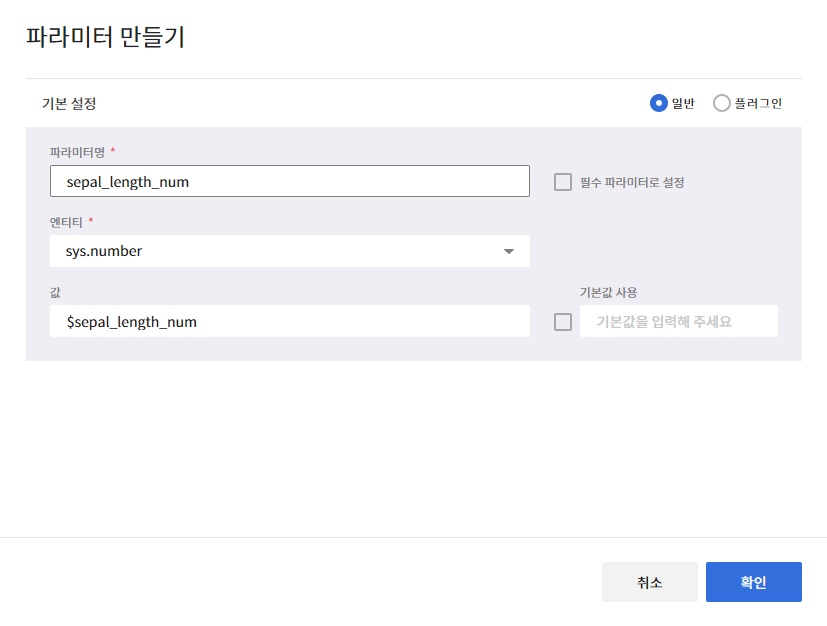
- 파라미터 설정 값은 아래와 같이 바꾼다.
배포 & 테스트
- 시나리오가 완성이 되면 배포를 진행한다.
- 테스트를 진행한다.
- 숫자를 변경할 때마다 결괏값이 다르게 나타나는 것을 확인할 수 있다.