Kaggle Feature Engineering - House Price
Page content
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

공지
- 현재 책 출판 준비 중입니다.
- 구체적인 설명은 책이 출판된 이후에 요약해서 올리도록 합니다.
Kaggle API
Kaggle API를 활용한 데이터를 수집하는 예제는 Feature Engineering with Housing Price Prediction - Numerical Features 에서도 확인할 수 있기 때문에 생략 합니다.
데이터 다운로드 및 불러오기
- 데이터를 불러옵니다.
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
print('Data Loading is done!')
Data Loading is done!
데이터 둘러보기
- 총 변수의 개수를 확인합니다.
print("The shape of Train Data is:", train.shape)
print("The shape of Test Data is:", test.shape)
The shape of Train Data is: (1460, 81)
The shape of Test Data is: (1459, 80)
Feature Engineering
- Feature Engineering은 크게 데이터를 가공 하고, 또한 변환하는 가정을 동반합니다.
이상치 제거
- 이상치를 제거하는 코드입니다.
train.drop(train[(train['OverallQual']<4) & (train['SalePrice']> 200000)].index, inplace=True)
train.drop(train[(train['OverallCond']<4) & (train['SalePrice']> 200000)].index, inplace=True)
train.reset_index(drop=True, inplace=True)
print(train.shape)
(1458, 81)
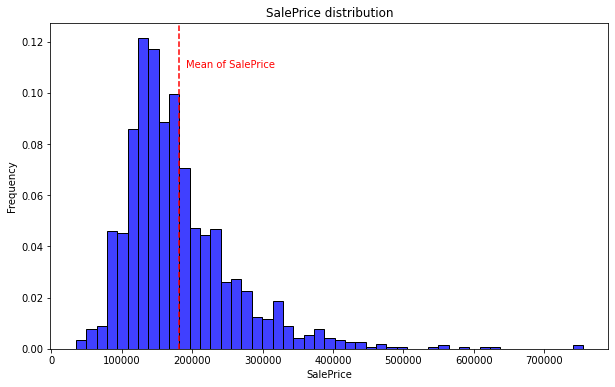
종속변수의 로그 변환
- 주택 가격처럼 가격의 차이가 큰 경우에는 로그 변환으로 변경하는 것이 중요합니다.
- 로그 변환 하기전의 시각화 입니다.
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
(mu, sigma) = norm.fit(train['SalePrice'])
print("The value of mu before log transformation is:", mu)
print("The value of sigma before log transformation is:", sigma)
fig, ax = plt.subplots(figsize=(10, 6))
sns.histplot(train['SalePrice'], color="b", stat="probability")
ax.xaxis.grid(False)
ax.set(ylabel="Frequency")
ax.set(xlabel="SalePrice")
ax.set(title="SalePrice distribution")
plt.axvline(mu, color='r', linestyle='--')
plt.text(mu + 10000, 0.11, 'Mean of SalePrice', rotation=0, color='r')
fig.show()
The value of mu before log transformation is: 180761.24142661178
The value of sigma before log transformation is: 79270.93617295024
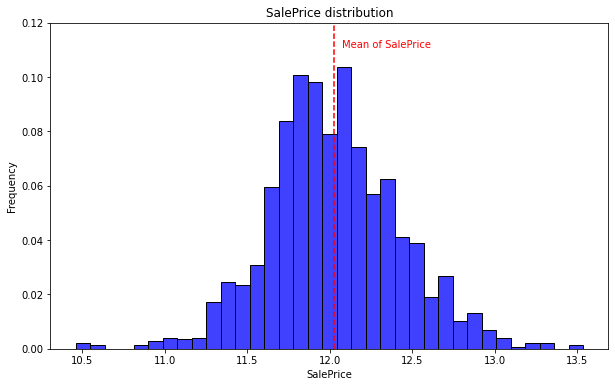
- 로그 변환 후의 시각화 입니다.
import numpy as np
train["SalePrice"] = np.log1p(train["SalePrice"])
(mu, sigma) = norm.fit(train['SalePrice'])
print("The value of mu before log transformation is:", mu)
print("The value of sigma before log transformation is:", sigma)
fig, ax = plt.subplots(figsize=(10, 6))
sns.histplot(train['SalePrice'], color="b", stat="probability")
ax.xaxis.grid(False)
ax.set(ylabel="Frequency")
ax.set(xlabel="SalePrice")
ax.set(title="SalePrice distribution")
plt.axvline(mu, color='r', linestyle='--')
plt.text(mu + 0.05, 0.111, 'Mean of SalePrice', rotation=0, color='r')
plt.ylim(0, 0.12)
fig.show()
The value of mu before log transformation is: 12.0233397799989
The value of sigma before log transformation is: 0.3989191793099824
데이터 ID 값 제거
- ID 변수는 머신러닝 모형의 입력변수로 넣지 않습니다.
train_ID = train['Id']
test_ID = test['Id']
train.drop(['Id'], axis=1, inplace=True)
test.drop(['Id'], axis=1, inplace=True)
train.shape, test.shape
((1458, 80), (1459, 79))
Y값 추출
- y값은 별도로 추출합니다. test 데이터에는 없기 때문에, 추출하여 별도로 저장합니다.
y = train[['SalePrice']].reset_index(drop=True)
train = train.drop('SalePrice', axis = 1)
train.shape, test.shape
((1458, 79), (1459, 79))
데이터 합치기
- 변수의 갯수가 똑같다면, 데이터를 합칠 수 있습니다.
all_df = pd.concat([train, test]).reset_index(drop=True)
all_df.shape
(2917, 79)
결측치 확인
- 결측치를 체크하는 함수를 정의 합니다.
def check_na(data, head_num = 6):
isnull_na = (data.isnull().sum() / len(data)) * 100
data_na = isnull_na.drop(isnull_na[isnull_na == 0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'Missing Ratio' :data_na,
'Data Type': data.dtypes[data_na.index]})
print("결측치 데이터 컬럼과 건수:\n", missing_data.head(head_num))
check_na(all_df, 20)
결측치 데이터 컬럼과 건수:
Missing Ratio Data Type
PoolQC 99.657182 object
MiscFeature 96.400411 object
Alley 93.212204 object
Fence 80.425094 object
FireplaceQu 48.680151 object
LotFrontage 16.626671 float64
GarageFinish 5.450806 object
GarageYrBlt 5.450806 float64
GarageQual 5.450806 object
GarageCond 5.450806 object
GarageType 5.382242 object
BsmtExposure 2.811107 object
BsmtCond 2.811107 object
BsmtQual 2.776826 object
BsmtFinType2 2.742544 object
BsmtFinType1 2.708262 object
MasVnrType 0.788481 object
MasVnrArea 0.754200 float64
MSZoning 0.137127 object
BsmtFullBath 0.068564 float64
결측치 제거
- 결측치의 비율이 많은 변수들은 제거합니다.
all_df.drop(['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu', 'LotFrontage'], axis=1, inplace=True)
check_na(all_df)
결측치 데이터 컬럼과 건수:
Missing Ratio Data Type
GarageQual 5.450806 object
GarageFinish 5.450806 object
GarageYrBlt 5.450806 float64
GarageCond 5.450806 object
GarageType 5.382242 object
BsmtCond 2.811107 object
결측치 채우기
- 이제 결측치를 채우도록 합니다.
print(all_df['BsmtCond'].value_counts())
print()
print(all_df['BsmtCond'].mode()[0])
TA 2604
Gd 122
Fa 104
Po 5
Name: BsmtCond, dtype: int64
TA
import numpy as np
cat_all_vars = train.select_dtypes(exclude=[np.number])
print("The whole number of all_vars", len(list(cat_all_vars)))
final_cat_vars = []
for v in cat_all_vars:
if v not in ['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu', 'LotFrontage']:
final_cat_vars.append(v)
print("The whole number of final_cat_vars", len(final_cat_vars))
for i in final_cat_vars:
all_df[i] = all_df[i].fillna(all_df[i].mode()[0])
check_na(all_df, 20)
The whole number of all_vars 43
The whole number of final_cat_vars 38
결측치 데이터 컬럼과 건수:
Missing Ratio Data Type
GarageYrBlt 5.450806 float64
MasVnrArea 0.754200 float64
BsmtHalfBath 0.068564 float64
BsmtFullBath 0.068564 float64
GarageArea 0.034282 float64
GarageCars 0.034282 float64
TotalBsmtSF 0.034282 float64
BsmtUnfSF 0.034282 float64
BsmtFinSF2 0.034282 float64
BsmtFinSF1 0.034282 float64
import numpy as np
num_all_vars = list(train.select_dtypes(include=[np.number]))
print("The whole number of all_vars", len(num_all_vars))
num_all_vars.remove('LotFrontage')
print("The whole number of final_cat_vars", len(num_all_vars))
for i in num_all_vars:
all_df[i].fillna(value=all_df[i].median(), inplace=True)
check_na(all_df, 20)
The whole number of all_vars 36
The whole number of final_cat_vars 35
결측치 데이터 컬럼과 건수:
Empty DataFrame
Columns: [Missing Ratio, Data Type]
Index: []
왜도(Skewnewss) 처리하기
- 왜도 값을 추출하여 수치 데이터의 대칭성을 확인합니다.
from scipy.stats import skew
def find_skew(x):
return skew(x)
skewness_features = all_df[num_all_vars].apply(find_skew).sort_values(ascending=False)
skewness_features
MiscVal 21.939672
PoolArea 16.892477
LotArea 12.867139
LowQualFinSF 12.084539
3SsnPorch 11.372080
KitchenAbvGr 4.318923
BsmtFinSF2 4.144503
EnclosedPorch 4.013741
ScreenPorch 3.945101
BsmtHalfBath 3.929996
MasVnrArea 2.615714
OpenPorchSF 2.534326
WoodDeckSF 1.841876
1stFlrSF 1.469798
BsmtFinSF1 1.429239
MSSubClass 1.374726
GrLivArea 1.271773
TotalBsmtSF 1.165468
BsmtUnfSF 0.919795
2ndFlrSF 0.860643
TotRmsAbvGrd 0.760404
Fireplaces 0.734449
HalfBath 0.695072
BsmtFullBath 0.626733
OverallCond 0.584601
BedroomAbvGr 0.329555
GarageArea 0.241611
OverallQual 0.196514
MoSold 0.195229
FullBath 0.164226
YrSold 0.132129
GarageCars -0.218309
GarageYrBlt -0.398311
YearRemodAdd -0.451063
YearBuilt -0.600023
dtype: float64
skewnewss_index = list(skewness_features.index)
skewnewss_index.remove('LotArea')
all_numeric_df = all_df.loc[:, skewnewss_index]
fig, ax = plt.subplots(figsize=(10, 6))
ax.set_xlim(0, all_numeric_df.max().sort_values(ascending=False)[0])
ax = sns.boxplot(data=all_numeric_df[skewnewss_index] , orient="h", palette="Set1")
ax.xaxis.grid(False)
ax.set(ylabel="Feature names")
ax.set(xlabel="Numeric values")
ax.set(title="Numeric Distribution of Features Before Box-Cox Transformation")
sns.despine(trim=True, left=True)
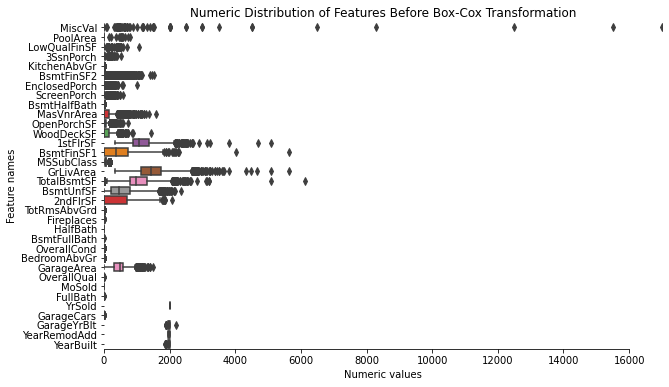
- Box-Cox 변환을 시도합니다.
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
high_skew = skewness_features[skewness_features > 1]
high_skew_index = high_skew.index
print("The data before Box-Cox Transformation: \n", all_df[high_skew_index].head())
for num_var in high_skew_index:
all_df[num_var] = boxcox1p(all_df[num_var], boxcox_normmax(all_df[num_var] + 1))
print("The data after Box-Cox Transformation: \n", all_df[high_skew_index].head())
The data before Box-Cox Transformation:
MiscVal PoolArea LotArea ... MSSubClass GrLivArea TotalBsmtSF
0 0 0 8450 ... 60 1710 856.0
1 0 0 9600 ... 20 1262 1262.0
2 0 0 11250 ... 60 1786 920.0
3 0 0 9550 ... 70 1717 756.0
4 0 0 14260 ... 60 2198 1145.0
[5 rows x 18 columns]
The data after Box-Cox Transformation:
MiscVal PoolArea LotArea ... MSSubClass GrLivArea TotalBsmtSF
0 0.0 0.0 13.454344 ... 6.505897 7.219262 294.614887
1 0.0 0.0 13.725427 ... 4.252612 6.933523 404.051498
2 0.0 0.0 14.066408 ... 6.505897 7.260108 312.423510
3 0.0 0.0 13.714276 ... 6.869385 7.223100 266.274241
4 0.0 0.0 14.584552 ... 6.505897 7.454890 373.304502
[5 rows x 18 columns]
/usr/local/lib/python3.6/dist-packages/scipy/stats/stats.py:3508: PearsonRConstantInputWarning: An input array is constant; the correlation coefficent is not defined.
warnings.warn(PearsonRConstantInputWarning())
/usr/local/lib/python3.6/dist-packages/scipy/stats/stats.py:3538: PearsonRNearConstantInputWarning: An input array is nearly constant; the computed correlation coefficent may be inaccurate.
warnings.warn(PearsonRNearConstantInputWarning())
fig, ax = plt.subplots(figsize=(10, 6))
ax.set_xscale('log')
ax = sns.boxplot(data=all_df[high_skew_index] , orient="h", palette="Set1")
ax.xaxis.grid(False)
ax.set(ylabel="Feature names")
ax.set(xlabel="Numeric values")
ax.set(title="Numeric Distribution of Features Before Box-Cox Transformation")
sns.despine(trim=True, left=True)
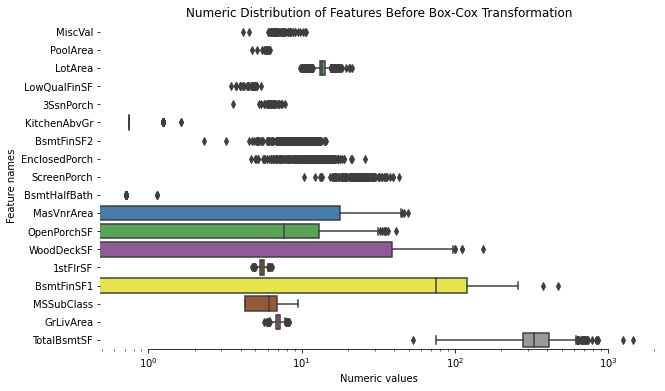
도출 변수
- 도출 변수를 만든 후, 참조한 변수는 삭제하도록 합니다.
all_df['TotalSF'] = all_df['TotalBsmtSF'] + all_df['1stFlrSF'] + all_df['2ndFlrSF']
all_df = all_df.drop(['TotalBsmtSF', '1stFlrSF', '2ndFlrSF'], axis=1)
print(all_df.shape)
(2917, 71)
all_df['Total_Bathrooms'] = (all_df['FullBath'] + (0.5 * all_df['HalfBath']) + all_df['BsmtFullBath'] + (0.5 * all_df['BsmtHalfBath']))
all_df['Total_porch_sf'] = (all_df['OpenPorchSF'] + all_df['3SsnPorch'] + all_df['EnclosedPorch'] + all_df['ScreenPorch'])
all_df = all_df.drop(['FullBath', 'HalfBath', 'BsmtFullBath', 'BsmtHalfBath', 'OpenPorchSF', '3SsnPorch', 'EnclosedPorch', 'ScreenPorch'], axis=1)
print(all_df.shape)
(2917, 65)
num_all_vars = list(train.select_dtypes(include=[np.number]))
year_feature = []
for var in num_all_vars:
if 'Yr' in var:
year_feature.append(var)
elif 'Year' in var:
year_feature.append(var)
else:
print(var, "is not related with Year")
print(year_feature)
MSSubClass is not related with Year
LotFrontage is not related with Year
LotArea is not related with Year
OverallQual is not related with Year
OverallCond is not related with Year
MasVnrArea is not related with Year
BsmtFinSF1 is not related with Year
BsmtFinSF2 is not related with Year
BsmtUnfSF is not related with Year
TotalBsmtSF is not related with Year
1stFlrSF is not related with Year
2ndFlrSF is not related with Year
LowQualFinSF is not related with Year
GrLivArea is not related with Year
BsmtFullBath is not related with Year
BsmtHalfBath is not related with Year
FullBath is not related with Year
HalfBath is not related with Year
BedroomAbvGr is not related with Year
KitchenAbvGr is not related with Year
TotRmsAbvGrd is not related with Year
Fireplaces is not related with Year
GarageCars is not related with Year
GarageArea is not related with Year
WoodDeckSF is not related with Year
OpenPorchSF is not related with Year
EnclosedPorch is not related with Year
3SsnPorch is not related with Year
ScreenPorch is not related with Year
PoolArea is not related with Year
MiscVal is not related with Year
MoSold is not related with Year
['YearBuilt', 'YearRemodAdd', 'GarageYrBlt', 'YrSold']
fig, ax = plt.subplots(3, 1, figsize=(10, 6), sharex=True, sharey=True)
for i, var in enumerate(year_feature):
if var != 'YrSold':
ax[i].scatter(train[var], y, alpha=0.3)
ax[i].set_title('{}'.format(var), size=15)
ax[i].set_ylabel('SalePrice', size=15, labelpad=12.5)
plt.tight_layout()
plt.show()
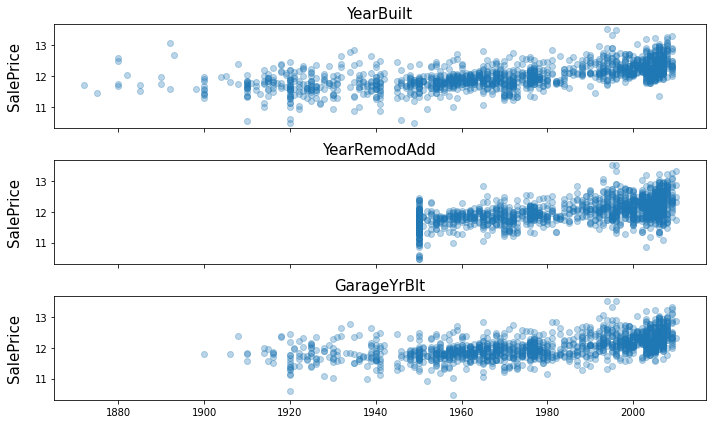
all_df = all_df.drop(['YearBuilt', 'GarageYrBlt'], axis=1)
print(all_df.shape)
(2917, 63)
YearsSinceRemodel = train['YrSold'].astype(int) - train['YearRemodAdd'].astype(int)
fig, ax = plt.subplots(figsize=(10, 6))
ax.scatter(YearsSinceRemodel, y, alpha=0.3)
fig.show()
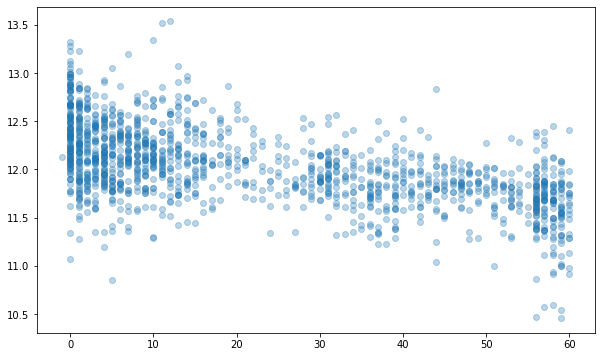
all_df['YearsSinceRemodel'] = all_df['YrSold'].astype(int) - all_df['YearRemodAdd'].astype(int)
all_df = all_df.drop(['YrSold', 'YearRemodAdd'], axis=1)
print(all_df.shape)
(2917, 62)
더미 변수
- Count 기반의 데이터를 가지고 더미 변수를 만드는 과정을 진행합니다.
all_df['PoolArea'].value_counts()
0.000000 2904
4.721829 1
5.913421 1
6.161330 1
5.854879 1
5.786591 1
5.553561 1
5.843016 1
6.048366 1
5.130821 1
6.231252 1
5.945809 1
5.922801 1
5.718338 1
Name: PoolArea, dtype: int64
def count_dummy(x):
if x > 0:
return 1
else:
return 0
all_df['PoolArea'] = all_df['PoolArea'].apply(count_dummy)
all_df['PoolArea'].value_counts()
0 2904
1 13
Name: PoolArea, dtype: int64
all_df['GarageArea'] = all_df['GarageArea'].apply(count_dummy)
all_df['GarageArea'].value_counts()
1 2760
0 157
Name: GarageArea, dtype: int64
all_df['Fireplaces'] = all_df['Fireplaces'].apply(count_dummy)
all_df['Fireplaces'].value_counts()
1 1497
0 1420
Name: Fireplaces, dtype: int64
라벨 인코딩 vs 원핫 인코딩
- 자세한 설명은 Label Encoding vs One-Hot Encoding를 참조 하시기를 바랍니다.
from sklearn.preprocessing import LabelEncoder
import pandas as pd
temp = pd.DataFrame({'Food_Name': ['Apple', 'Chicken', 'Broccoli'],
'Calories': [95, 231, 50]})
encoder = LabelEncoder()
encoder.fit(temp['Food_Name'])
labels = encoder.transform(temp['Food_Name'])
print(list(temp['Food_Name']), "==>", labels)
['Apple', 'Chicken', 'Broccoli'] ==> [0 2 1]
import pandas as pd
temp = pd.DataFrame({'Food_Name': ['Apple', 'Chicken', 'Broccoli'],
'Calories': [95, 231, 50]})
temp = pd.get_dummies(temp)
print(temp)
print(temp.shape)
Calories Food_Name_Apple Food_Name_Broccoli Food_Name_Chicken
0 95 1 0 0
1 231 0 0 1
2 50 0 1 0
(3, 4)
all_df = pd.get_dummies(all_df).reset_index(drop=True)
all_df.shape
(2917, 258)
