ACEA Water, Intro to Time Series Forecasting
Page content
강의 홍보
- 취준생을 위한 강의를 제작하였습니다.
- 본 블로그를 통해서 강의를 수강하신 분은 게시글 제목과 링크를 수강하여 인프런 메시지를 통해 보내주시기를 바랍니다.
스타벅스 아이스 아메리카노를 선물로 보내드리겠습니다.
- [비전공자 대환영] 제로베이스도 쉽게 입문하는 파이썬 데이터 분석 - 캐글입문기

Overview
Can you build a model to predict the amount of water in each waterbody to help preserve this natural resource? This is an Analytics competition where your task is to create a Notebook that best addresses the Evaluation criteria below. Submissions should be shared directly with host and will be judged by the Acea Group based on how well they addrss:
Methodology/Completeness (min 0 points, max 5 points)
- Are the statistical models appropriate given the data?
- Did the author develop one or more machine learning models?
- Did the author provide a way of assessing the performance and accuracy of their solution?
- What is the Mean Absolute Error (MAE) of the models?
- What is the Root Mean Square Error (RMSE) of the models?
Presentation (min 0 points, max 5 points)
- Does the notebook have a compelling and coherent narrative?
- Does the notebook contain data visualizations that help to communicate the author’s main points?
- Did the author include a thorough discussion on the intersection between features and their prediction? For example between rainfall and amount/level of water.
- Was there discussion of automated insight generation, demonstrating what factors to take into account?
- Is the code documented in a way that makes it easy to understand and reproduce?
- Were all external sources of data made public and cited appropriately?
Application (min 0 points, max 5 points)
- Is the provided model useful/able to forecast water availability in terms of level or water flow in a time interval of the year?
- Is the provided methodology applicable also on new datasets belong to another waterbody?
1. Problem Definition
- It’s generally difficult to define problem. Since the goal of this competition is to build a model predict the depth to groundwater or river of an aquifer located in Petrignano, Italy, the problem definition could be related with the future prediction.
1.1 📊 Quick EDA 📈
- To explore data, let’s import relevant libraries
import numpy as np # Linear Algebra
import pandas as pd # Data Processing, CSV File I/O
import seaborn as sns # Visualisation
import matplotlib.pyplot as plt # Visualisation
from matplotlib.patches import Rectangle # Helper
import os # PATH
PATH = "../input/acea-water-prediction/"
aquifer_auser = pd.read_csv(f"{PATH}Aquifer_Auser.csv")
aquifer_doganella = pd.read_csv(f"{PATH}Aquifer_Doganella.csv")
aquifer_luco = pd.read_csv(f"{PATH}Aquifer_Luco.csv")
aquifer_petrignano = pd.read_csv(f"{PATH}Aquifer_Petrignano.csv")
lake_biliancino = pd.read_csv(f"{PATH}Lake_Bilancino.csv")
river_arno = pd.read_csv(f"{PATH}River_Arno.csv")
water_spring_amiata = pd.read_csv(f"{PATH}Water_Spring_Amiata.csv")
water_spring_lupa = pd.read_csv(f"{PATH}Water_Spring_Lupa.csv")
water_spring_madonna = pd.read_csv(f"{PATH}Water_Spring_Madonna_di_Canneto.csv")
- To understand each dataset, we will make temp_df dataset, given column category such as Date, Rainfall, Depth, Volume, Hydrometry, Lake_Level, Flow_Rate. Through this, We will know more about the common and difference between datasets.
datasets = []
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
if '.csv' in filename:
datasets += list([filename])
print("The datasets:", datasets)
datasets_df = pd.DataFrame(columns=['filename'], data=datasets)
datasets_df['waterbody_type'] = datasets_df.filename.apply(lambda x: x.split('_')[0])
print("The datasets_df:", datasets_df)
f, ax = plt.subplots(nrows=1, ncols=2, figsize=(24,6), gridspec_kw={'width_ratios': [1,2]})
sns.countplot(datasets_df.waterbody_type, palette=['lightblue'], ax= ax[0])
ax[0].set_title('Datasets', fontsize=16)
ax[0].set_ylabel('Number of Datasets', fontsize=14)
ax[0].set_ylim(0, 5)
ax[0].set_xlabel('Waterbody Type', fontsize=14)
ax[0].set_xticklabels(labels=['Aquifer', 'Water Spring', 'Lake', 'River'], fontsize=14)
def get_column_category(x):
if 'Date' in x:
return 'Date'
elif 'Rainfall' in x:
return 'Rainfall'
elif 'Depth' in x:
return 'Depth to Groundwater'
elif 'Temperature' in x:
return 'Temperature'
elif 'Volume' in x:
return 'Volume'
elif 'Hydrometry' in x:
return 'Hydrometry'
elif 'Lake_Level' in x:
return 'Lake Level'
elif 'Flow_Rate' in x:
return 'Flow Rate'
else:
return x
temp_df = pd.DataFrame({'column_name' : aquifer_auser.columns, 'waterbody_type':'Aquifer Auser'})
temp_df = temp_df.append(pd.DataFrame({'column_name' : aquifer_doganella.columns, 'waterbody_type':'Aquifer Doganella'}))
temp_df = temp_df.append(pd.DataFrame({'column_name' : aquifer_luco.columns, 'waterbody_type':'Aquifer Luco'}))
temp_df = temp_df.append(pd.DataFrame({'column_name' : aquifer_petrignano.columns, 'waterbody_type':'Aquifer Petrignano'}))
temp_df = temp_df.append(pd.DataFrame({'column_name' : lake_biliancino.columns, 'waterbody_type':'Lake Biliancino'}))
temp_df = temp_df.append(pd.DataFrame({'column_name' : river_arno.columns, 'waterbody_type':'River Arno'}))
temp_df = temp_df.append(pd.DataFrame({'column_name' : water_spring_amiata.columns, 'waterbody_type':'Water Spring Amiata'}))
temp_df = temp_df.append(pd.DataFrame({'column_name' : water_spring_lupa.columns, 'waterbody_type':'Water Spring Lupa'}))
temp_df = temp_df.append(pd.DataFrame({'column_name' : water_spring_madonna.columns, 'waterbody_type':'Water Spring Madonna'}))
temp_df['column_category'] = temp_df.column_name.apply(lambda x: get_column_category(x))
temp_df = temp_df.groupby('waterbody_type').column_category.value_counts().to_frame()
temp_df.columns = ['counts']
temp_df = temp_df.reset_index(drop=False)
temp_df = temp_df.pivot(index='waterbody_type', columns='column_category')['counts']
temp_df['Number of Features in Dataset'] = temp_df.sum(axis=1)
display(temp_df)
sns.heatmap(temp_df, cmap='Blues', linewidth=1, ax=ax[1], vmin=0, vmax=10, annot=True)
#ax[1].set_ylabel('Waterbody Type', fontsize=16)
ax[1].set_ylabel(' ', fontsize=16)
ax[1].set_xlabel('Column Category', fontsize=16)
ax[1].set_title('Features, Number of Columns and Target Variables', fontsize=16)
ax[1].add_patch(Rectangle((1, 0), 1, 4, fill=False, alpha=1, color='dodgerblue', lw=3))
ax[1].add_patch(Rectangle((2, 4), 1, 1, fill=False, alpha=1, color='dodgerblue', lw=3))
ax[1].add_patch(Rectangle((4, 4), 1, 1, fill=False, alpha=1, color='dodgerblue', lw=3))
ax[1].add_patch(Rectangle((3, 5), 1, 1, fill=False, alpha=1, color='dodgerblue', lw=3))
ax[1].add_patch(Rectangle((2, 6), 1, 3, fill=False, alpha=1, color='dodgerblue', lw=3))
for tick in ax[1].xaxis.get_major_ticks():
tick.label.set_fontsize(14)
for tick in ax[1].yaxis.get_major_ticks():
tick.label.set_fontsize(14)
#tick.label.set_rotation('horizontal')
tick.label.set_rotation(45)
plt.show()
The datasets: ['Aquifer_Doganella.csv', 'Aquifer_Auser.csv', 'Water_Spring_Amiata.csv', 'Lake_Bilancino.csv', 'Water_Spring_Madonna_di_Canneto.csv', 'Aquifer_Luco.csv', 'Aquifer_Petrignano.csv', 'Water_Spring_Lupa.csv', 'River_Arno.csv']
The datasets_df: filename waterbody_type
0 Aquifer_Doganella.csv Aquifer
1 Aquifer_Auser.csv Aquifer
2 Water_Spring_Amiata.csv Water
3 Lake_Bilancino.csv Lake
4 Water_Spring_Madonna_di_Canneto.csv Water
5 Aquifer_Luco.csv Aquifer
6 Aquifer_Petrignano.csv Aquifer
7 Water_Spring_Lupa.csv Water
8 River_Arno.csv River
/opt/conda/lib/python3.7/site-packages/seaborn/_decorators.py:43: FutureWarning: Pass the following variable as a keyword arg: x. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
FutureWarning
| column_category | Date | Depth to Groundwater | Flow Rate | Hydrometry | Lake Level | Rainfall | Temperature | Volume | Number of Features in Dataset |
|---|---|---|---|---|---|---|---|---|---|
| waterbody_type | |||||||||
| Aquifer Auser | 1.0 | 5.0 | NaN | 2.0 | NaN | 10.0 | 4.0 | 5.0 | 27.0 |
| Aquifer Doganella | 1.0 | 9.0 | NaN | NaN | NaN | 2.0 | 2.0 | 8.0 | 22.0 |
| Aquifer Luco | 1.0 | 4.0 | NaN | NaN | NaN | 10.0 | 4.0 | 3.0 | 22.0 |
| Aquifer Petrignano | 1.0 | 2.0 | NaN | 1.0 | NaN | 1.0 | 2.0 | 1.0 | 8.0 |
| Lake Biliancino | 1.0 | NaN | 1.0 | NaN | 1.0 | 5.0 | 1.0 | NaN | 9.0 |
| River Arno | 1.0 | NaN | NaN | 1.0 | NaN | 14.0 | 1.0 | NaN | 17.0 |
| Water Spring Amiata | 1.0 | 3.0 | 4.0 | NaN | NaN | 5.0 | 3.0 | NaN | 16.0 |
| Water Spring Lupa | 1.0 | NaN | 1.0 | NaN | NaN | 1.0 | NaN | NaN | 3.0 |
| Water Spring Madonna | 1.0 | NaN | 1.0 | NaN | NaN | 1.0 | 1.0 | NaN | 4.0 |
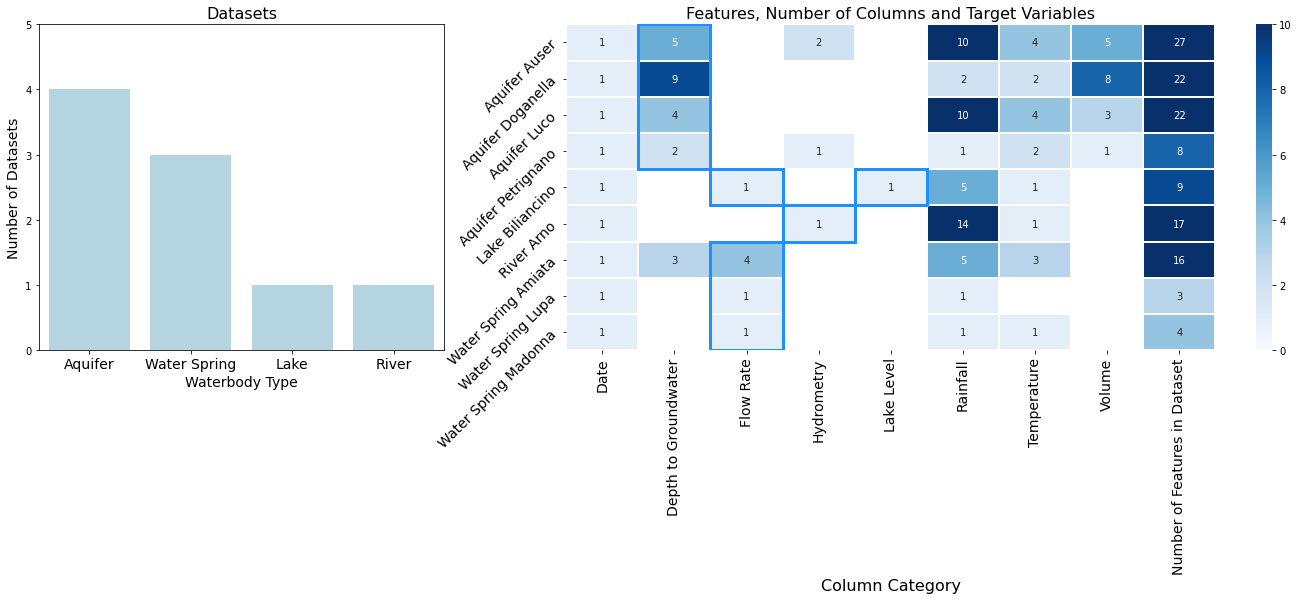
- Both Date and Rainfall appear in all datasets
- Temperature appear in all datasets except Water Spring Lupa.
- Target Variables are shared in the right figure.
- The Rectangle figure indicates target variable - Depth To Groundwater, Flow Rate, Hydrometry Lake Level
- Since I have no good knowledge of Water Engineering, it’s necessary to define each target variables.
- Depth to Groundwater: groundwater level detected by the piezometer (m from the ground floor)
- Flow Rate (water spring/aquifer): flow rate (l/s)
- Flow Rate (lake): flow rate ($m^3$/s)
- Hydrometry: groundwater level detected by the hydrometric station (m)
- Lake Level: river level (m)
1.2 Picking Data ❗
- Since this Notebook is for newbie studying time series analysis and forecasting, it will begin with one dataset, Lake Biliancino
- Let’s explore Water Spring Lupa data
Lake_Bilancino = pd.read_csv(f"{PATH}Lake_Bilancino.csv")
display(Lake_Bilancino)
Lake_Bilancino.info()
| Date | Rainfall_S_Piero | Rainfall_Mangona | Rainfall_S_Agata | Rainfall_Cavallina | Rainfall_Le_Croci | Temperature_Le_Croci | Lake_Level | Flow_Rate | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 03/06/2002 | NaN | NaN | NaN | NaN | NaN | NaN | 249.43 | 0.31 |
| 1 | 04/06/2002 | NaN | NaN | NaN | NaN | NaN | NaN | 249.43 | 0.31 |
| 2 | 05/06/2002 | NaN | NaN | NaN | NaN | NaN | NaN | 249.43 | 0.31 |
| 3 | 06/06/2002 | NaN | NaN | NaN | NaN | NaN | NaN | 249.43 | 0.31 |
| 4 | 07/06/2002 | NaN | NaN | NaN | NaN | NaN | NaN | 249.44 | 0.31 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6598 | 26/06/2020 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 22.50 | 250.85 | 0.60 |
| 6599 | 27/06/2020 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 23.40 | 250.84 | 0.60 |
| 6600 | 28/06/2020 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 21.50 | 250.83 | 0.60 |
| 6601 | 29/06/2020 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 23.20 | 250.82 | 0.60 |
| 6602 | 30/06/2020 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 22.75 | 250.80 | 0.60 |
6603 rows × 9 columns
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6603 entries, 0 to 6602
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 6603 non-null object
1 Rainfall_S_Piero 6026 non-null float64
2 Rainfall_Mangona 6026 non-null float64
3 Rainfall_S_Agata 6026 non-null float64
4 Rainfall_Cavallina 6026 non-null float64
5 Rainfall_Le_Croci 6026 non-null float64
6 Temperature_Le_Croci 6025 non-null float64
7 Lake_Level 6603 non-null float64
8 Flow_Rate 6582 non-null float64
dtypes: float64(8), object(1)
memory usage: 464.4+ KB
- Missing Value appears in some variables.
Lake_Bilancino = Lake_Bilancino.dropna().reset_index(drop=True)
Lake_Bilancino.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6025 entries, 0 to 6024
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 6025 non-null object
1 Rainfall_S_Piero 6025 non-null float64
2 Rainfall_Mangona 6025 non-null float64
3 Rainfall_S_Agata 6025 non-null float64
4 Rainfall_Cavallina 6025 non-null float64
5 Rainfall_Le_Croci 6025 non-null float64
6 Temperature_Le_Croci 6025 non-null float64
7 Lake_Level 6025 non-null float64
8 Flow_Rate 6025 non-null float64
dtypes: float64(8), object(1)
memory usage: 423.8+ KB
- Data Type of Date is object, let’s convert it to datetime
Lake_Bilancino['Date_dt'] = pd.to_datetime(Lake_Bilancino.Date, format = '%d/%m/%Y')
- I have no idea what to do with Rainfall_* variables. So will delete it.
Lake_Bilancino.drop(['Date',
'Rainfall_S_Piero',
'Rainfall_Mangona',
'Rainfall_S_Agata',
'Rainfall_Cavallina',
'Rainfall_Le_Croci'], axis = 1, inplace=True)
display(Lake_Bilancino)
| Temperature_Le_Croci | Lake_Level | Flow_Rate | Date_dt | |
|---|---|---|---|---|
| 0 | 6.50 | 251.21 | 0.5 | 2004-01-02 |
| 1 | 4.45 | 251.28 | 0.5 | 2004-01-03 |
| 2 | 2.00 | 251.35 | 0.5 | 2004-01-04 |
| 3 | 0.90 | 251.37 | 0.5 | 2004-01-05 |
| 4 | 2.25 | 251.42 | 0.5 | 2004-01-06 |
| ... | ... | ... | ... | ... |
| 6020 | 22.50 | 250.85 | 0.6 | 2020-06-26 |
| 6021 | 23.40 | 250.84 | 0.6 | 2020-06-27 |
| 6022 | 21.50 | 250.83 | 0.6 | 2020-06-28 |
| 6023 | 23.20 | 250.82 | 0.6 | 2020-06-29 |
| 6024 | 22.75 | 250.80 | 0.6 | 2020-06-30 |
6025 rows × 4 columns
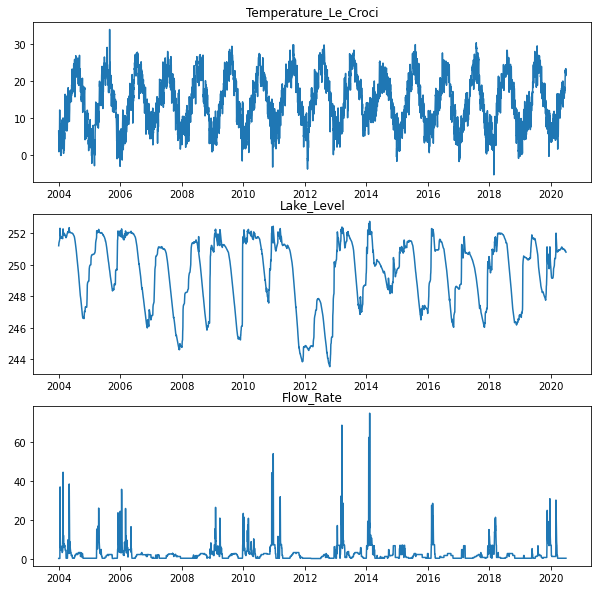
- Let’s Draw Time Series Data
fig, ax = plt.subplots(nrows = 3, ncols = 1, figsize=(10, 10))
ax[0].plot(Lake_Bilancino['Date_dt'], Lake_Bilancino['Temperature_Le_Croci'])
ax[0].set_title("Temperature_Le_Croci")
ax[1].plot(Lake_Bilancino['Date_dt'], Lake_Bilancino['Lake_Level'])
ax[1].set_title("Lake_Level")
ax[2].plot(Lake_Bilancino['Date_dt'], Lake_Bilancino['Flow_Rate'])
ax[2].set_title("Flow_Rate")
plt.show()
Reference Notebook
https://www.kaggle.com/iamleonie/eda-quenching-the-thirst-for-insights
