GCP VM Connect to BigQuery using Streamlit (ver. 2025, 06)
Page content
개요
- VM 만들기 Web UI가 일부 변경됨 (추가 진행하기로 함)
- VM 생성 및 VS Code 연결
- VM과 BigQuery 연결
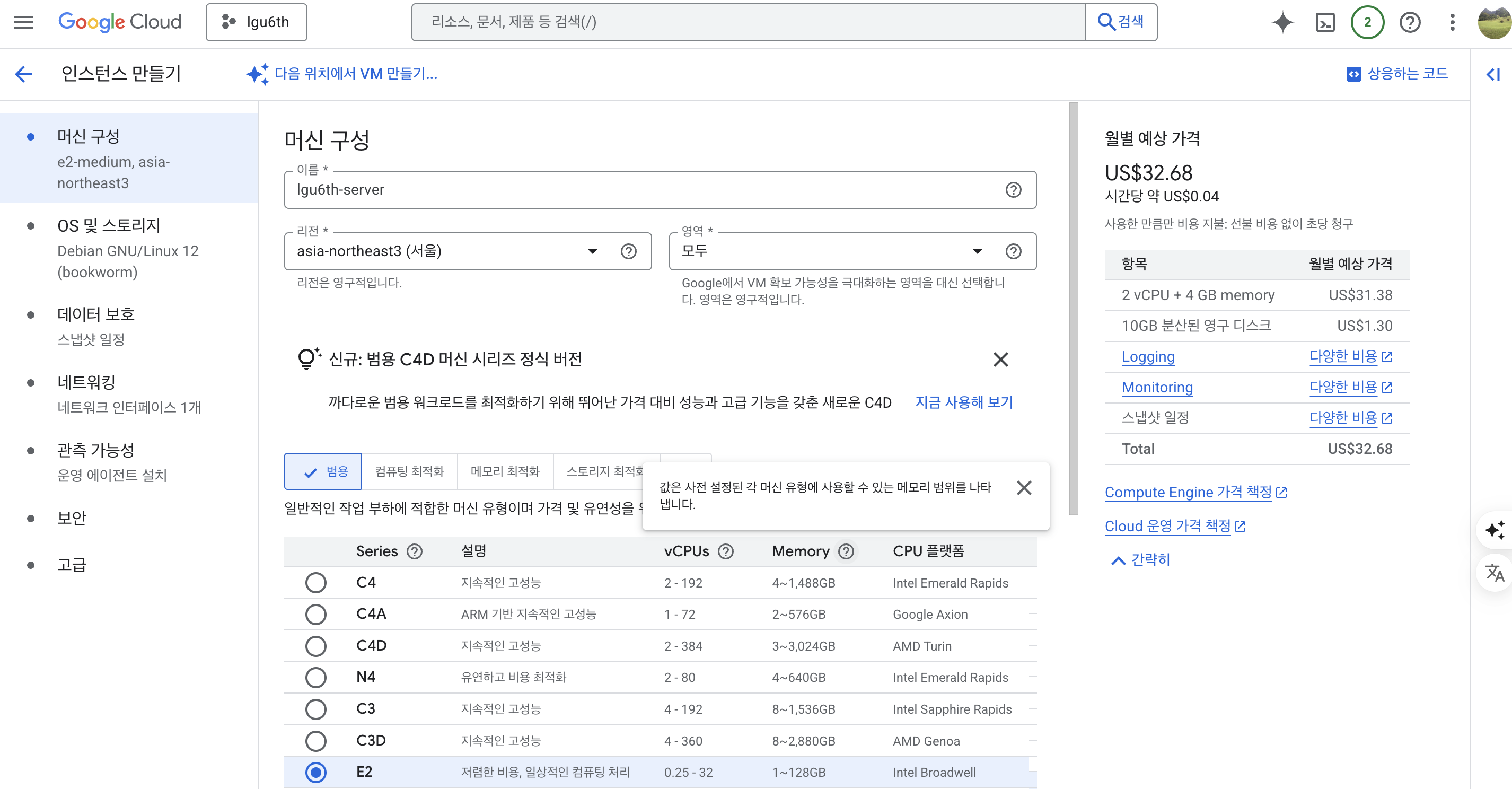
VM 머신 생성
머신 구성
- 이름과 성능 체크
- 월별 예상 가격을 체크한다.
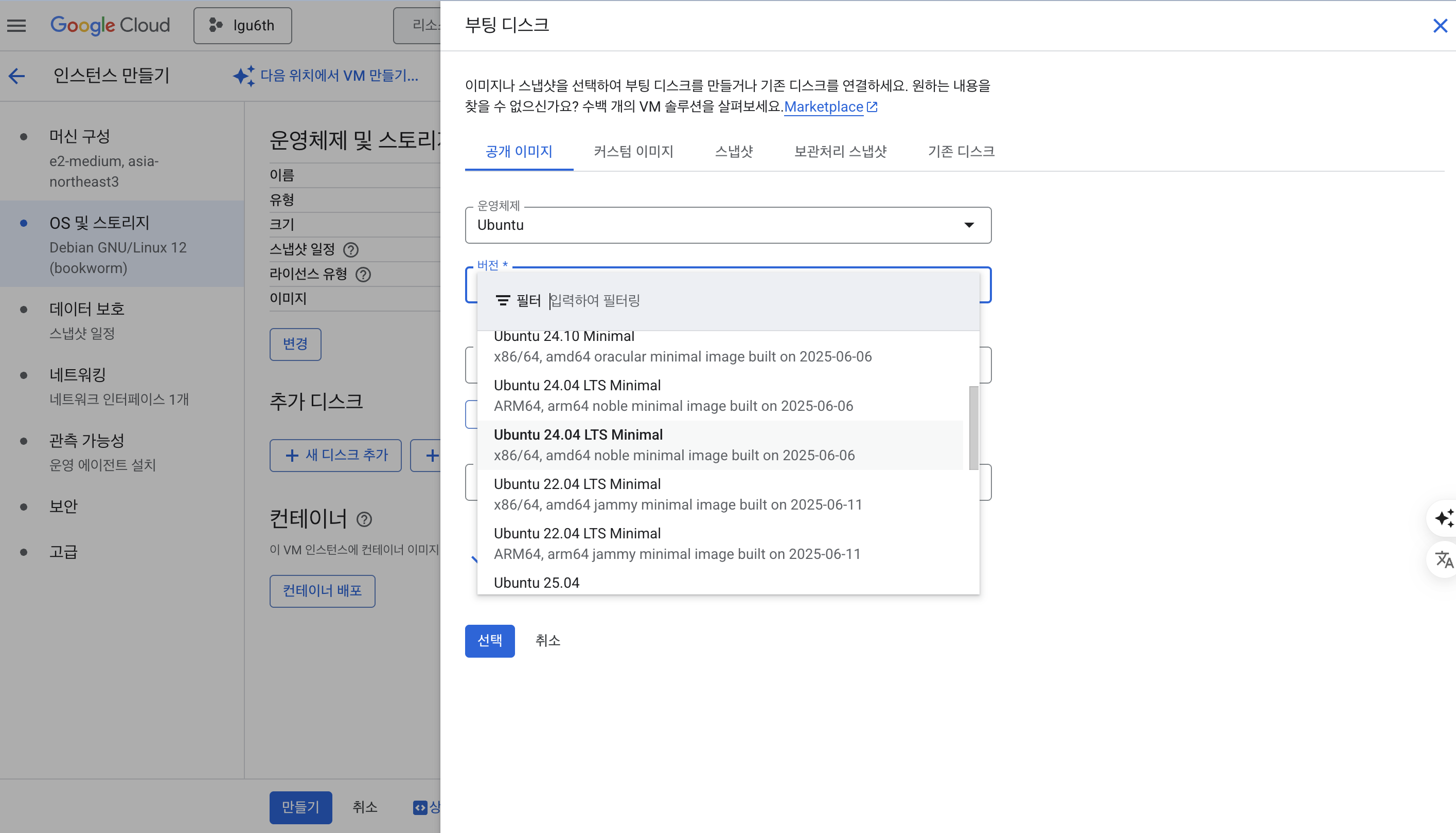
OS 및 스토리지
- Ubuntu - Ubuntu 24.04 LTS 방식으로 진행 (x86/64) 방식 선택
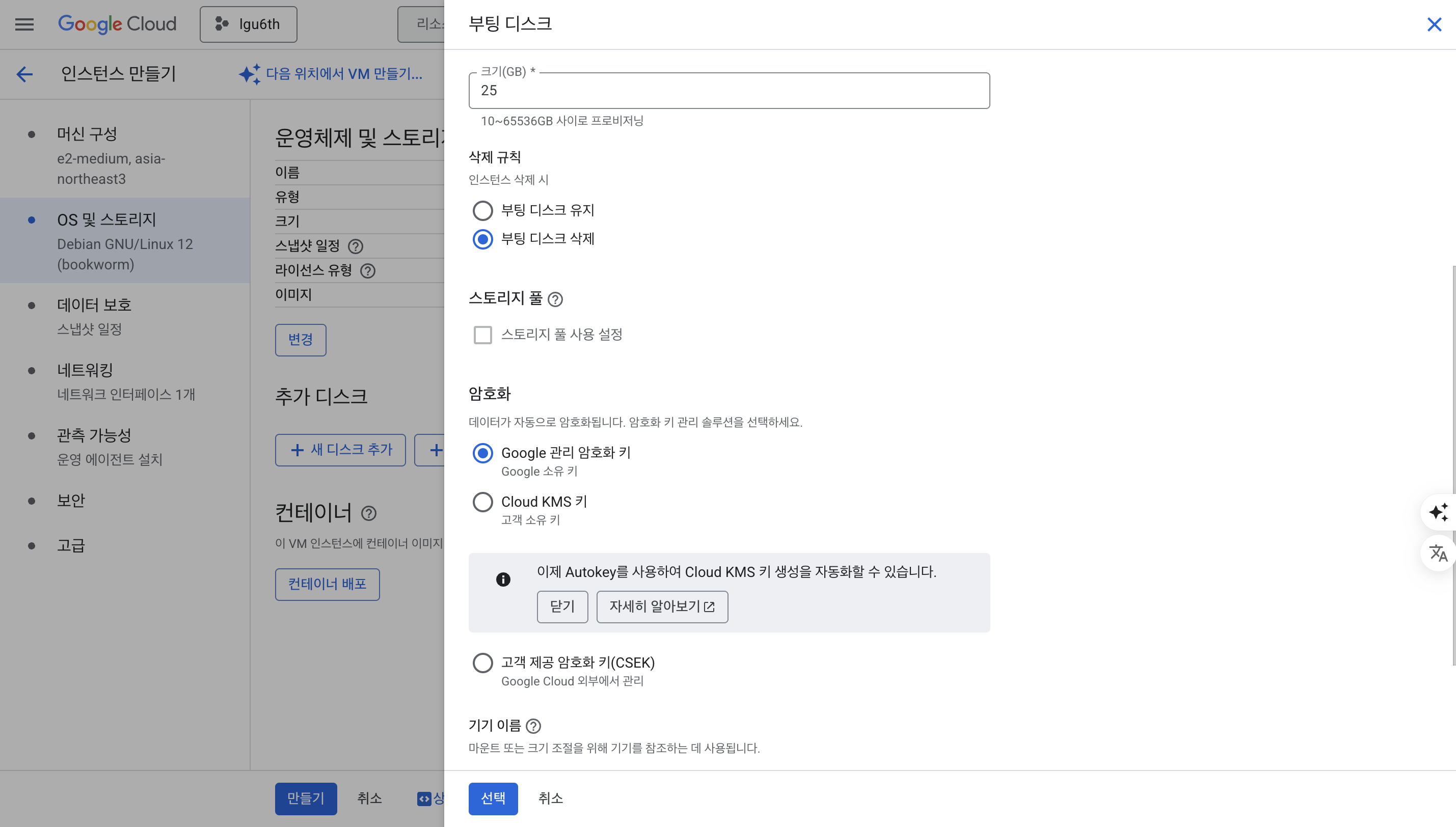
- 디스크 사이즈 : 25GB
- 암호화 : Google 관리 암호화 키 선택
데이터 보호
- 이 부분은 생략하고 넘어간다.
네트워킹
- 방화벽은 아래와 같이 HTTP & HTTPS 트래픽 허용

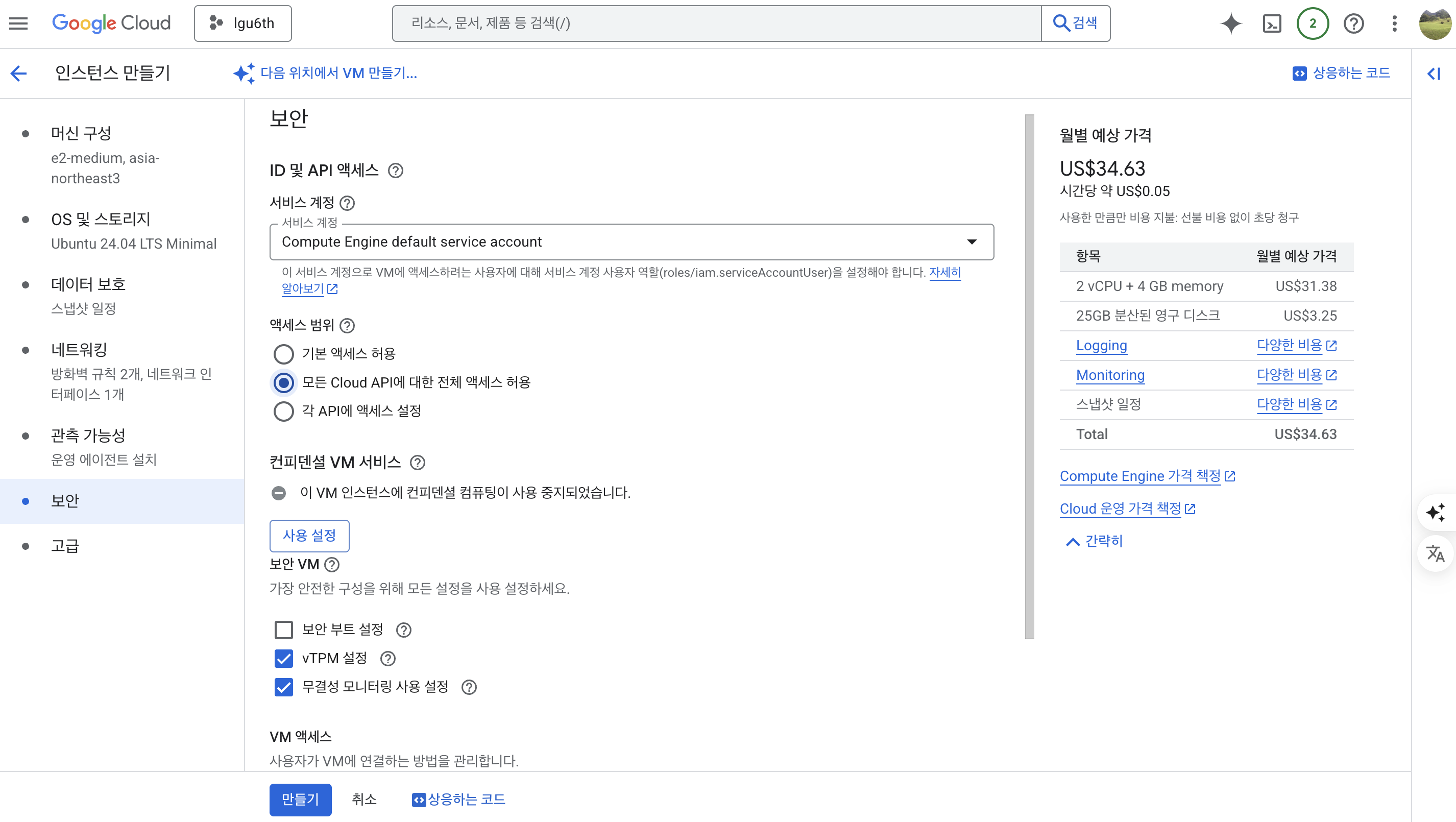
보안
- 액세스 범위 : 모든 Cloud API에 대한 전체 액세스 허용
VM 생성
- 다음과 같이 만들기 버튼 클릭

고정 IP 할당
- VPC 네트워크 > IP 주소 클릭
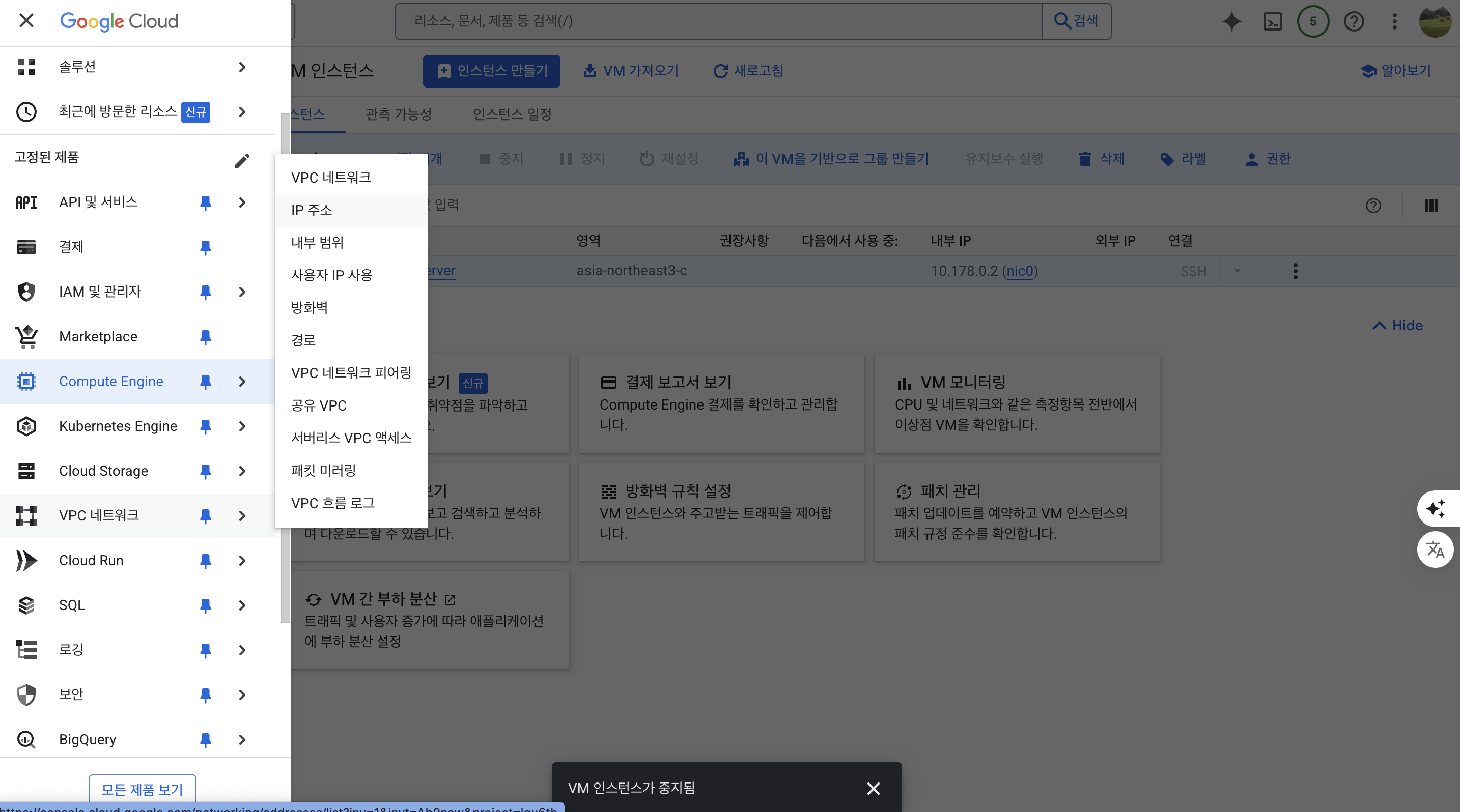
- 오른쪽 끝 작업 하단 메뉴 선택 후 고정 IP 주소로 승급 선택
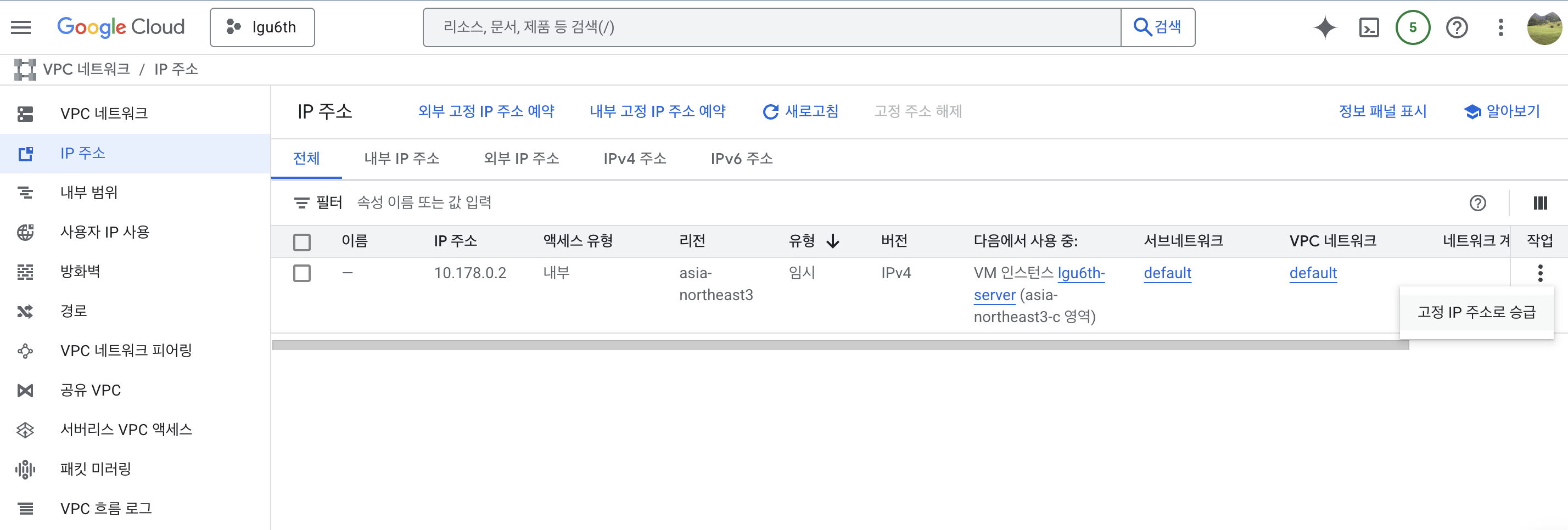
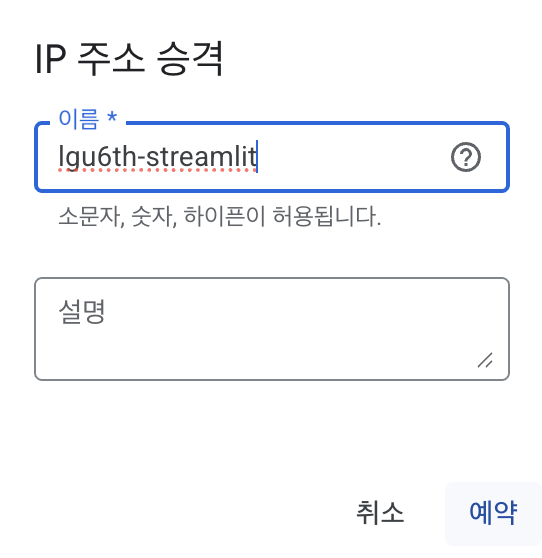
-
다음과 같이 임의의 이름 지정
방화벽 설정 (프로젝트 배포 위해)
- VPC 네트워크 탭 왼쪽 메뉴에서 방화벽을 클릭한다.
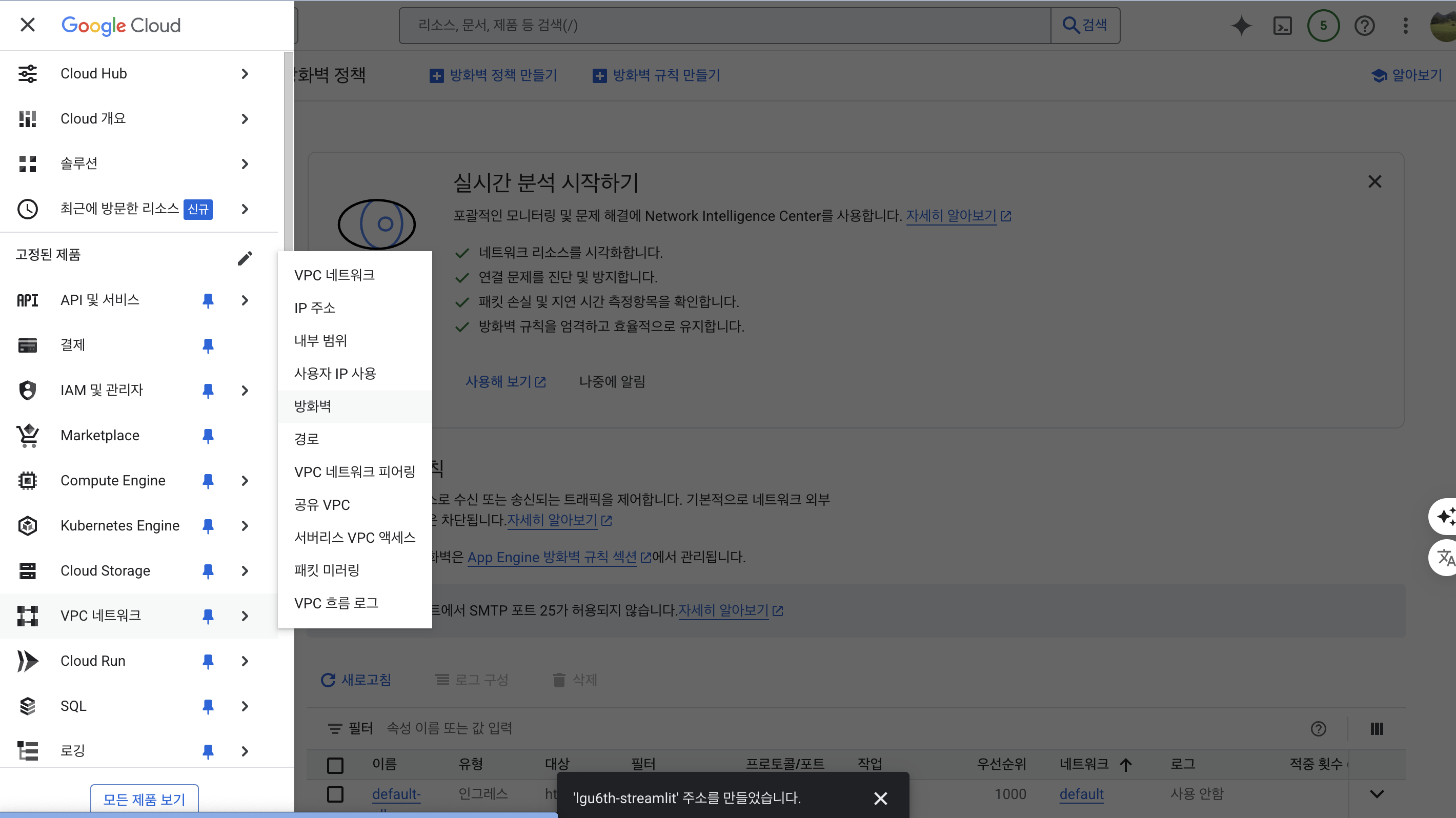
- 방화벽 > 방화벽 규칙만들기를 순차적으로 클릭한다.
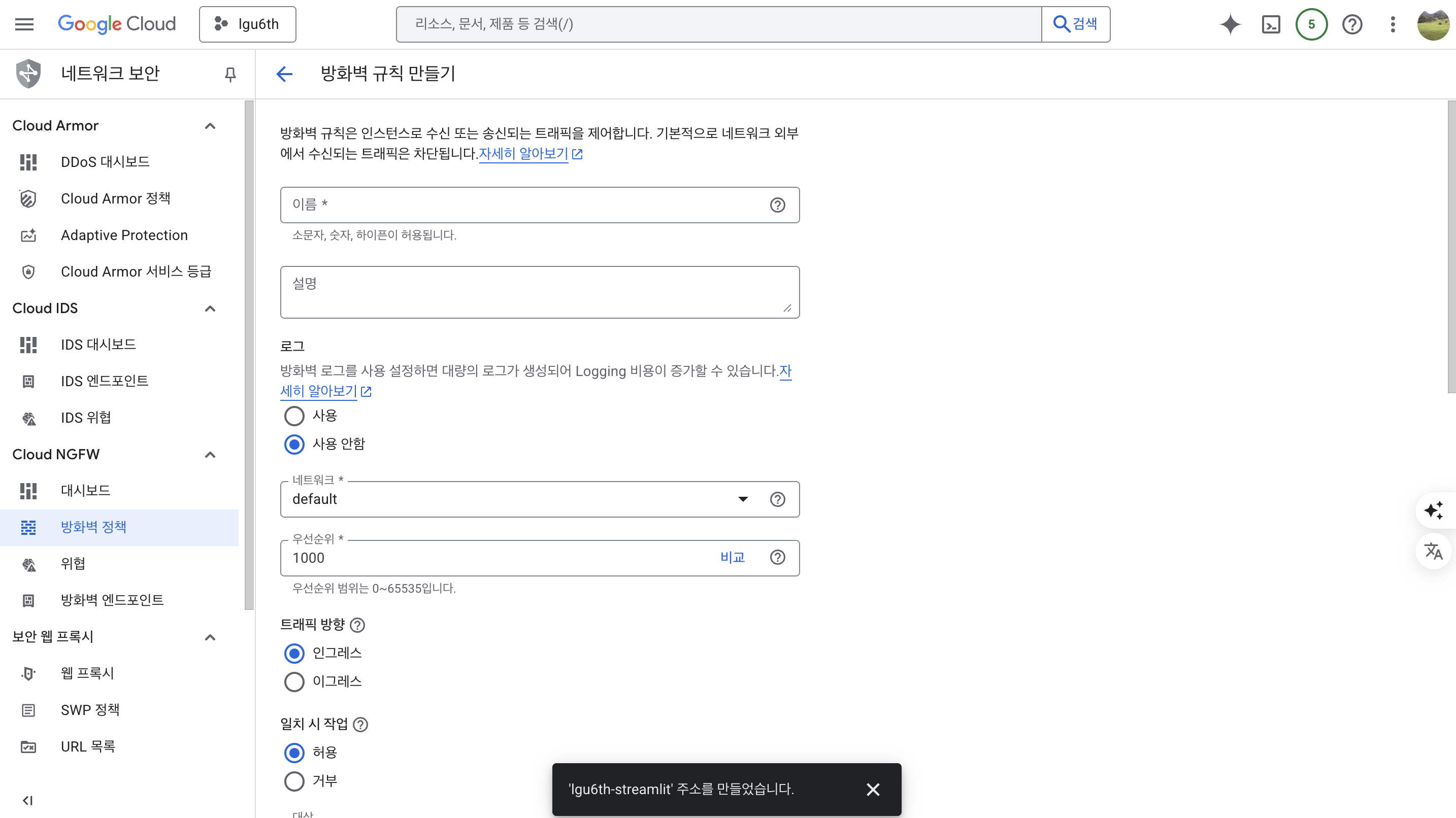
- 방화벽 규칙 이름 : lgu6th-firewall
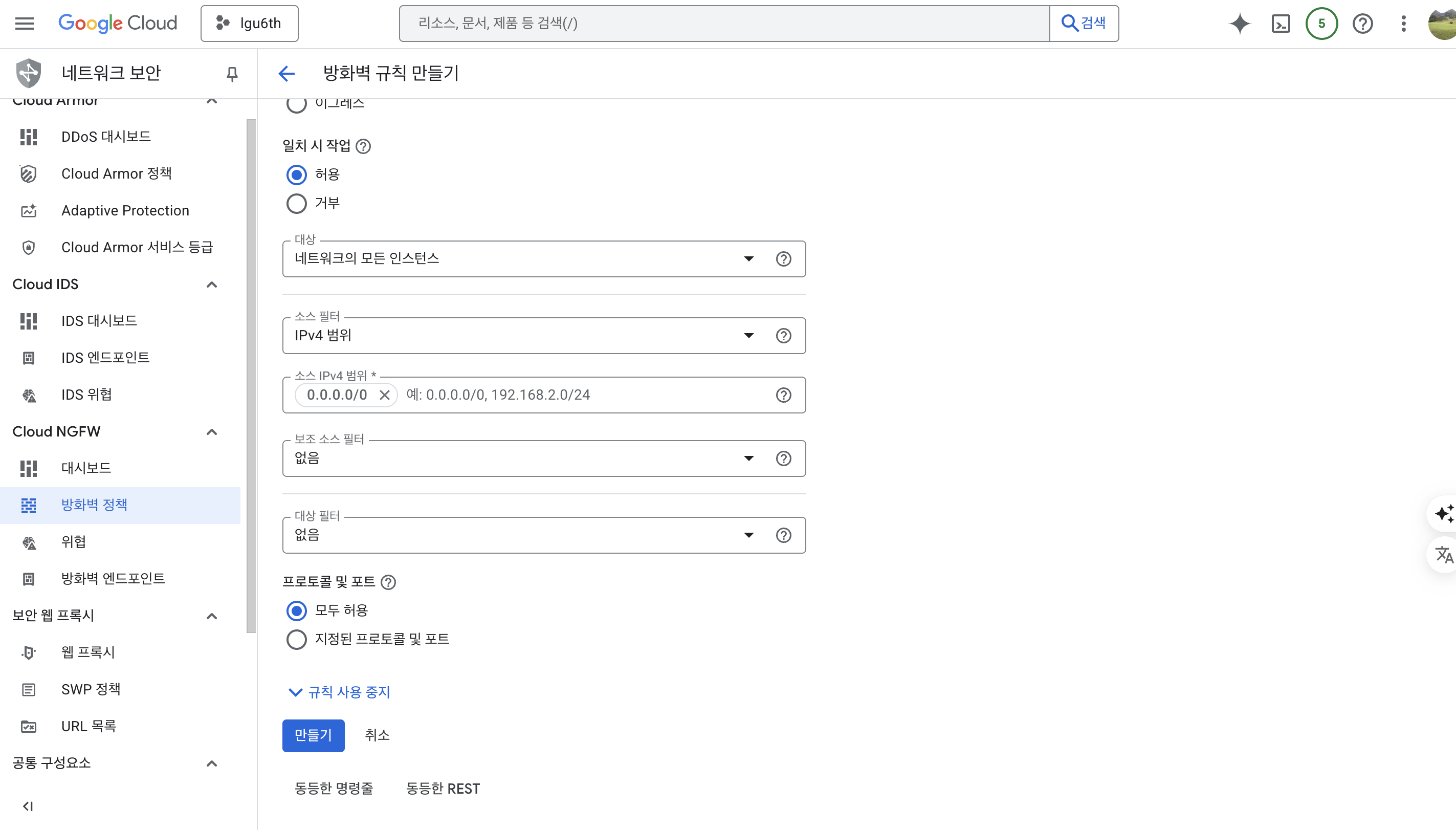
- 여기에서 대상은 네트워크의 모든 인스턴스 / 소스 IPv4 범위는
0.0.0.0/0프로토콜은 모두 허용을 클릭한다.
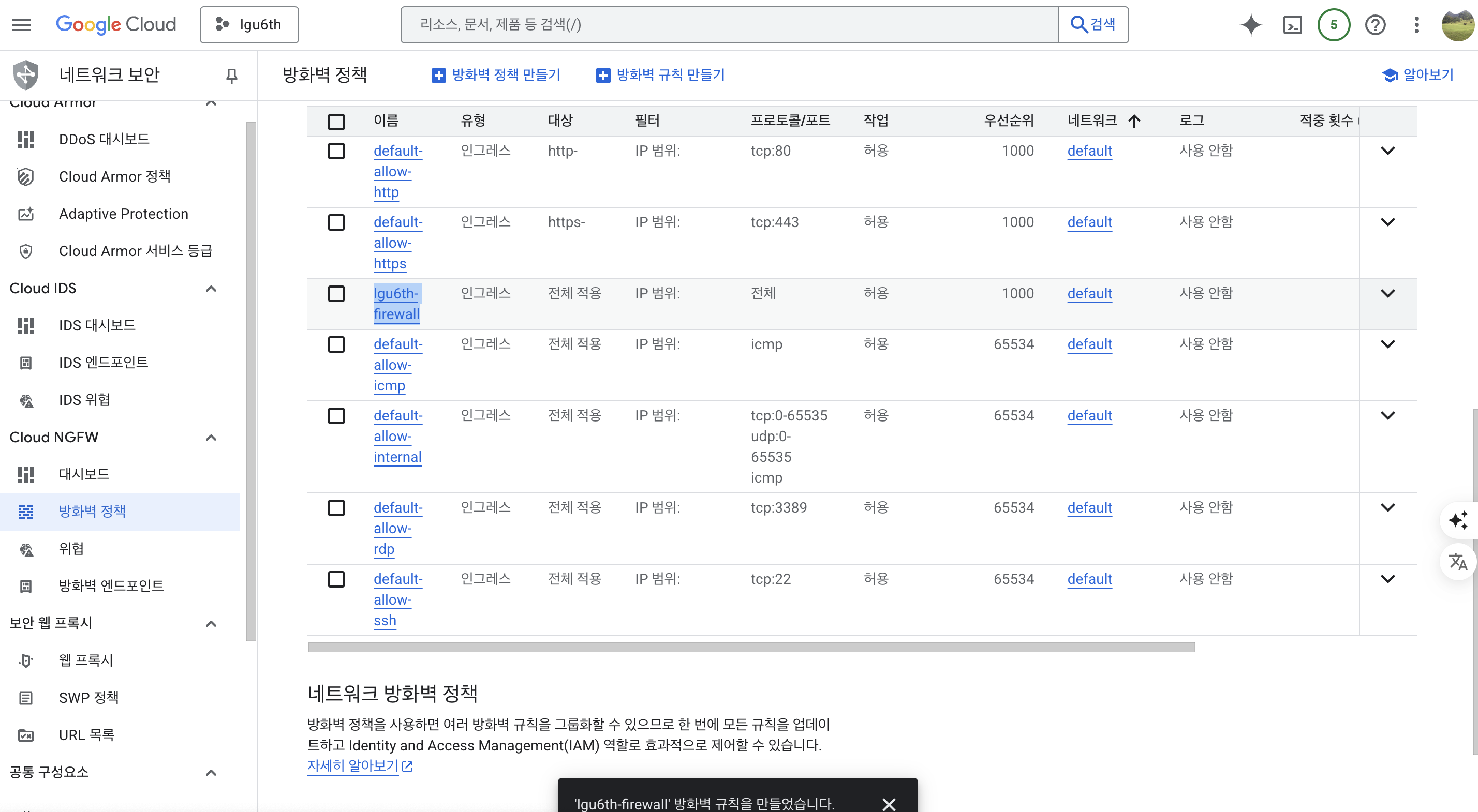
- 생성된 방화벽 확인
메타데이터 등록
- Mac/Linux에서 등록하는 것과 Windows에서 등록하는 것은 다르다.
- Windows에서 등록하는 방법을 소개한다.
SSH Key 생성하기 - PuTTYgen 사용
- Windows에서는 PuTTY에서 작성한다.
- 프로그래밍 검색창에서 PuTTYgen 프로그래밍을 실행한다.
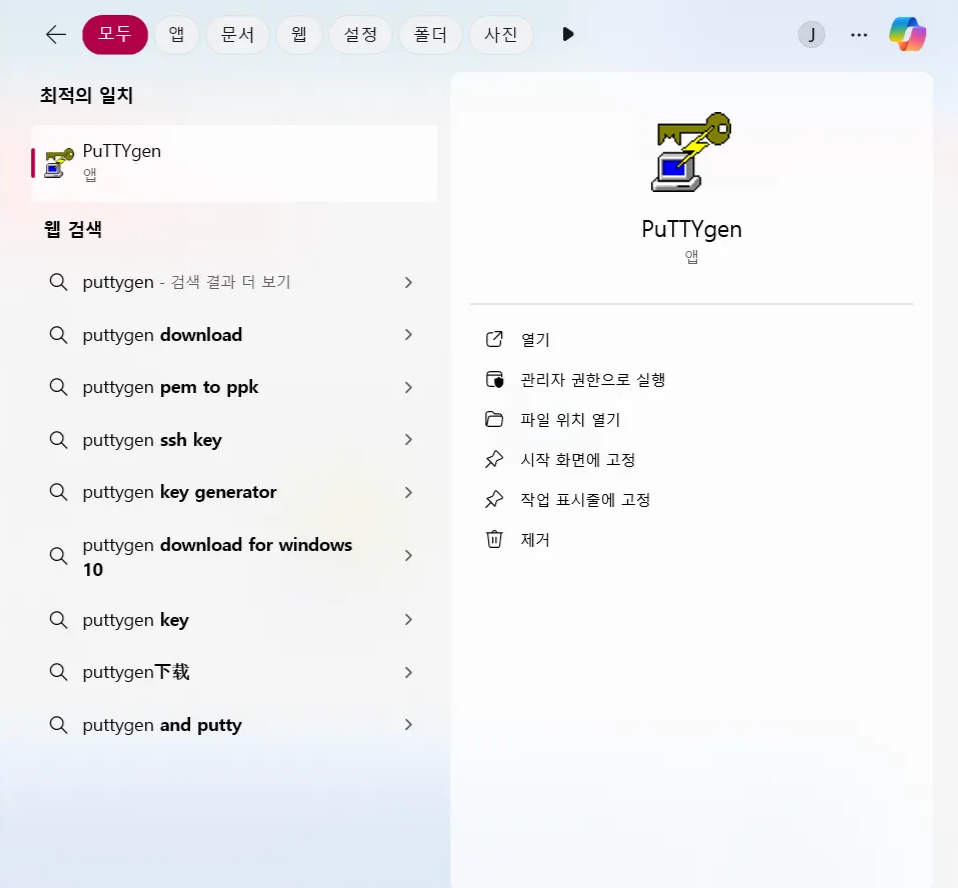
- 아래화면에서 Generate 버튼을 클릭한다.
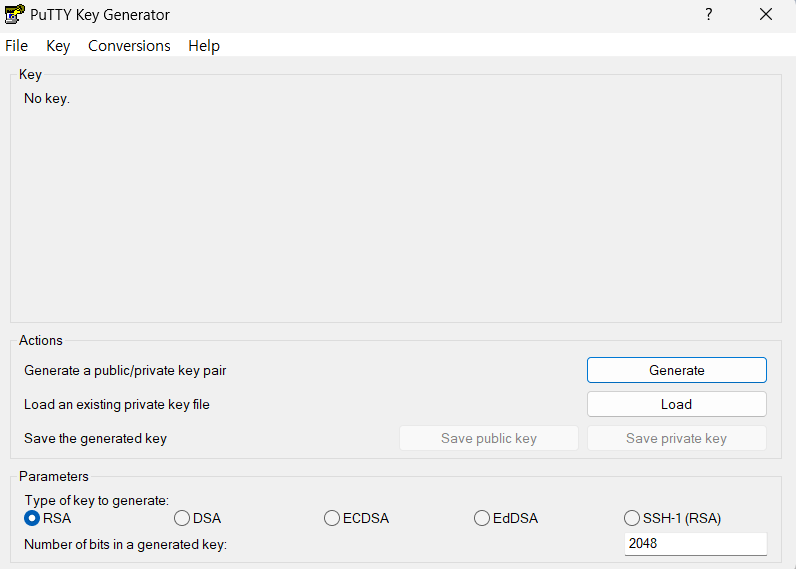
- Private Key를 OpenSSH 방식으로 Export 한다.
- Key Comment에 구글 계정을 입력한다.
- password도 입력한다.
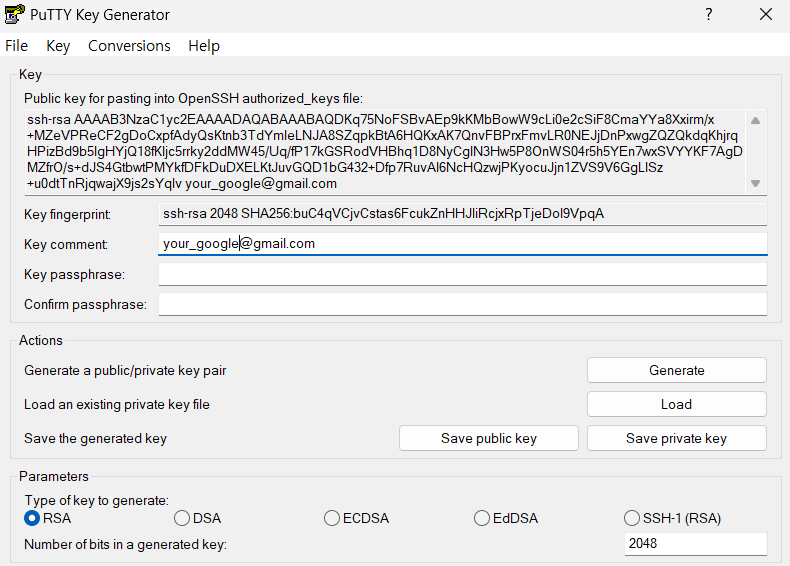
- Conversions > Export OpenSSH Key 선택
- 파일 이름은 gce2windows로 저장 (바탕화면에 임시로)
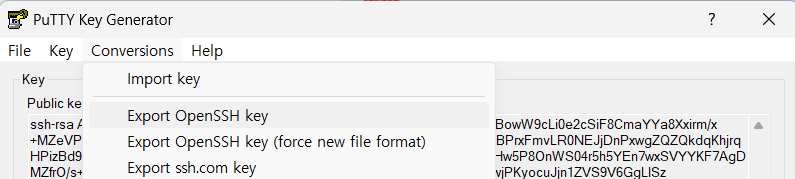
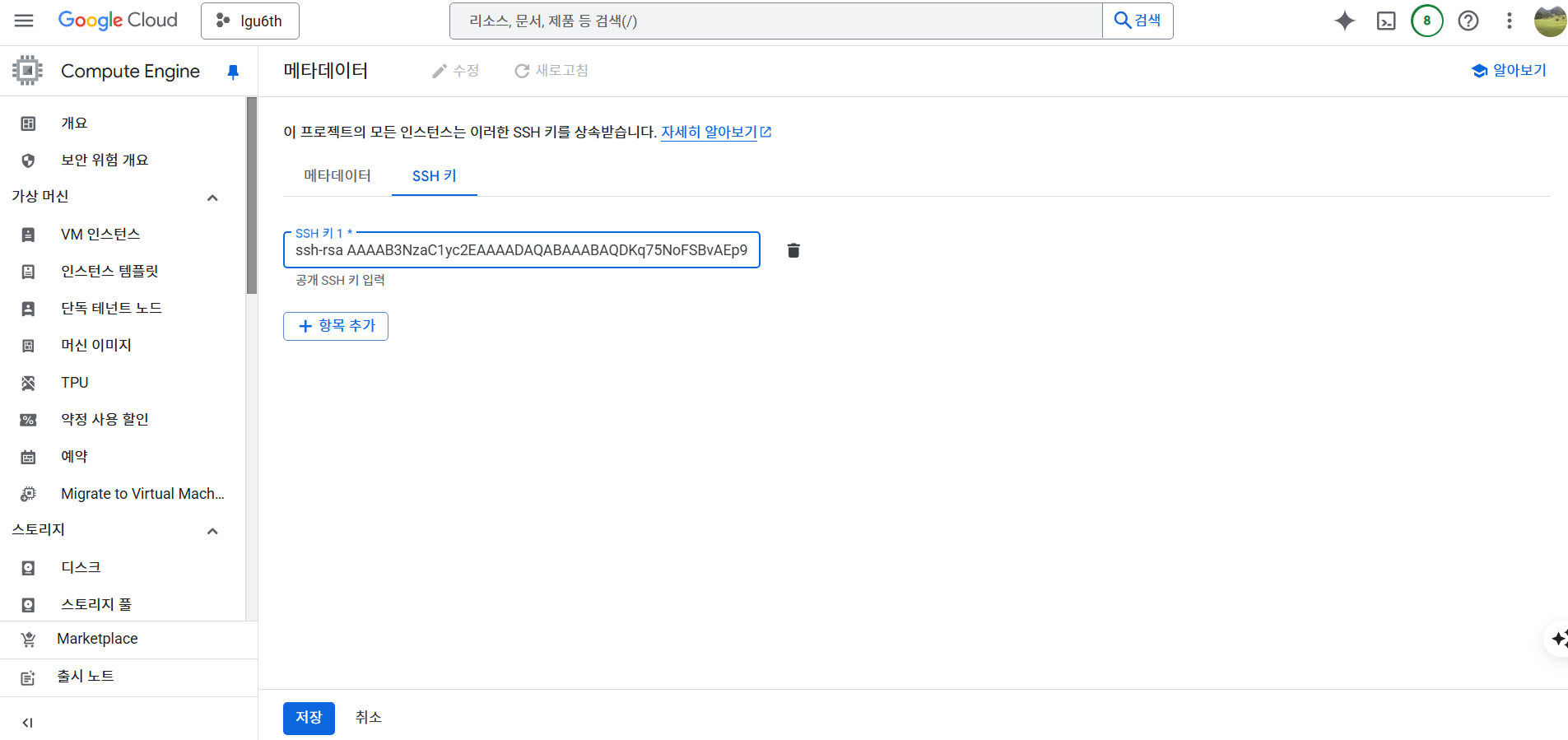
- Public Key는 모두 복사한다. (ssh-rsa 부터 email.com 까지)
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDKq75NoFSBvAEp9kKMbBowW9cLi0e2cSiF8CmaYYa8Xxirm/x+ ... your_gmail@gmail.com
GCP 메타데이터 등록
- Compute Engine > 메타데이터 클릭
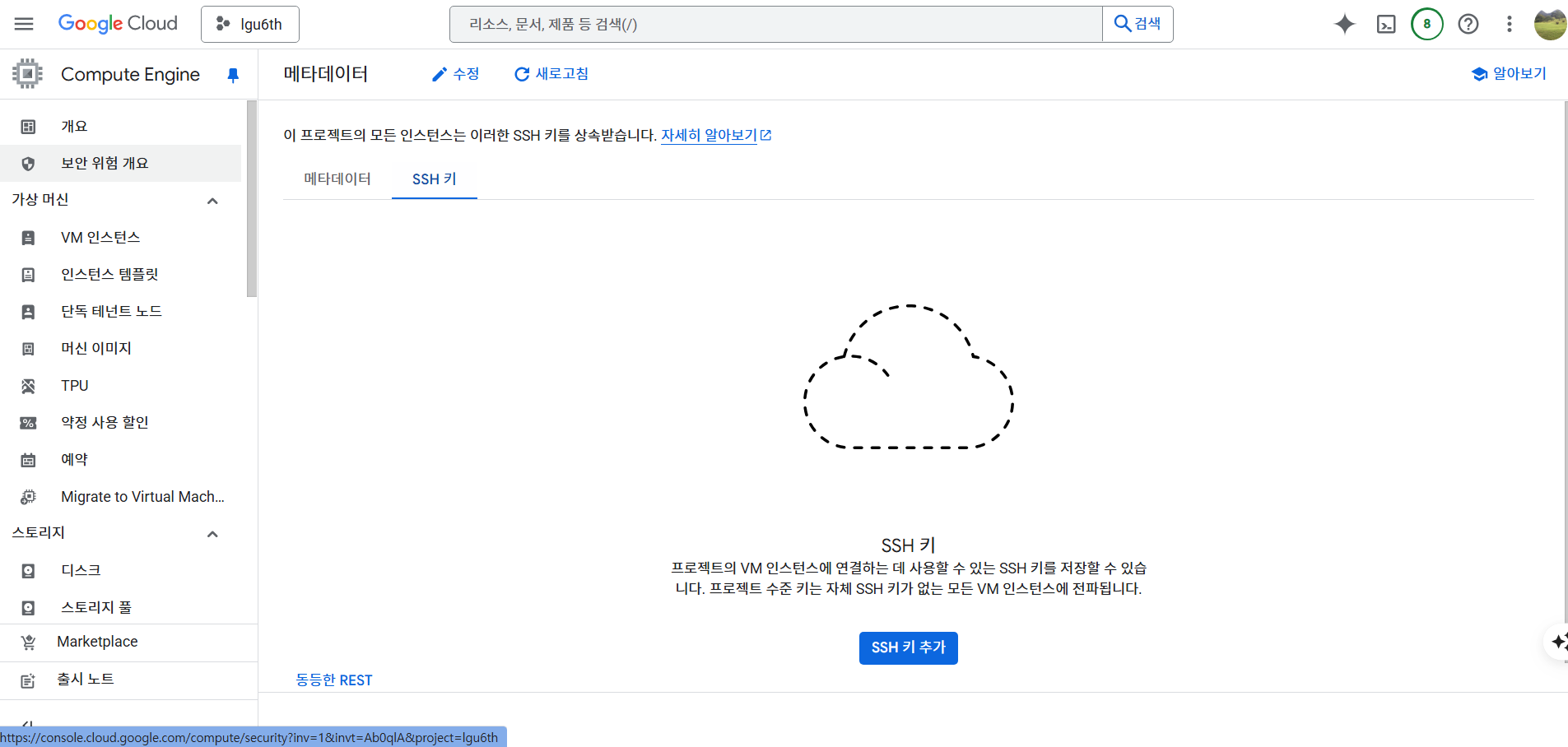
- SSH 키 탭에서 SSH 추가
- 다음과 같이 SSH 키 입력 후 저장
VS Code 접속
- GCE 인스턴스 활성화한다.
- 바탕화면에 있던 gce2windows 파일을 .ssh 폴더에 복사 붙이기 할 것이다. (Git-Bash에서 진행)
~/OneDrive/Desktop
$ cp -r gce2windows ~/.ssh/
~/OneDrive/Desktop
$ cd ~/.ssh
~/OneDrive/Desktop
$ ls
Q-tutor.pem gce2windows id_rsa.pub known_hosts.old
config id_rsa.ppk known_hosts openssh
- VS Code에서는 다음과 같이 진행
- 먼저 SSH Config 파일 수정
- Ctrl + Shift + P > Remote-SSH: Open SSH Configuration File… > ~.ssh\config 선택
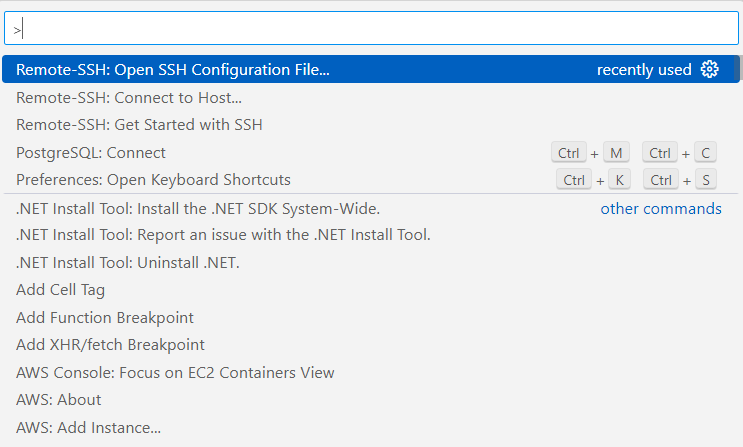
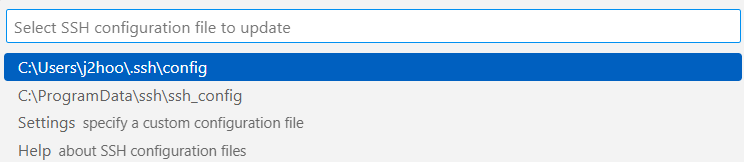
- 다음과 같이 수정한다.
- HostName에 있는 포트번호는 GCP에서 발급해준 번호
Host gce2windows
HostName 34.22.86.213 # 외부 IP 각자 다름
Port 22
User yourname
IdentityFile ~/.ssh/gce2windows
- 키 생성할 때 만들었던 Password 입력
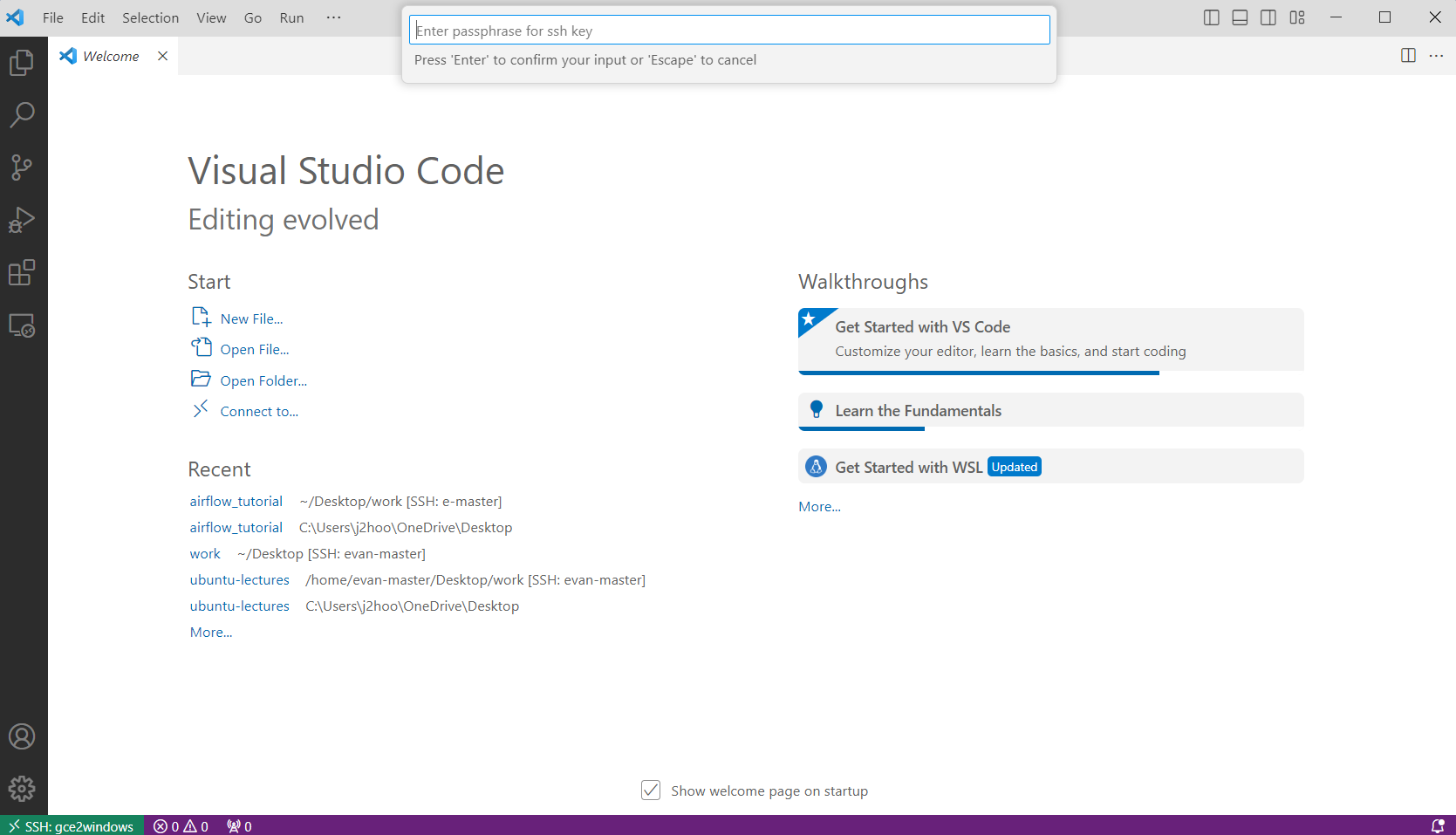
- 접속 여부 확인
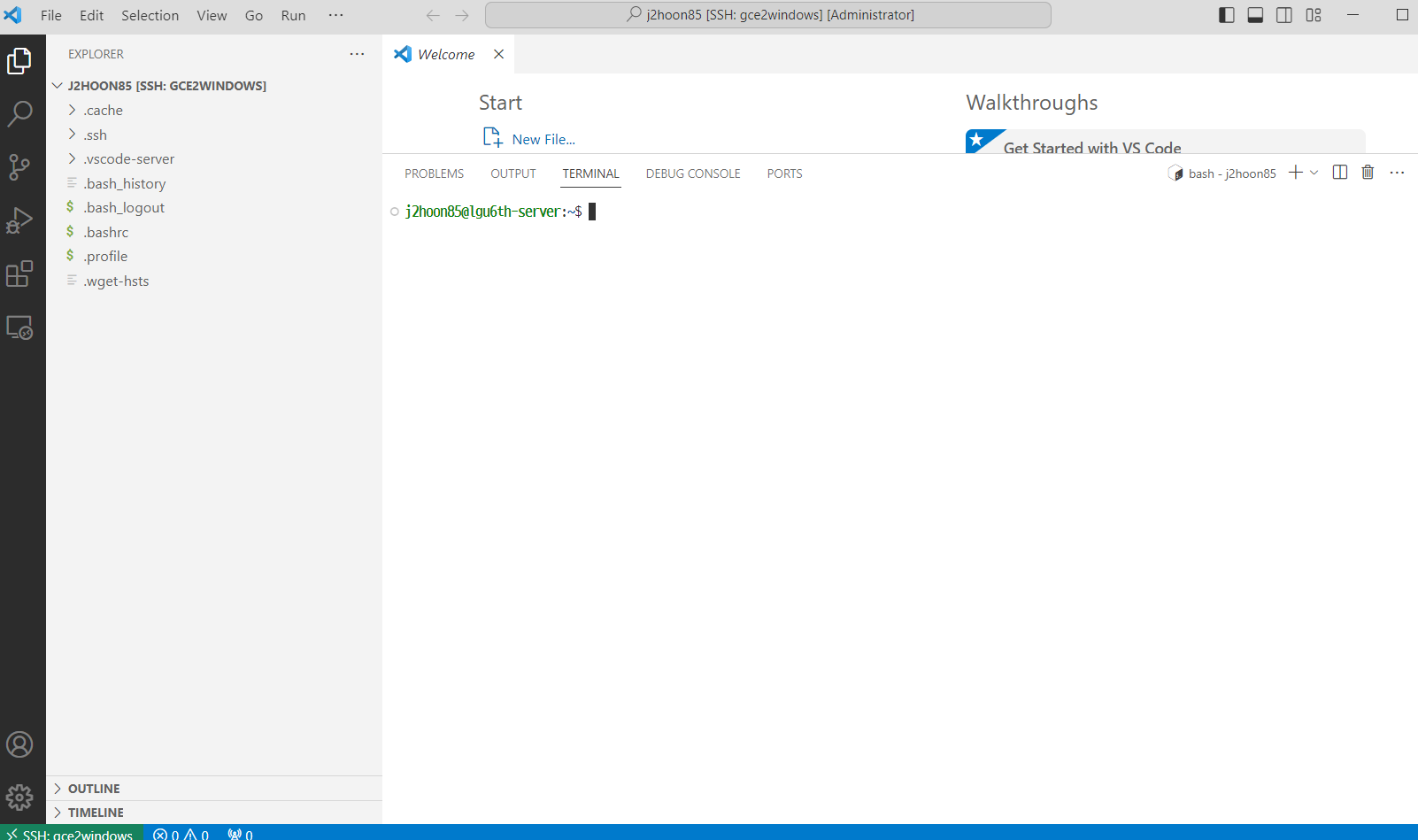
간단한 웹 테스트 (Streamlit & Jupyterlab)
- Streamlit이 동작하는지 살펴보기 위해 빠르게 라이브러리 설치 진행
- uv 설치
- 환경변수 지정 및 터미널 종료 및 재 실행
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
- requirements.txt 파일
streamlit
jupyterlab
- 라이브러리 설치
uv pip install -r requirements.txt
Streamlit 웹 배포 체크
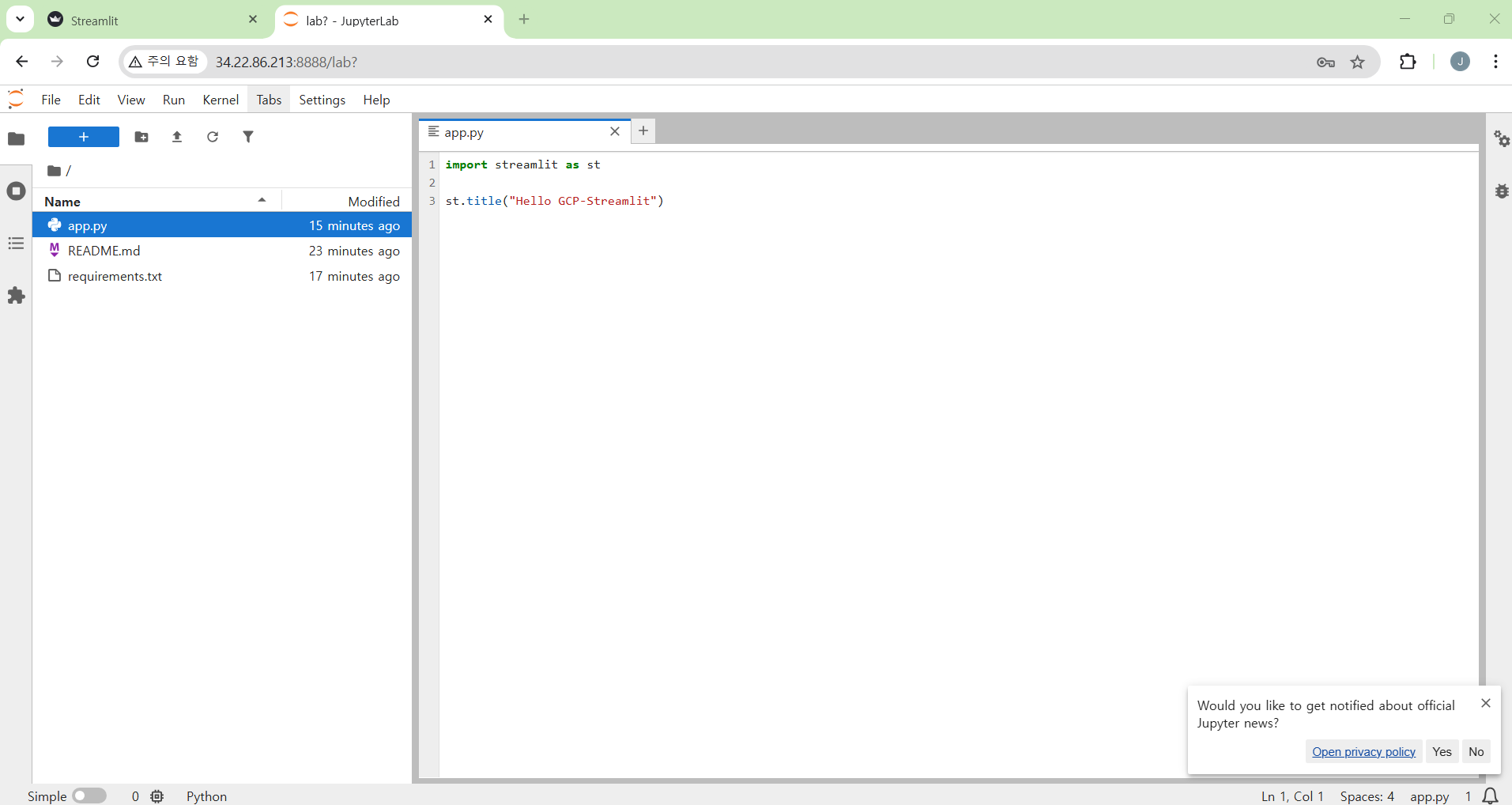
- 간단한 streamlit 파일 작성 (파일명 : app.py)
import streamlit as st
st.title("Hello GCP-Streamlit")
- 실행 확인

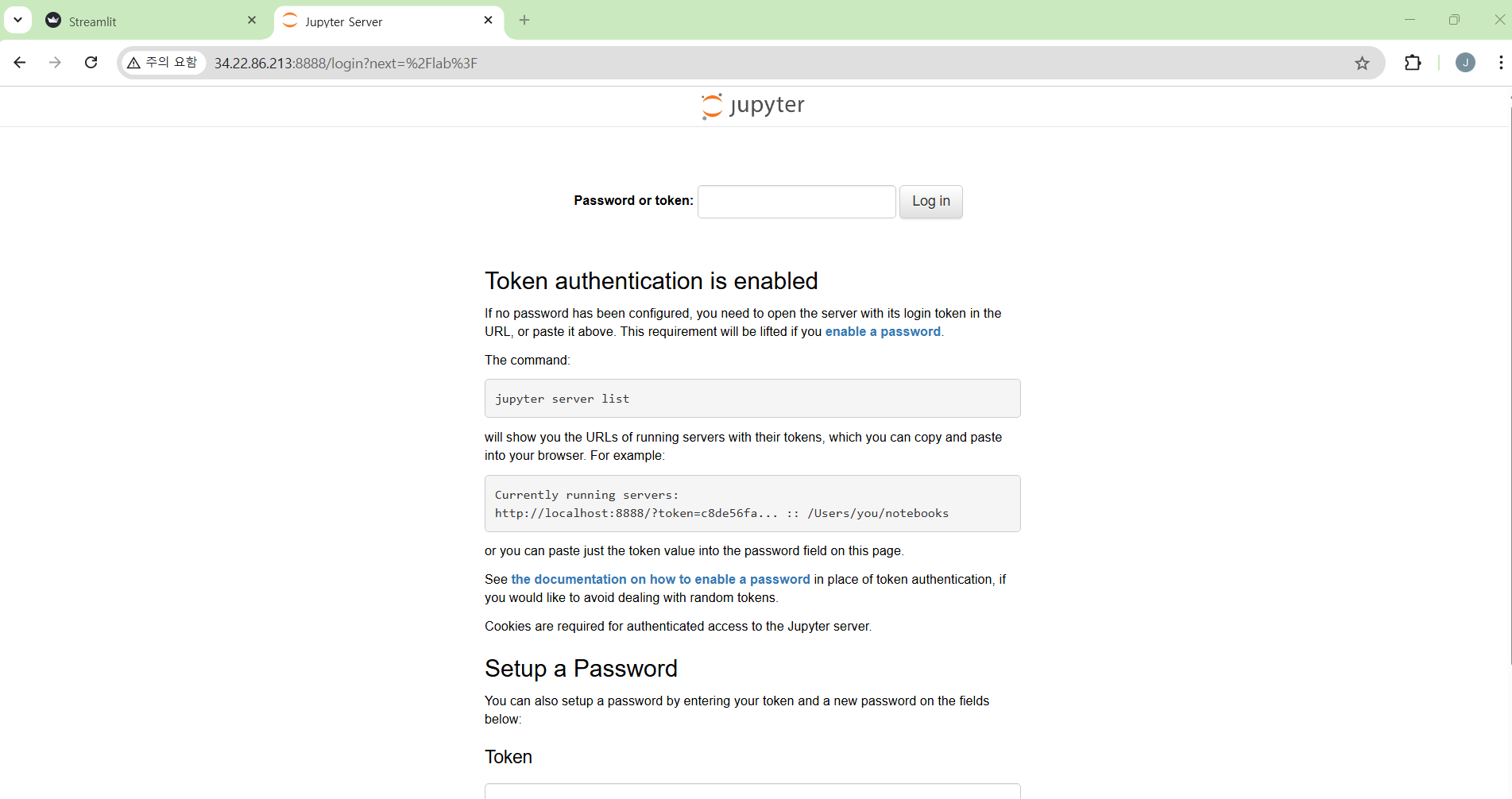
JupyterLab 웹 배포 체크
- 다음과 같이 실행한다.
jupyter lab --ip=0.0.0.0 --port=8888 --allow-root
- 이 때 토큰값은 복사해둔다. 필자는 다음과 같다.
- 이때 127.0.0.1:8888을 URL에 띄우는 것이 아니다.
- 여기선 token값 복사를 한다.
http://127.0.0.1:8888/lab?token=297d002ad3c3a76b55db4ed10856609201bd12631ef5efbc
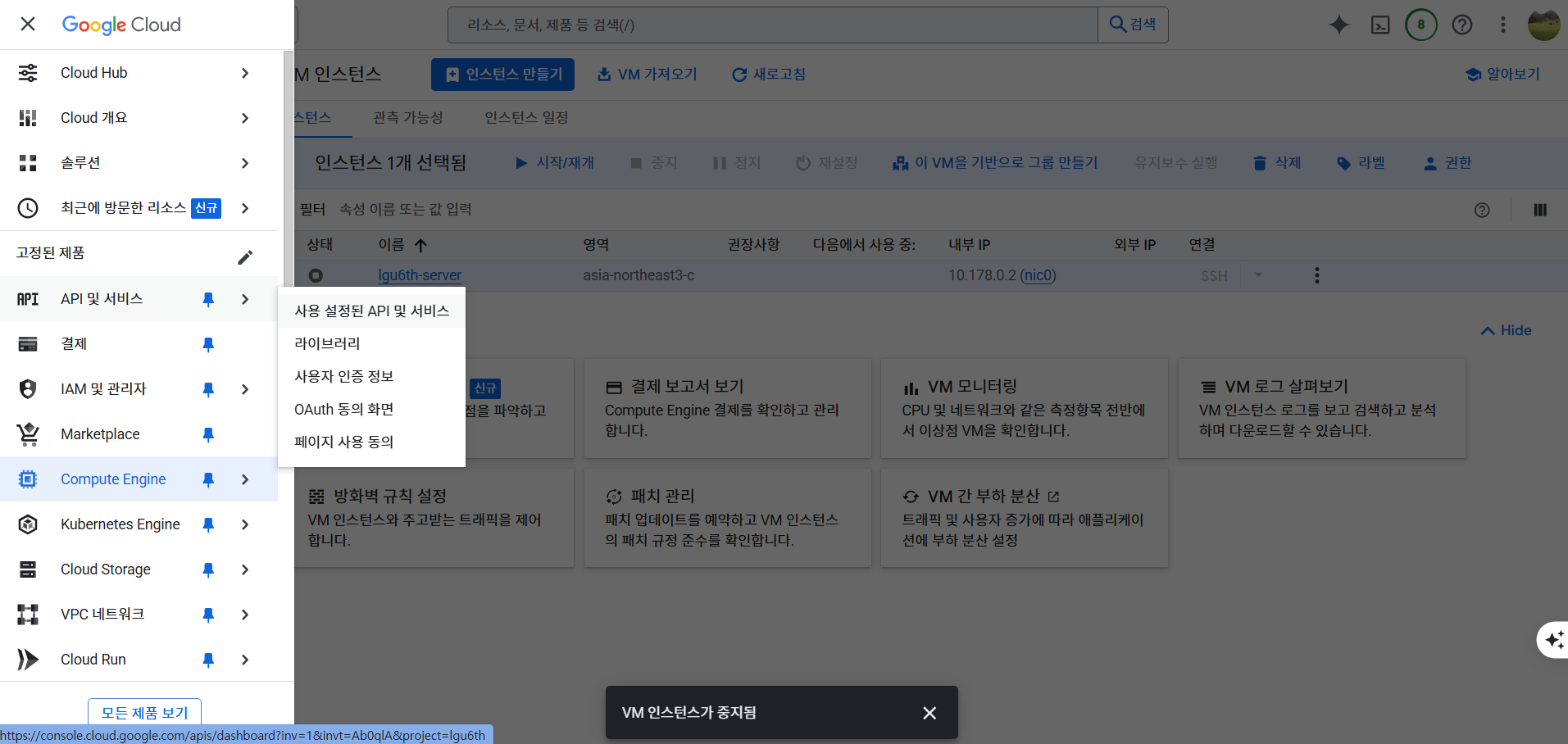
빅쿼리 사용 및 연결
- 빅쿼리 사용 설정을 하기 위해서 잠깐 인스턴스는 중지한다.
BigQuery API 설정
- API 및 서비스 > 사용 설정된 API 및 서비스를 클릭한다.
- BigQuery 검색하기
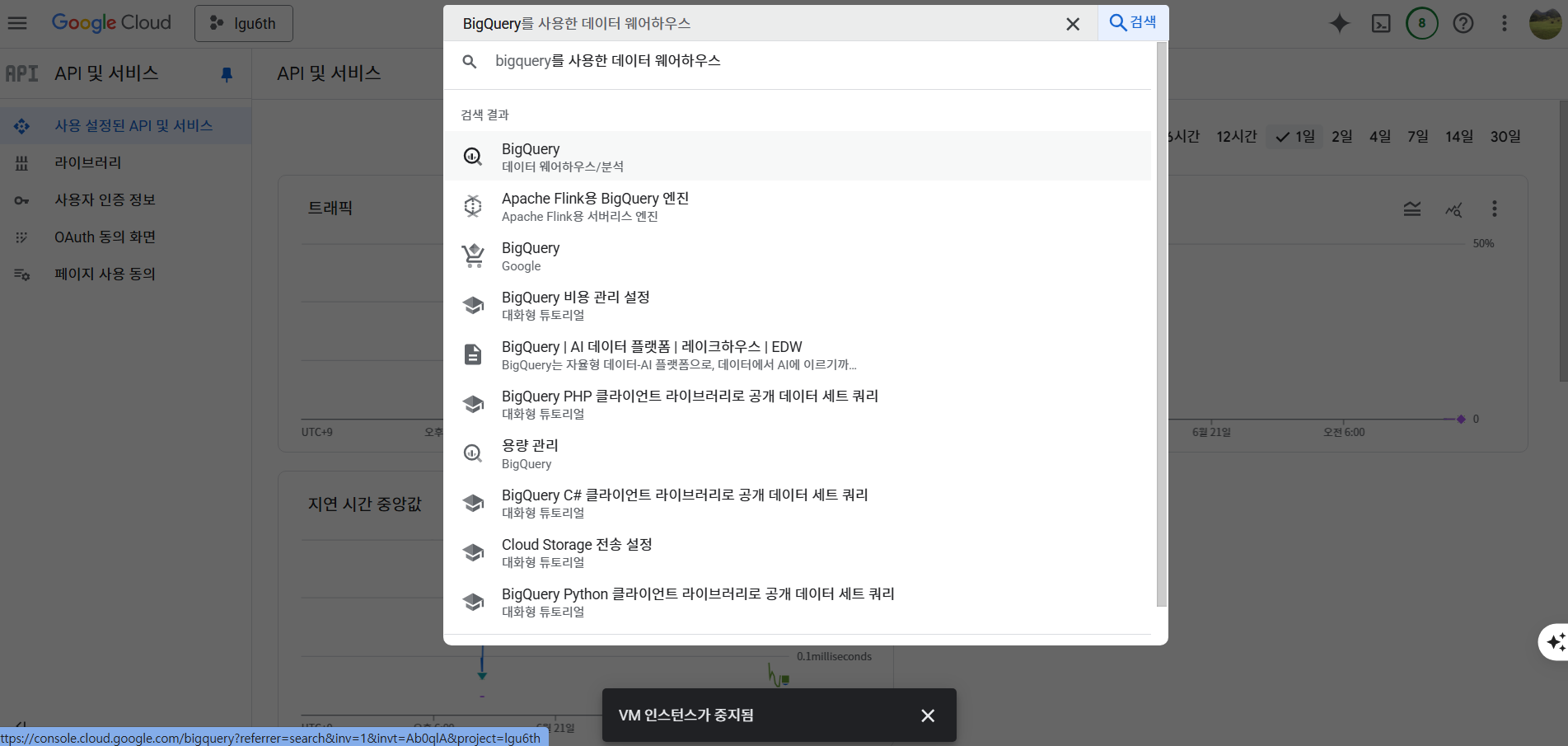
- 아래와 같은 화면이 나오면 사용 버튼 클릭한다.
- BigQuery Studio 화면이 나온다.
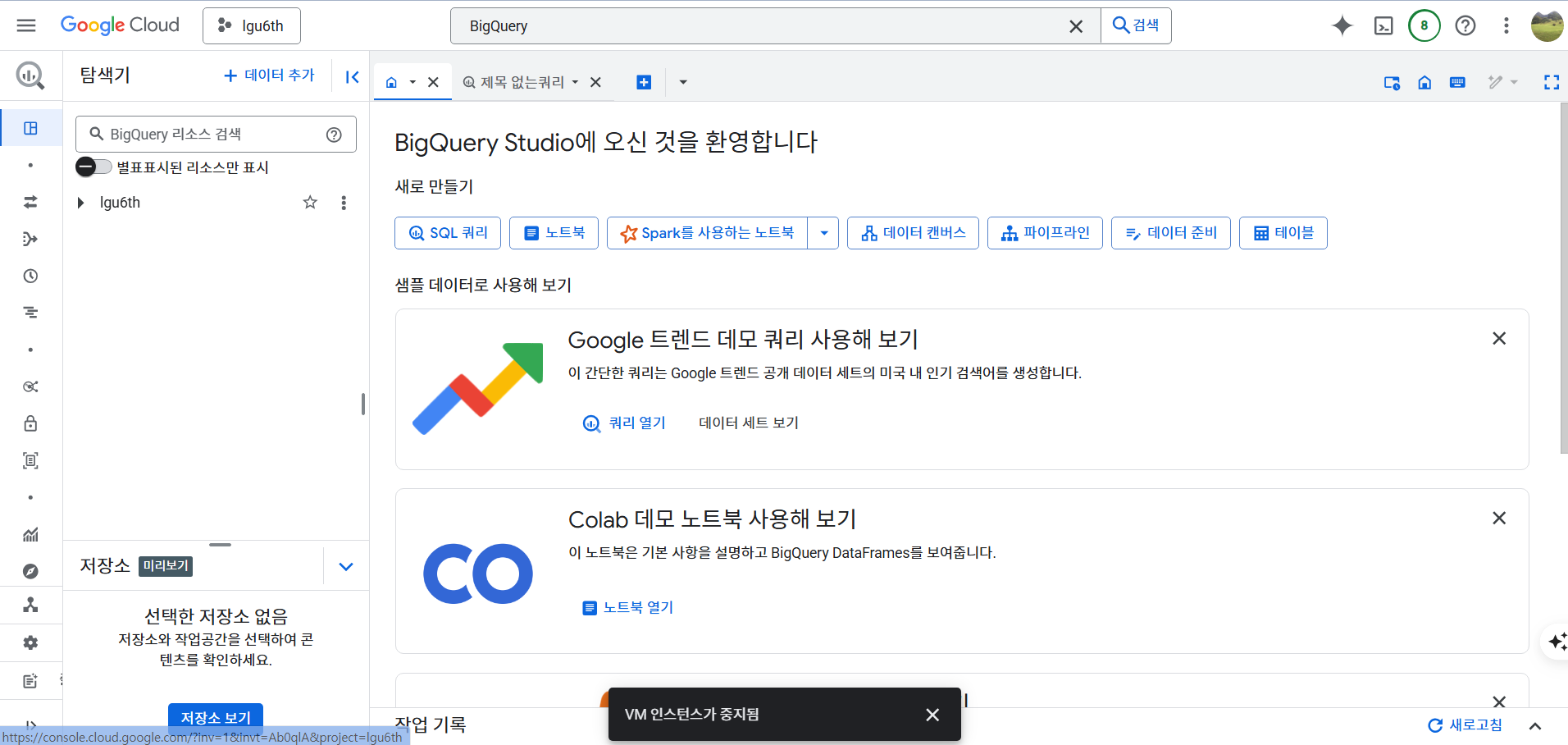
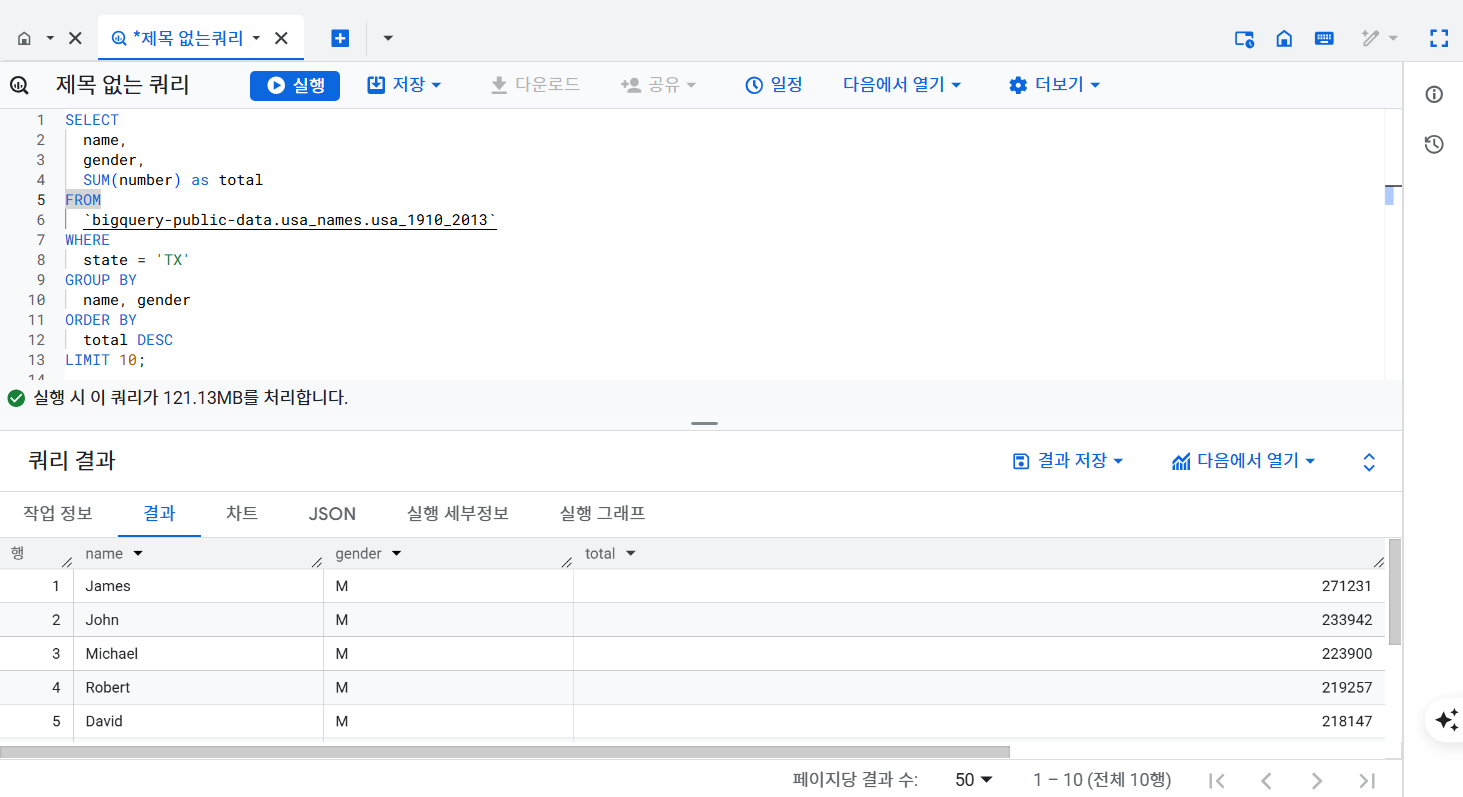
- SQL 쿼리 열고 다음 쿼리
SELECT
name,
gender,
SUM(number) as total
FROM
`bigquery-public-data.usa_names.usa_1910_2013`
WHERE
state = 'TX'
GROUP BY
name, gender
ORDER BY
total DESC
LIMIT 10;
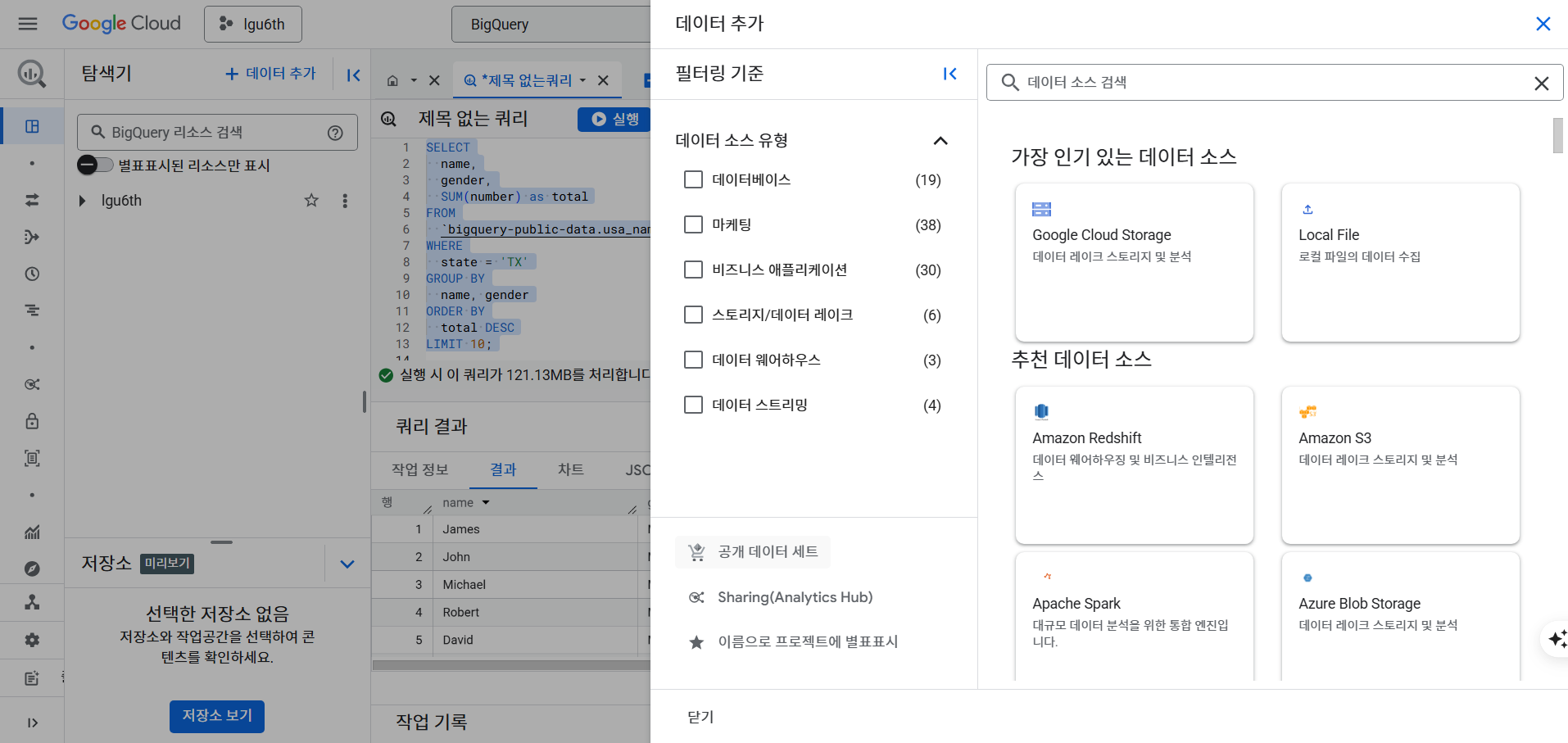
- 데이터 추가 버튼 > 공개 데이터 선택 > 데이터 > 무료 버튼 클릭
- 무료 데이터 처리
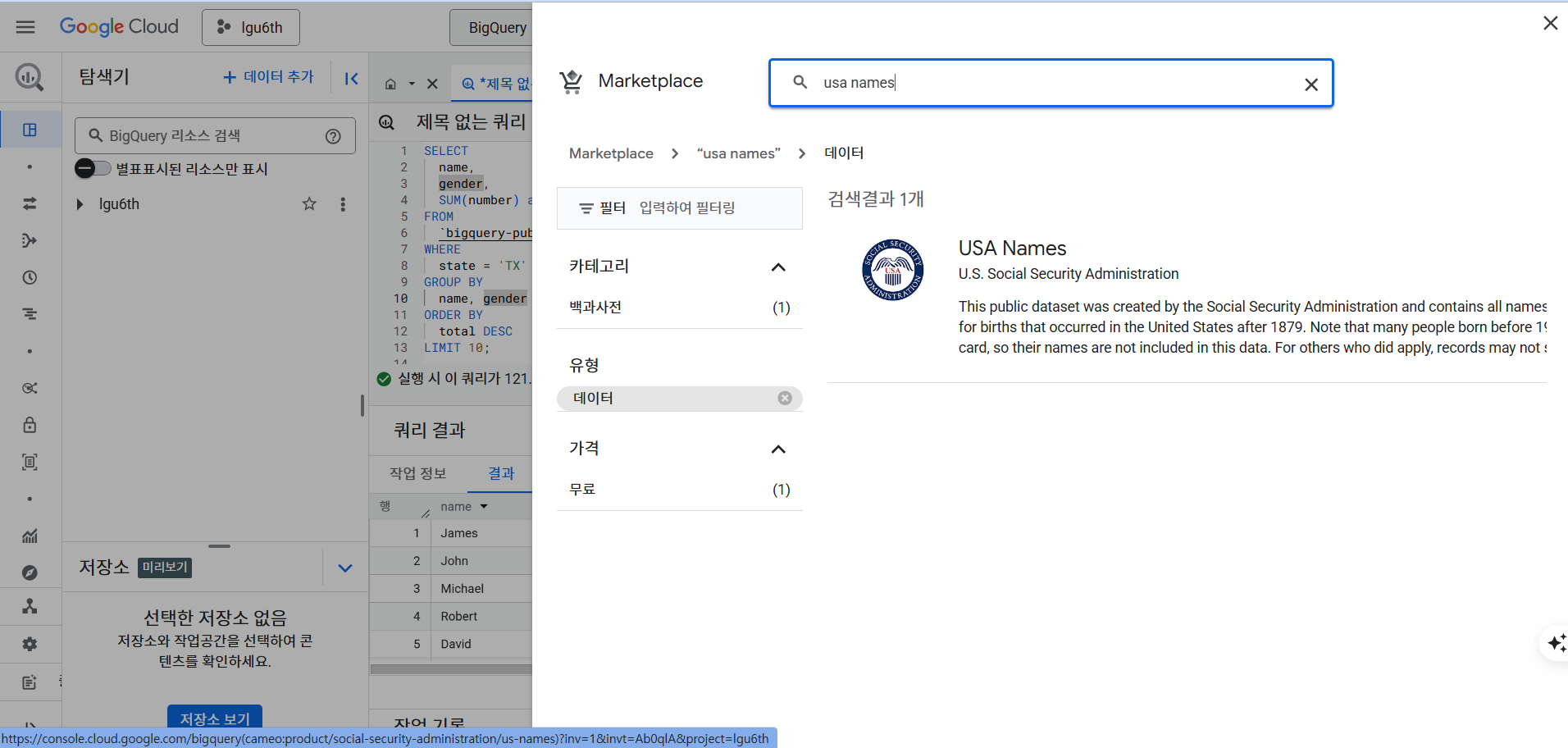

Local 데이터 업로드
- 데이터 세트 만들기
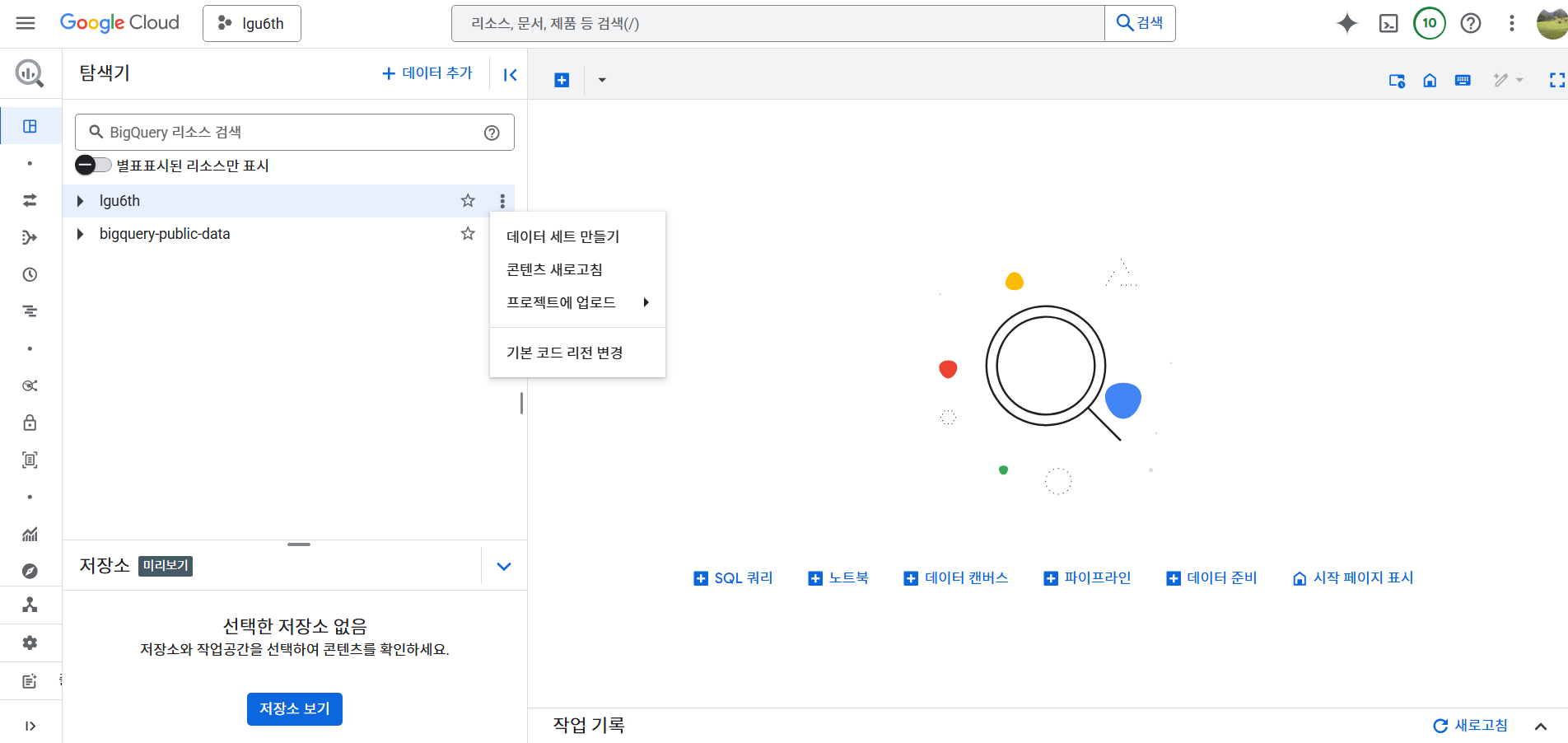
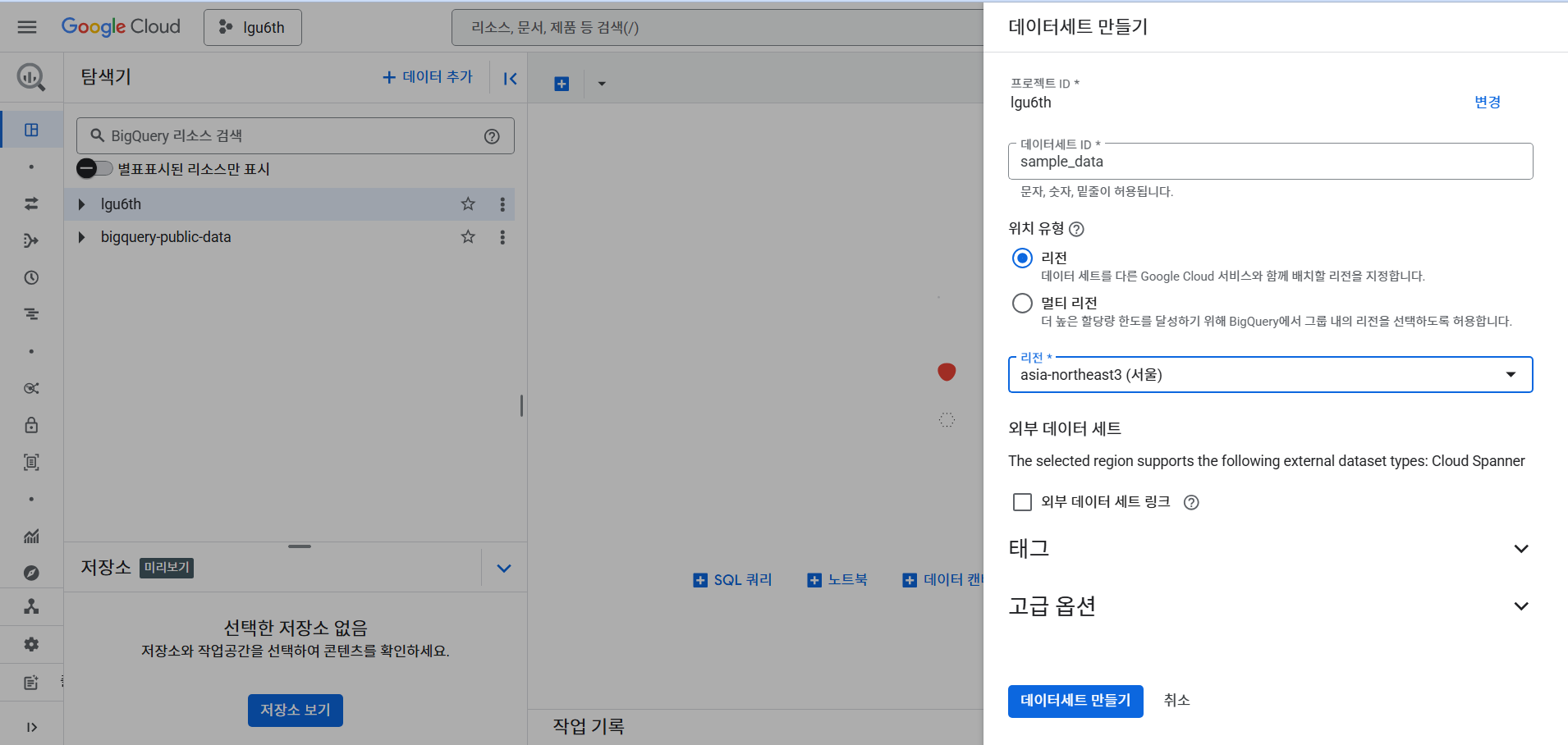
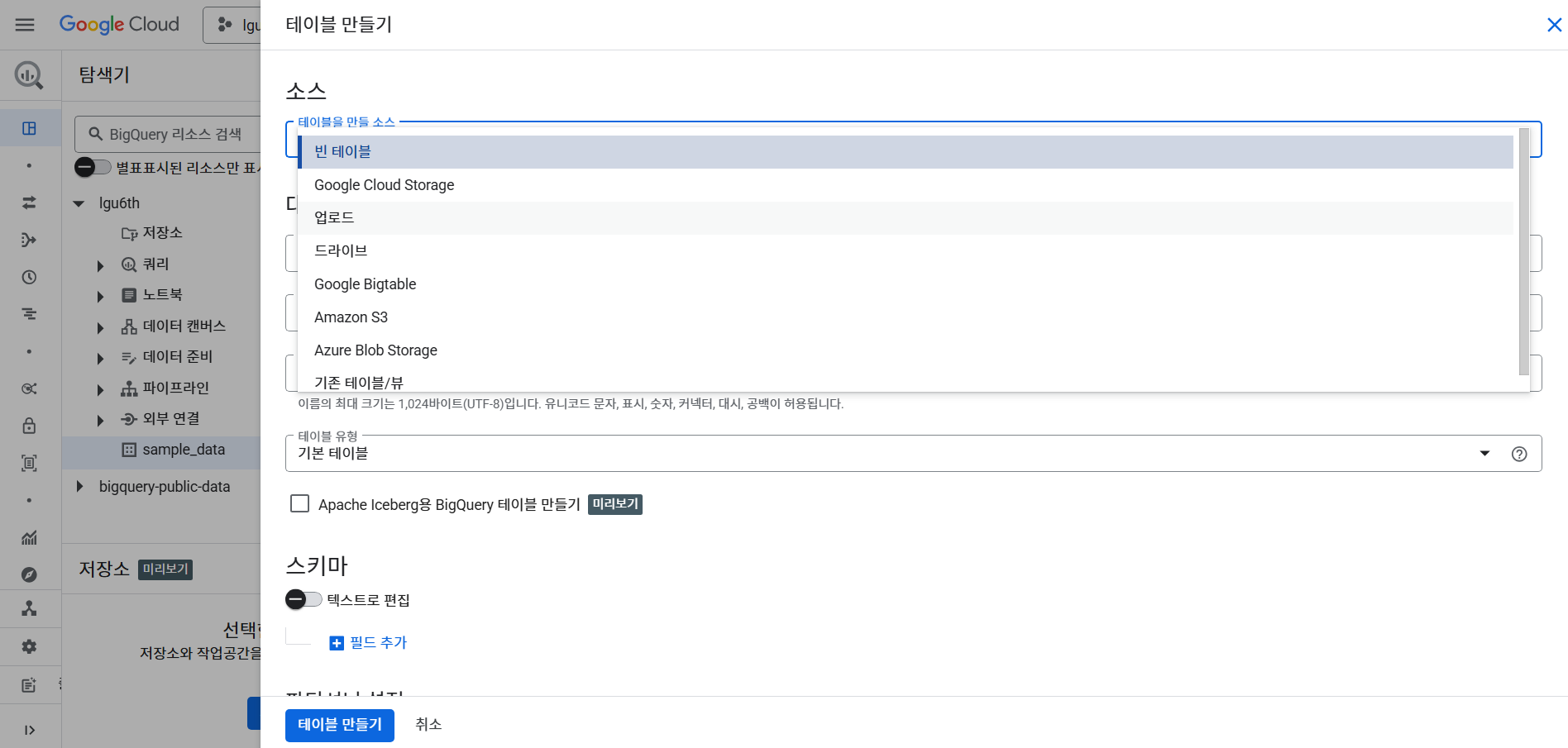
- 테이블 만들기
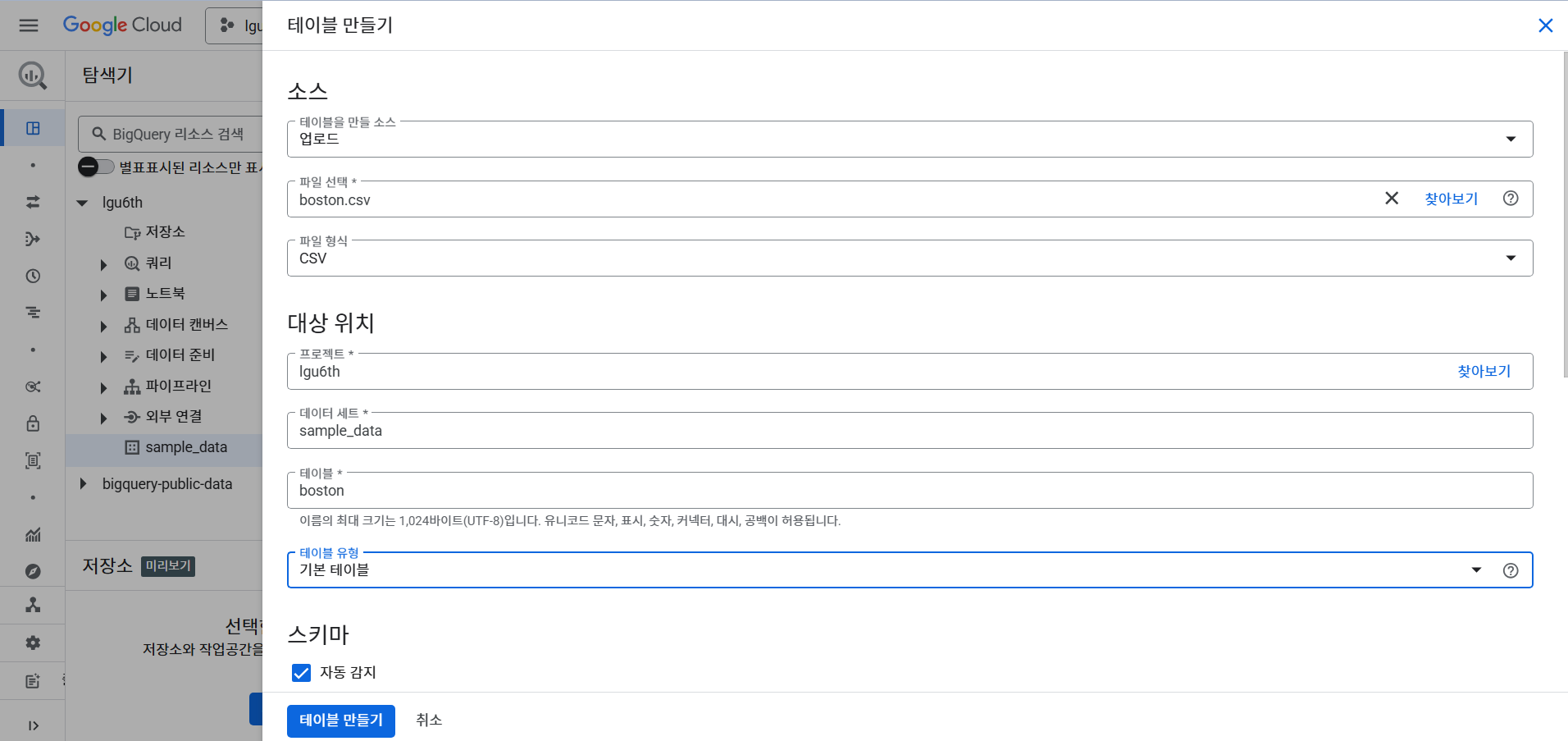
- boston 데이터 파일을 준비한다. 1MB 이하의 파일을 준비한다.
- 테이블을 만들 소스는 업로드에서 가져온다.
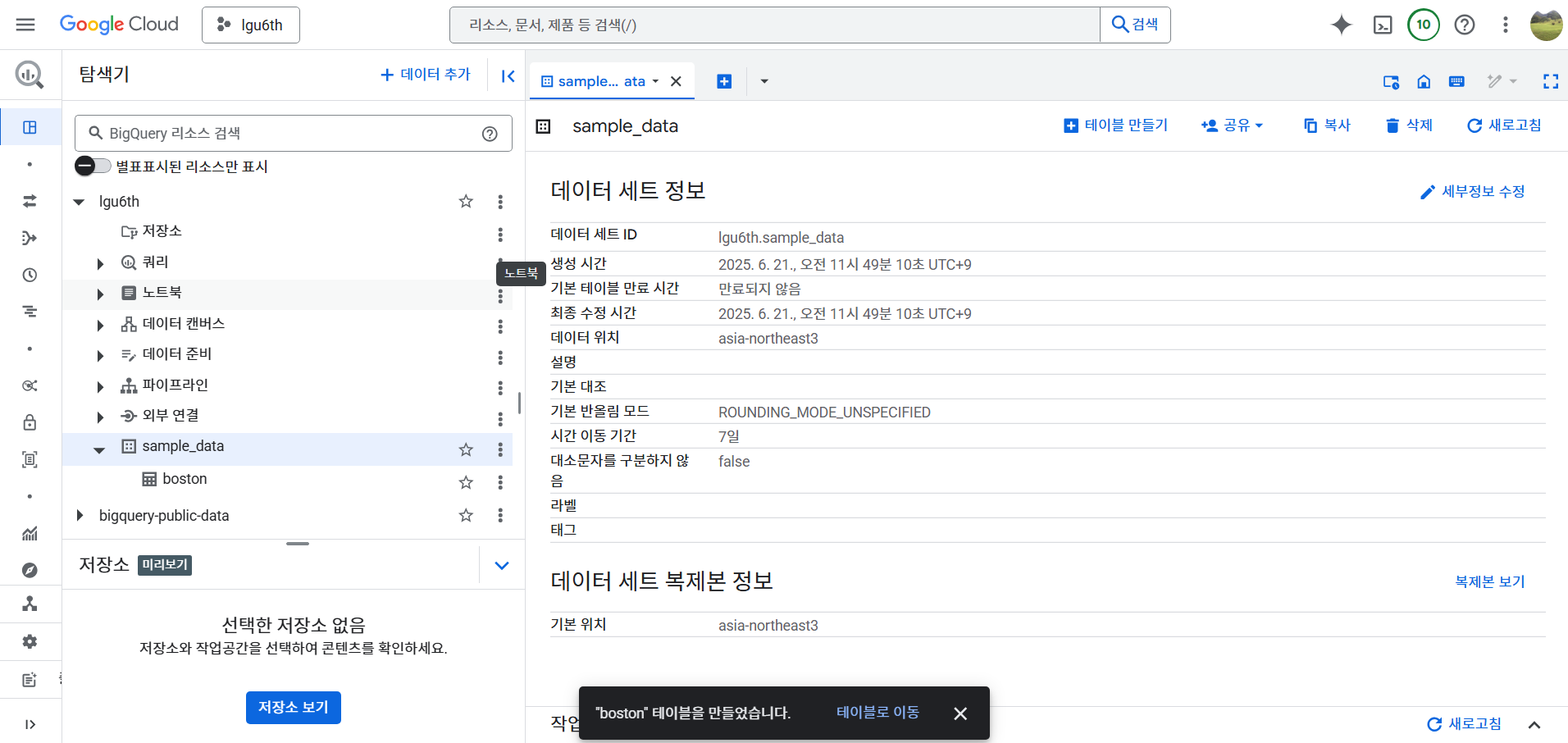
- 간단하게 쿼리 가져오기
SELECT * FROM `lgu6th.sample_data.boston`;
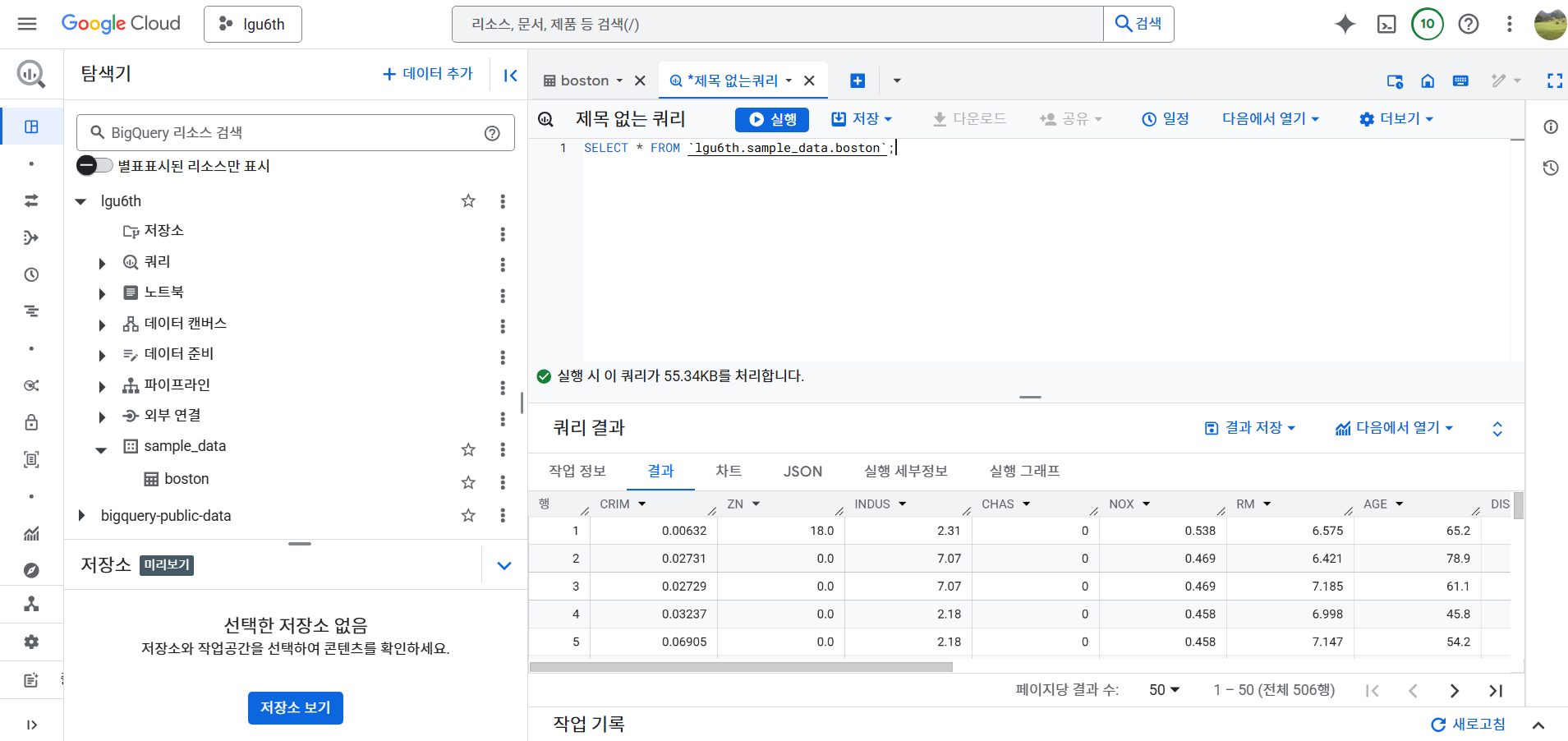
BigQuery 관련 라이브러리 설치
- 이제 VM 다시 생성 후, VS Code에서 연결 후 라이브러리 추가 (requirements.txt)
- 라이브러리 설치
streamlit
jupyterlab
db-dtypes
google-cloud-bigquery
pandas
matplotlib
- streamlit 코드 추가
import streamlit as st
import pandas as pd
import numpy as np
from google.cloud import bigquery
import matplotlib.pyplot as plt
client = bigquery.Client()
source_table = "lgu6th.sample_data.boston"
transformed_table = "lgu6th.sample_data.transformed_boston"
st.set_page_config(layout="wide")
st.title("Boston Housing Data - BigQuery 연동 및 표준화 처리")
tab1, tab2, tab3 = st.tabs(["데이터 불러오기", "데이터 변환 및 업로드", "📊 시각화"])
# 데이터 불러오기 탭
with tab1:
st.subheader("1. 원본 데이터 불러오기")
if st.button("데이터 불러오기 (BigQuery)"):
query = f"SELECT * FROM `{source_table}` LIMIT 1000"
df = client.query(query).to_dataframe()
st.session_state["original_df"] = df
st.success("데이터 불러오기 완료")
if "original_df" in st.session_state:
st.dataframe(st.session_state["original_df"])
# 데이터 변환 탭
with tab2:
st.subheader("2. 데이터 변환 및 BigQuery 업로드")
if "original_df" not in st.session_state:
st.warning("먼저 [데이터 불러오기] 탭에서 데이터를 불러오세요.")
else:
if st.button("데이터 표준화 + 로그변환 후 업로드"):
df = st.session_state["original_df"].copy()
# 로그 변환
df["LOG_CRIM"] = df["CRIM"].apply(lambda x: np.nan if x <= 0 else round(np.log(x), 4))
# 표준화 (평균 0, 표준편차 1)
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()
for col in numeric_cols:
mean = df[col].mean()
std = df[col].std()
if std > 0:
df[f"{col}_z"] = (df[col] - mean) / std
st.session_state["transformed_df"] = df # 변환된 데이터 저장
# 업로드
job_config = bigquery.LoadJobConfig(
write_disposition="WRITE_TRUNCATE",
autodetect=True,
)
job = client.load_table_from_dataframe(df, transformed_table, job_config=job_config)
job.result()
st.success("변환 및 업로드 완료")
st.dataframe(df)
elif "transformed_df" in st.session_state:
st.info("이전 변환 결과:")
st.dataframe(st.session_state["transformed_df"])
# 시각화 탭
with tab3:
st.subheader("3. 변환된 데이터 시각화 (BigQuery에서 불러오기)")
if st.button("변환된 데이터 시각화"):
try:
query = f"SELECT * FROM `{transformed_table}`"
df_trans = client.query(query).to_dataframe()
st.session_state["visual_df"] = df_trans # 시각화용 저장
st.success("BigQuery에서 불러오기 완료")
except Exception as e:
st.error(f"불러오기 실패: {e}")
if "visual_df" in st.session_state:
df_trans = st.session_state["visual_df"]
st.write("데이터 미리보기:")
st.dataframe(df_trans.head())
# 시각화
if "CRIM" in df_trans.columns and "LOG_CRIM" in df_trans.columns:
fig, ax = plt.subplots()
ax.hist(df_trans["CRIM"].dropna(), bins=30, alpha=0.5, label="CRIM")
ax.hist(df_trans["LOG_CRIM"].dropna(), bins=30, alpha=0.5, label="LOG_CRIM")
ax.set_title("CRIM vs LOG_CRIM Histogram")
ax.legend()
st.pyplot(fig)
- Web 배포 결과 확인
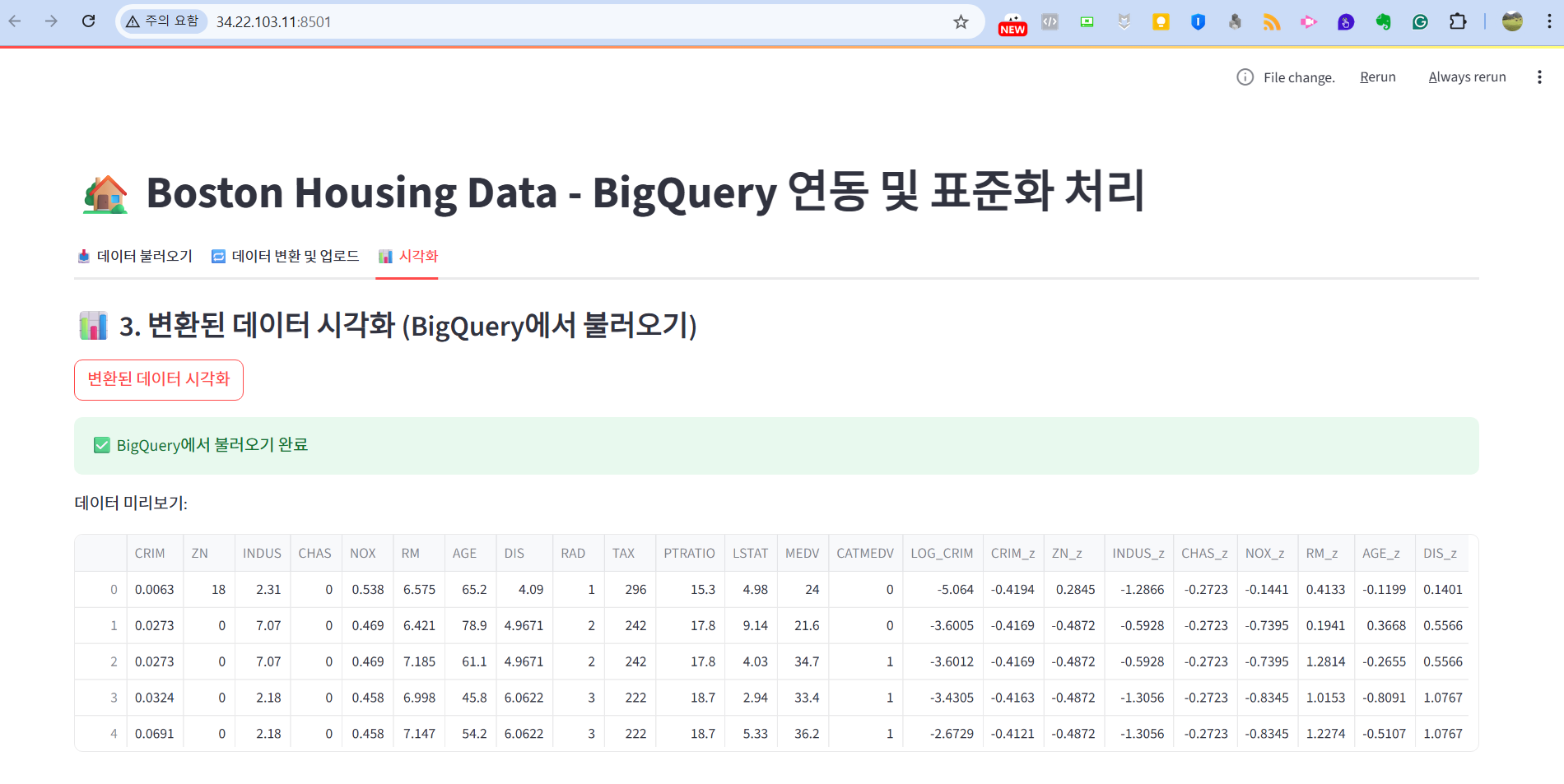
- 결과 확인
VM 종료
- 테스트가 완료가 되었다면 모두 사용 중지 시킨다.
