Streamlit와 BigQuery 활용한 배포 (API)
Page content
사전학습
- 이 글을 읽기전에 한번 Streamlit 라이브러리를 활용한 배포 - BigQuery 사용 을 읽고 오기를 바란다.
실습 순서
- 서울시 부동산 실거래가를 API 크롤링으로 가져온다.
- JSON 형태의 데이터를 pandas 데이터프레임으로 변환한다.
- 데이터프레임을 BigQuery에 전체 데이터를 저장한다.
- 저장된 데이터프레임을 BigQuery에서 일부 컬럼만 불러온다.
실습 1 - API 크롤링에서 빅쿼리로 데이터 저장
.streamlit/secrets.toml을 열고 아래와 같이 설정한다.seoul_api_key는 서울 열린데이터 광장을 의미한다.gcp_service_account아래 내용은api key를json파일로 열면 확인할 수 있다.
# .streamlit/secrets.toml
[public_data_api]
seoul_api_key = 'your_api_key'
[gcp_service_account]
type = "service_account"
project_id = "your_project_id"
private_key_id = "your_private_key_id"
private_key = "your_private_key"
client_email = "your_client_email"
client_id = "your_client_id"
auth_uri = "https://accounts.google.com/o/oauth2/auth"
token_uri = "https://oauth2.googleapis.com/token"
auth_provider_x509_cert_url = "https://www.googleapis.com/oauth2/v1/certs"
client_x509_cert_url = "your_client_x509_cert_url"
utils.py를 생성하고 아래와 같이 설정을 저장한다.
import streamlit as st
from google.oauth2 import service_account
SERVICE_KEY = st.secrets.public_data_api.seoul_api_key
# Create API client.
credentials = service_account.Credentials.from_service_account_info(
# Very Important Point
st.secrets["gcp_service_account"]
)
[aptCrawling.py](http://aptCrawling.py)를 아래와 같이 작성한다.
# -*- coding:utf-8 -*-
import requests
import pandas as pd
# Google Cloud
from google.cloud import bigquery
import pandas_gbq
# API Key Settings
from utils import credentials, SERVICE_KEY
client = bigquery.Client(credentials=credentials)
def aptCrawling(SERVICE_KEY):
data = None
for j in range(1,2):
url = f'http://openapi.seoul.go.kr:8088/{SERVICE_KEY}/json/tbLnOpendataRtmsV/{1+((j-1)*1000)}/{j*1000}'
print(url)
req = requests.get(url)
content = req.json()
con = content['tbLnOpendataRtmsV']['row']
result = pd.DataFrame(con)
data = pd.concat([data, result])
data = data.reset_index(drop=True)
data['DEAL_YMD'] = pd.to_datetime(data['DEAL_YMD'], format=("%Y%m%d"))
return data
def save2BQ(data):
table_name = "seoul.realestate"
project_id = "streamlit-dashboard-369600"
# Save the DataFrame to BigQuery
pandas_gbq.to_gbq(data,
table_name,
project_id=project_id, if_exists='replace')
if __name__ == "__main__":
data = aptCrawling(SERVICE_KEY)
save2BQ(data)
- 아래와 같이 실행해보자.
$ python aptCrawling.py
http://openapi.seoul.go.kr:8088/your_api_key/json/tbLnOpendataRtmsV/1/1000
100%|████████████████████████████████████████████████████████████| 1/1 [00:00<?, ?it/s]
- 이번에는 BigQuery 콘솔에서 확인해본다.
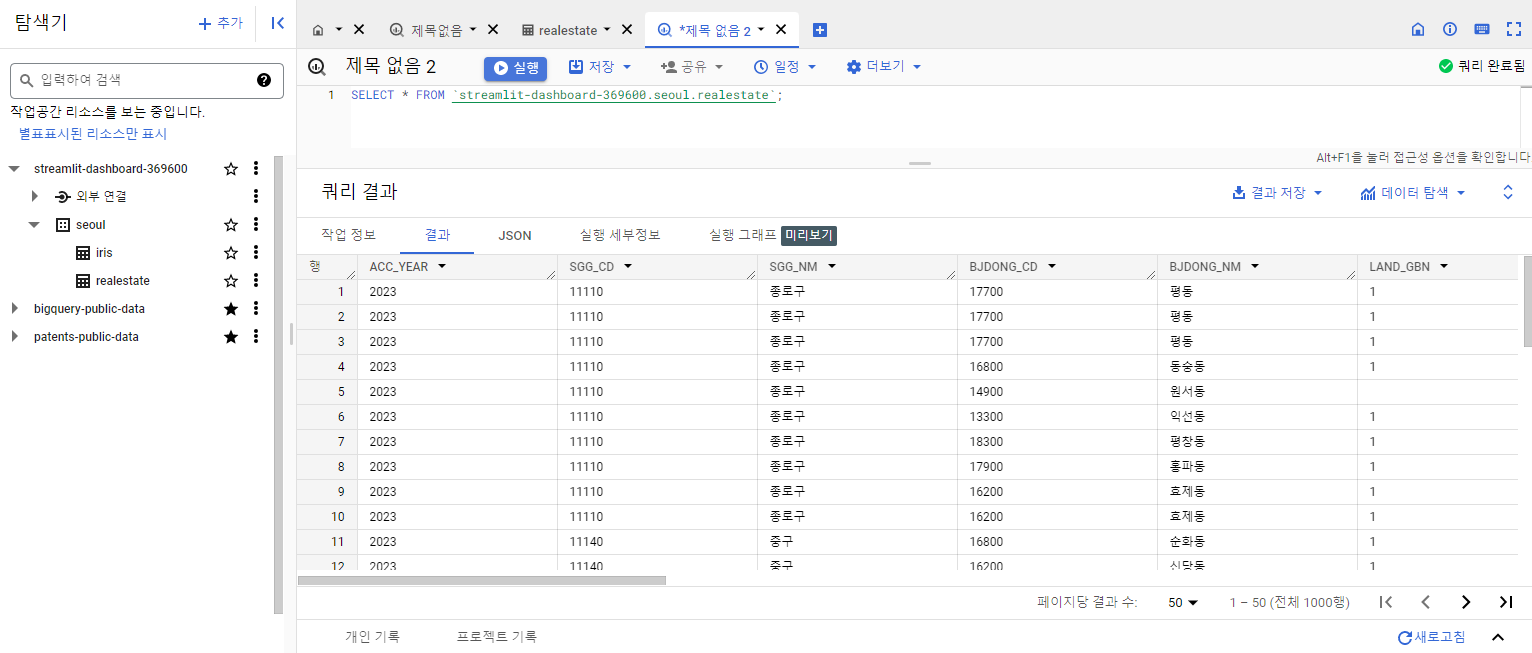
실습 2 - 빅쿼리에서 데이터 불러오기
- 이번에는 app.py를 정의한다.
# streamlit_app.py
import streamlit as st
from google.cloud import bigquery
import seaborn as sns
import pandas as pd
import pandas_gbq
from utils import credentials, SERVICE_KEY
client = bigquery.Client(credentials=credentials)
# Perform query.
# Uses st.experimental_memo to only rerun when the query changes or after 10 min.
@st.cache_data(ttl=600)
def run_query(cols, name):
st.write("Load DataFrame")
sql = f"SELECT {cols} FROM streamlit-dashboard-369600.seoul.{name}"
df = client.query(sql).to_dataframe()
st.dataframe(df)
def main():
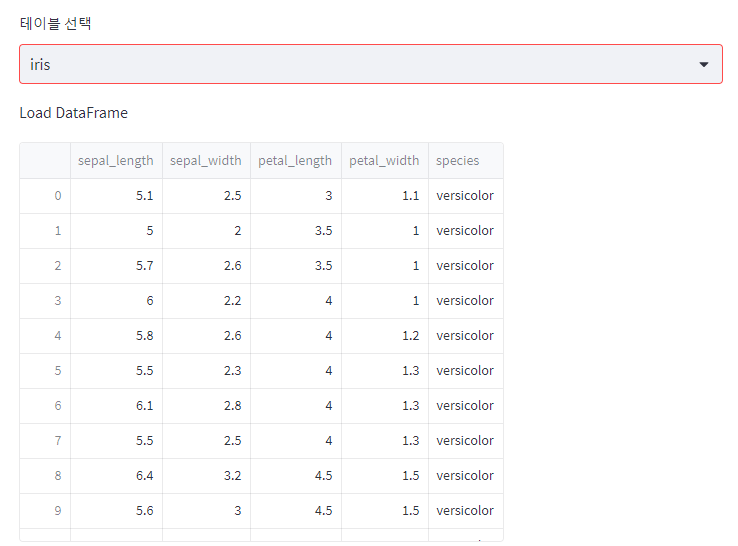
tableNames = st.selectbox("테이블 선택", ("realestate", "iris"))
if tableNames == "iris":
run_query(cols="*", name="iris")
else:
sql = """
SELECT STRING_AGG(column_name)
FROM `streamlit-dashboard-369600.seoul.INFORMATION_SCHEMA.COLUMNS`
where table_name = 'realestate'
group by table_name
"""
df = client.query(sql).to_dataframe()
all_cols = df.values[0][0].split(",")
columns = st.multiselect("컬럼명 선택", all_cols, default=all_cols)
temp_Strings = ", ".join(columns)
run_query(temp_Strings, tableNames)
if __name__ == "__main__":
main()
- 완성된 화면은 아래와 같다.
- 컬럼명 선택에 따라 추출된 테이블이 달라지게 하였다.
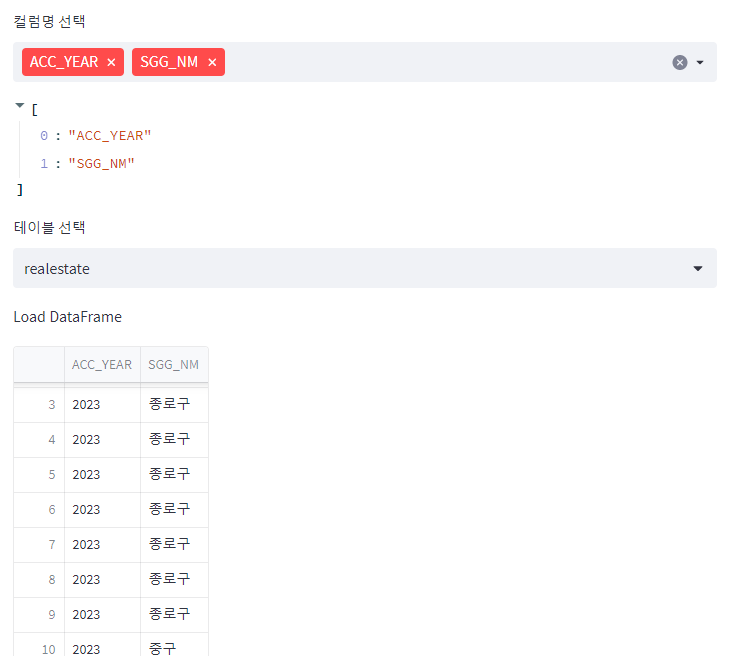
- iris는 디폴트로, 전체 데이터가 조회할 수 있도록 하였고, 컬럼명은 선택할 수 없다.