Logstash 실행 및 확인 - 기본예제
Page content
개요
- Logstash 기본 설치 과정을 확인한다.
- Logstash 활용 예제를 확인한다.
사전준비
- 기존에 Elasticsearch와 Kibana 실행 방법을 알고 있어야 한다.
- 모든 코드는 Windows 에서 실행하였다.
Logstash의 역할
- 데이터 수집 (Ingest) - 데이터 변환 및 처리 (Processing / Filtering) - 데이터 출력 (Output)
데이터 수집
- 다양한 데이터 소스로부터 데이터 수집
- 로그파일
- TCP/UDP/HTTP 요청
- Kafka, Redis, JDBC(DB) 등
데이터 변환 및 처리 (Processing / Filtering)
-
주요 내용
- Logstash는 수집한 원시 데이터를 구조화된 형식으로 파싱하고 정제 및 가공
- 정규표현식 기반
grok필터로 로그 파싱 - 날짜 포맷 통일 (
date) - 필드 추가/삭제/이름 변경
- 조건 분기 처리 (
if,else) - JSON, CSV 파싱
- 지오IP, 위치 정보 추가 등
-
예시 코드
# Logstash 필터 설정 # 이 필터 블록은 들어오는 로그 데이터를 처리하여 구조화된 정보를 추출 filter { # GROK 패턴 매칭 # grok 필터는 정규표현식 패턴을 사용하여 비구조화된 로그 데이터를 구조화된 필드로 파싱합니다 # Logstash에서 로그 파싱을 위한 가장 강력한 필터 중 하나입니다 grok { # 'match' 매개변수는 어떤 필드를 파싱할지와 적용할 패턴을 지정합니다 # 여기서는 'message' 필드를 사용자 정의 grok 패턴으로 파싱합니다 match => { "message" => "%{IP:client_ip} - %{WORD:method} %{URIPATH:uri}" } # 패턴 상세 분석: # %{IP:client_ip} - IP 주소를 매칭하여 'client_ip' 필드에 저장 # - IPv4 또는 IPv6 형식 모두 지원 # - - 리터럴 대시 문자 (구분자) # %{WORD:method} - 단어를 매칭 (GET, POST, PUT, DELETE 같은 HTTP 메서드) # - 'method' 필드에 저장 # %{URIPATH:uri} - URI 경로를 매칭 (/api/users, /index.html 같은 경로) # - 'uri' 필드에 저장 # 입력 예시: "192.168.1.100 - GET /api/users" # 출력 필드: # client_ip: "192.168.1.100" # method: "GET" # uri: "/api/users" } # 날짜 파싱 # date 필터는 타임스탬프 문자열을 적절한 @timestamp 필드로 변환합니다 # Kibana에서 시간 기반 분석과 시각화를 위해 매우 중요합니다 date { # 'match' 매개변수는 타임스탬프가 포함된 필드와 해당 형식을 지정합니다 # 형식: [필드명, "날짜_형식_패턴"] match => [ "timestamp", # 날짜 문자열이 포함된 소스 필드 "dd/MMM/yyyy:HH:mm:ss Z" # 매칭할 날짜 형식 패턴 ] # 날짜 형식 패턴 상세 분석: # dd - 월의 일 (01-31) # MMM - 월 이름 약어 (Jan, Feb, Mar 등) # yyyy - 전체 연도 (2023, 2024 등) # : - 리터럴 콜론 구분자 # HH - 24시간 형식의 시간 (00-23) # mm - 분 (00-59) # ss - 초 (00-59) # Z - 시간대 오프셋 (+0000, -0500 등) # 입력 타임스탬프 예시: "25/Dec/2023:14:30:45 +0000" # 출력: 적절한 datetime 객체가 있는 @timestamp 필드 # 추가할 수 있는 선택적 매개변수들: # target => "@timestamp" # 기본 대상 필드 (사용자 정의 가능) # timezone => "UTC" # 타임스탬프에 없는 경우 시간대 지정 # locale => "en" # 월 이름의 로케일 (기본값: en) } } # 추가 참고사항: # 1. 이 필터는 로그 데이터에 'message' 필드와 'timestamp' 필드가 있다고 가정합니다 # 2. grok 패턴은 메시지 형식이 패턴과 정확히 일치할 때만 매칭됩니다 # 3. grok이 매칭에 실패하면 이벤트는 여전히 통과하지만 추출된 필드 없이 진행됩니다 # 4. date 필터는 타임스탬프 형식이 정확히 일치할 때만 작동합니다 # 5. 서로 다른 로그 형식을 위해 배열에 여러 grok 패턴을 추가할 수 있습니다: # match => { "message" => ["패턴1", "패턴2", "패턴3"] }
데이터 출력 (Output)
- 변환된 데이터를 다양한 곳으로 전송할 수 있음
- Elasticsearch
- 파일
- Kafka
- AWS S3
- stdout (터미널 출력)
- 코드 예시
# Logstash Output 설정 (한글 주석)
# 이 output 블록은 처리된 로그 데이터를 Elasticsearch에 저장하는 방법을 정의합니다
output {
# Elasticsearch 출력
# elasticsearch 플러그인은 Logstash에서 Elasticsearch로 데이터를 전송하는 표준 방법입니다
# 이 설정은 로그 데이터를 Elasticsearch 인덱스에 저장하여 Kibana에서 분석할 수 있게 합니다
elasticsearch {
# hosts 매개변수: Elasticsearch 클러스터의 호스트 주소들을 배열로 지정
# 각 호스트는 프로토콜(http/https), 호스트명, 포트를 포함할 수 있습니다
hosts => ["http://localhost:9200"]
# 호스트 설정 상세:
# http://localhost:9200 - 로컬 Elasticsearch 인스턴스 (기본 포트)
# https://es-cluster:9200 - SSL이 활성화된 원격 클러스터
# 여러 호스트 예시: ["http://es1:9200", "http://es2:9200", "http://es3:9200"]
# index 매개변수: 데이터가 저장될 Elasticsearch 인덱스 이름을 지정
# %{+YYYY.MM.dd}는 Logstash의 날짜 형식화 기능을 사용한 동적 인덱스 이름
index => "nginx-logs-%{+YYYY.MM.dd}"
# 인덱스 이름 패턴 분석:
# nginx-logs- - 고정 접두사 (로그 타입 식별)
# %{+YYYY.MM.dd} - 날짜 기반 동적 접미사
# + - 날짜 형식화 시작 표시
# YYYY - 4자리 연도 (2023, 2024 등)
# . - 리터럴 점 구분자
# MM - 2자리 월 (01-12)
# . - 리터럴 점 구분자
# dd - 2자리 일 (01-31)
# 실제 생성되는 인덱스 이름 예시:
# nginx-logs-2023.12.25
# nginx-logs-2024.01.01
# nginx-logs-2024.01.02
# 날짜 기반 인덱스의 장점:
# 1. 데이터 관리 용이성 (오래된 인덱스 삭제 가능)
# 2. 성능 최적화 (새로운 데이터는 최신 인덱스에만 쓰기)
# 3. 샤드 분산 (각 날짜별로 별도 샤드)
# 4. 백업 및 복구 용이성
}
}
# 추가 설정 옵션들 (주석 처리된 예시):
# output {
# elasticsearch {
# hosts => ["http://localhost:9200"]
# index => "nginx-logs-%{+YYYY.MM.dd}"
#
# # 인증 설정 (보안이 활성화된 Elasticsearch)
# # user => "elastic"
# # password => "your_password"
#
# # SSL/TLS 설정
# # ssl => true
# # ssl_certificate_verification => false
#
# # 연결 설정
# # retry_initial_interval => 5
# # retry_max_interval => 30
# # retry_on_conflict => 5
#
# # 배치 설정 (성능 최적화)
# # bulk_size => 1000
# # flush_size => 500
# # idle_flush_time => 1
#
# # 타임아웃 설정
# # timeout => 60
#
# # 문서 ID 설정 (중복 방지)
# # document_id => "%{client_ip}-%{timestamp}"
#
# # 동작 설정
# # action => "index" # 기본값: index (문서 생성/업데이트)
# # action => "create" # 문서가 존재하지 않을 때만 생성
# # action => "update" # 문서 업데이트
# # action => "delete" # 문서 삭제
# }
# }
# 인덱스 라이프사이클 관리 (ILM) 고려사항:
# 1. 인덱스 템플릿 설정으로 매핑 자동화
# 2. ILM 정책으로 자동 인덱스 관리 (롤오버, 삭제)
# 3. 샤드 수 최적화 (일반적으로 1-3개 권장)
# 4. 복제본 수 설정 (고가용성을 위해 1개 이상 권장)
# 모니터링 및 디버깅:
# 1. Logstash 로그에서 Elasticsearch 연결 상태 확인
# 2. Elasticsearch 클러스터 상태 모니터링
# 3. 인덱스 생성 및 문서 수 확인
# 4. 성능 메트릭 모니터링 (bulk 요청 성공률, 응답 시간 등)
설치
간단 예시
Hello World
- 먼저 프로젝트 폴더 최상위 경로에서 logstash-hello-world.conf 파일을 만들고 다음과 같이 입력한다.
input {
stdin {}
}
filter {
mutate {
replace => { "message" => "Hello World" }
}
}
output {
stdout {
codec => plain
}
}
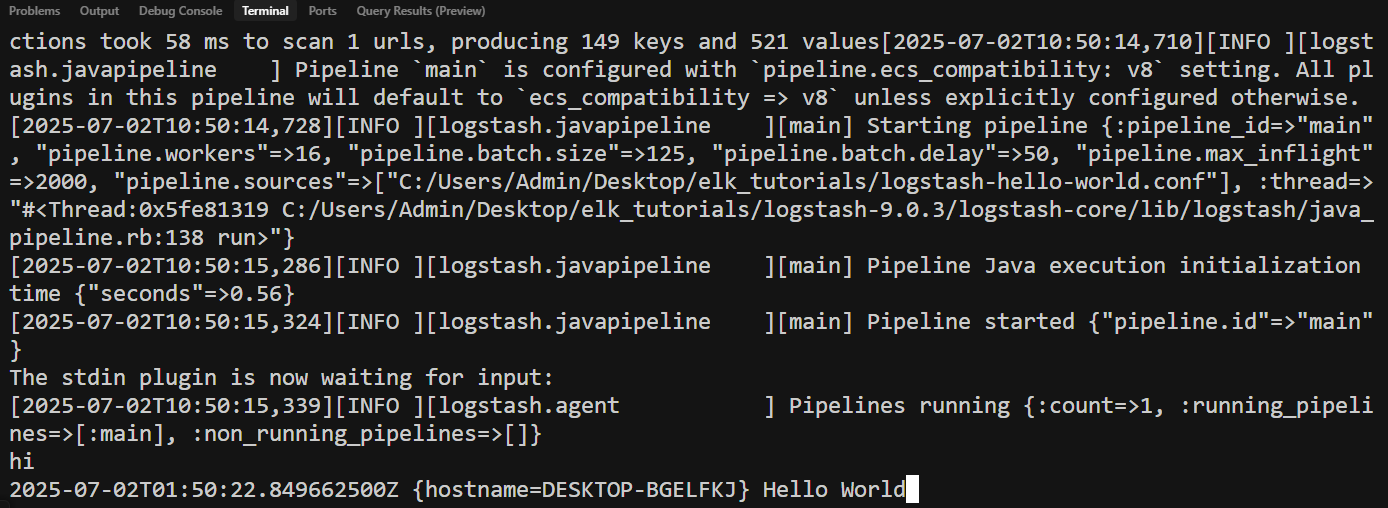
- 실행 방법은 다음과 같다. 그 이후에 hi라고 입력하면 Hello World가 출력될 것이다.
logstash-9.0.3\bin\logstash -f ../logstash-hello-world.conf
Python Log 생성기
- 먼저 다음과 같이 코드 작성 후 해당 파일을 바로 실행시킨다.
- 파일명 : logstash_log_generator.py
# 필요한 모듈들을 가져옵니다
import time # 시간 지연을 위한 모듈
import random # 랜덤 선택을 위한 모듈
import logging # 로깅 기능을 위한 모듈
# 로그 파일 설정
# - filename: 로그가 저장될 파일명
# - level: 로그 레벨 (INFO 이상의 모든 로그 기록)
# - format: 로그 형식 (시간 로그레벨 메시지)
logging.basicConfig(
filename='sample_log.log', # 로그 파일명
level=logging.INFO, # 로그 레벨 설정
format='%(asctime)s %(levelname)s %(message)s' # 로그 형식 정의
)
# 무한 루프로 로그를 생성하는 함수
def generate_logs():
# 로그 레벨 목록 (INFO, WARNING, ERROR)
levels = ['INFO', 'WARNING', 'ERROR']
# 로그 메시지 목록 (다양한 시스템 이벤트 시뮬레이션)
messages = [
"User login successful", # 사용자 로그인 성공
"User login failed", # 사용자 로그인 실패
"File not found", # 파일을 찾을 수 없음
"Database connection established", # 데이터베이스 연결 성공
"Database connection failed" # 데이터베이스 연결 실패
]
# 무한 루프로 계속 로그 생성
while True:
# 랜덤하게 로그 레벨과 메시지 선택
level = random.choice(levels) # 랜덤 로그 레벨 선택
message = random.choice(messages) # 랜덤 메시지 선택
# 로그 레벨에 따라 적절한 로깅 함수 호출
if level == 'INFO':
logging.info(message) # 정보 로그 기록
elif level == 'WARNING':
logging.warning(message) # 경고 로그 기록
else:
logging.error(message) # 에러 로그 기록
# 1초 대기 후 다음 로그 생성
time.sleep(1)
# 스크립트가 직접 실행될 때만 로그 생성 시작
if __name__ == "__main__":
generate_logs() # 로그 생성 함수 호출
conf 파일 작성
- 다음과 같이 파일 작성 (파일명 : logstash_pipeline.conf)
# Logstash 파이프라인 설정 파일
# 이 파일은 sample_log.log 파일을 읽어서 Elasticsearch에 저장하는 설정입니다
input {
file {
# 읽을 로그 파일의 경로 (Windows 절대 경로 사용)
# 경로에 공백이나 특수문자가 있으면 따옴표로 감싸야 함
path => "C:/Users/Admin/Desktop/elk_tutorials/sample_log.log"
# 파일 읽기 시작 위치 설정
# "beginning": 파일의 처음부터 읽기 (기존 로그도 모두 처리)
# "end": 파일의 끝부터 읽기 (새로 추가되는 로그만 처리)
start_position => "beginning"
# Windows 환경에서 파일 변경 감지 정보 저장 위치
# "NUL"로 설정하면 변경 감지 정보를 저장하지 않음
# 매번 실행할 때마다 처음부터 읽게 됨
sincedb_path => "NUL"
# 입력 파일의 인코딩 방식 설정
# "plain": 일반 텍스트 파일로 읽기
# "json": JSON 형식으로 읽기
codec => "plain"
# 모든 로그 레코드에 추가할 필드
# 로그 유형을 식별하기 위한 메타데이터 추가
add_field => { "log_type" => "sample_logs" }
}
}
filter {
# Grok 패턴을 사용하여 로그 메시지를 구조화된 필드로 분해
grok {
match => {
# 로그 형식: "2024-01-01 12:00:00,123 INFO User login successful"
# %{TIMESTAMP_ISO8601:timestamp}: ISO8601 형식의 타임스탬프를 timestamp 필드로 추출
# %{LOGLEVEL:level}: 로그 레벨(INFO, WARNING, ERROR)을 level 필드로 추출
# %{GREEDYDATA:log_message}: 나머지 모든 텍스트를 log_message 필드로 추출
"message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:level} %{GREEDYDATA:log_message}"
}
}
# 타임스탬프 필드를 Elasticsearch의 @timestamp 필드로 변환
date {
# timestamp 필드의 날짜 형식을 지정
# yyyy-MM-dd HH:mm:ss,SSS: 년-월-일 시:분:초,밀리초
match => ["timestamp", "yyyy-MM-dd HH:mm:ss,SSS"]
# 변환된 날짜를 저장할 필드명
# @timestamp는 Elasticsearch의 기본 타임스탬프 필드
target => "@timestamp"
}
# 로그 레벨에 따라 태그 추가 (분류 및 필터링용)
if [level] == "ERROR" {
# 에러 로그에 "error_log" 태그 추가
mutate { add_tag => ["error_log"] }
} else if [level] == "WARNING" {
# 경고 로그에 "warning_log" 태그 추가
mutate { add_tag => ["warning_log"] }
} else if [level] == "INFO" {
# 정보 로그에 "info_log" 태그 추가
mutate { add_tag => ["info_log"] }
}
}
output {
# Elasticsearch에 로그 데이터 저장
elasticsearch {
# Elasticsearch 서버 주소 (기본 포트 9200)
hosts => ["http://localhost:9200"]
# Elasticsearch 인증 정보
# user: 사용자명 (기본값: elastic)
user => "elastic"
# password: 비밀번호 (설치 시 설정한 값)
password => "123456"
# 인덱스명 설정 (날짜별로 자동 생성)
# sample-logs-2024.01.01 형식으로 생성됨
# %{+YYYY.MM.dd}: 현재 날짜를 YYYY.MM.dd 형식으로 삽입
index => "sample-logs-%{+YYYY.MM.dd}"
}
# 콘솔에 처리된 로그 출력 (디버깅 및 모니터링용)
stdout {
# 출력 형식 설정
# rubydebug: 구조화된 JSON 형태로 출력 (가독성 좋음)
# plain: 일반 텍스트로 출력
codec => rubydebug
}
}
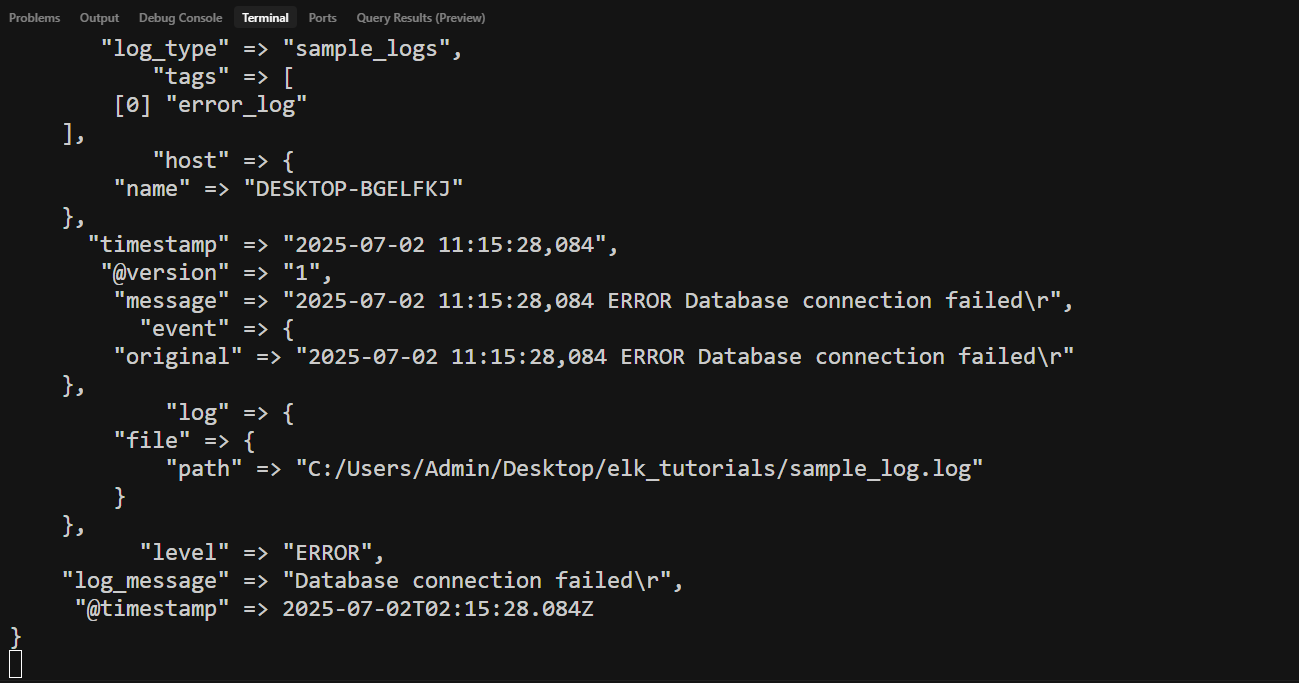
- Hello World에서 실행하는 것과 같이 실행
logstash-9.0.3\bin\logstash -f ../logstash_pipeline.conf
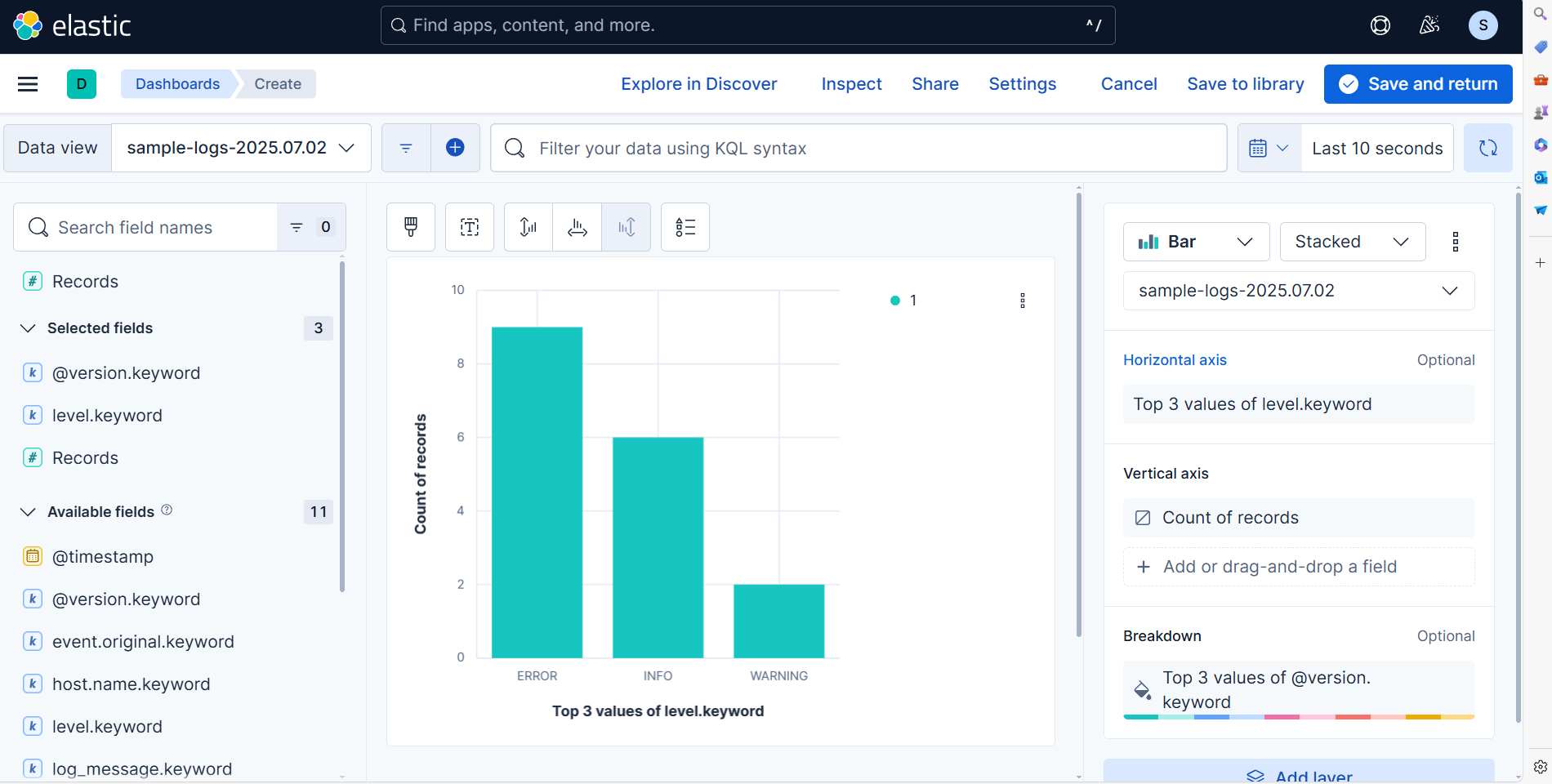
Kibana 확인
- 이제 Kibana에서 실제 로그가 추적되는지 확인한다.
- 우측 상단에 새로고침 버튼을 주기적으로 클릭하면 변화를 확인할 수 있다.